文章目录
创建线程的方式
创建线程的方式一般有如下 4 种:
- 继承 Thread 类
- 实现 Runable 接口
- 实现 Callable 接口
- 利用线程池
其中,直接继承 Thread 或者实现 Runnable 接口都可以创建线程,但是这两种方法都有一个问题就是:没有返回值,也就是不能获取执行完的结果。因此 java1.5 就提供了 Callable 接口来实现这一场景,配合 Future 和 FutureTask 使用。
为什么需要 Callable?Runnable 的缺陷如下:
- 不能返回一个返回值
- 不能抛出 checked Exception
Callable 的 call 方法可以有返回值,可以声明抛出异常。和 Callable 配合的有一个 Future 类,通过 Future 可以了解任务执行情况,或者取消任务的执行,还可获取任务执行的结果,这些功能都是 Runnable 做不到的。
public class FutureDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
new Thread(() -> {
System.out.println("通过 Runnable 方式执行任务");
}).start();
FutureTask task = new FutureTask(new Callable() {
@Override
public Object call() throws Exception {
System.out.println("通过 Callable 方式执行任务");
// 等待 3s 模拟执行任务
Thread.sleep(3000);
return "返回任务结果";
}
});
new Thread(task).start();
System.out.println("结果:" + task.get());
}
}
Future
Future 表示一个可能还没有完成的异步任务的结果,对于具体的 Runnable 或者 Callable 任务的执行结果进行取消、查询是否完成、获取结果。
必要时可以通过get方法获取执行结果,该方法会阻塞直到任务返回结果。
构造方法
public FutureTask(Callable<V> callable)
public FutureTask(Runnable runnable, V result)
实际上Callable = Runnable + result。
常用方法
Future 接口存在以下几个方法:
-
boolean cancel (boolean mayInterruptIfRunning)取消任务的执行。参数指定是否立即中断任务执行,或者等等任务结束。
-
boolean isCancelled ()任务是否已经取消,任务正常完成前将其取消,则返回 true。
-
boolean isDone ()任务是否已经完成。需要注意的是如果任务正常终止、异常或取消,都将返回 true。
-
V get () throws InterruptedException, ExecutionException等待任务执行结束,然后获得 V 类型的结果。InterruptedException 线程被中断异常,ExecutionException任务执行异常,如果任务被取消,还会抛出 CancellationException 。
-
V get(long timeout,TimeUnit unit) throws InterruptedException,ExecutionException, TimeoutException同上面的 get 功能一样,多了设置超时时间。参数 timeout 指定超时时间,uint 指定时间的单位,在枚举类TimeUnit中有相关的定义。如果计算超时,将抛出 TimeoutException。
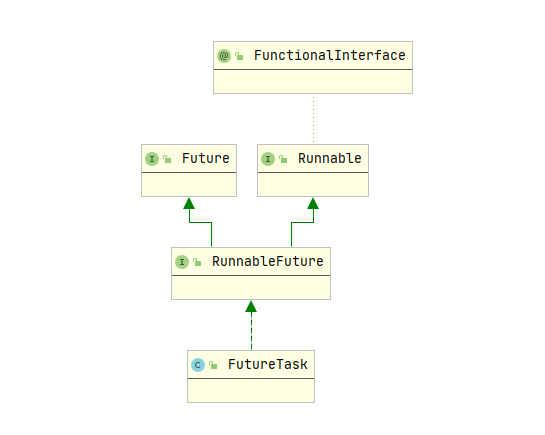
FutureTask
Future 实际采用 FutureTask 实现,该对象相当于是消费者和生产者的桥梁,消费者通过 FutureTask 存储任务的处理结果,更新任务的状态:未开始、正在处理、已完成等。而生产者拿到的 FutureTask 被转型为 Future 接口,可以阻塞式获取任务的处理结果,非阻塞式获取任务处理状态。
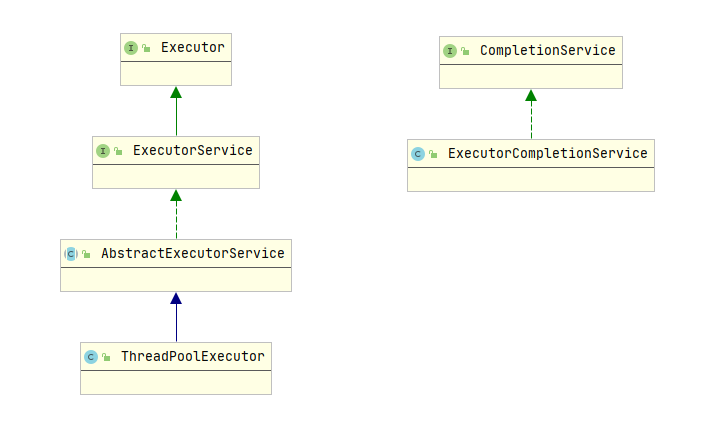
FutureTask 既可以被当做 Runnable 来执行,也可以被当做 Future 来获取 Callable 的返回结果。继承关系如下:
使用方式
可以把 Callable 实例当作 FutureTask 构造函数的参数,生成 FutureTask 的对象,然后把这个对象当作一个 Runnable 对象,放到线程池中或另起线程去执行,最后还可以通过 FutureTask 获取任务执行的结果。
public class FutureTaskDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 实现 Callable
Task task = new Task();
//构建futureTask
FutureTask<Integer> futureTask = new FutureTask<>(task);
//作为Runnable入参
new Thread(futureTask).start();
System.out.println("task运行结果:" + futureTask.get());
}
static class Task implements Callable<Integer> {
@Override
public Integer call() throws Exception {
System.out.println("子线程正在计算");
int sum = 0;
for (int i = 0; i < 100; i++) {
sum += i;
}
return sum;
}
}
}
使用场景
A 服务调用 B 服务多接口响应时间最短?
比如促销活动中商品信息查询(包括商品基本信息、商品价格、商品库存、商品图片、商品销售状态等),再比如机票订单详情页面(包括订单信息、航班信息、乘机人信息、联系人信息、支付信息、退改签规定信息等等,通常情况下这些信息都不会由一个服务提供)。
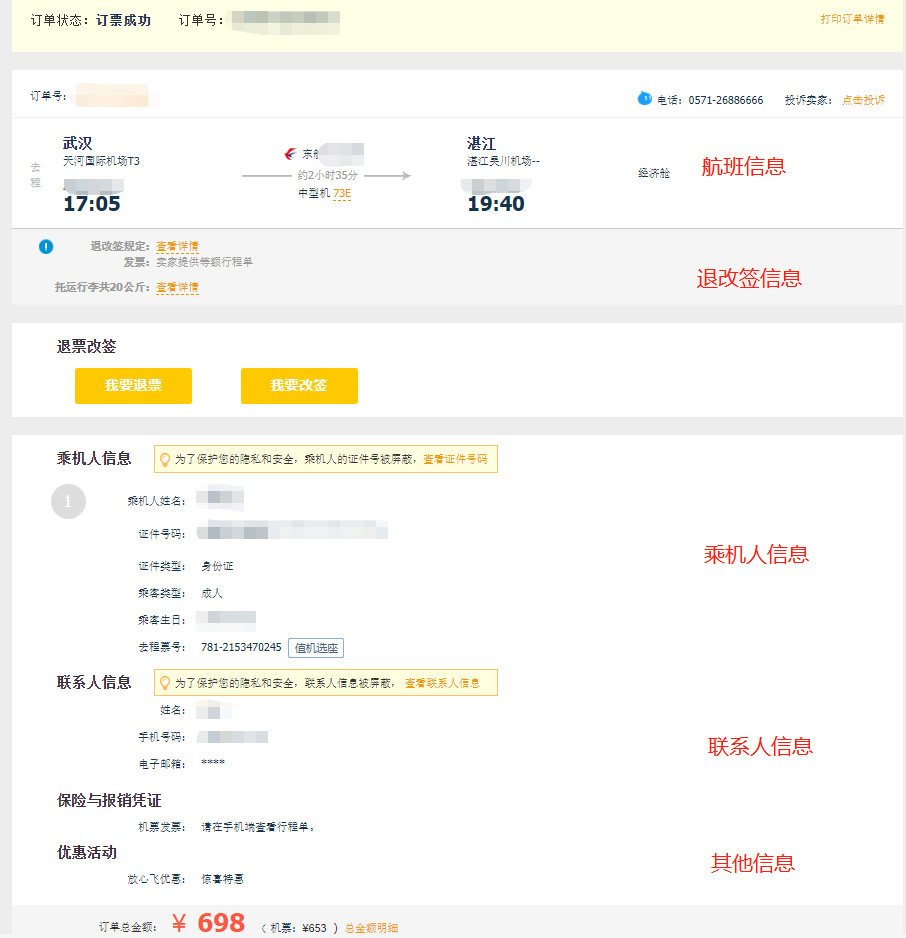
这些信息分布在不同的业务中心,由不同的系统提供服务。如果采用同步方式,假设一个接口需要 50ms,总耗时则为每个接口耗时之和,那么一个订单详情页面信息查询下来就需要 200ms-300ms,这对于我们来说是不满意的。
因此,我们可以通过 Future 异步并行的方式来获取不同的信息,如下:
public class FutureTaskDemo2 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<String> ft1 = new FutureTask<>(new T1Task());
FutureTask<String> ft2 = new FutureTask<>(new T2Task());
FutureTask<String> ft3 = new FutureTask<>(new T3Task());
FutureTask<String> ft4 = new FutureTask<>(new T4Task());
FutureTask<String> ft5 = new FutureTask<>(new T5Task());
//构建线程池
ExecutorService executorService = Executors.newFixedThreadPool(5);
executorService.submit(ft1);
executorService.submit(ft2);
executorService.submit(ft3);
executorService.submit(ft4);
executorService.submit(ft5);
//获取执行结果
System.out.println(ft1.get());
System.out.println(ft2.get());
System.out.println(ft3.get());
System.out.println(ft4.get());
System.out.println(ft5.get());
executorService.shutdown();
}
static class T1Task implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("T1:查询航班信息...");
TimeUnit.MILLISECONDS.sleep(5000);
return "航班信息查询成功";
}
}
static class T2Task implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("T2:查询乘机人信息...");
TimeUnit.MILLISECONDS.sleep(50);
return "乘机人信息查询成功";
}
}
static class T3Task implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("T3:查询联系人信息...");
TimeUnit.MILLISECONDS.sleep(50);
return "联系人信息查询成功";
}
}
static class T4Task implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("T4:查询退改签信息...");
TimeUnit.MILLISECONDS.sleep(50);
return "退改签信息查询成功";
}
}
static class T5Task implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("T5:查询其他信息...");
TimeUnit.MILLISECONDS.sleep(50);
return "其他信息查询成功";
}
}
}
执行结果:

Future的局限性
从本质上说,Future表示一个异步计算的结果。它提供了isDone()来检测计算是否已经完成,并且在计算结束后,可以通过get()方法来获取计算结果。在异步计算中,Future 确实是个非常优秀的接口。但是,它的本身也确实存在着许多限制。
-
并发执行多任务
Future 只提供了 get() 方法来获取结果,并且是阻塞的。所以,除了等待你别无他法。
-
无法对多个任务进行链式调用
如果你希望在计算任务完成后执行特定动作,比如发邮件,但 Future 却没有提供这样的能力。
-
无法组合多个任务
如果你运行了 10 个任务,并期望在它们全部执行结束后执行特定动作,那么在 Future 中这是无能为力的。
-
没有异常处理
Future 接口中没有关于异常处理的方法。
CompletionService
Callable+Future 可以实现多个 task 并行执行,但是如果遇到前面的 task 执行较慢时需要阻塞等待前面的 task 执行完后面 task 才能取得结果。而 CompletionService 的主要功能就是一边生成任务,一边获取任务的返回值。让两件事分开执行,任务之间不会互相阻塞,可以实现先执行完的先取结果,不再依赖任务顺序了。
构造方法
CompletionService 是一个接口,其实现类为 ExecutorCompletionService,ExecutorCompletionService 把具体的计算任务交给 Executor 完成。
ExecutorCompletionService(Executor executor)
ExecutorCompletionService(Executor executor, BlockingQueue<Future<V>> completionQueue)
常用方法

-
submit提交一个 Callable 或者 Runnable 类型的任务,并返回 Future。
-
take阻塞方法,从结果队列中获取并移除一个已经执行完成的任务的结果,如果没有就会阻塞,直到有任务完成返回结果。
-
poll从结果队列中获取并移除一个已经执行完成的任务的结果,如果没有就会返回 null,该方法不会阻塞。
使用场景
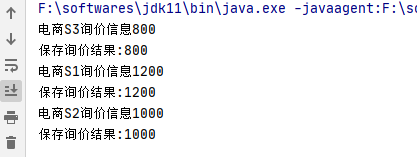
向不同电商平台询价,并保存价格。
我们询价过程中,不同电商平台由于不同因素返回的时间肯定不同,因此对于先返回的我们先保存。
public class CompletionServiceDemo {
public static void main(String[] args) throws InterruptedException, ExecutionException {
//创建线程池
ExecutorService executor = Executors.newFixedThreadPool(10);
//创建CompletionService
CompletionService<Integer> cs = new ExecutorCompletionService<>(executor);
//异步向电商S1询价
cs.submit(() -> getPriceByS1());
//异步向电商S2询价
cs.submit(() -> getPriceByS2());
//异步向电商S3询价
cs.submit(() -> getPriceByS3());
//将询价结果异步保存到数据库
for (int i = 0; i < 3; i++) {
//从阻塞队列获取futureTask
Integer r = cs.take().get();
executor.execute(() -> save(r));
}
executor.shutdown();
}
private static void save(Integer r) {
System.out.println("保存询价结果:" + r);
}
private static Integer getPriceByS1() throws InterruptedException {
TimeUnit.MILLISECONDS.sleep(5000);
System.out.println("电商S1询价信息1200");
return 1200;
}
private static Integer getPriceByS2() throws InterruptedException {
TimeUnit.MILLISECONDS.sleep(8000);
System.out.println("电商S2询价信息1000");
return 1000;
}
private static Integer getPriceByS3() throws InterruptedException {
TimeUnit.MILLISECONDS.sleep(3000);
System.out.println("电商S3询价信息800");
return 800;
}
}
执行结果:
实现原理
内部通过阻塞队列+FutureTask,实现了任务先完成可优先获取到,即结果按照完成先后顺序排序,内部有一个先进先出的阻塞队列,用于保存已经执行完成的 Future,通过调用它的 take 方法或 poll 方法可以获取到一个已经执行完成的 Future,进而通过调用 Future 接口实现类的 get 方法获取最终的结果。
在实现上,ExecutorCompletionService 在构造函数中会创建一个 BlockingQueue(使用的基于链表的无界队列LinkedBlockingQueue),该 BlockingQueue 的作用是保存 Executor 执行的结果。当计算完成时,调用 FutureTask 的 done 方法。当提交一个任务到 ExecutorCompletionService 时,首先将任务包装成 QueueingFuture,它是 FutureTask 的一个子类,然后改写 FutureTask 的 done 方法,之后把 Executor 执行的计算结果放入 BlockingQueue 中。
当 ExecutorCompletionService 提交任务时,如下:
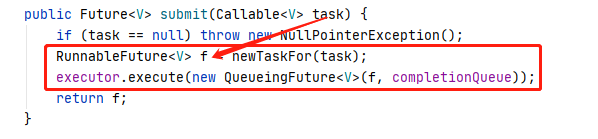
然后把任务包装成 QueueingFuture,QueueingFuture 的源码如下:
private static class QueueingFuture<V> extends FutureTask<Void> {
QueueingFuture(RunnableFuture<V> task,
BlockingQueue<Future<V>> completionQueue) {
super(task, null);
this.task = task;
this.completionQueue = completionQueue;
}
private final Future<V> task;
private final BlockingQueue<Future<V>> completionQueue;
// 改写 FutureTask 的 done 方法,之后把 Executor 执行的计算结果放入 BlockingQueue 中
protected void done() {
completionQueue.add(task);
}
}
从代码可以看到,CompletionService 将提交的任务转化为 QueueingFuture,并且覆盖了done方法,在 done 方法中就是将任务加入任务队列中。
ExecutorService和CompletionService
在 Future 我们通过线程池 ExecutorService 的方式异步的方式用于并行执行任务,但存在的问题就是当向线程池提交任务后,从线程池得到一批 Future 对象集合,然后依次遍历调用其 get() 方法,而 get() 方法又是阻塞的,因此如果某个 Future 对象执行时间太长,由于阻塞导致无法及时从后面早已完成的 Future 当中取得结果。
CompletionService 之所以能做到一边生成任务,一边获取任务的返回值,就是因为它没有采取依次遍历 Future 的方式,而是在中间加上了一个结果队列,任务完成后马上将结果放入队列,那么从队列中取到的就是最早完成的结果。
性能优化实战
存在如下一个场景,某考试系统需要从题库中按照某些规则抽取部分题目并且生成大量的离线练习文档(PDF),一份 PDF 文档的生成过程如下:
- 分离出需要处理的题目(60~120 个,平均大约 80 个题目左右);
- 解析处理题目,对题目中的图片下载到本地,然后调用第三方工具生成 PDF 文档(耗时大约 3~10 秒);
- 将 PDF 文档上传到 OSS 云空间进行存储(耗时大约 1~3 秒);
- 提供文档地址让用户去下载打印。
按照上述规则那么生成一个 PDF 文档耗时在 4~13s之间,假设其平均值为8s。
那么生成 100 个文档就是 800s(约 13 分钟),1000 个文档就是 8000s(约 133 分钟,2.2小时),依次累加。
在我们的第一个版本中,为了项目上线,直接采用串行的方式,简单来说就是一个 for循环去进行操作。
模拟上述操作方法如下:
/**
* 根据需要的待处理文档信息
*/
public class PDFDocVO {
//待处理文档名称
private String docName;
// 省略其他
public String getDocName() {
return docName;
}
public void setDocName(String docName) {
this.docName = docName;
}
}
生成文档本地实际文档:
public class ProduceDocService {
/**
* 将待处理文档处理为本地实际文档
*
* @param doc
* @return
*/
public static String makePDF(PDFDocVO doc) throws InterruptedException {
// 用 sleep 模拟生成文档额耗时范围 3~10s
Random r = new Random();
Thread.sleep(3000 + r.nextInt(7000));
return "local" + doc.getDocName();
}
}
文件上传:
public class UploadDocService {
/**
* 模拟上传
*
* @param localName 实际文档在本地的存储位置
* @return oss 的文件路径
* @throws InterruptedException
*/
public static String upload(String localName) throws InterruptedException {
// 用 sleep 模拟生成文档额耗时范围 1~3s
Random r = new Random();
Thread.sleep(1000 + r.nextInt(2000));
return "https://aliyun.oss.xxx/file/" + localName;
}
}
串行
import java.util.ArrayList;
import java.util.List;
public class SerializeModel {
/**
* 符合条件的文档
*
* @param count
* @return
*/
public static List<PDFDocVO> getPDFDocList(int count) {
List<PDFDocVO> list = new ArrayList<>();
for (int i = 0; i < count; i++) {
PDFDocVO doc1 = new PDFDocVO();
list.add(doc1);
}
return list;
}
public static void main(String[] args) throws InterruptedException {
List<PDFDocVO> docList = getPDFDocList(10);
// 开始时间
long start = System.currentTimeMillis();
for (PDFDocVO doc : docList) {
// 生成文档
String localName = ProduceDocService.makePDF(doc);
// 上传文档
UploadDocService.upload(localName);
}
long total = System.currentTimeMillis() - start;
System.out.println("总耗时为:" + total / 1000 + "秒," + total / 1000 / 60 + "分钟");
}
}
测试结果如下:

测试 10 条任务,总耗时为 82s,即生成一个 PDF 文档平均耗时 82/10=8.2s。
并行
对于并行模式,通过上面对 Future 的了解(即 Future 的局限性 ),对于上面这个场景来说,生成文档和上传文档是有关联性的,如果想要生成文档和上传文档并行执行,上传文档则不知道本地文件是哪一个,因此单单通过 Future 是不能完成并行任务的,因此我们可以考虑使用 CompletionService,并行+异步的方式。
并行+异步
对于这个离线文档,每份文档的生成独立性是很高的,因此天生就适用于多线程并发进行,可以使用生产者消费者模式。
所以当接收到一个调用方的请求的时候,把请求解析出来的数据打包放入到一个阻塞队列中,然后会有多个线程进行消费处理,也就是生成每个具体文档。
当文档生成后,再使用一次生产者消费者模式,投入另一个阻塞队列,由另外的一组线程负责进行上传。当上传成功完成后,由上传线程返回文档的下载地址,表示当前文档已经成功完成。
注:这里不能直接使用线程池把任务提交给阻塞队列,一旦某个任务耗时太久,则后面的任务必须阻塞等到前面的任务完成,所以这里应该使用 CompletionService,即一旦有任务生成文档成功,就先获取执行上传。
代码实现:
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.CompletionService;
import java.util.concurrent.ExecutorCompletionService;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
/**
* TODO
*
* @date 2022/4/7 22:08
*/
public class ParallelAsyncModel {
// 线程池线程数
public final static int THREAD_COUNT = Runtime.getRuntime().availableProcessors();
// 处理文档生成的线程池 IO密集型任务
private static ExecutorService makeDocService = Executors.newFixedThreadPool(THREAD_COUNT * 2);
// 处理文档上传的线程池
private static ExecutorService uploadDocService = Executors.newFixedThreadPool(THREAD_COUNT * 2);
// 文档生成队列
private static CompletionService<String> makeDocCompletionService = new ExecutorCompletionService(makeDocService);
// 文档上传队列
private static CompletionService<String> uploadDocCompletionService = new ExecutorCompletionService(uploadDocService);
/**
* 符合条件的文档
*
* @param count
* @return
*/
public static List<PDFDocVO> getPDFDocList(int count) {
List<PDFDocVO> list = new ArrayList<>();
for (int i = 0; i < count; i++) {
PDFDocVO doc1 = new PDFDocVO();
list.add(doc1);
}
return list;
}
public static void main(String[] args) throws InterruptedException {
int count = 100;
List<PDFDocVO> docList = getPDFDocList(count);
// 开始时间
long start = System.currentTimeMillis();
// 多线程处理文档生成
for (PDFDocVO doc : docList) {
makeDocCompletionService.submit(new Callable<String>() {
@Override
public String call() throws Exception {
String localName = ProduceDocService.makePDF(doc);
return localName;
}
});
}
// 上传文档
for (int i = 0; i < count; i++) {
Future<String> take = makeDocCompletionService.take();
uploadDocCompletionService.submit(new Callable<String>() {
@Override
public String call() throws Exception {
String uploadUrl = UploadDocService.upload(take.get());
return uploadUrl;
}
});
}
long total = System.currentTimeMillis() - start;
System.out.println("总耗时为:" + total / 1000 + "秒," + total / 1000 / 60 + "分钟");
}
}
我们把任务数调成 100,测试结果如下:
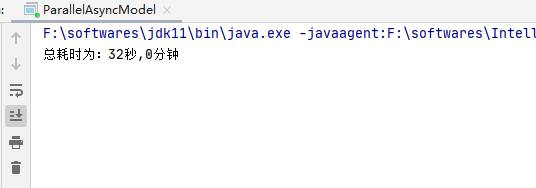
测试 100 条任务,总耗时为 32s,即生成一个 PDF 文档平均耗时 32/100=0.32s。
对比串行执行提高了8.2/0.32 ≈ 25 倍。
线程数的设置
对于线程池参数的设置我们通常遵守以下原则:
- IO 密集型任务,线程数为
CPU 核心数*2; - CPU 密集型任务,线程数为
CPU 核心数+1。
如果按照我们通用的 IO 密集型任务,两个线程池设置的都是机器的 CPU 核心数*2,但是这个就是最佳的吗?
实际上,通过反复试验发现,处理文档的线程池线程数设置为 CPU 核心数*4,继续提高线程数并不带来性能上的提升。
而因为我们改进后处理文档的时间和上传文档的时间基本在 1:4 到 1:3 的样子,所以处理文档的线程池线程数设置为 CPU 核心数*4*3。
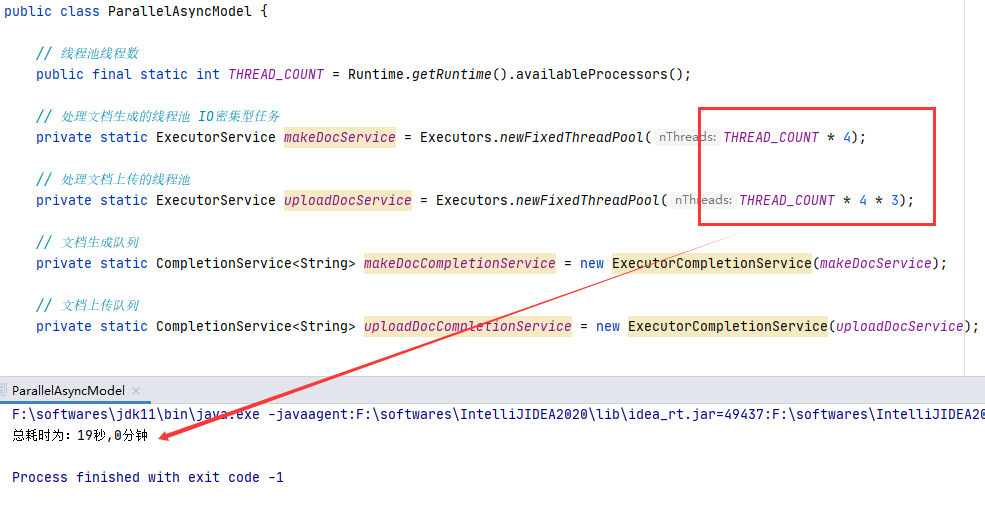
可以看到,由原来的 32s 减少为 19s。
因此,对于线程池的线程数来说,太少的线程数会使得程序整体性能降低,而过多的线程也会消耗内存等其他资源,所以如果想要更准确的话,可以进行压测,监控 JVM 的线程情况以及 CPU 的负载情况,根据实际情况衡量应该创建的线程数,合理并充分利用资源。
总结
对于Futrue 与 Callable
可以看到有返回结果的异步实现最终依赖 FutureTask,它同时实现了 Runnable 与 Future,拥有一个 Callable 属性。get 方法根据 FutureTask 的状态会把线程挂起并放到等待链表中了。
同时它可以被用到线程池中被执行,在线程池中最后会调用它的 run 方法,run 方法会调用 Callable 的 call 方法也就是真正计算的方法,返回结果后会修改 FutureTask 的状态并唤醒等待链表的线程。
线程池的 submit 方法还支持 Runnable 参数,但是 FutureTask 执行的是 Callable 的 call 方法,那么 Runnable 中的run 是怎么转换成 Callable 的 call 方法呢?
实际上也很简单,采用适配器模式,建一个 Callable 的子类 RunnableAdapter,它保存一个 Runnable 属性,RunnableAdapter 的 call 方法调用 Runnable 的 run 方法,至于返回的结果为 null 或者自己传一个结果。
所以要实现有返回结果的异步任务,要么实现 Callable 并实现 call 方法,或者创建一个 Runnable 的实现类也行。
对于CompletionServic
CompletionServic 提交任务利用的是线程池的提交,而他自己只创建了一个FutureTask的子类 QueueingFuture 用来实现 done 方法,在任务完成后把 FutureTask 添加到阻塞队列中。