文章目录
一、代码
以下代码提供了四种创建model的方式:其中包含两张使用 Sequential() 的方法,一种使用 keras API的方法,以及一种将 model 定义为 keras.Model 的子类的方法。
import tensorflow as tf
import tensorflow.keras as keras
def load_dataset():
(x_train, y_train), (x_valid, y_valid) = keras.datasets.mnist.load_data()
class_num = 10
assert x_train.shape == (60000, 28, 28)
assert x_valid.shape == (10000, 28, 28)
assert y_train.shape == (60000,) # 这里写成 (60000, 1)会报错
assert y_valid.shape == (10000,)
# 将数据归一化到0-1之间的浮点数
# y=tf.cast(x,dtype) 表示将x的数据类型转为 dtype类型,返回 y
x_train = tf.cast(x_train / 255, tf.float32)
x_valid = tf.cast(x_valid / 255, tf.float32)
y_train = tf.cast(y_train, tf.int64)
y_valid = tf.cast(y_valid, tf.int64)
return x_train, x_valid, y_train, y_valid, class_num
def bulid_model(x_train, class_num):
# 第一种创建模型的方法
model1 = keras.models.Sequential([
keras.layers.Flatten(input_shape=(x_train.shape[1], x_train.shape[2])), # input_shape=(28,28)
keras.layers.Dense(units=512, activation=tf.nn.relu),
keras.layers.Dropout(0.2),
keras.layers.Dense(class_num, activation=tf.nn.softmax)
])
# 第二种创建模型的方法
model2 = keras.models.Sequential()
model2.add(keras.layers.Flatten(input_shape=(x_train.shape[1], x_train.shape[2])))
model2.add(keras.layers.Dense(units=512, activation=tf.nn.relu))
model2.add(keras.layers.Dropout(0.2))
model2.add(keras.layers.Dense(class_num, activation=tf.nn.softmax))
# 第三种创建模型的方法
input = keras.Input(shape=(x_train.shape[1], x_train.shape[2]))
x = keras.layers.Flatten()(input)
x = keras.layers.Dense(units=512, activation=tf.nn.relu)(x)
x = keras.layers.Dropout(0.2)(x)
output = keras.layers.Dense(units=class_num, activation=tf.nn.softmax)(x)
model3 = keras.Model(inputs=input, outputs=output)
# 第四种创建模型的方法
class MnistModel(tf.keras.Model):
def __init__(self, num_classes=10):
super(MnistModel, self).__init__()
self.x0 = tf.keras.layers.Flatten()
self.x1 = tf.keras.layers.Dense(units=512, activation=tf.nn.relu)
self.x2 = tf.keras.layers.Dropout(0.2)
self.predictions = tf.keras.layers.Dense(units=10, activation=tf.nn.softmax)
def call(self, input):
x = self.x0(input)
x = self.x1(x)
x = self.x2(x)
return self.predictions(x)
model4 = MnistModel()
return model1, model2, model3, model4
def train(x_train, x_valid, y_train, y_valid, batch_size, epochs, model):
# 编译模型
# 采用 sparse_categorical_crossentropy 而不是 categorical_crossentropy 损失函数,可以直接传入int类型的label,而不需要one-hot类型
optimiser = keras.optimizers.Adam()
model.compile(optimizer=optimiser, loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 打印模型结构
# model.summary()必须要在模型编译之后才能执行,否则会报错 ”This model has not yet been built“
# 使用 model4时 model.summary() 只能在模型训练之后打印模型结构,不知道为什么。
print("model:")
model.summary()
# train
print("train:")
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs)
# valid
print("valid:")
model.evaluate(x_valid, y_valid)
def main(epochs, batch_size):
x_train, x_valid, y_train, y_valid, class_num = load_dataset()
model1, model2, model3, model4 = bulid_model(x_train, class_num)
# 这里修改使用的model类型
train(x_train, x_valid, y_train, y_valid, batch_size, epochs, model=model1)
if __name__ == '__main__':
epochs = 5
batch_size = 64
main(epochs, batch_size)
MnistModel 子类是在 bulid_model 函数中定义的,因此可以发现 python 可以在函数中定义和使用类。
二、模型结构
model1.summary()打印出的模型结构为:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense (Dense) (None, 512) 401920
_________________________________________________________________
dropout (Dropout) (None, 512) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 5130
=================================================================
Total params: 407,050
Trainable params: 407,050
Non-trainable params: 0
_________________________________________________________________
三、全连接层参数量计算
该模型没有卷积层,只有两个全连接层。全连接层示意图如下:
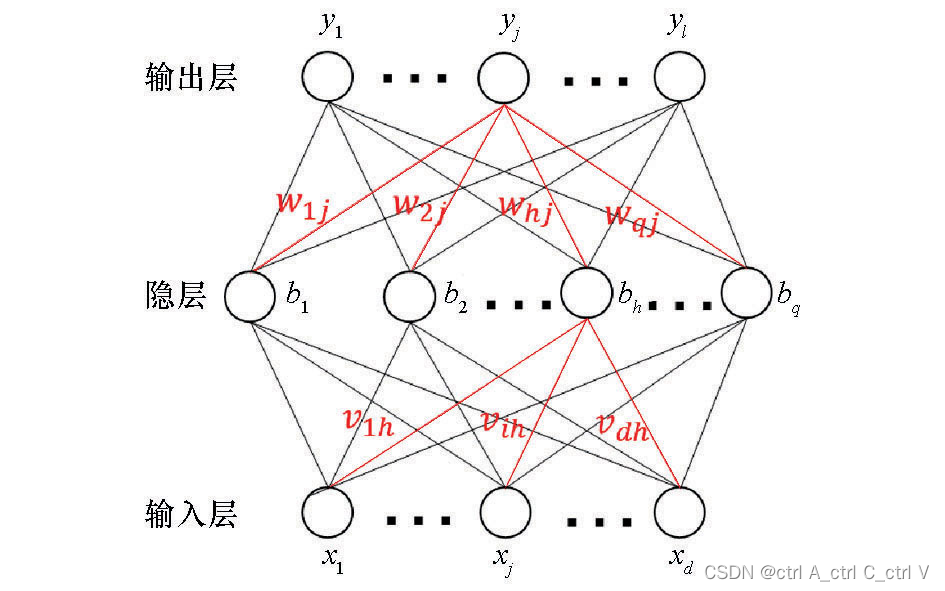
全连接层每两个神经元之间的连线都有一个权重w,但只有神经元本身才有偏置b

因此 flatten层和 dense层之间的权重数量为 784 * 512,dense层的偏置数量为512。则dense的参数量为 784*512+512=401920
同理,dense_1的参数量为 512 * 10+10=5130
四、训练和测试结果
train:
Epoch 1/5
938/938 [==============================] - 2s 2ms/step - loss: 0.2430 - accuracy: 0.9297
Epoch 2/5
938/938 [==============================] - 1s 2ms/step - loss: 0.1035 - accuracy: 0.9686
Epoch 3/5
938/938 [==============================] - 1s 1ms/step - loss: 0.0730 - accuracy: 0.9777
Epoch 4/5
938/938 [==============================] - 1s 2ms/step - loss: 0.0557 - accuracy: 0.9827
Epoch 5/5
938/938 [==============================] - 1s 1ms/step - loss: 0.0437 - accuracy: 0.9862
valid:
313/313 [==============================] - 0s 325us/step - loss: 0.0597 - accuracy: 0.9809
最终准确率为 98.09%