
社区开发者:LeoJie 介龙平
GitHub :CCweixiao
座右铭:心之所向,素履以往
目录
1.1 新建一个 maven 模块,并引入 ECP 的 maven 依赖

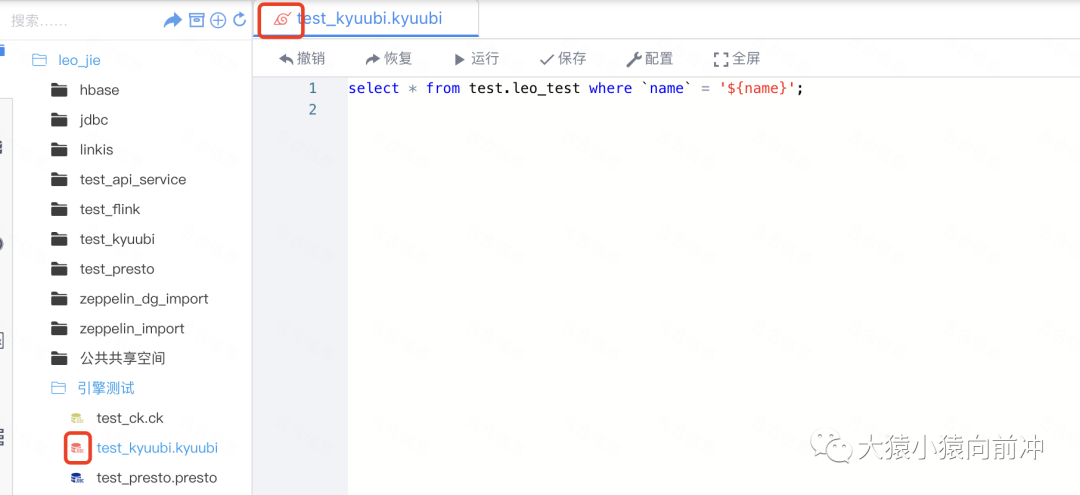
2.4 允许 Scripts 中打开 kyuubi 类型的脚本文件
2.7 Linkis 管理员台界面引擎管理器中加入新增引擎文字提示或图标
2.10 DSS Scripts 中新增脚本类型以及图标等信息
1. Linkis 新引擎功能代码实现
实现一个新的引擎其实就是实现一个新的 EngineConnPlugin(ECP)引擎插件。
具体步骤如下:
1.1 新建一个 maven 模块,并引入 ECP 的 maven 依赖

新引擎模块
<dependency>
<groupId>org.apache.linkis</groupId>
<artifactId>linkis-engineconn-plugin-core</artifactId>
<version>${linkis.version}</version>
</dependency>
<!-- 以及一些其他所需依赖的maven配置 -->1.2 实现 ECP 的主要接口
-
EngineConnPlugin:启动 EngineConn 时,先找到对应的 EngineConnPlugin 类,以此为入口,获取其它核心接口的实现,是必须实现的主要接口。
-
EngineConnFactory:实现如何启动一个引擎连接器,和如何启动一个引擎执行器的逻辑,是必须实现的接口。
实现 createEngineConn 方法:返回一个 EngineConn 对象,其中,getEngine 返回一个封装了与底层引擎连接信息的对象,同时包含 Engine 类型信息。
对于只支持单一计算场景的引擎,继承 SingleExecutorEngineConnFactory,实现 createExecutor,返回对应的 Executor。
对于支持多计算场景的引擎,需要继承 MultiExecutorEngineConnFactory,并为每种计算类型实现一个 ExecutorFactory。EngineConnPlugin 会通过反射获取所有的 ExecutorFactory,根据实际情况返回对应的 Executor。
-
EngineConnResourceFactory:用于限定启动一个引擎所需要的资源,引擎启动前,将以此为依 据 向 Linkis Manager 申 请 资 源。非必须,默认可以使用 GenericEngineResourceFactory。
-
EngineLaunchBuilder:用于封装 EngineConnManager 可以解析成启动命令的必要信息。非必须,可以直接继承 JavaProcessEngineConnLaunchBuilder。
1.3 实现引擎 Executor 执行器逻辑
Executor 为执行器,作为真正的计算场景执行器,是实际的计算逻辑执行单元,也是对引擎各种具体能力的抽象,提供加锁、访问状态、获取日志等多种不同的服务。并根据实际的使用需要,Linkis 默认提供以下的派生 Executor 基类,其类名和主要作用如下:
-
SensibleExecutor:
Executor 存在多种状态,允许 Executor 切换状态
Executor 切换状态后,允许做通知等操作
-
YarnExecutor:指 Yarn 类型的引擎,能够获取得到 applicationId 和 applicationURL 和队列。
-
ResourceExecutor:指引擎具备资源动态变化的能力,配合提供 requestExpectedResource 方法,用于每次希望更改资源时,先向 RM 申请新的资源;而 resourceUpdate 方法,用于每次引擎实际使用资源发生变化时,向 RM 汇报资源情况。
-
AccessibleExecutor:是一个非常重要的 Executor 基类。如果用户的 Executor 继承了该基类,则表示该 Engine 是可以被访问的。这里需区分 SensibleExecutor 的 state()和 AccessibleExecutor 的 getEngineStatus()方法:state()用于获取引擎状态,getEngineStatus()会获取引擎的状态、负载、并发等基础指标 Metric 数据。
-
同时,如果继承了 AccessibleExecutor,会触发 Engine 进程实例化多个 EngineReceiver 方法。EngineReceiver 用于处理 Entrance、EM 和 LinkisMaster 的 RPC 请求,使得该引擎变成了一个可被访问的引擎,用户如果有特殊的 RPC 需求,可以通过实现 RPCService 接口,进而实现与 AccessibleExecutor 通信。
-
ExecutableExecutor:是一个常驻型的 Executor 基类,常驻型的 Executor 包含:生产中心的 Streaming 应用、提交给 Schedulis 后指定要以独立模式运行的脚本、业务用户的业务应用等。
-
StreamingExecutor:Streaming 为流式应用,继承自 ExecutableExecutor,需具备诊断、do checkpoint、采集作业信息、监控告警的能力。
-
ComputationExecutor:是常用的交互式引擎 Executor,处理交互式执行任务,并且具备状态查询、任务 kill 等交互式能力。
1.4 引擎功能实现的实际案例
以下以 Hive 引擎为案例,说明各个接口的实现方式。
Hive 引擎是一个交互式引擎,因此在实现 Executor 时,继承了 ComputationExecutor,并做 了以下 maven 依赖的引入:
<dependency>
<groupId>org.apache.linkis</groupId>
<artifactId>linkis-computation-engineconn</artifactId>
<version>${linkis.version}</version>
</dependency>
作为 ComputationExecutor 的子类,HiveEngineConnExecutor 实现了 executeLine 方法,该方法接收一行执行语句,调用 Hive 的接口进行执行后,返回不同的 ExecuteResponse 表示成功或失败。同时在该方法中,通过参数 engineExecutorContext 中提供的接口,实现了结果集、日志和进度的传输。
Hive 的引擎是只需要执行 HQL 的 Executor,是一个单一执行器的引擎,因此,在定义HiveEngineConnFactory 时,继承的是 SingleExecutorEngineConnFactory,实现了以下两个接口:
-
createEngineConn:创建了一个包含 UserGroupInformation、SessionState 和 HiveConf 的对象,作为与底层引擎的连接信息的封装,set 到 EngineConn 对象中返回。
-
createExecutor:根据当前的引擎连接信息,创建一个 HiveEngineConnExecutor 执行器对象。
Hive 引擎是一个普通的 Java 进程,因此在实现 EngineConnLaunchBuilder 时,直接继承了 JavaProcessEngineConnLaunchBuilder。像内存大小、Java 参数和 classPath,可以通过配置进行调整,具体参考 EnvConfiguration 类。
Hive 引擎使用的是 LoadInstanceResource 资源,因此不需要实现 EngineResourceFactory,直接使用默认的 GenericEngineResourceFactory,通过配置调整资源的数量,具体参考 EngineConnPluginConf 类。
实现 HiveEngineConnPlugin,提供以上实现类的创建方法。
2. 以实际扩展引擎为例详解新引擎实现的后续步骤
本文以合合信息内部维护的 Linkis 分支中增加的 Kyuubi 引擎举例,补充说明用户在扩展新引擎时,除关注引擎本身的核心功能之外,还需要的一些额外的配置或修改。Kyuubi 引擎在 Linkis 的官方分支上还未支持,可以使用 jdbc 引擎来连接 kyuubi 服务执行对应脚本。
2.1 引擎代码准备
合合 Linkis 分支中 Kyuubi 引擎的代码实现比较简单,是对 JDBC 引擎模块的一个拷贝。不太一样的地方是,JDBC 引擎中的核心类JDBCEngineConnExecutor继承的抽象类是ConcurrentComputationExecutor,Kyuubi 引擎中的核心类KyuubiJDBCEngineConnExecutor继承的抽象类是ComputationExecutor。这导致两者最大的一个区别是:JDBC 引擎实例由管理员用户启动,被所有用户共享;而 Kyuubi 类型的脚本提交时,每个用户会各自启动一个引擎实例,用户间引擎实例互相隔离。其实针对 JDBC 类型的引擎,标准化的做法应该是使用并发引擎的特性,避免每个用户拉起一个引擎实例,以提高机器的资源利用率,这个在此处暂不细说,因为无论是并发引擎还是计算引擎,下文提到的额外修改流程应是一致的。
相应的,如果你新增的引擎是并发引擎,那么你需要关注下这个类:AMConfiguration.scala,如果你新增的引擎是计算类引擎,则可忽略。
object AMConfiguration {
// 如果你的引擎是多用户并发引擎,那么这个配置项需要关注下
val MULTI_USER_ENGINE_TYPES = CommonVars("wds.linkis.multi.user.engine.types", "jdbc,ck,es,io_file,appconn")
private def getDefaultMultiEngineUser(): String = {
// 此处应该是为了设置并发引擎拉起时的启动用户,默认jvmUser即是引擎服务Java进程的启动用户
val jvmUser = Utils.getJvmUser
s"""{jdbc:"$jvmUser", presto: "$jvmUser", kyuubi: "$jvmUser", es: "$jvmUser", ck:"$jvmUser", appconn:"$jvmUser", io_file:"root"}"""
}
}2.2 新引擎类型扩展
实现ComputationSingleExecutorEngineConnFactory接口的类KyuubiJDBCEngineConnFactory中,下面两个方法需要实现:
override protected def getEngineConnType: EngineType = EngineType.KYUUBI
override protected def getRunType: RunType = RunType.KYUUBI因此需要在 EngineType 和 RunType 中增加 Kyuubi 对应的变量。
// EngineType中类似已存在引擎的变量定义,增加Kyuubi相关变量或代码
object EngineType extends Enumeration with Logging {
val KYUUBI = Value("kyuubi")
}
def mapStringToEngineType(str: String): EngineType = str match {
case _ if KYUUBI.toString.equalsIgnoreCase(str) => KYUUBI
}
// RunType中
object RunType extends Enumeration {
val KYUUBI = Value("kyuubi")
}2.3 Kyuubi 引擎标签中的版本号设置
// 在LabelCommonConfig中增加kyuubi的version配置
public class LabelCommonConfig {
public final static CommonVars<String> KYUUBI_ENGINE_VERSION = CommonVars.apply("wds.linkis.kyuubi.engine.version", "1.4");
}
// 在EngineTypeLabelCreator的init方法中补充kyuubi的匹配逻辑
// 如果这一步不做,代码提交到引擎上时,引擎标签信息中会缺少版本号
public class EngineTypeLabelCreator {
private static void init() {
defaultVersion.put(EngineType.KYUUBI().toString(), LabelCommonConfig.KYUUBI_ENGINE_VERSION.getValue());
}
}2.4 允许 Scripts 中打开 kyuubi 类型的脚本文件
在 fileType 数组中增加新引擎脚本类型,如果不加,Scripts 文件列表中不允许打开新引擎的脚本类型
// FileSource.scala中
object FileSource {
private val fileType = Array("......", "kyuubi")
}2.5 配置 kyuubi 脚本变量存储和解析
如果这个操作不做,新增引擎 kyuubi 的脚本中变量不能被存储和解析,脚本中直接使用${变量}时代码会执行失败!

在 Linkis-1.0.3 版本之前:
// QLScriptCompaction.scala
class QLScriptCompaction private extends CommonScriptCompaction{
override def belongTo(suffix: String): Boolean = {
suffix match {
...
case "kyuubi" => true
case _ => false
}
}
}
// QLScriptParser.scala
class QLScriptParser private extends CommonScriptParser {
override def belongTo(suffix: String): Boolean = {
suffix match {
case "kyuubi" => true
case _ => false
}
}
}
// CustomVariableUtils.scala中
object CustomVariableUtils extends Logging {
def replaceCustomVar(jobRequest: JobRequest, runType: String): (Boolean, String) = {
runType match {
......
case "hql" | "sql" | "fql" | "jdbc" | "hive"| "psql" | "presto" | "ck" | "kyuubi" => codeType = SQL_TYPE
case _ => return (false, code)
}
}
}在 Linkis-1.1.2 版本之后:
// 通过CodeAndRunTypeUtils工具类中的CODE_TYPE_AND_RUN_TYPE_RELATION变量来维护codeType和runType间的对应关系
val CODE_TYPE_AND_RUN_TYPE_RELATION = CommonVars("wds.linkis.codeType.runType.relation", "sql=>sql|hql|jdbc|hive|psql|fql|kyuubi,python=>python|py|pyspark,java=>java,scala=>scala,shell=>sh|shell")参考 PR:https://github.com/apache/incubator-linkis/pull/2047
2.6 ujes.client 中增加新引擎类型
/ JobExecuteAction.scala中
object EngineType {
......
val KYUUBI = new EngineType {
override val toString: String = "kyuubi"
val KYUUBI_RunType = new RunType {
override val toString: String = "kyuubi"
}
override def getDefaultRunType: RunType = KYUUBI_RunType
}
}
// UJESClientUtils.scala中
object UJESClientUtils {
def toEngineType(engineType: String): EngineType = engineType match {
......
case "kyuubi" => EngineType.KYUUBI
case _ => EngineType.SPARK
}
def toRunType(runType:String, engineType: EngineType) : RunType = runType match {
......
case "kyuuubi" => EngineType.KYUUBI.KYUUBI_RunType
case _ => EngineType.SPARK.SQL
}
}客户端 API 运行新引擎类型脚本时所需。
2.7 Linkis 管理员台界面引擎管理器中加入新增引擎文字提示或图标
web/src/dss/module/resourceSimple/engine.vue
methods: {
calssifyName(params) {
switch (params) {
case 'kyuubi':
return 'Kyuubi';
......
}
}
// 图标过滤
supportIcon(item) {
const supportTypes = [
......
{ rule: 'kyuubi', logo: 'fi-kyuubi' },
];
}
}最终呈现给用户的效果:
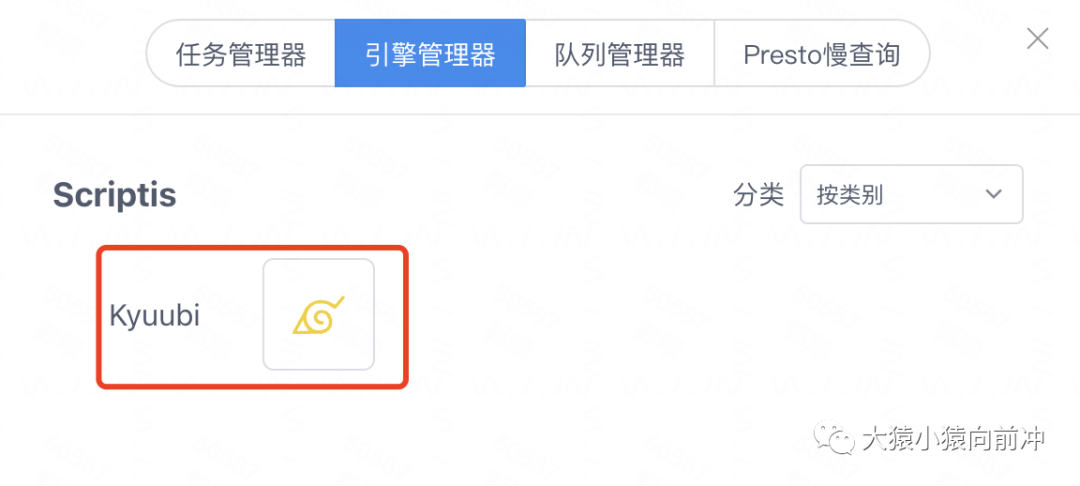
2.8 引擎的编译打包和安装部署
新引擎模块编译的示例命令如下:
cd /Users/leojie/intsig_project/intsiglinkis/linkis-engineconn-plugins/engineconn-plugins/kyuubi
mvn clean install -DskipTests编译完整项目时,新增引擎默认不会加到最终的 tar.gz 压缩包中,如果需要,请修改如下文件:
assembly-combined-package/assembly-combined/src/main/assembly/assembly.xml
<!--kyuubi-->
<fileSets>
......
<fileSet>
<directory>
../../linkis-engineconn-plugins/engineconn-plugins/kyuubi/target/out/
</directory>
<outputDirectory>lib/linkis-engineconn-plugins/</outputDirectory>
<includes>
<include>**/*</include>
</includes>
</fileSet>
</fileSets>然后对在项目根目录运行编译命令:
mvn clean install -DskipTests编译成功后在 assembly-combined-package/target/apache-linkis-1.x.x-incubating-bin.tar.gz 和 linkis-engineconn-plugins/engineconn-plugins/kyuubi/target/目录下找到 out.zip。
上传 out.zip 文件到 Linkis 的部署节点,解压缩到:安装目录/lib/linkis-engineconn-plugins/:

解压后别忘记删除 out.zip,至此引擎编译和安装完成。
2.9 引擎数据库配置
引擎安装完之后,要想运行新的引擎代码,还需对引擎进行数据库配置,以 Kyuubi 引擎为例,按照你自己实现的新引擎的情况,请按需修改。
SQL 参考如下:
SET @KYUUBI_LABEL="kyuubi-1.4";
SET @KYUUBI_ALL=CONCAT('*-*,',@KYUUBI_LABEL);
SET @KYUUBI_IDE=CONCAT('*-IDE,',@KYUUBI_LABEL);
SET @KYUUBI_NODE=CONCAT('*-nodeexecution,',@KYUUBI_LABEL);
-- kyuubi
INSERT INTO `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.rm.instance', '范围:1-20,单位:个', 'kyuubi引擎最大并发数', '2', 'NumInterval', '[1,20]', '0', '0', '1', '队列资源', 'kyuubi');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.kyuubi.jdbc.connect.url', '例如:jdbc:hive2://127.0.0.1:10000', 'jdbc连接地址', '\"jdbc:hive2://127.0.0.1:10009/;[email protected]\"', 'None', '', '0', '0', '1', '数据源配置', 'kyuubi');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.kyuubi.jdbc.version', '取值范围:jdbc3,jdbc4', 'jdbc版本','jdbc4', 'OFT', '[\"jdbc3\",\"jdbc4\"]', '0', '0', '1', '数据源配置', 'kyuubi');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.kyuubi.jdbc.connect.max', '范围:1-20,单位:个', 'jdbc引擎最大连接数', '10', 'NumInterval', '[1,20]', '0', '0', '1', '数据源配置', 'kyuubi');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.kyuubi.jdbc.auth.type', '取值范围:SIMPLE,USERNAME,KERBEROS', 'jdbc认证方式', 'KERBEROS', 'OFT', '[\"SIMPLE\",\"USERNAME\",\"KERBEROS\"]', '0', '0', '1', '用户配置', 'kyuubi');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.kyuubi.jdbc.username', 'username', '数据库连接用户名', '', 'None', '', '0', '0', '1', '用户配置', 'kyuubi');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.kyuubi.jdbc.password', 'password', '数据库连接密码', '', 'None', '', '0', '0', '1', '用户配置', 'kyuubi');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.kyuubi.jdbc.principal', '例如:hadoop/[email protected]', '用户principal', 'hadoop/[email protected]', 'None', '', '0', '0', '1', '用户配置', 'kyuubi');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.kyuubi.jdbc.keytab.location', '例如:/data/keytab/hadoop.keytab', '用户keytab文件路径', '/data/keytab/hadoop.keytab', 'None', '', '0', '0', '1', '用户配置', 'kyuubi');
insert into `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.kyuubi.jdbc.proxy.user.property', '例如:hive.server2.proxy.user', '用户代理配置', 'hive.server2.proxy.user', 'None', '', '0', '0', '1', '用户配置', 'kyuubi');
INSERT INTO `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.engineconn.java.driver.cores', '取值范围:1-8,单位:个', 'kyuubi引擎初始化核心个数', '1', 'NumInterval', '[1,8]', '0', '0', '1', 'kyuubi引擎设置', 'kyuubi');
INSERT INTO `linkis_ps_configuration_config_key` (`key`, `description`, `name`, `default_value`, `validate_type`, `validate_range`, `is_hidden`, `is_advanced`, `level`, `treeName`, `engine_conn_type`) VALUES ('wds.linkis.engineconn.java.driver.memory', '取值范围:1-8,单位:G', 'kyuubi引擎初始化内存大小', '1g', 'Regex', '^([1-8])(G|g)$', '0', '0', '1', 'kyuubi引擎设置', 'kyuubi');
insert into `linkis_cg_manager_label` (`label_key`, `label_value`, `label_feature`, `label_value_size`, `update_time`, `create_time`) VALUES ('combined_userCreator_engineType',@KYUUBI_ALL, 'OPTIONAL', 2, now(), now());
insert into `linkis_ps_configuration_key_engine_relation` (`config_key_id`, `engine_type_label_id`)
(select config.id as `config_key_id`, label.id AS `engine_type_label_id` FROM linkis_ps_configuration_config_key config INNER JOIN linkis_cg_manager_label label ON config.engine_conn_type = 'kyuubi' and label_value = @KYUUBI_ALL);
insert into `linkis_cg_manager_label` (`label_key`, `label_value`, `label_feature`, `label_value_size`, `update_time`, `create_time`) VALUES ('combined_userCreator_engineType',@KYUUBI_IDE, 'OPTIONAL', 2, now(), now());
insert into `linkis_cg_manager_label` (`label_key`, `label_value`, `label_feature`, `label_value_size`, `update_time`, `create_time`) VALUES ('combined_userCreator_engineType',@KYUUBI_NODE, 'OPTIONAL', 2, now(), now());
select @label_id := id from linkis_cg_manager_label where `label_value` = @KYUUBI_IDE;
insert into linkis_ps_configuration_category (`label_id`, `level`) VALUES (@label_id, 2);
select @label_id := id from linkis_cg_manager_label where `label_value` = @KYUUBI_NODE;
insert into linkis_ps_configuration_category (`label_id`, `level`) VALUES (@label_id, 2);
-- jdbc default configuration
insert into `linkis_ps_configuration_config_value` (`config_key_id`, `config_value`, `config_label_id`) (select `relation`.`config_key_id` AS `config_key_id`, '' AS `config_value`, `relation`.`engine_type_label_id` AS `config_label_id` FROM linkis_ps_configuration_key_engine_relation relation INNER JOIN linkis_cg_manager_label label ON relation.engine_type_label_id = label.id AND label.label_value = @KYUUBI_ALL);如果想重置引擎的数据库配置数据,参考文件如下,请按需进行修改使用:
-- 清除kyuubi引擎的初始化数据
SET @KYUUBI_LABEL="kyuubi-1.4";
SET @KYUUBI_ALL=CONCAT('*-*,',@KYUUBI_LABEL);
SET @KYUUBI_IDE=CONCAT('*-IDE,',@KYUUBI_LABEL);
SET @KYUUBI_NODE=CONCAT('*-nodeexecution,',@KYUUBI_LABEL);
delete from `linkis_ps_configuration_config_value` where `config_label_id` in
(select `relation`.`engine_type_label_id` AS `config_label_id` FROM `linkis_ps_configuration_key_engine_relation` relation INNER JOIN `linkis_cg_manager_label` label ON relation.engine_type_label_id = label.id AND label.label_value = @KYUUBI_ALL);
delete from `linkis_ps_configuration_key_engine_relation`
where `engine_type_label_id` in
(select label.id FROM `linkis_ps_configuration_config_key` config
INNER JOIN `linkis_cg_manager_label` label
ON config.engine_conn_type = 'kyuubi' and label_value = @KYUUBI_ALL);
delete from `linkis_ps_configuration_category`
where `label_id` in (select id from `linkis_cg_manager_label` where `label_value` in (@KYUUBI_IDE, @KYUUBI_NODE));
delete from `linkis_ps_configuration_config_key` where `engine_conn_type` = 'kyuubi';
delete from `linkis_cg_manager_label` where `label_value` in (@KYUUBI_ALL, @KYUUBI_IDE, @KYUUBI_NODE);最终的效果:

这样配置完之后,linkis-cli 以及 Scripts 提交引擎脚本时,才能正确匹配到引擎的标签信息和数据源的连接信息,然后才能拉起你新加的引擎。
2.10 DSS Scripts 中新增脚本类型以及图标等信息
如果你使用到了 DSS 的 Scripts 功能,还需要对 dss 项目中 web 的前端文件进行一些小小的改动,改动的目的是为了在 Scripts 中支持新建、打开、执行新引擎脚本类型,以及实现引擎对应的图标、字体等。
2.10.1 scriptis.js
web/src/common/config/scriptis.js
{
rule: /\.kyuubi$/i,
// 语法高亮
lang: 'hql',
// 是否可执行
executable: true,
// application
application: 'kyuubi',
// 运行类型
runType: 'kyuubi',
// 脚本扩展名
ext: '.kyuubi',
// 脚本类型
scriptType: 'kyuubi',
abbr: 'kyuubi',
// 图标
logo: 'fi-kyuubi',
// 配色
color: '#FF6666',
// 是否可被新建
isCanBeNew: true,
label: 'Kyuubi',
// 是否可被打开
isCanBeOpen: true,
// 工作流类型
flowType: 'kyuubi'
},2.10.2 脚本复制支持
web/src/apps/scriptis/module/workSidebar/workSidebar.vue
copyName() {
let typeArr = ['......', 'kyuubi']
}2.10.3 logo 与字体配色
web/src/apps/scriptis/module/workbench/title.vue
data() {
return {
isHover: false,
iconColor: {
'fi-kyuubi': '#FF6666',
},
};
},web/src/apps/scriptis/module/workbench/modal.js
let logoList = [
{ rule: /\.kyuubi$/i, logo: 'fi-kyuubi' },
];web/src/components/tree/support.js
export const supportTypes = [
// 这里大概没用到
{ rule: /\.kyuubi$/i, logo: 'fi-kyuubi' },
]引擎图标展示
web/src/dss/module/resourceSimple/engine.vue
methods: {
calssifyName(params) {
switch (params) {
case 'kyuubi':
return 'Kyuubi';
......
}
}
// 图标过滤
supportIcon(item) {
const supportTypes = [
......
{ rule: 'kyuubi', logo: 'fi-kyuubi' },
];
}
}web/src/dss/assets/projectIconFont/iconfont.css
.fi-kyuubi:before {
content: "\e75e";
}此处控制的应该是:
找一个引擎图标的 svg 文件
web/src/components/svgIcon/svg/fi-kyuubi.svg
如果新引擎后续需要贡献社区,那么新引擎对应的 svg 图标、字体等需要确认其所属的开源协议,或获取其版权许可。
2.11 DSS 的工作流适配
最终达成的效果:

在 dss_workflow_node 表中保存新加 kyuubi 引擎的定义数据,参考 SQL:
# 引擎任务节点基本信息定义
insert into `dss_workflow_node` (`id`, `name`, `appconn_name`, `node_type`, `jump_url`, `support_jump`, `submit_to_scheduler`, `enable_copy`, `should_creation_before_node`, `icon`) values('18','kyuubi','-1','linkis.kyuubi.kyuubi',NULL,'1','1','1','0','svg文件');
# svg文件对应新引擎任务节点图标
# 引擎任务节点分类划分
insert into `dss_workflow_node_to_group`(`node_id`,`group_id`) values (18, 2);
# 引擎任务节点的基本信息(参数属性)绑定
INSERT INTO `dss_workflow_node_to_ui`(`workflow_node_id`,`ui_id`) VALUES (18,45);
# 在dss_workflow_node_ui表中定义了引擎任务节点相关的基本信息,然后以表单的形式在上图右侧中展示,你可以为新引擎扩充其他基础信息,然后自动被右侧表单渲染。web/src/apps/workflows/service/nodeType.js
import kyuubi from '../module/process/images/newIcon/kyuubi.svg';
const NODETYPE = {
......
KYUUBI: 'linkis.kyuubi.kyuubi',
}
const ext = {
......
[NODETYPE.KYUUBI]: 'kyuubi',
}
const NODEICON = {
[NODETYPE.KYUUBI]: {
icon: kyuubi,
class: {'kyuubi': true}
},
}在 web/src/apps/workflows/module/process/images/newIcon/目录下增加新引擎的图标
web/src/apps/workflows/module/process/images/newIcon/kyuubi.svg
同样贡献社区时,请考虑 svg 文件的 lincese 或版权。
3. 总结
上述内容记录了新引擎的实现流程,以及额外需要做的一些引擎配置。本文主要基于 Apache Linkis 1.0.3,对 1.1.x 之后的版本也应适用。目前,一个新引擎的扩展流程还是比较繁琐的,希望能在后续版本中,优化新引擎的扩展、以及安装等过程。
4. 附录:WeDataSphere介绍
WeDataSphere(以下简称WDS)是一套一站式、金融级、全连通、开源开放的大数据平台套件。目前WDS生态共开源了9个项目,分别为:
(1)Apache Linkis(incubating) 计算中间件,已入选Apache基金会作为顶级项目进行孵化;
(2)DataSphereStudio 一站式数据应用开发管理门户
(3)Qualitis 数据质量管理平台
(4)Schedulis 工作流任务调度系统
(5)Exchangis 数据交换平台
(6)Prophecis 一站式机器学习平台
(7)Scriptis 交互式数据分析 Web 工具
(8)Visualis 数据可视化工具
(9)Streamis 流式应用开发管理系统
WDS项目的沙箱环境试用企业超过1800家,自行搭建试用的企业超过800家,涉及到金融、互联网、通信、制造、教育等众多行业。
WDS社区在高速发展中,运营着10个微信社群和1个QQ群,覆盖了6000+的开发者,为社区贡献的Contributor超过150人。
