紧接 机器学习介绍(上),当 x 和 y 中间有比较复杂的关系时,对 Linear 的 Model 来说,x 跟 y 的关系就是一条直线,随著 x 越来越高,y 就应该越来越大,你可以设定不同的 w 改变这条线的斜率,也可以设定不同的 b 改变这一条蓝色的直线跟 y 轴的交叉点,但是无论你怎么改 w 跟 b ,它永远都是一条直线,永远都是 x 越大, y 就越大,前一天观看的人数越多,隔天的观看人数就越多。
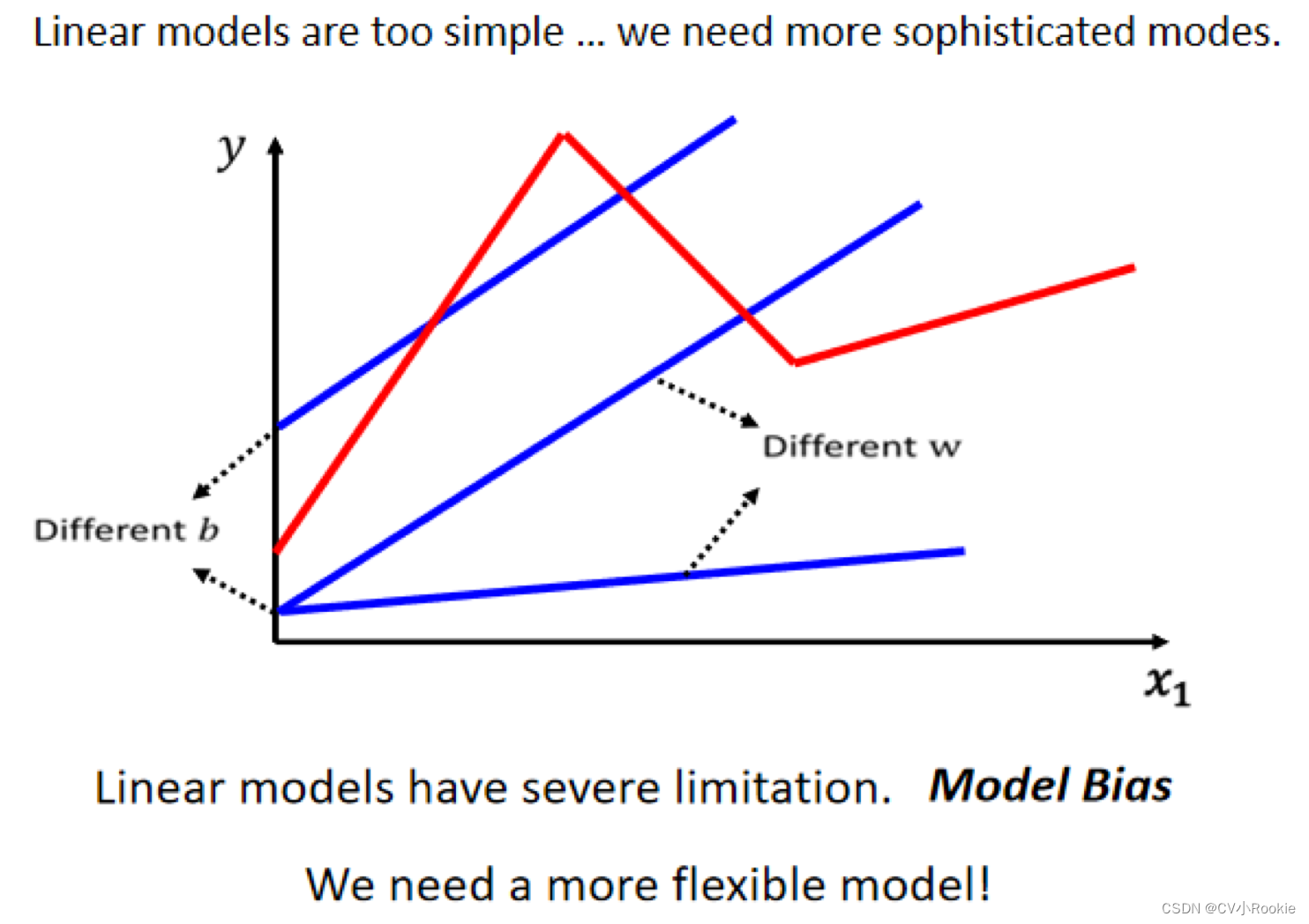
但是现实世界并不是这个样子,也许成正比,还有可能存在成反比的情况,比如周五周六大家都不想看学习视频,可是周一又要开始上课,那周日观看人次就会明显升高。所以仅仅是改变 w 和 b 是不会把蓝色曲线构造成红色曲线的样子。所以我们需要一个更复杂、更有弹性的含未知数函数。

蓝色 Function 替代之前的线性函数:
- 当输入的值,当 x 轴的值小于某一个阈值的时候,它是某一个定值;
- 大于另外一个阈值的时候又是另外一个定值;
- 中间有一个斜坡
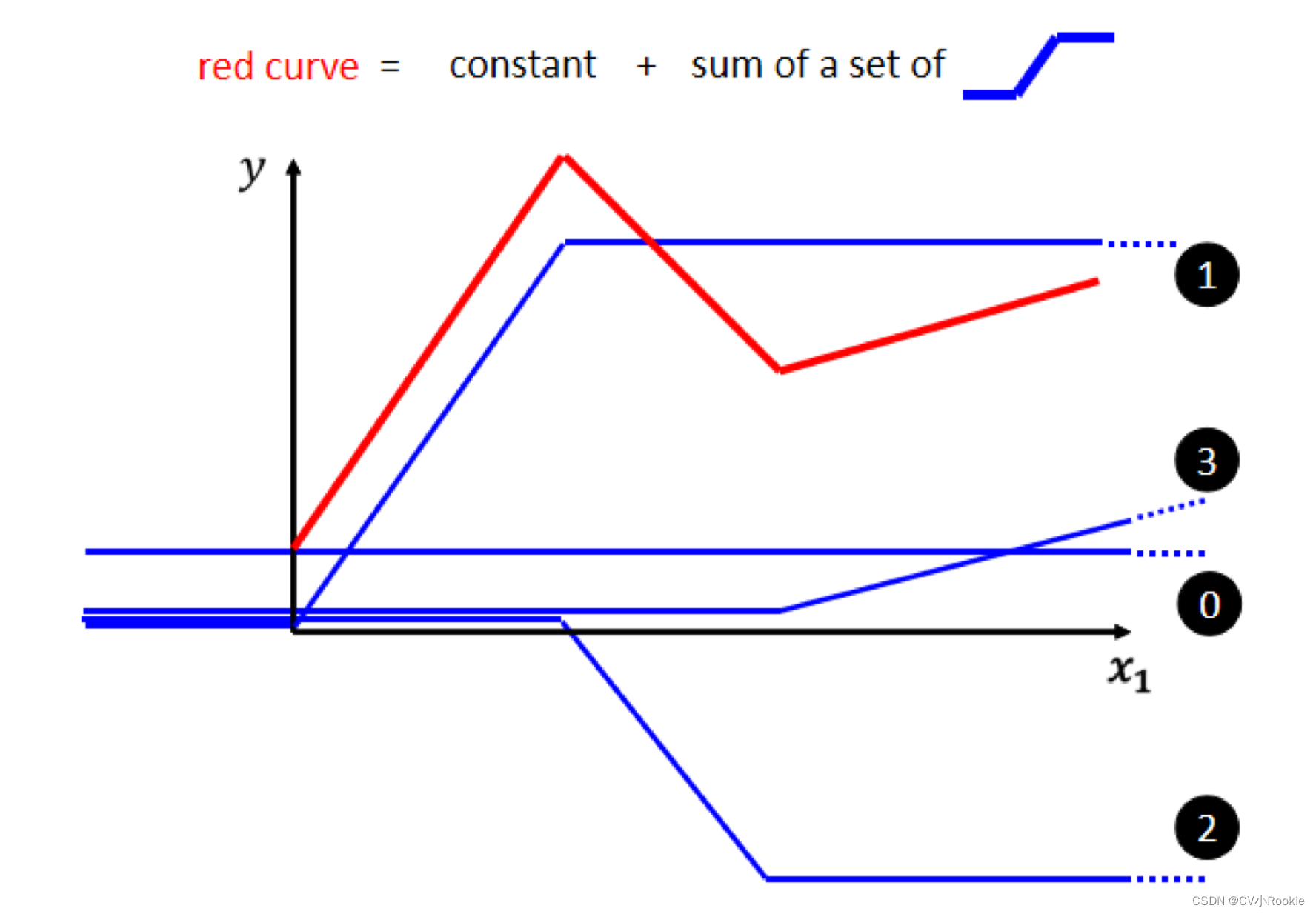
- 蓝色 Function “0” 是一条直线,是为了拟合红色 Function 的 bias(红线和 y 轴交界点)。
- 蓝色 Function “1” 是为了拟合红色 Function 的第一段上升。斜坡的起点设在红色 Function 的起始的地方,然后斜坡的终点设在第一个转角处。只需要调整 “1” 和红色的 Function 斜率一样即可。
- 蓝色 Function “2” 是为了拟合红色 Function 的下降段。“2” 的斜坡就在红色 Function 的第一个转折点到第二个转折点之间。
- 蓝色 Function “3” 是为了拟合第二段上升。起点在红色 Function 的第二个转折点,斜率与其保持一致。
通过上面设置不同的蓝色 Function,0+1+2+3 就可以拟合出红色 Function。
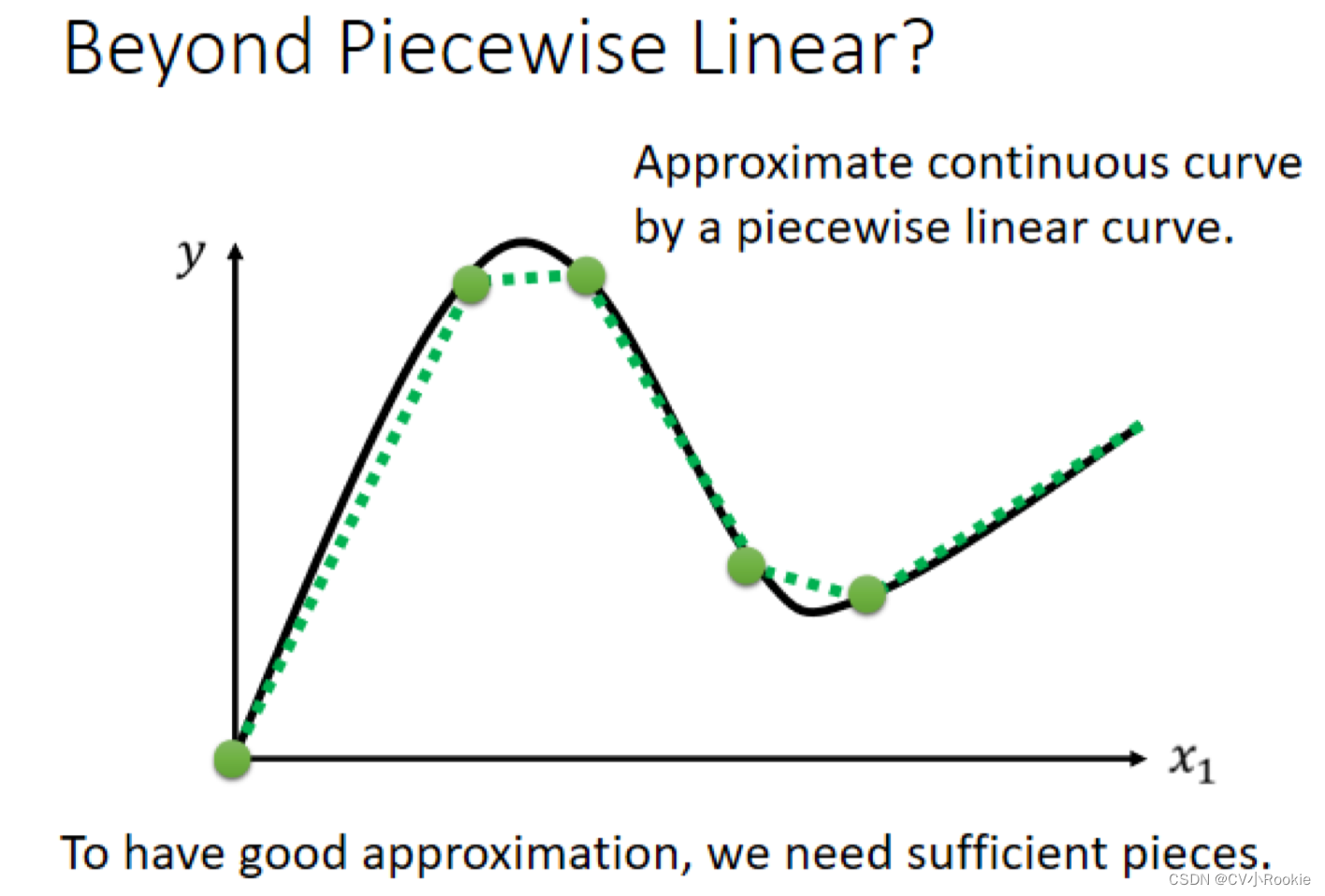
如果我们的目标函数不是一个折线段,而是一个曲线呢?没关系!可以在曲线上选择一定的采样点,只要采样点足够多,就可以近似曲线。所以只要蓝色 Function 足够多,就可以拟合出任意一个函数!
但是这个蓝色的折现好像不太容易去写出表达式,但是我们找到一个名为 Sigmoid Function 用来逼近蓝色折线(其实蓝色折线也有名字叫做 Hard Sigmoid)。
sigmoid:
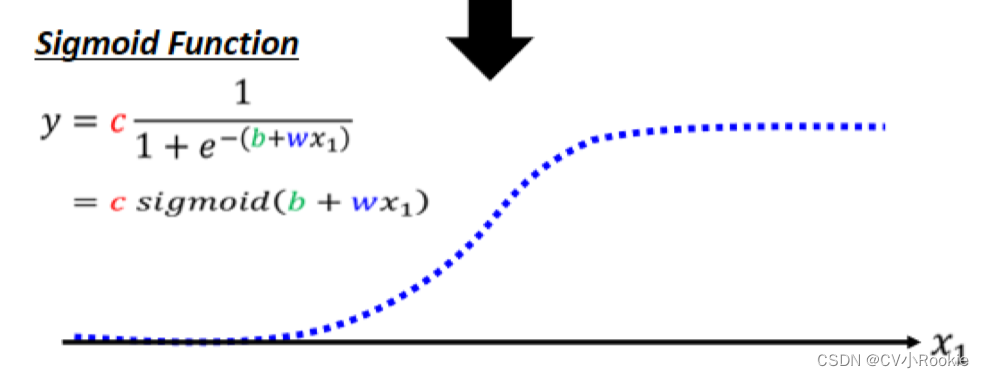
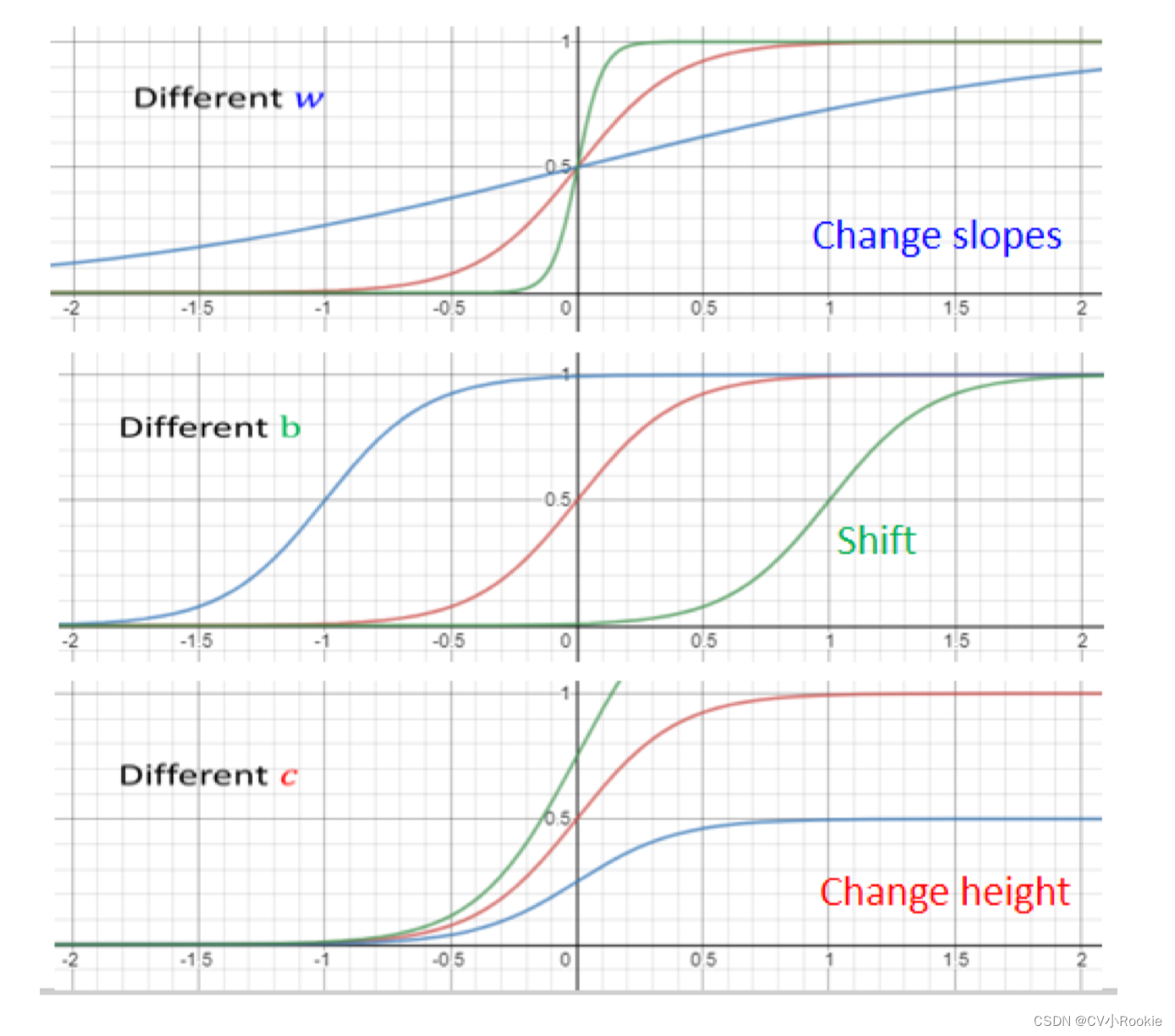
- 改变 w 就会改变斜率,改变斜坡的坡度
- 改变 b 就可以把这一个 Sigmoid Function 左右移动
- 改变 c 就可以改变它的高度
那么先前的红色 Function 就可以用 sigmoid 来拟合:
之前我们看到过使用多个 Feature 来代替一个 x 的函数预测更佳,所以我们可以改写 Function :
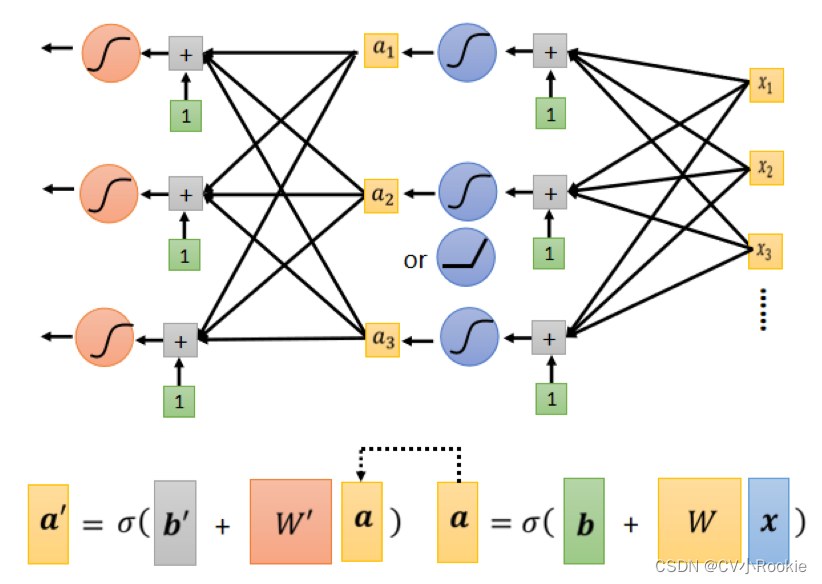
我们画一下图看一下 y 整个流程是怎样的,我们以 i=3,j=3 为例。
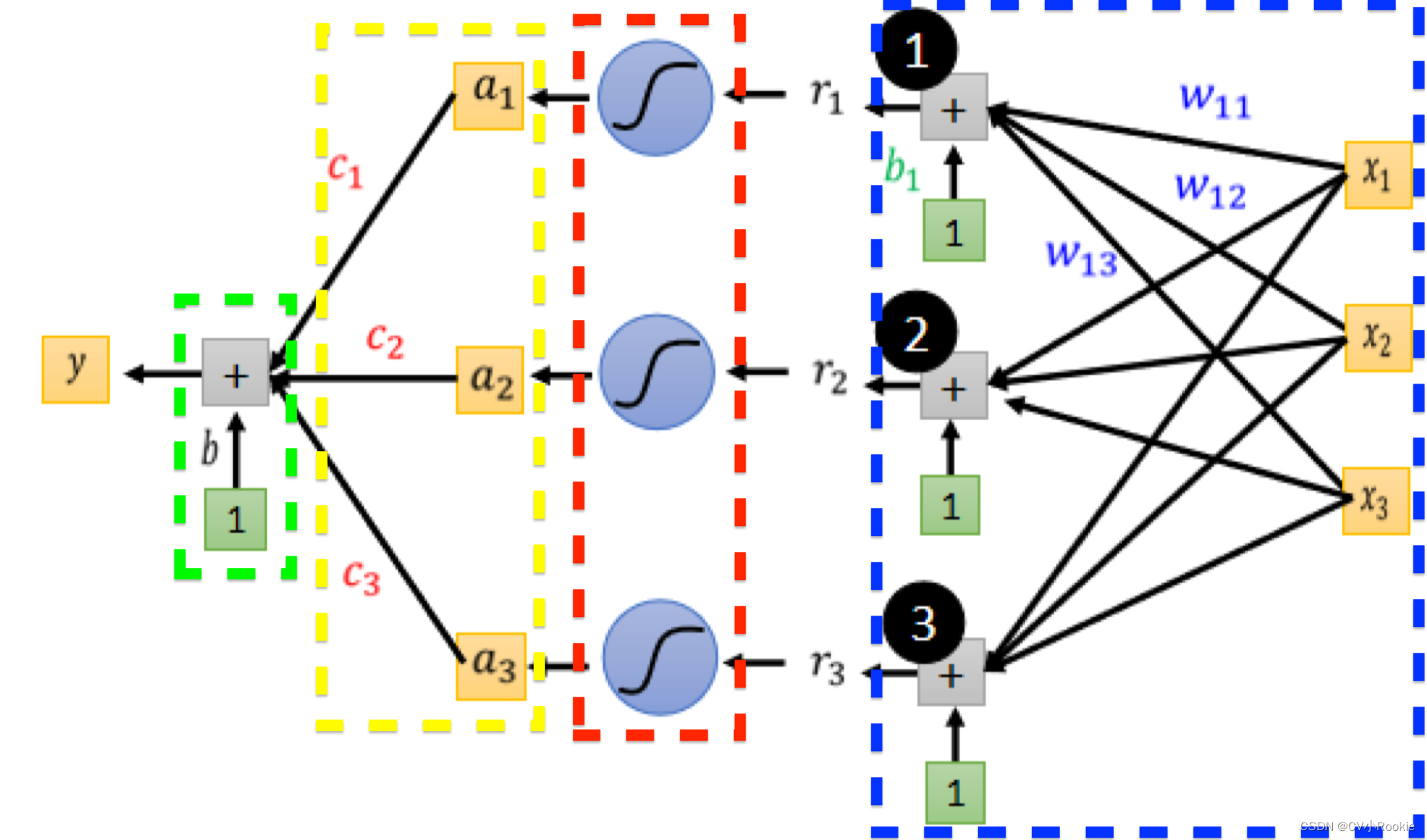
蓝色虚线框就是 部分,我们以 i=1为例:
。特别说明一下
下标 j 代表的是 feature,不要搞反(神经网络里 j 是 feature,i 是神经元节点)
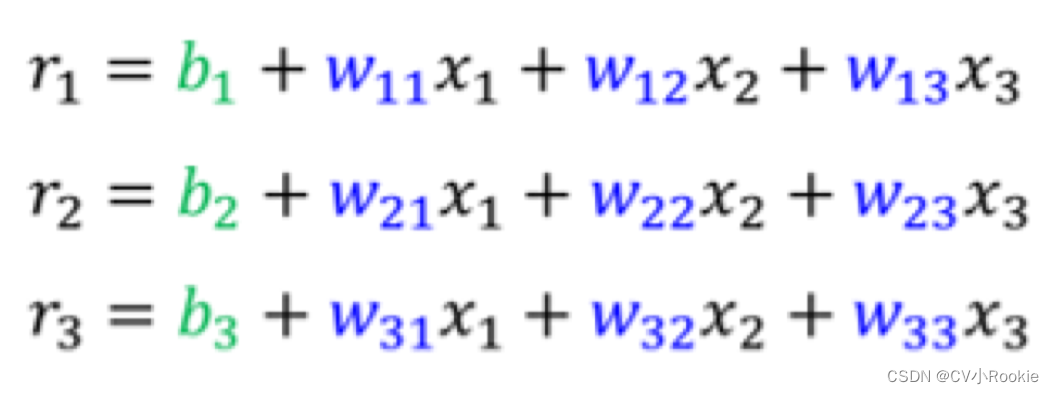
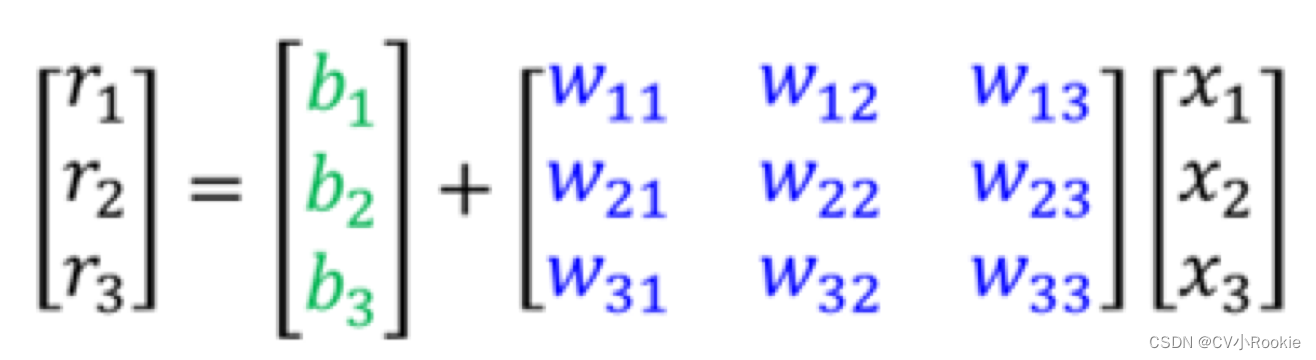
图左就是全部情况,图右是写成了矩阵与向量的形式。
红色虚线框是 sigmoid 部分: 。
黄色虚线框是 部分。
绿色虚线框就是最后bias 。


把这些矩阵和向量通通拉直,拼成一个很长的向量,这个向量包含所有未知参数,我们用 表示。
接下来定义我们的损失函数。之前损失函数是 ,现在我们统一用
表示。

Optimization 优化与机器学习介绍(上)最主要的区别就是多了几个参数,多了几个微分。

当训练数据比较大时,我们不太容易去计算所有资料的梯度。所以我们把训练数据分成一个个的 batch 。每一组有 B 笔资料,然后去计算每一个 batch 的 loss 去做梯度下降,更新参数。
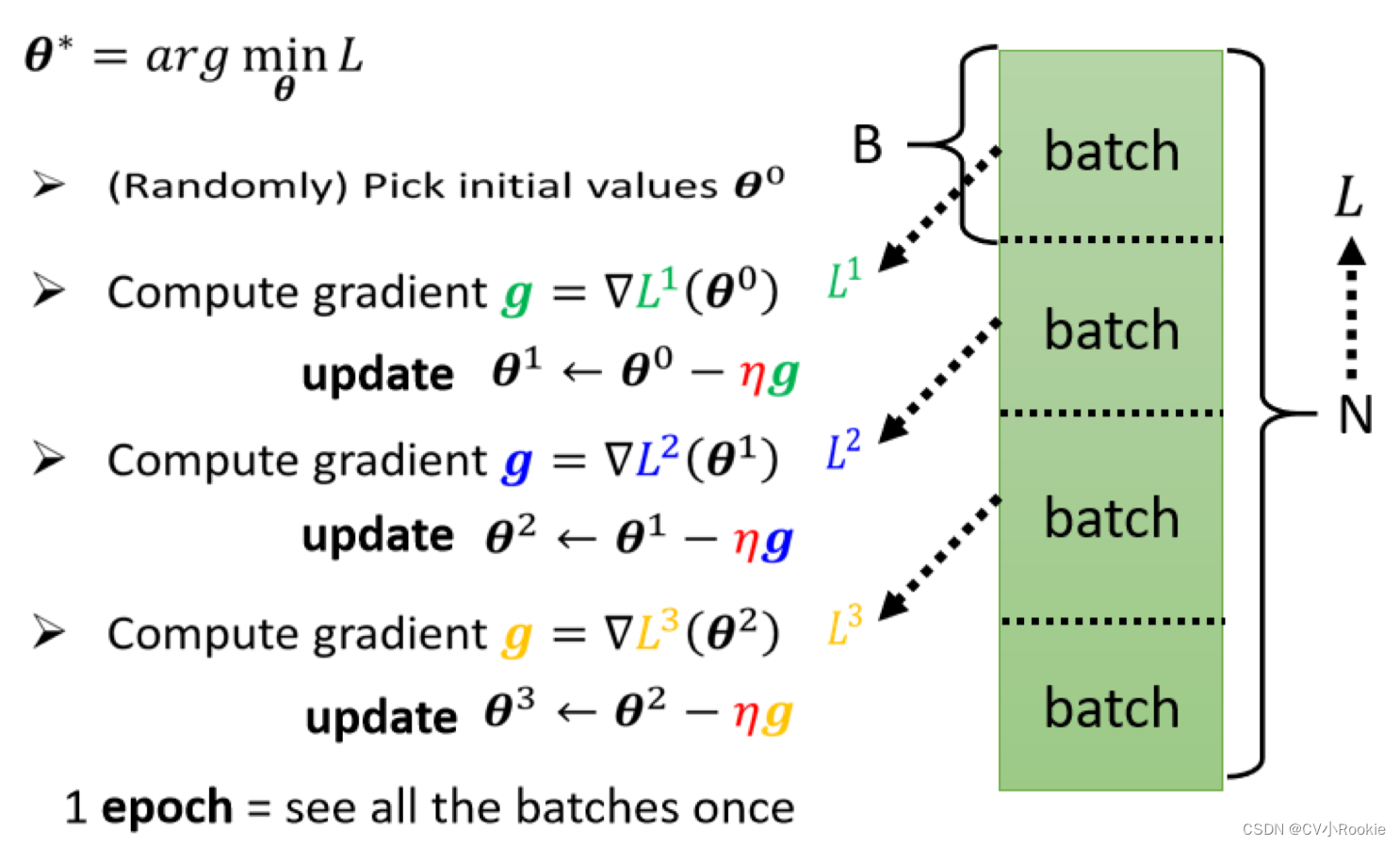
每训练一个 batch 称作一次 update 更新;所有的资料都训练一次叫做一次 epoch 。
模型变形
1. 改变激活函数,将 sigmoid 改为 ReLu(Rectified Linear Unit):

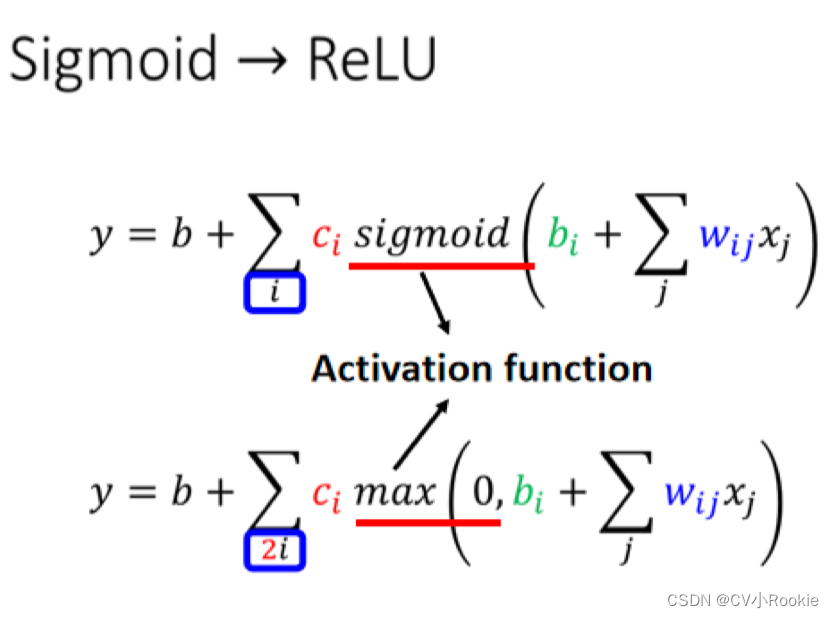
那本来只需要 i 个 Sigmoid,但是要 2 个 ReLU 才能够合成一个 Hard Sigmoid 。那这个 Sigmoid 或是 ReLU,它们在机器学习里面叫做 Activation Function 激活函数。
2. 加大模型,多做几次级联。把 x 做这一连串的运算产生 a ,接下来把 a 再做这一连串的运算产生 a’ 。那我们可以反覆地多做几次。要做几次,这又是另外一个 Hyper Parameter。
到目前为止,我们讲了很多各式各样的模型,那我们现在还缺了一个东西,缺一个好名字。
(李宏毅:你知道这个外表 啊是很重要的,一个死臭酸宅穿上西装以后就潮了起来,或者是隻鞋半缕的,说他是汉左将军宜城亭侯中山靖王之后,也就潮了起来 ,所以我们的模型也需要一个好名字)
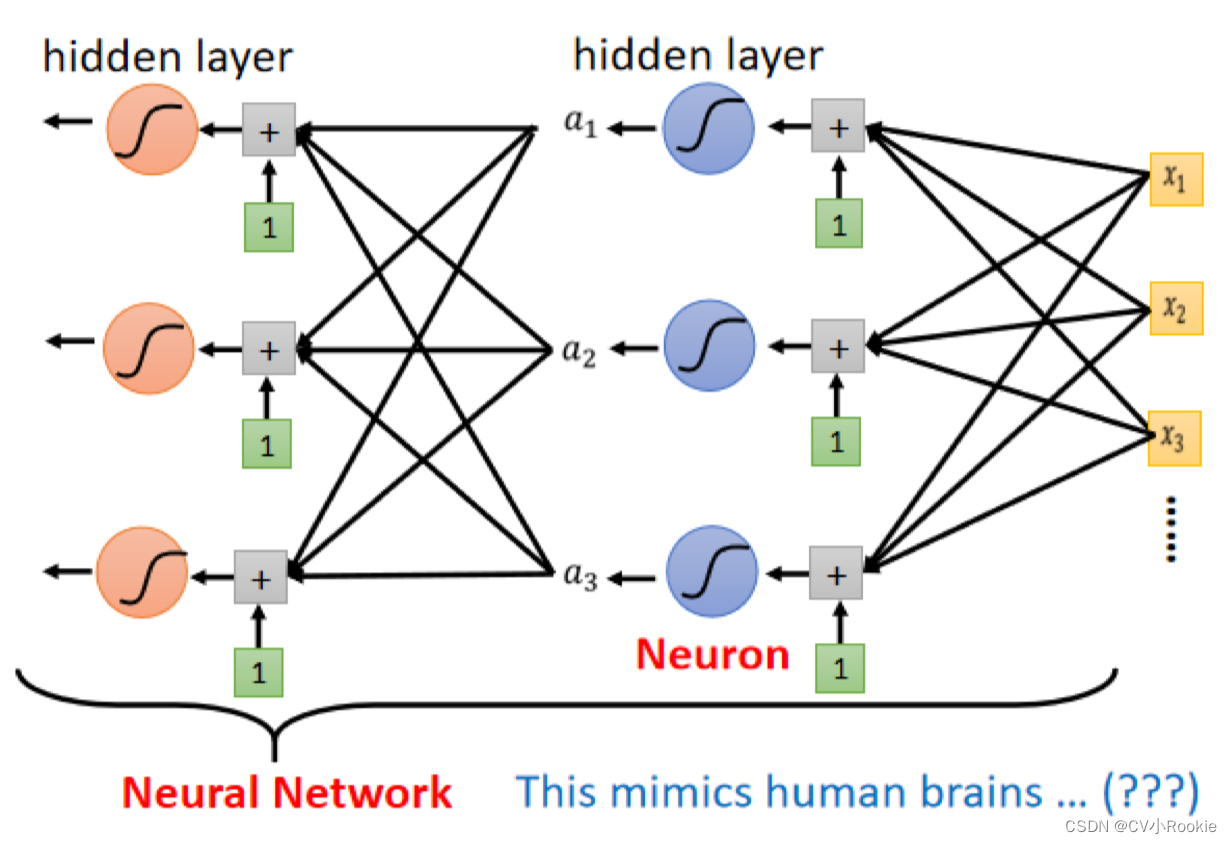
这些 Sigmoid 或 ReLU ,它们叫做 Neuron 神经元。我们这边有很多的 Neuron,很多的 Neuron 就叫做 Neural Network。
(李宏毅:接下来你 就可以到处骗麻瓜说,看到没有 这个模型就是在模拟人们脑 知道吗,这个就是在模拟人脑,这个就是人工智能,然后麻瓜就会吓得把钱掏出来)
神经网络分为三个部分:输入层也就是 feature ;隐藏层,中间的神经元网络;输出层;(一般说神经网络的层数是隐藏层个数 + 输出层个数)
Deep Learning 就是非常深的网络层数。现在的深度神经网络有很多,想要了解一些奠基性的模型可以看之前写过的 LeNet 、AlexNet 、VGGNet 、GoogLeNet