Q-learning是off-policy的,而Sarsa是on-policy的,但是它们的算法非常类似:

策略pi可以理解为和q相关,因此更新q就是更新pi
Sarsa更新的过程:
可以看出来,计算一个action value需要知道s,a,s’,a’四个数据,其中s,a是用来算reward,而s’,a’是用来估计下一个状态的state value。
比如A3/S3是在状态S3选择了A3,它作为下标用到了两次
- Q(A3, S3)在计算S2的action value的时候估计S3的state value
- 在计算S3的state value的时候,它又可以计算reward,即r(A3, S3)
下面是Q-learning更新的过程
可以看出Q-learning没有强制要求一个s,a对使用两次,而是通过别的策略再次生成了一个s,a对。
有人说Q-learning在估计state value的时候使用了max action,因此默认是最优策略,但是实际上的策略不是最优的,因此是off-policy的。
我觉得说的不对,因为Sarsa使用的是下一个state的action value来估计state value,但是下一个action的选择也倾向于选择action value最大的,因此和Q-learning也就是determistic和stomastic的区别。
换句话说,难道Sarsa在选择策略的时候不选择action value最大的吗?
我觉得Sarsa和Q-learning最大的不同在于Sarsa在算reward的这个s,a必须是上一次估计state value获得的s,a,而Q-learning则是可以任意的选择一个s,a。
简单来说:
- behavior policy就是如何选择一对s,a来估计reward
- target policy就是如何选择一对s,a来估计state value
- Sarsa要求behavior policy获得的s,a必须是上一次的target policy选择的s,a
- Q-learning 不对behavior policy做要求,因此第一个s,a可以用任意的策略选择,但是估计state value的s,a必须是用target policy来确定。
这就是我认为它们的不同。也就是获取了一个采样s,a以后,用它来计算了reward。如果说该采样是前一次估计state value时候选择的,那么就是on-policy的,如果说不是,那么就是off-policy的。
另外Q-learning也有on-policy的版本,就是也强制让Qc, Qd都相同,也就是说本轮用来计算reward的s,a一定是上轮最优的那个s,a。因此最开始的图片其实两者都是on-policy的。

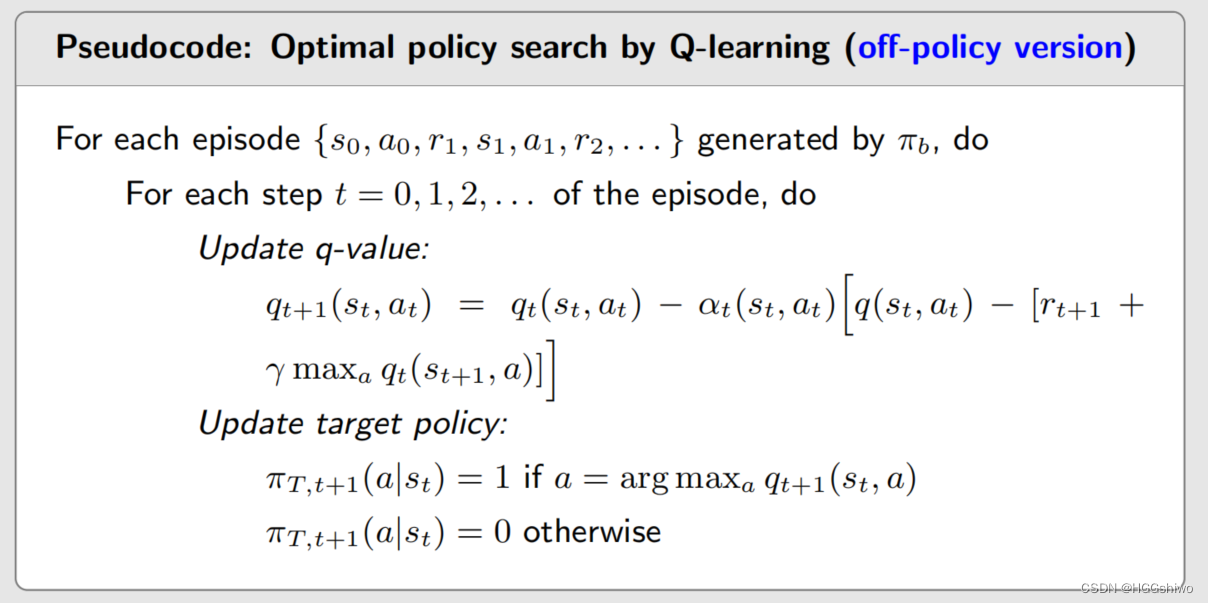
可以清晰的看出,用来计算r的s,a是不同的,一个是由pi t 生成的,一个是由当前策略生成的。而它们用来计算state value的s, a都是当前策略生成的。