linux内核内存管理
注意!内核空间和用户空间都是处于虚拟空间中
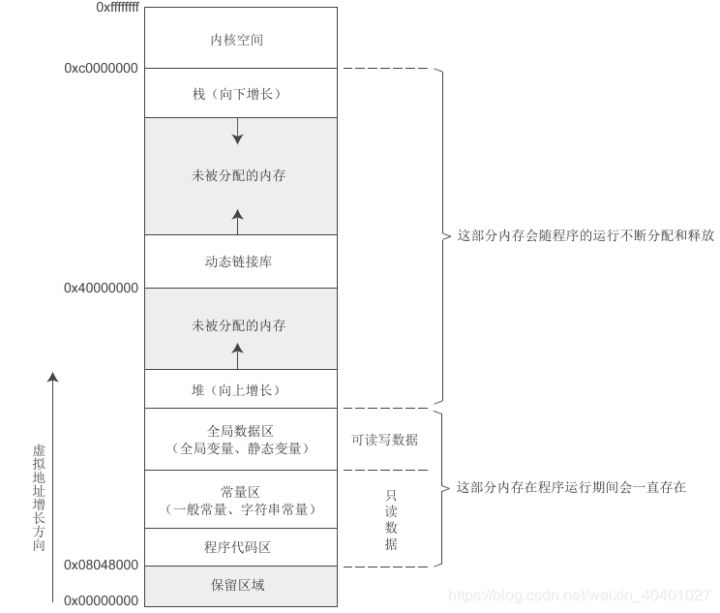
Linux的虚拟地址空间范围为0~4G,Linux内核将这4G字节的空间分为两部分
内核空间: 最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),而映射到物理内存中是从0x00000000地址开始
用户空间:较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF)(所有进程一起使用)
每个进程可以通过系统调用进入内核,所以Linux内核由系统内的所有进程共享。从具体进程的角度来看,每个进程可以拥有4G字节的虚拟空间。
内核态的内存管理和用户态的内存管理方式不一样点:
- 内核态虚拟地址到物理地址基本是直接映射,分配的物理内存是连续的(除vmalloc)。用户态会基于进程各自的页表,分配非连续的物理内存
- 内核态会直接依赖物理内存的管理因为物理内存中有一部分内存只能被内核访问。用户态则需要多一层的虚拟地址空间到物理地址的转换
现代的操作系统都处于32位保护模式下。每个进程一般都能寻址4G的物理空间。我们的物理内存一般都是几百M,但是通过虚拟内存技术即可使进程获得4G 的物理空间使用
内核对于物理内存管理主要包括以下几个概念:
- 分配大块内存的伙伴系统;
- 分配非连续内存块的vmalloc机制及内存映射机制;
- 分配小块内存的slab,slub和slob
32位内核内存空间分布图,64位不一样!
内核态空间分布 高地址 --> 低地址
ffff:ffff:ffff:ffff +--------------------------+
| |
| |
z z
| |
| |
ffff:ffc0:b000:0000 |--------------------------|
| |
| memory (2.75G) |
| |
ffff:ffc0:0000:0000 +==========================+ <-- PAGE_OFFSET
| |
| |
| |
| vmemmap (4G) |
| +----------------------+ |
| | actual (44M) | |
ffff:ffbf:0000:0000 +--------------------------+
|//|
ffff:ffbe:ffe0:0000 +--------------------------+
| PCI I/O (16M) |
ffff:ffbe:fee0:0000 +--------------------------+
|//|
ffff:ffbe:fec0:0000 +--------------------------+
| fixed (4M) |
ffff:ffbe:fe7f:d000 +--------------------------+
|//|
ffff:ffbe:bfff:0000 +--------------------------+
| |
| |
| |
| |
| |
| |
z vmalloc (250G) z
| |
| |
| |
| |
| |
| |
ffff:ff80:087c:f76c | +----------------------+ |
| | .bss | |
| | .data | |
| | .init | | Kernel
| | .rodata | |
| | .text | |
ffff:ff80:0808:0000 | +----------------------+ |
ffff:ff80:0800:0000 +--------------------------+
| modules (128M) |
ffff:ff80:0000:0000 +--------------------------+
以下内核日后学习了会继续补充
/*
在内核中(以下所涉及的栈都指内核栈):
模块地址往往是`0xffff ffff c000 0000` 的偏移比如函数地址`0xffffffffc00000f0` (babydevice为例)
栈地址往往是`0xffff c900 0000 0000`的偏移比如->`0xffffc900001b7e90`
slub分配的object地址往往是`0xffff888000000000`的偏移比如`0xffff888007198340`
*/
slub分配器使用

kmem_cache数据结构
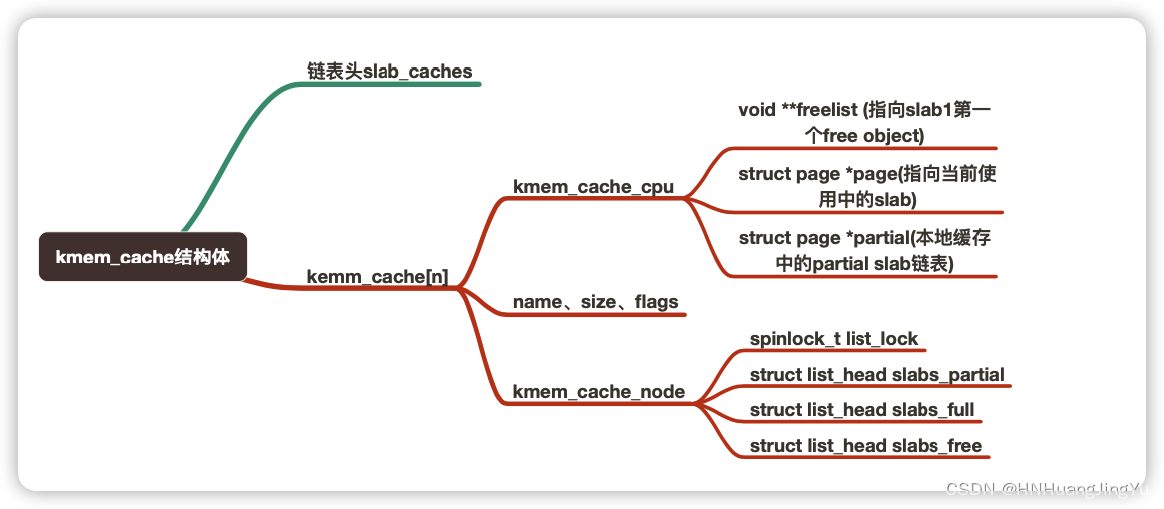
slab分配器的对象单位–>管理自己的kmem_cache–>kmem_cache存在于slab_caches双链表中
kmem_cache里的一些小slab对象–>存在于“kmem_cache_node->partial”中 --> 每个node对应于kmem_cache_node数组项
kmem_cache里的另一部分小slab对象–>存在于“kmem_cache_cpu->partial”中
slab中没有被使用的对象称为空闲对象(free object),同一slab中的所有空闲对象被串成了一个单项链表(freelist),每个空闲对象的首地址 + kmem_cache->offset处会保存下一个空闲对象的地址,这样就形成了一个单链表
分配对象
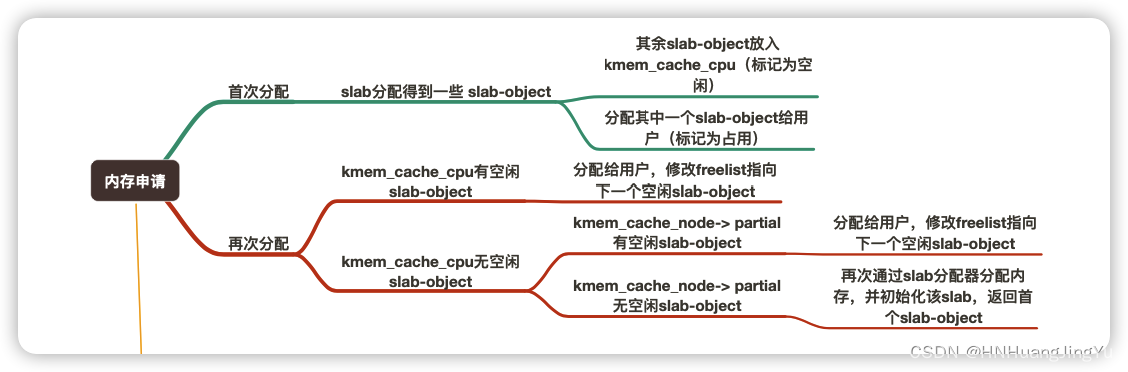
有了上面的kmem_cache结构体就可以通过kmem_cache_alloc()分配对象在分配时有如下情况:
- fast path:直接从本地cpu缓存中的freelist拿到可用object
- slow path:本地cpu缓存中的freelist为NULL,但本地cpu缓存中的partial中有未满的slab
- very slow path:本地cpu缓存中的freelist为NULL,且本地cpu缓存中的partial也无slab可用。
内存管理是按大小块管理的具体可看cat /proc/slainfo 大小相同的会物理相邻
专用高速缓存是由kmem_cache_creat()函数创建的,专门使用与特殊类型的对象
普通高速缓存使用kmalloc()进行分配
释放对象
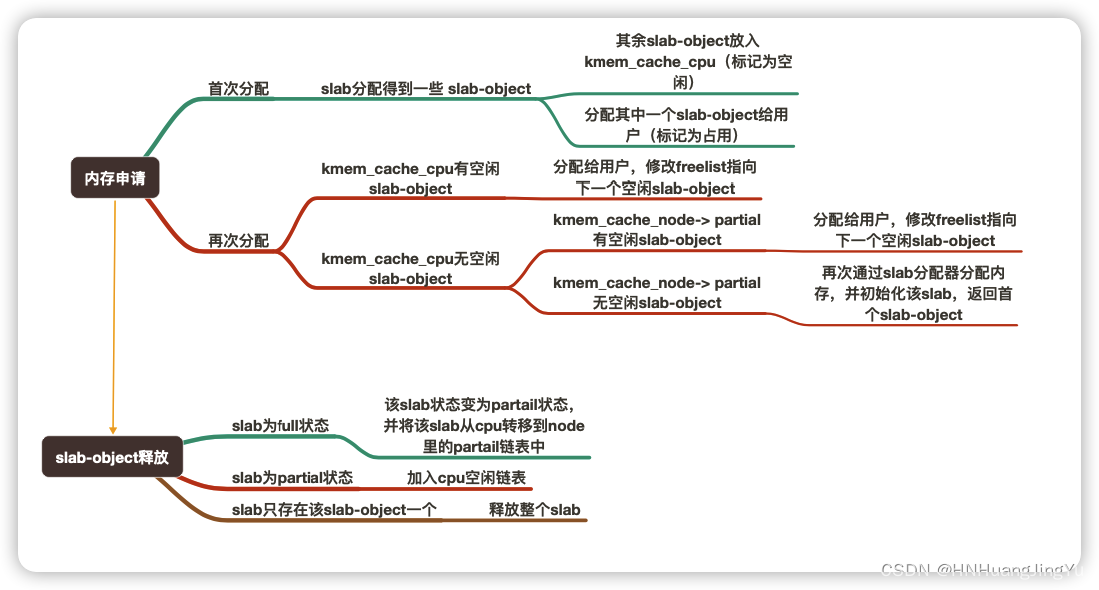
函数定义:
/*分配一块给某个数据结构使用的缓存描述符
name:对象的名字 size:对象的实际大小 align:对齐要求,通常填0,创建是自动选择。 flags:可选标志位 ctor: 构造函数 */
struct kmem_cache *kmem_cache_create( const char *name, size_t size, size_t align, unsigned long flags, void (*ctor)(void*));
/*销毁kmem_cache_create分配的kmem_cache*/
int kmem_cache_destroy( struct kmem_cache *cachep);
/*从kmem_cache中分配一个object flags参数:GFP_KERNEL为常用的可睡眠的,GFP_ATOMIC从不睡眠 GFP_NOFS等等等*/
void* kmem_cache_alloc(struct kmem_cache* cachep, gfp_t flags);
/*释放object,把它返还给原先的slab*/
void kmem_cache_free(struct kmem_cache* cachep, void* objp);
常见的pwn题使用kmem_cache_alloc_trace如下:(ctf linux内核-内存管理slub分配器)
int __cdecl sudrv_init()
{
int v0; // eax
__int64 v1; // rdi
printk("\x016SUCTF 2019 SUDriver\n");
v0 = _register_chrdev(0xE9LL, 0LL, 0x100LL, "meizijiutql", &fops);
v1 = kmalloc_caches[12];
su_fd = v0;
su_buf = (char *)kmem_cache_alloc_trace(v1, 0x480020LL, 0x1000LL);//
// kmem_cache_alloc_trace(cachep, flags,size);
return 0;
}
kmem_cache_alloc_trace函数就是kmem_cache_create + kmem_cache_alloc这样就通过slub分配器分配了一块内存了
参考资料
https://blog.csdn.net/u012489236/article/details/108188375(写的很容易理解)
https://zhuanlan.zhihu.com/p/166649492
https://cloud.tencent.com/developer/news/646104(写的很全)