KNN (K-Nearest Neighbor)–K近邻分类算法
• 为了判断未知实例的类别,以所有已知类别的实例作为参照选择参数K
• 计算未知实例与所有已知实例的距离
• 选择最近K个已知实例
• 根据少数服从多数的投票法则(majority-voting),让未知实例归类为K个最邻近样本中最多数的类别
简单来说,KNN算法就是看预测数据距离哪一类数据接近就把它预测成哪一类。
举一个简单的例子:
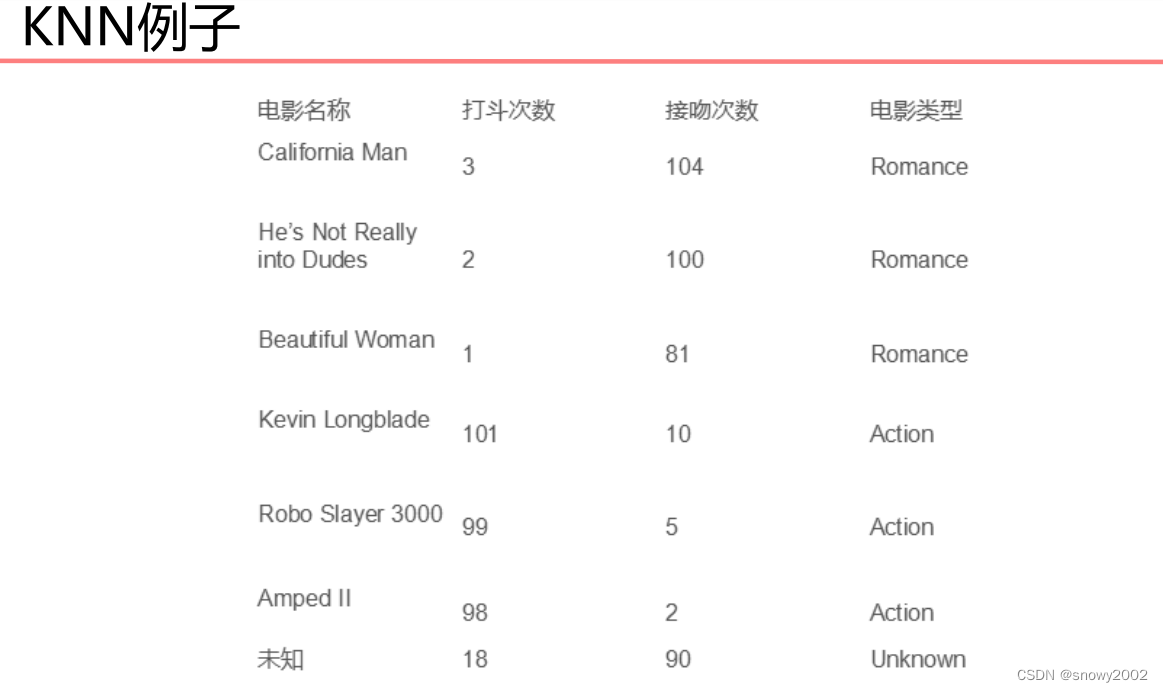
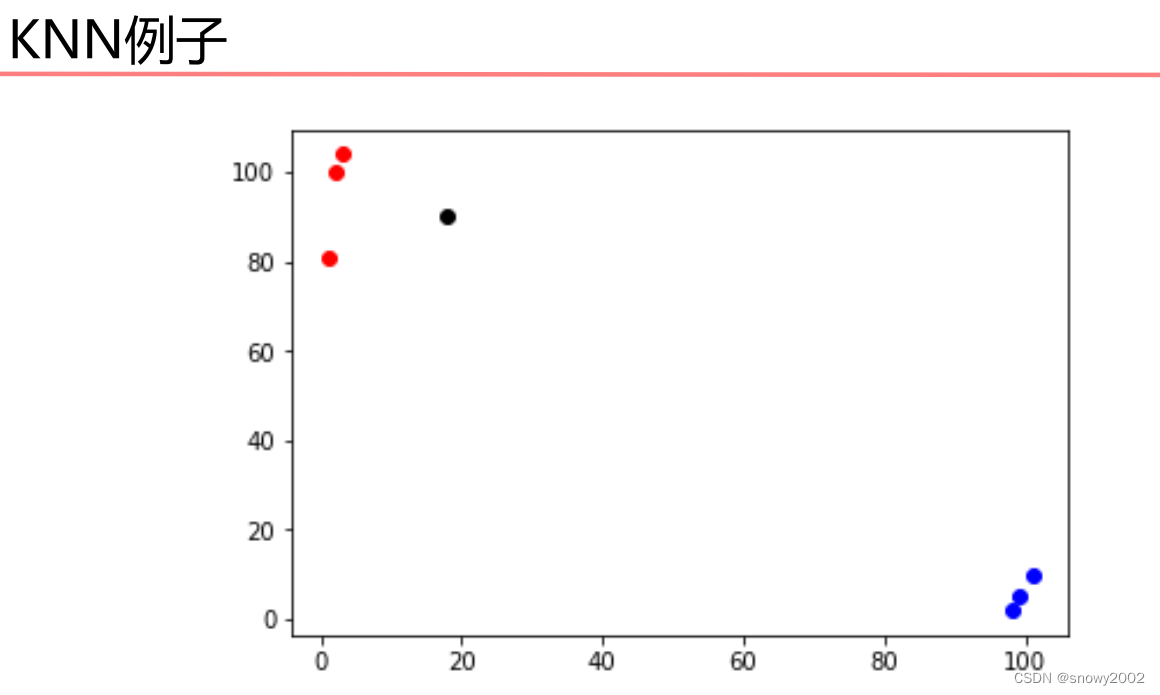
如图,红色的点和蓝色的点分别为已知分类的两种数据点,现在想要预测黑色的点的所属类别,显而易见应该属于红色类别,因为距离红色类别的距离较近,KNN算法大致就是这样的分类思路。
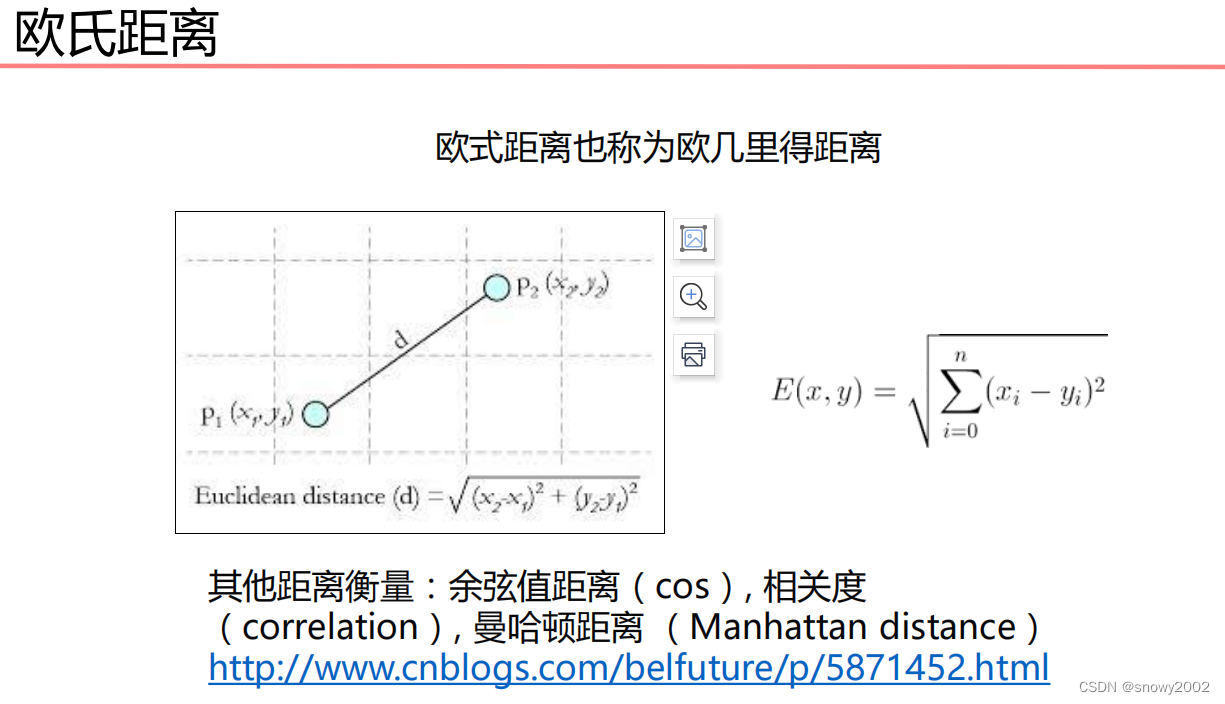
那么在计算距离的时候,我们应该采取什么样的方法呢?
一般来讲,我们通常会使用欧几里得距离作为计算的标准。
K值又是如何确定呢?
这个问题往往需要根据实际问题来进行确定,也可以通过实践的方法找出最优的K值。
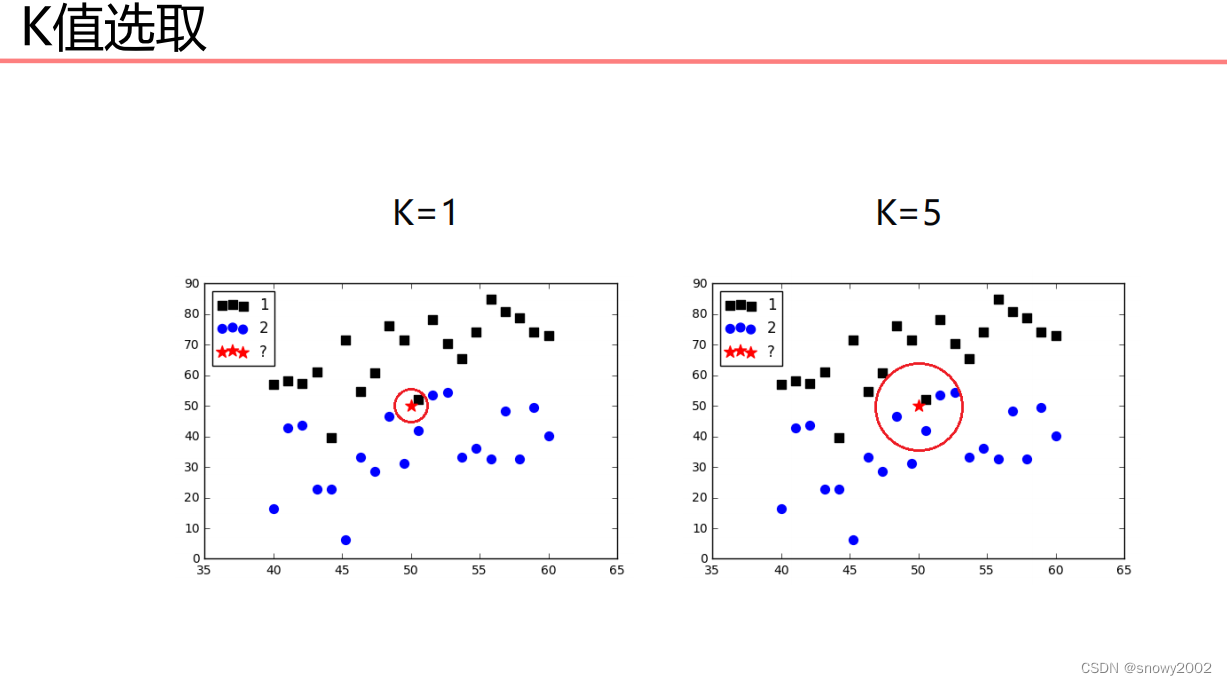
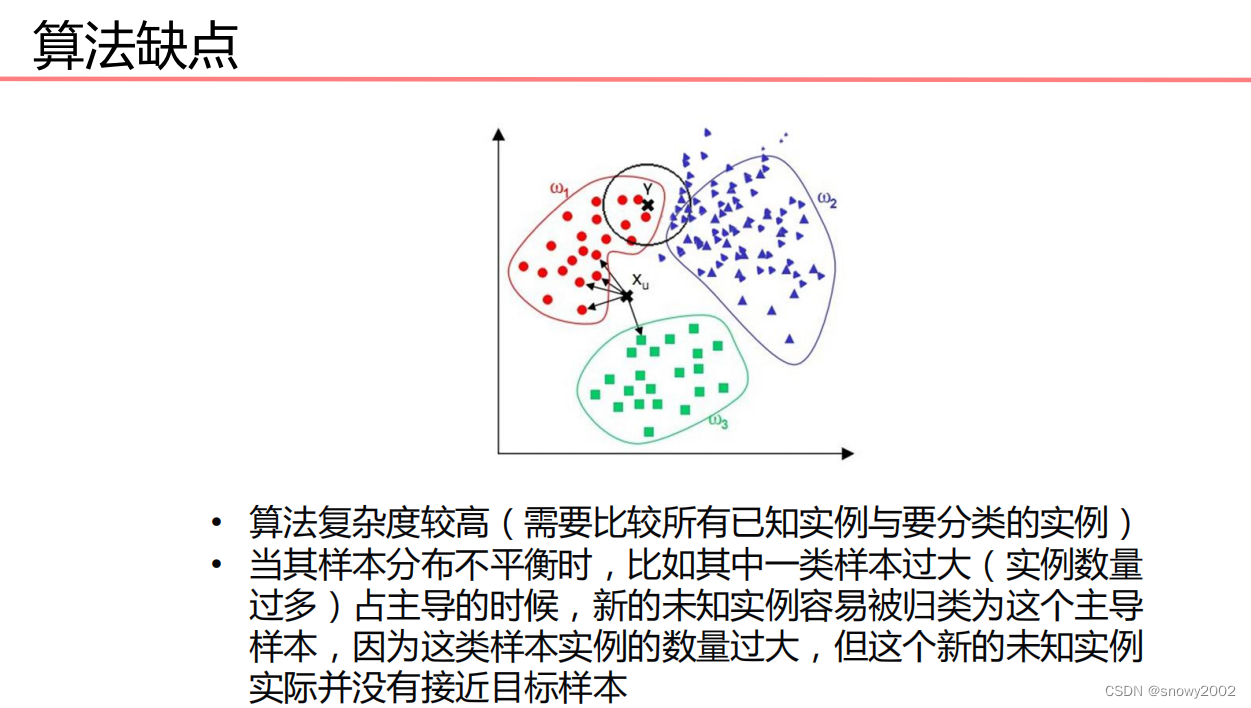
因为该算法的复杂度较高,在处理大规模数据的时候往往表现的非常糟糕,因此,此类算法适用于解决小规模的数据问题。
下面我来实现一个简单的KNN算法:
# 导入算法包以及数据集
from sklearn import neighbors
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import random
iris = datasets.load_iris() #载入数据
# 打乱数据切分数据集
# x_train,x_test,y_train,y_test = train_test_split(iris.data, iris.target, test_size=0.2) #分割数据0.2为测试数据,0.8为训练数据
#打乱数据
data_size = iris.data.shape[0]
index = [i for i in range(data_size)]
random.shuffle(index)
iris.data = iris.data[index]
iris.target = iris.target[index]
#切分数据集
test_size = 40
x_train = iris.data[test_size:]
x_test = iris.data[:test_size]
y_train = iris.target[test_size:]
y_test = iris.target[:test_size]
# 构建模型
model = neighbors.KNeighborsClassifier() #默认K=5
model.fit(x_train, y_train)
prediction = model.predict(x_test)
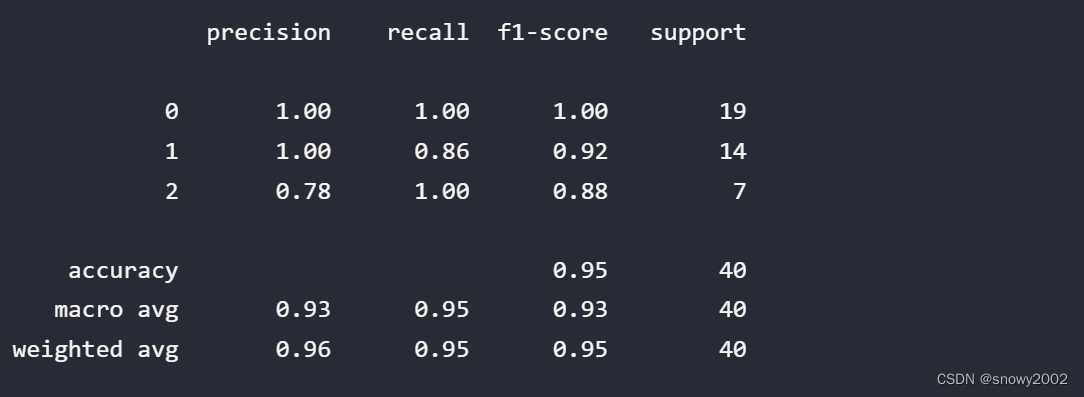
print(classification_report(y_test, prediction))