不久之前,人们还常说,计算机视觉的辨别能力尚不如一岁大的孩子。如今看来,这句话要改写了。
----- 特伦斯·谢诺夫斯基
目录
大家好啊,我是董董灿。
chatGPT 火了很久了,这是继 alphaGo 大战李世石大火之后,人工智能领域又一个难得一见的现象级产品。
据说 chatGPT 是历史上从发布到获得“一亿用户活跃度”最快的应用,可见它的火热。
人工智能现在发展的如火如荼,但你知道么,从上世纪50年代开始到现在,这几十年的过程中,人工智能的发展却一波三折,甚至出现了停滞。
有人说,人工智能在发展过程中,出现过“三次危机”。而每一次危机,都随着人类科学技术的不断发展,被更科学更先进的技术所化解。
最终,人工智能迎来了它的春天。

最近我在看一本书,书名叫《深度学习》,作者是特伦斯.谢诺夫斯基。
你可能听说过一本与它同名的书也叫《深度学习》,别名《花书》。
但这本书不同于花书的是,它不是专业性知识的介绍,更像是一本通俗的深度学习入门读物。
作者以自己亲历人工智能发展历史的视角,向读者展示了深度学习的发展脉络,在回顾历史的同时,还展望了未来。
作为一个从事人工智能行业的人,看完之后,大受震撼。最震撼的,大概是书中讲到的人工智能的发展历史,以及它是如何在不断演进中,慢慢走向春天的。
今天,就写一写书中提到的人工智能的发展史中,出现过的“三次危机”。
人工智能初现端倪
研究人工智能算法的同学可能知道,目前人工智能普遍的实现方式,是设计深层次的人工神经网络,通过对大量数据样本进行训练,获取到AI模型,然后利用训练好的模型,完成各项任务的推理工作。
因此,无论是图像任务、语音任务还是文字转图像任务(AI绘画),大抵都是如此的逻辑。
这种对AI模型训练的方法,基本都是基于深度学习的算法而来。
深度学习中所谓的深度,指的是在人工神经网络中,网络的层数很深,神经网络可以深度地“自学习”数据样本中的各种特征。
因此,可以不夸张的讲,深度学习,是人工智能的灵魂。
但是,在人工智能出现的最开始,却不是这样的。
人工智能初现
1956 年,马文·明斯基等四位美国科学家,共同发起了达特茅斯人工智能夏季研究计划,开始了人工智能领域的研究。
在人们刚开始研究人工智能的时候,关于如何构建人工智能,当时存在两种不同的观点。
一种观点主张使用逻辑和计算机程序来设计人工智能,而另一种则主张让人工智能直接从数据中进行自我学习。
前者暂且称之为“设计派”,他们认为,人工智能可以基于逻辑和计算机程序被设计出来。
只要给出明确的规则和逻辑,编写程序输入计算机,就能让计算机拥有智能。
举个例子,只要我们能够给出足够的规则来描述什么是一只猫,那么计算机只要看到世界上任何一只猫,它都可以识别出来。
另一派则被称之为“学习派”。他们主张借助大量的数据样本,让计算机程序自己学习,慢慢拥有智能。
虽然“学习派”的观点和目前构建人工智能的方式很相近,但在当时的情况下,大多数的人工智能科学家,却更倾向于“设计派“”。
为什么呢?
因为设计派的理念与当时的环境和计算机研究更相符。
毕竟,当时的人们,让计算机实现数学计算,并不是让他自己去学习的,而是通过编程,把一加一等于二这种简单的规则告诉他,他自己就可以扩展完成更多的复杂计算。
于是,在上世纪七八十年代,在医疗行业就出现了所谓的人工智能专家系统。
科学家和医生为了识别某一致病菌,会依据以往的案例和数据,把病菌的特点和患者的表现输入到计算机中作为数据库,然后将新的症状与数据库中已有的记录进行匹配,输出匹配结果,完成专家系统的诊断。
但是人们很快就发现,对于稍微复杂的病症,医生们更倾向于自己的经验判断,而非专家系统的推理结果。
在复杂病症的处理上,当时的人工智能专家系统,显得力不从心。
在当时,一个更加典型的例子是积木世界,这也导致了人们对于基于“设计派”观点构建人工智能的不信任。
人工智能“第一次危机”——“设计派”行不通
积木世界(Blocks World)是MIT AI Lab(麻省理工人工智能实验室)在20世纪60年代推出的一个项目。
当时为了处理视觉问题,将人类所在的真实世界进行了简化,称为“积木世界”。积木世界由矩形积木组成,积木可以堆叠起来组成新的结构。

该项目的目标是编写一个能够理解命令的程序,例如“找到一个大的黄色积木并将其放在红色积木上面”,并让机器人手臂执行命令完成对应动作。
这看起来小孩子都会玩的游戏,但在当时,却需要一个庞大而复杂的程序来实现。
而且这个程序后来变得十分冗长,以至于编写该程序的学生——特里·维诺格拉德离开该实验室之后,程序因为错误百出,频频崩溃,最终被无奈地放弃。
这个看起来很简单的问题,在使用程序编码实现的过程中,却异常的艰难,几乎不可能成功。
就算解决了积木世界的问题,想要通过编程完成一栋现实中大楼的建设,这中间还是有巨大的技术鸿沟。
于是,通过设计一种特定的规则,让机器拥有智能这条路,开始碰壁了。
“设计派”们心灰意冷,放弃了积木问题的研究。
这也使人们意识到,单纯的靠规则和逻辑,完成复杂现实世界的推理,是不可行的。
第一次危机破局——学习派初见成效
“设计派”的路走不通,科学家们开始发力,寻找另一种可行的方法。于是,“学习派”越来越被受到重视。
1957年,康奈尔大学的弗兰克·罗森布拉特教授发明了“感知器”,这是深度学习的前身。
感知器是具有单一人造神经元的神经网络,它只有一个输入层,一个神经元和一个输出。
可以说,他是现代人工神经网络中的最小单元。
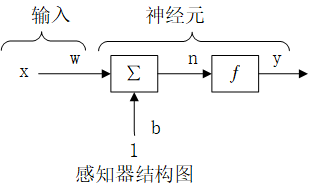
感知器的出现,其实已经初步具有现代深度学习的雏形,只不过它是一个单独的神经元,并没有现代神经网络复杂多层的结构。
在发明感知器的同一年,美国军方就利用感知器完成了一个程序,让计算机识别有坦克的图片,训练一段时间后,计算机竟然真的可以从新的图片中正确的识别出坦克。
这在当时,引起了轰动。
这也意味着,设计派走不通的路,学习派可以走通,并且已经初见成效。
但是接下来又遇到了新问题——
怎么让感知器算法处理更加复杂的问题呢?总不能一直识别坦克吧,它能不能和人一样,能听,能说,能写,能画呢?
于是,人工智能的研究者们开始尝试,把感知器和感知器连接起来,组成更大的人工神经网络。
可是,还没开始,这条路,就被人工智能之父——堵死了。
人工智能“第二次危机”——多层神经网络无法训练
马文·明斯基,1956年达特茅斯人工智能夏季研究计划的发起人,大家眼中的——人工智能之父。
在1969年,它出版了一本书,书名就叫《感知器》。
在书中,明斯基给出了几条结论。
第一条是: 单个感知器,只能解决有限的问题。要解决更复杂的问题,必须要把更多感知器连接起来,组成人工神经网络。
第二条是: 我们无法找到一种可行的算法,来对多层的人工神经网络进行训练。
这段话什么意思?
就好比有人告诉你,我们发现了,圆形可以稳定高速的在地上移动,我们可以利用这个特性造出快速的交通工具。
甚至,已经有人造出了独轮车,但是,也只能如此了,想要实现高铁那种高速、复杂又载人多的功能,是不可能办到的。
我们找不到办法可以办到,现在不行,将来也不行。
而且告诉你的不是别人,正是独轮车的发明人——人工智能之父。
于是,一代人工智能研究者,心灰意冷。导致了在后来长达十几年的时间里,人工智能的发展处于停滞状态。
一句“多层人工神经网络无法训练”,迎来了人工智能的第二次危机。
第二次危机破局——玻尔兹曼机
1985 年,特伦斯·谢诺夫斯基,也就是上面介绍的《深度学习》这本书的作者,和另一个人工智能专家杰弗里·辛顿,提出了一种算法,可以让多个感知器共同组成一个人工神经网络。
这个算法叫做"玻尔兹曼机"。
玻尔兹曼机的出现,证明了科学家们可以找到一种方法,让多层人工神经网络处理更加复杂的问题。
在随后的 1986 年,大卫·鲁姆哈特提出了"误差反向传播"算法,它比玻尔兹曼机更简单高效。
误差反向传播算法几乎是现代深度学习中的灵魂,它可以让一个神经网络得到上一次推理结果的反馈,从而不断纠正自己,完成自我训练,也就是使神经网络具有自学习能力。
如果说深度学习是人工智能的灵魂,那么反向传播算法就是深度学习的灵魂。
于是,在反向传播算法的加持下,人工智能的第二次浪潮到来。
可是这股浪潮,到了 1995 年前后,又停滞不前了。
人工智能“第三次危机”——算力跟不上
这一次是因为算力太拉胯了。
上世纪90年代,国内计算机才刚刚开始走向大众。当时的计算机芯片的计算能力少的可怜。
据说当时有人在电脑上运行人工智能程序,神经元的个数不敢超过 20 个,一个模型的参数估计也就几十几百个。
而现在的大模型,比如最火的GPT4的参数,是以万亿为单位的。
如此多的参数量,没有大量的算力和硬件计算资源,是根本行不通的。
于是,人工智能领域的研究者除了不断优化算法,其余的时间只能等待,等待计算机的算力的爆发时刻,在继续研究层数更深,参数更大的大模型。
怎么等?能等到么?
在芯片行业有个定律叫“摩尔定律”,是说,每隔两年,芯片内晶体管的数量增加一倍,简单来说,就是芯片的运算能力增加一倍。
这种指数级的增长是很吓人的。
从上世纪开始,摩尔定律配合着时间,开始发挥他的魔力。
几十年间,一个同等大小的芯片,其算力已经是最初的几百几千万倍了。
最近几十年,随着芯片制程的不断发展,从28nm到14nm,再到7nm,再到5nm,芯片算力持续攀升。
从2012年开始,英伟达CUDA编程模型的问世,GPU架构的不断升级,人工智能多卡训练成为现实。
这一系列的科技加持,使得人工智能的春天,又一次到来。
这一次,人工智能的发展像是洪水猛兽,一发不可收拾。
算力需求持续走高,倒逼着芯片架构不断创新,国内外AI芯片如雨后春笋般出现。
算力的加持又使得人工智能的应用延伸到各行各业。甚至反哺芯片制造业,芯片制造业下的蛋,最终又成了鸡。
AI模型不断优化,AI训练的速度和精度不断被刷榜,顶会期刊不断SOTA。
这一次,算法成熟了,算力也跟上了,人工智能的研究,终于可以在大模型上崭露头角。
于是,chatGPT,走向大众,破圈了。
国内的百度也在积极部署文心大模型。有人说,随着人工智能大模型的成熟,这一波的科技浪潮,要远比移动互联网带来的影响更大。
甚至,它可能掀起第四次工业革命。
而这一次的浪潮,我们每一个人都在经历。

看完这本书,回过头来思考人工智能的发展,我依然心潮澎湃。
一个新的技术的发展,离不开当时的科技环境。
人工智能从最初基于规则进行的程序设计,到感知机,到玻尔兹曼机,到反向传播算法、再到现在的AI芯片算力加持,每一步走的都异常艰难。
很早之前就看过说,人工智能的三驾马车,是数据、算法和算力。
数据得益于互联网的发达,chatGPT的训练数据就来自于各个国家的互联网。
算法得益于人工智能算法科学家几十年的沉淀和不断持续的优化。
算力得益于芯片制程的不断创新和摩尔定律与时间的魔法效应。
三驾马车都齐了,人工智能还能发展不起来么?
每一个行业从萌芽,到初具规模,走的都不容易。幸运作为一名深度学习算法开发者,参与了这次人工智能发展的浪潮。见证这次的科技变革。
有朝一日随风起,扶摇直上九万里。