正则规则
正则表达式是对字符串提取的一套规则,我们把这个规则用正则里面的特定语法表达出来,去匹配满足这个规则的字符串。正则表达式具有通用型,不仅python里面可以用,其他的语言也一样适用。
匹配字符串
re.match()必须从字符串开头匹配!match方法尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
import re
a = re.match('test','testasdtest')
print(a) #返回一个匹配对象
print(a.group()) #返回test,获取不到则报错
print(a.span()) #返回匹配结果的位置,左闭右开区间
print(re.match('test','atestasdtest')) #返回None
从例子中我们可以看出,re.match()方法返回一个匹配的对象,而不是匹配的内容。如果需要返回内容则需要调用group()。通过调用span()可以获得匹配结果的位置。而如果从起始位置开始没有匹配成功,即便其他部分包含需要匹配的内容,re.match()也会返回None。
单字符匹配
以下字符,都匹配单个字符数据。且开头(从字符串0位置开始)没匹配到,即使字符串其他部分包含需要匹配的内容,.match也会返回none
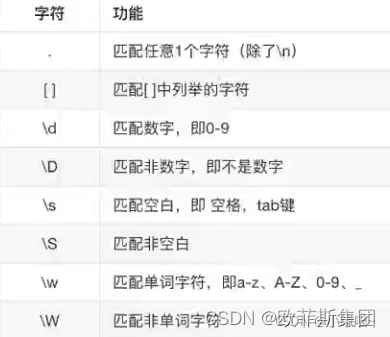
表示数量的规则
| 字符 | 功能 |
|---|---|
| * | 匹配前一个字符出现0次多次或者无限次,可有可无,可多可少 |
| + | 匹配前一个字符出现1次多次或则无限次,直到出现一次 |
| ? | 匹配前一个字符出现1次或者0次,要么有1次,要么没有 |
| {m} | 匹配前一个字符出现m次 |
| {m,} | 匹配前一个字符至少出现m次 |
| {m,n} | 匹配前一个字符出现m到n次 |
匹配边界
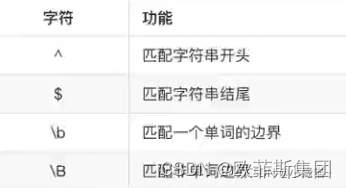
匹配分组

案列
匹配任意一个字符
import re
a = re.match('..','testasdtest')
print(a.group()) #输出te
b = re.match('ab.','testasdtest')
print(b) #返回none,因为表达式是以固定的ab开头然后跟上通配符. 所以必须要先匹配上ab才会往后进行匹配
\d 匹配数字
import re
a = re.match('\d\d','23es12testasdtest')
print(a)
b = re.match('\d\d\d','23es12testasdtest')
print(b) #要求匹配三个数字,匹配不到返回none
c = re.match('\d','es12testasdtest')
print(c) #起始位置没有匹配成功,一样返回none
\D 匹配非数字
import re
a = re.match('\D','23es12testasdtest')
print(a) #开头为数字所以返回none
b = re.match('\D\D','*es12testasdtest')
print(b) #返回*e
\s 匹配特殊字符,如空白,空格,tab等
import re
print(re.match('\s',' 23es 12testasdtest')) #匹配空格
print(re.match('\s',' 23es 12testasdtest')) #匹配tab
print(re.match('\s','\r23es 12testasdtest')) #匹配\r换行
print(re.match('\s','23es 12testasdtest')) #返回none
\w 匹配单词、字符,如大小写字母,数字,_ 下划线
import re
print(re.match('\w','23es 12testasdtest')) #返回none
print(re.match('\w\w\w','aA_3es 12testasdtest')) #返回none
print(re.match('\w\w\w','\n12testasdtest')) #返回none
* 出现0次或无数次
import re
a = re.match('..','testasdtest')
print(a.group()) #输出te
a = re.match('.*','testasdtest')
print(a.group()) #全部输出
+ 至少出现一次
import re
print(re.match('a+','aaatestasdtest')) #匹配前面为字母a的字符,且a至少有1一个
print(re.match('a+','atestasdtest')) #a
print(re.match('a+','caaatestasdtest')) #none
? 1次或则0次
import re
print(re.match('a?','abatestasdtest')) #匹配a出现0次或者1次数
print(re.match('a?','batestasdtest')) #输出空,因为a可以为0次
print(re.match('a?','aaatestasdtest')) #a出现0次或者1次,输出1个a
{m}指定出现m次
import re
print(re.match('to{3}','toooooabatestasdtest')) #匹配t以及跟随在后面的三个ooo
print(re.match('to{3}','tooabatestasdtest')) #只有两个0,返回none
{m,n} 指定从m-n次的范围
import re
print(re.match('to{3,4}','toooabatestasdtest')) #刚好有三个ooo,成功匹配
print(re.match('to{3,4}','tooabatestasdtest')) #只有两个o,返回none
print(re.match('to{3,4}','toooooabatestasdtest')) #提取最多四个o
$ 匹配结尾字符
import re
print(re.match('.*d$','2testaabcd')) #字符串必须以d结尾
print(re.match('.*c','2testaabcd')) #字符串不是以c结尾,返回none
^ 匹配开头字符
import re
print(re.match('^2','2stoooabatestas')) #规定必须以2开头,否则none
print(re.match('^2s','2stoooabatestas')) #必须以2s开头
\b 匹配一个单词的边界
import re
print(re.match(r'.*ve\b','ve.2testaabcd')) #因为在python中\代表转义,所以前面加上r消除转义
print(re.match(r'.*ve\b','ve2testaabcd'))
| 匹配左右任意一个表达式
import re
print(re.match(r'\d[1-9]|\D[a-z]','2233')) #匹配|两边任意一个表达式
print(re.match(r'\d[1-9]|\D[a-z]','as'))
(ab) 将括号中字符作为一个分组
import re
a = re.match(r'<h1>(.*)<h1>','<h1>你好啊<h1>')
print(a.group()) #输出匹配的字符
print(a.groups()) #会将()中的内容会作为一个元组字符装在元组中
print('`````````````')
b = re.match(r'<h1>(.*)(<h1>)','<h1>你好啊<h1>')
print(b.groups()) #有两括号就分为两个元组元素
print(b.group(0)) #group中默认是0
print(b.group(1)) #你好啊
print(b.group(2)) #h1
search
和match差不多用法,从字符串中进行搜索
import re
print(re.match(r'\d\d','123test123test'))
print(re.search(r'\d\d','123test123test'))
findall
从字面意思上就可以看到,findall是寻找所有能匹配到的字符,并以列表的方式返回
import re
print(re.search(r'test','123test123test'))
print(re.findall(r'test','123test123test')) #以列表的方式返回
邮箱
格式: 包含大小写字母,下划线,阿拉伯数字,点号,中划线。
表达式:[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(?:.[a-zA-Z0-9_-]+)
pattern = re.compile(r"[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(?:\.[a-zA-Z0-9_-]+)")
strs = '我的邮箱是[email protected],QQ邮箱是[email protected]'
result = pattern.findall(strs)
print(result)#打印邮箱
身份证号
格式: xxxxxxyyyyMMdd3750 (18位数字)
地区:[1-9] \d{5}
年的前两位:(18|19|([23]\d))
年的后两位:\d{2}
月份:((0[1-9])|(10|11|12))
天数:(([0-2][1-9])|10|20|30|31)
三位顺序码:\d{3}
两位顺序码:\d{2}
校验码:[0-9Xx]
pattern = re.compile(r"[1-9]\d{5}(?:18|19|(?:[23]\d))\d{2}(?:(?:0[1-9])|(?:10|11|12))(?:(?:[0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]")
strs = '我的的身份证号码是342623199805205163'
result = pattern.findall(strs)
print(result)#打印身份证号
手机号
格式: 手机号都为11位,且以1开头,第2位一般为3、5、6、7、8、9 ,剩下八位任意数字。
pattern = re.compile(r"1[356789]\d{9}")
strs = '我的手机号是17312345678,另外一个手机号是18312345678'
result = pattern.findall(strs)
print(result)#打印手机号
日期
格式: yyyyMMdd、yyyy-MM-dd、yyyy/MM/dd、yyyy.MM.dd
pattern = re.compile(r"\d{4}(?:-|\/|.)\d{1,2}(?:-|\/|.)\d{1,2}")
strs = '今天是2020/12/27'
result = pattern.findall(strs)
print(result)#打印日期
中文字符
pattern = re.compile(r"[\u4e00-\u9fa5]")
strs = 'name:张三'
result = pattern.findall(strs)
print(result) # 打印中文
| 优先权 | 符号 |
|---|---|
| 最高 | \ |
| 高 | ()、(?:)、(?=)、[] |
| 中 | *、+、?、{n}、{n,}、{n,m} |
| 低 | ^、$、中介字符 |
| 次最低 | 串接,即相邻字符连接在一起 |
| 最低 | \ |