4.1 keras指定运行时显卡及限制GPU用量
https://blog.csdn.net/A632189007/article/details/77978058
#!/usr/bin/env python
# encoding: utf-8
"""
@version: python3.6
@author: Xiangguo Sun
@contact: [email protected]
@site: http://blog.csdn.net/github_36326955
@software: PyCharm
@file: 2CLSTM.py
@time: 17-7-27 5:15pm
"""
import os
import tensorflow as tf
import keras.backend.tensorflow_backend as KTF
#进行配置,每个GPU使用60%上限现存
os.environ["CUDA_VISIBLE_DEVICES"]="1,2" # 使用编号为1,2号的GPU
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.6 # 每个GPU现存上届控制在60%以内
session = tf.Session(config=config)
# 设置session
KTF.set_session(session )
4.2 利用fit_generator最小化显存占用比率/数据Batch化
#!/usr/bin/env python
# encoding: utf-8
"""
@version: python3.6
@author: Xiangguo Sun
@contact: [email protected]
@site: http://blog.csdn.net/github_36326955
@software: PyCharm
@file: 2CLSTM.py
@time: 17-7-27 5:15pm
"""
#将内存中的数据分批(batch_size)送到显存中进行运算
def generate_arrays_from_memory(data_train, labels_cat_train, batch_size):
x = data_train
y=labels_cat_train
ylen=len(y)
loopcount=ylen//batch_size
while True:
i = np.random.randint(0,loopcount)
yield x[i*batch_size:(i+1)*batch_size],y[i*batch_size:(i+1)*batch_size]
# 下面的load不会占用显示存,而是load到了内存中。
data_train=np.loadtxt("./data_compress/data_train.txt")
labels_cat_train=np.loadtxt('./data_compress/labels_cat_train.txt')
data_val=np.loadtxt('./data_compress/data_val.txt')
labels_cat_val=np.loadtxt('./data_compress/labels_cat_val.txt')
hist=model.fit_generator(
generate_arrays_from_memory(data_train,
labels_cat_train,
bs),
steps_per_epoch=int(train_size/bs),
epochs=ne,
validation_data=(data_val,labels_cat_val),
callbacks=callbacks )如果你的内存也不够,你也可以选择从文件中分批导入:
#!/usr/bin/env python
# encoding: utf-8
"""
@version: python3.6
@author: Xiangguo Sun
@contact: [email protected]
@site: http://blog.csdn.net/github_36326955
@software: PyCharm
@file: 2CLSTM.py
@time: 17-7-27 5:15pm
"""
def process_line(line):
tmp = [int(val) for val in line.strip().split(',')]
x = np.array(tmp[:-1])
y = np.array(tmp[-1:])
return x,y
def generate_arrays_from_file(path,batch_size):
while 1:
f = open(path)
cnt = 0
X =[]
Y =[]
for line in f:
# create Numpy arrays of input data
# and labels, from each line in the file
x, y = process_line(line)
X.append(x)
Y.append(y)
cnt += 1
if cnt==batch_size:
cnt = 0
yield (np.array(X), np.array(Y))
X = []
Y = []
f.close()
更多参考
https://blog.csdn.net/sinat_26917383/article/details/74922230
https://blog.csdn.net/lujiandong1/article/details/54869170
4.3 nvidia-smi 命令查看GPU状态
nvidia-smi -l上面的命令可以实现实时跟踪
一下命令解读内容来自博客:https://blog.csdn.net/sallyxyl1993/article/details/62220424
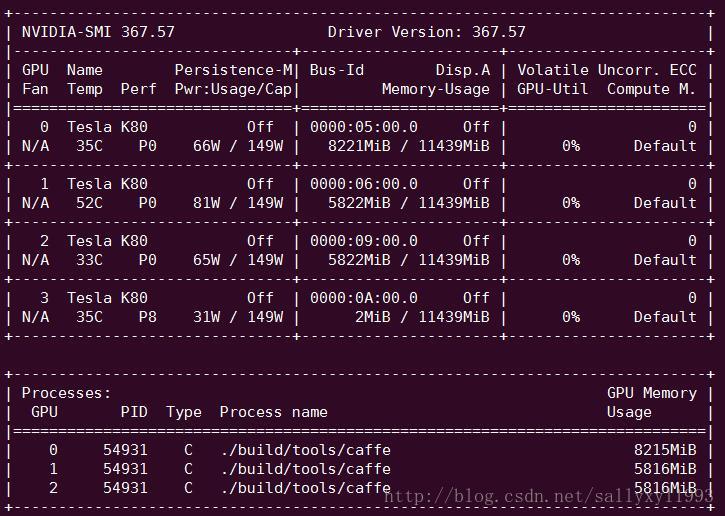
这是服务器上特斯拉K80的信息。
上面的表格中:
第一栏的Fan:N/A是风扇转速,从0到100%之间变动,这个速度是计算机期望的风扇转速,实际情况下如果风扇堵转,可能打不到显示的转速。有的设备不会返回转速,因为它不依赖风扇冷却而是通过其他外设保持低温(比如我们实验室的服务器是常年放在空调房间里的)。
第二栏的Temp:是温度,单位摄氏度。
第三栏的Perf:是性能状态,从P0到P12,P0表示最大性能,P12表示状态最小性能。
第四栏下方的Pwr:是能耗,上方的Persistence-M:是持续模式的状态,持续模式虽然耗能大,但是在新的GPU应用启动时,花费的时间更少,这里显示的是off的状态。
第五栏的Bus-Id是涉及GPU总线的东西,domain:bus:device.function
第六栏的Disp.A是Display Active,表示GPU的显示是否初始化。
第五第六栏下方的Memory Usage是显存使用率。
第七栏是浮动的GPU利用率。
第八栏上方是关于ECC的东西。
第八栏下方Compute M是计算模式。
下面一张表示每个进程占用的显存使用率。
显存占用和GPU占用是两个不一样的东西,显卡是由GPU和显存等组成的,显存和GPU的关系有点类似于内存和CPU的关系。我跑caffe代码的时候显存占得少,GPU占得多,师弟跑TensorFlow代码的时候,显存占得多,GPU占得少。
4.4 如何在多张GPU卡上使用Keras?(尚未解决)
这个问题目前还没有解决。
虽然能够实现数据分布在多个GPU上,但是似乎这歌分布仅仅是把数据复制了一份而已,在训练过程中,仍然是一个GPU在运算,另一个GPU的Volatile GPU-Util几乎为0.
比较有用的链接
https://keras-cn.readthedocs.io/en/latest/for_beginners/FAQ/#gpukeras
https://www.zhihu.com/question/67239897/answer/269003621
使用如下代码会报错,暂时不知道原因:
#!/usr/bin/env python
# encoding: utf-8
"""
@version: python3.6
@author: Xiangguo Sun
@contact: [email protected]
@site: http://blog.csdn.net/github_36326955
@software: PyCharm
@file: 2CLSTM.py
@time: 17-7-27 5:15pm
"""
import os
from keras.utils import multi_gpu_model
import tensorflow as tf
import keras.backend.tensorflow_backend as KTF
#进行配置,使用60%的GPU
os.environ["CUDA_VISIBLE_DEVICES"]="1,2"
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.6
session = tf.Session(config=config)
# 设置session
KTF.set_session(session )
……
model=multi_gpu_model(model,gpus=2)
#compile the model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
……
报错为:cannot merge devices with incompatible ids

4.5 ubuntu如何杀死进程
ps -ef
kill -9 PID