目录
1.什么是初始化列表
class A {
public:
A(int value):m_dada(value)
{
}
private:
int m_dada;
};
如上图,红色圈起来的部分,就是构造函数的初始化列表,以冒号开始,冒号后面依次列出需要赋值的成员变量和值。
2.什么时候需要使用初始化列表?
(1)当有成员变量是引用类型时
(2)当有数据成员是常量时
(3)当父类的构造函数有参数时
(4)当成员变量所属类型的构造函数有参数时
2.1当有成员变量是引用类型时
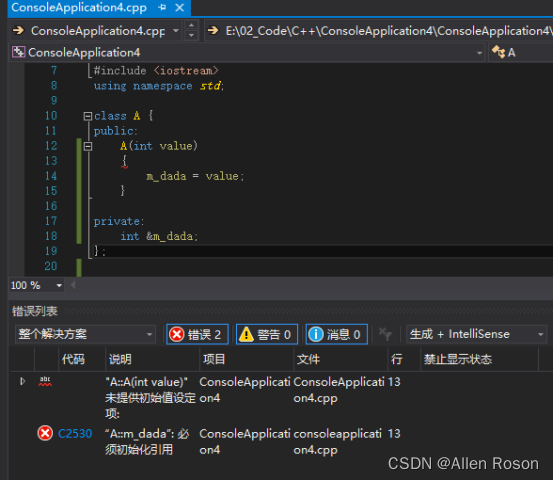
可以看到类中有一个引用类型的变量m_data,直接编译会报错,提示“必须初始化引用”,即使在构造函数里面赋值也不行,此时必须使用初始化列表,下面看看使用初始化列表后的情况。

可以看到,使用初始化列表后,编译成功。
2.2当有数据成员是常量时
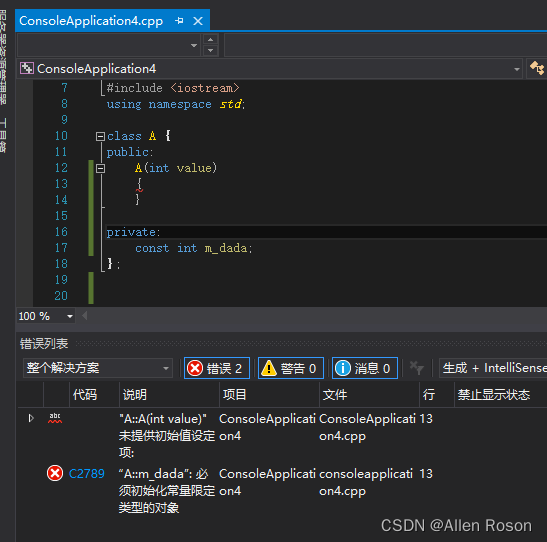
可以看到,类中有个const常量m_data,直接编译会报错,提示“必须初始化常量”。下面看看使用初始化列表后的情况。
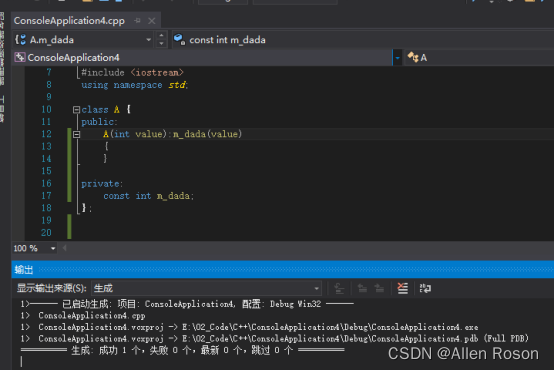
可以看到,使用初始化列表后,编译成功。
2.3当父类的构造函数有参数时

可以看到,B类的父类是A,A的构造函数有一个参数,在实现B类的构造函数时,如果不处理A类的构造函数,就会编译报错,提示“A类没有合适的默认构造函数可用”。下面看下使用了初始化列表后的情况。
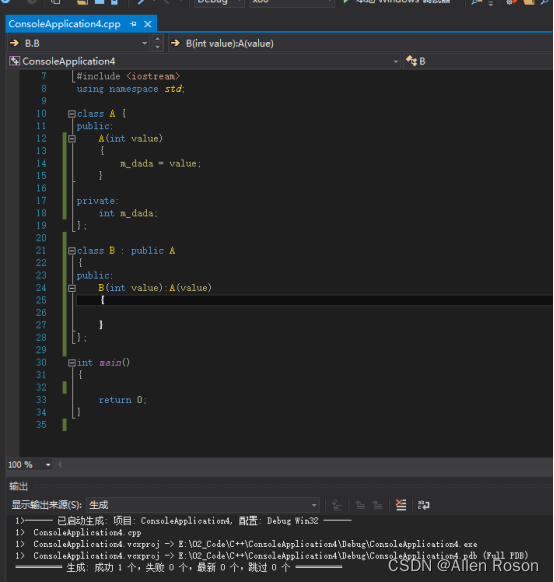
可以看到,使用初始化列表后,编译成功。
2.4当成员变量所属类型的构造函数有参数时

可以看到,B类有一个数据成员A m_a,在B类的构造函数中没有对这个m_a作处理,导致编译报错,提示“A没有合适的默认构造函数可以”。下面看看使用了初始化列表后的情况。

3.初始化列表的效率
#include "stdafx.h"
#include <iostream>
using namespace std;
class A {
public:
A()
{
cout << "call A()" << endl;
}
~A()
{
cout << "call ~A()" << endl;
}
};
class B
{
public:
B(A value) : m_a(value)
{
cout << "call B()" << endl;
//m_a = value;
}
~B()
{
cout << "call ~B()" << endl;
}
private:
A m_a;
};
int main()
{
A objA;
B objB(objA);
return 0;
}上面这段代码,在B类的构造函数中,使用了初始化列表给成员变量A m_a进行赋值,运行结果如下:
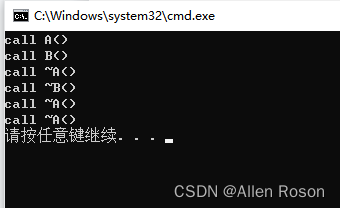
可以看到在调用B类的构造函数时,调用了一次A类的析构函数,没有调用A类的构造函数,我想这是VS编译器的特殊设计造成的,换成其它编译器可能就不是这样了,这里我认为使用了初始化列表之后,应该在B类的构造函数中不会调用A类的构造函数和析构函数了,这样才符合使用初始化列表的效率更高的特点。
下面看一下没有使用初始化列表,而直接在B类构造函数中给m_a赋值的情况。
#include "stdafx.h"
#include <iostream>
using namespace std;
class A {
public:
A()
{
cout << "call A()" << endl;
}
~A()
{
cout << "call ~A()" << endl;
}
};
class B
{
public:
B(A value)
{
cout << "call B()" << endl;
m_a = value;
}
~B()
{
cout << "call ~B()" << endl;
}
private:
A m_a;
};
int main()
{
A objA;
B objB(objA);
return 0;
}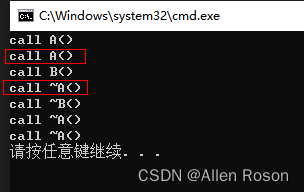
可以看到,如果直接在B类的构造函数中赋值,将会导致多一次A类构造函数的调用。
综上所述,使用初始化列表给成员变量设定初始值效率会更高,建议优先使用这种方法。对于基础类型的变量,比如int,bool类型,则没有必要非要采用初始化列表。
4.初始化列表的初始化顺序
编译器会将初始化列表一一转换成代码,并且这些代码会被放在用户编写的代码之前。初始化列表的初始化顺序是由数据成员的声明次序决定的,不是由初始化列表的排列次序决定的。
“初始化次序”和“初始化列表中的排列次序”如果不一致,将可能导致意想不到的风险。比如:
class C
{
private:
int i;
int j;
public:
C(int value):j(value),i(j)
{
cout << "i = " << i << endl;
cout << "j = " << j << endl;
}
};
int main()
{
C objC(10);
return 0;
}
上述程序代码看起来像是要把j设初值为 value,再把i设初值为 j.问题在于,由于声明次序的缘故,初始化列表中的”i(j)”其实比”j(value)”更早执行。但因为j 一开始未有初值,所以i(j)的执行结果导致无法预知其值。
那么如何避免上面的问题呢,建议是如果要用一个成员变量的值给另外一个成员变量赋值,则建议将赋值的代码写在构造函数中,如下:
class C
{
private:
int i;
int j;
public:
C(int value):j(value)
{
i = j;
cout << "i = " << i << endl;
cout << "j = " << j << endl;
}
};
int main()
{
C objC(10);
return 0;
}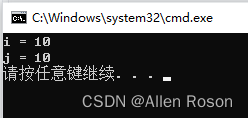
因为初始化列表的执行是在构造函数的用户代码之前,所以j会先被赋值。
接下来看看下面这段代码有没有什么问题。
class C
{
private:
int i;
int j;
public:
C(int value):j(value)
{
i = j;
cout << "i = " << i << endl;
cout << "j = " << j << endl;
}
};
class D : public C
{
private:
int data;
public:
int GetValue()
{
return data;
}
D(int value):data(value),C(GetValue())
{
cout << "data = " << data << endl;
}
};
int main()
{
D objD(10);
return 0;
}

上面的代码中,在D类的构造函数使用了初始化列表,在初始化列表中调用了成员函数来给父类的构造函数传参,乍一看好像没什么问题,但是从最后的运行结果来看,i和j未被成功赋值,这是为什么呢?
这是因为在初始化列表中,父类的构造函数被优先执行,导致data还没来得及赋值。所以建议将父类的构造函数放在初始化列表的最前面,这样可以提醒自己要先检查GetValue是否能正确返回数据。另外如果要避免上述问题,可以把C(GetValue())改成C(value),注意千万不要直接把C(GetValue())挪到D类的构造函数内部,会编译失败。