基础IO
1. 重新谈论文件
1.1 准备工作
1.1.1 提出问题
在谈论文件之前先提出几个问题:
- 你真的理解文件原理和操作了吗?不是语言问题,而是系统问题
- 是不是只有C/C++有文件操作呢? python, java, go…他们的文件操作方法不同,如何理解这种现象呢?有没有一种统一视角看待所有的语言文件操作呢?
- 操作文件的时候,第一件事情都是打开文件,打开文件是做什么呢?如何理解呢?
1.1.2 达成共识
- 文件=内容+属性 => 针对文件的操作就有: 对内容的操作和对属性的操作
- 当文件没有被操作的时候,文件一般会在什么位置呢?磁盘
- 当我们对文件进行操作的时候,文件需要在哪里呢?为什么?内存,因为冯诺依曼体系
- 当我们对文件进行操作的时候,文件需要提前被加载到内存,加载的是内容还是属性?至少得有属性吧
- 当我们对文件进行操作的时候,文件需要提前被加载到内存,是不是只有你一个人把文件加载到内存呢(是不是你一个人在打开呢)? 不是,内存中一定存在大量的不同文件的属性
- 所以综上, 打开文件的本质就是将需要的文件属性加载到内存中,OS内部一定会同时存在大量的被打开的文件,那么操作系统要不要管理这些被打开的文件呢?要, 先描述,再组织(如何管理)
先描述: 构建在内存中的文件结构体 struct file{文件属性(就可以从磁盘来),struct file*next} 表明被打开的文件
每一个被打开的文件,都要在OS内创建对应文件对象的struct 结构体,可以将所有的struct file结构体用某种数据结构链接起来 => 在OS内部,对被打开的文件进行管理,就被转换成了对链表的增删查改
=> 结论: 文件被打开,OS要为被打开的文件,创建对应的内核数据结构

- 文件其实可以被分成两大类: 磁盘文件,被打开的文件(内存文件) [这篇文章前半部分谈论被打开的文件, 后半部分谈论磁盘文件]
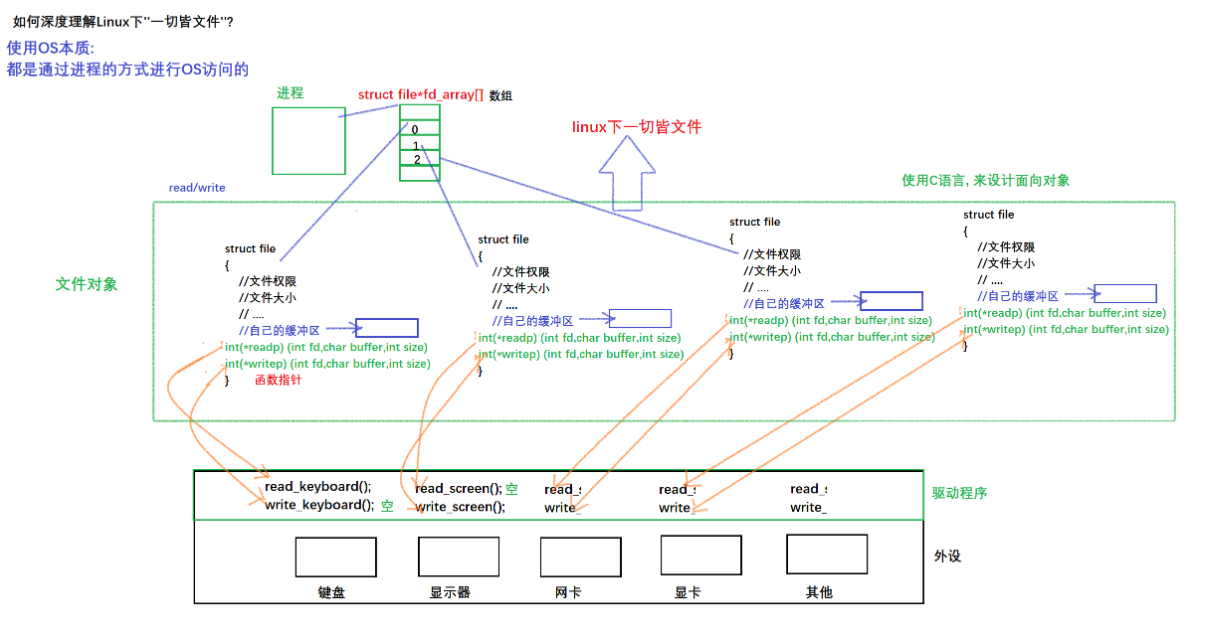
- 文件被打开,是谁在打开呢?OS,但是是谁让OS打开的呢?用户(以进程为代表的[写好的代码编译运行起来变成进程])
- 我们之前的所有文件操作,都是进程和被打开文件的关系
- 都是进程和被打开文件的关系: struct task_struct 和 struct file的关系
1.2 回忆C语言文件操作
以下的内容也可以称为文件操作的语言方案
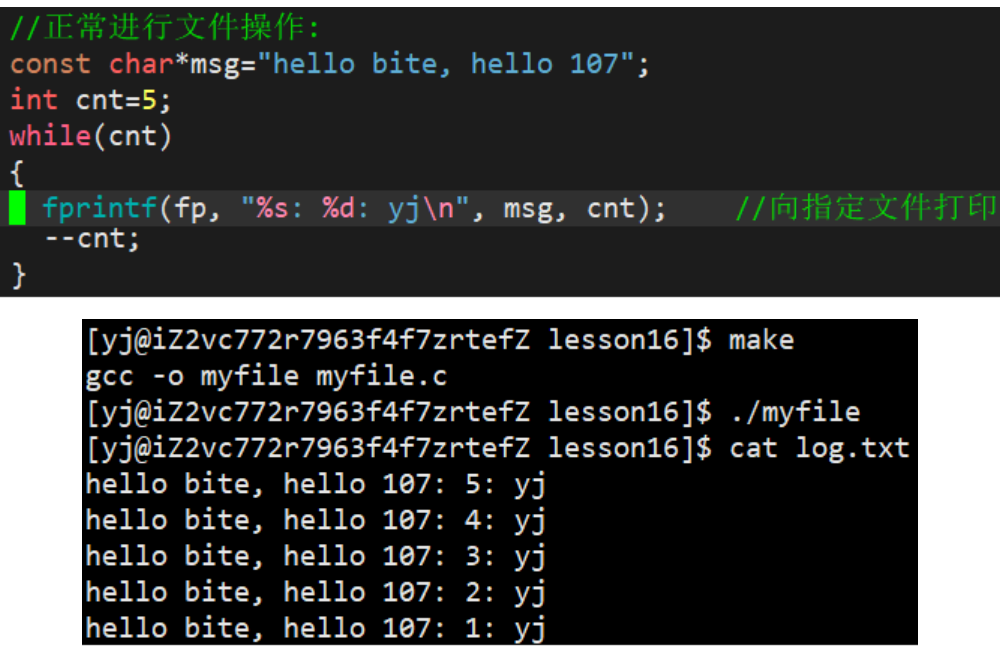
1.2.1 写文件
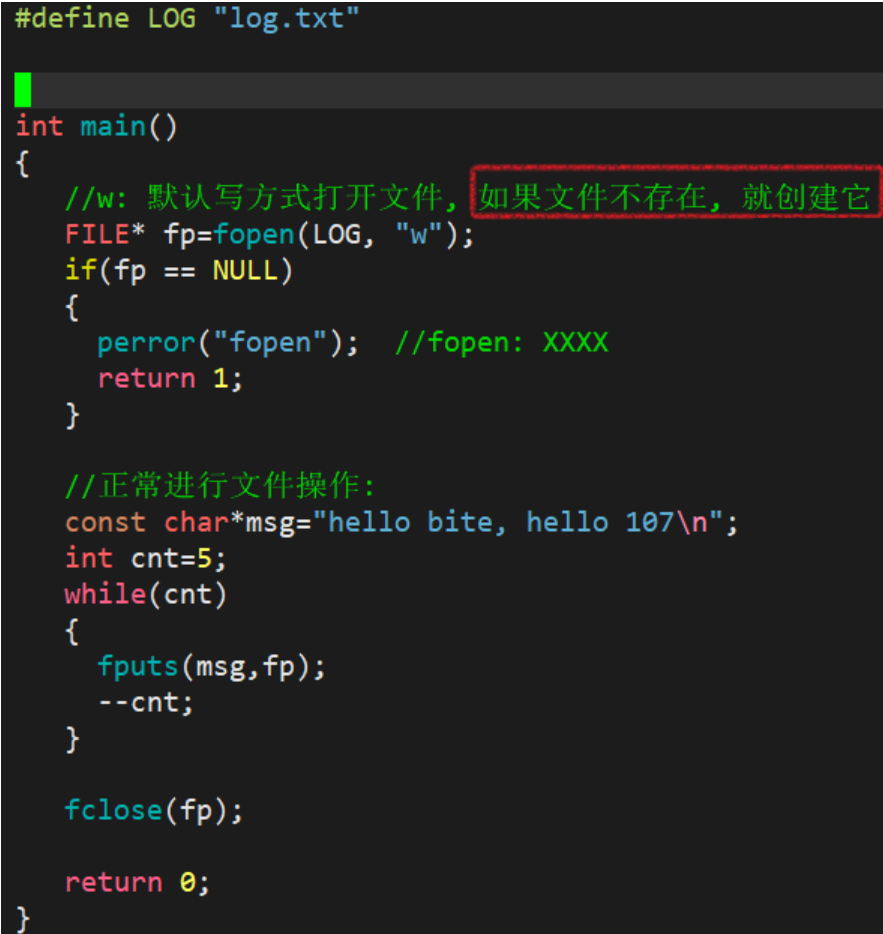
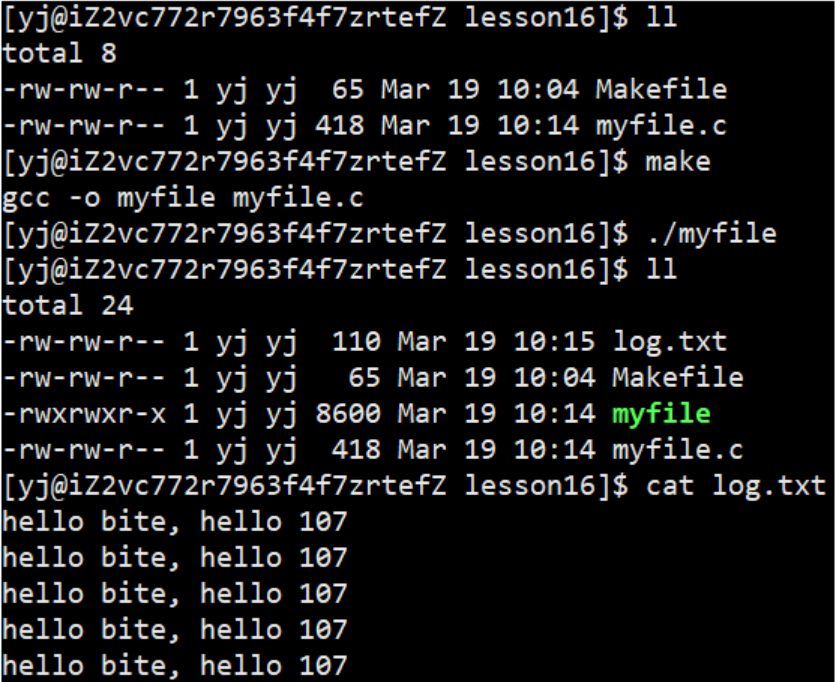
辨析

fprintf
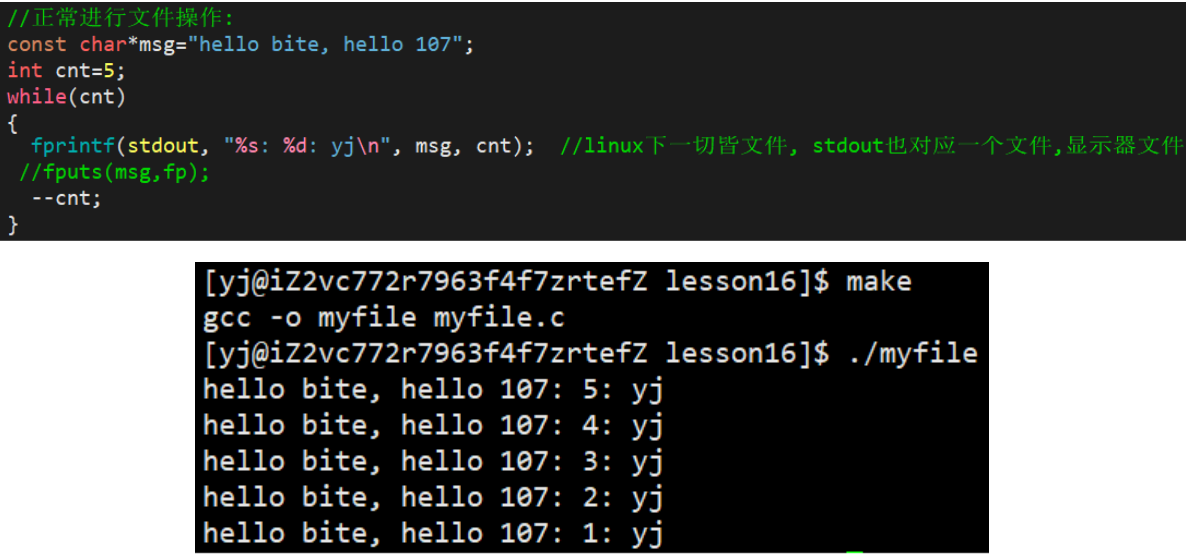
snprintf
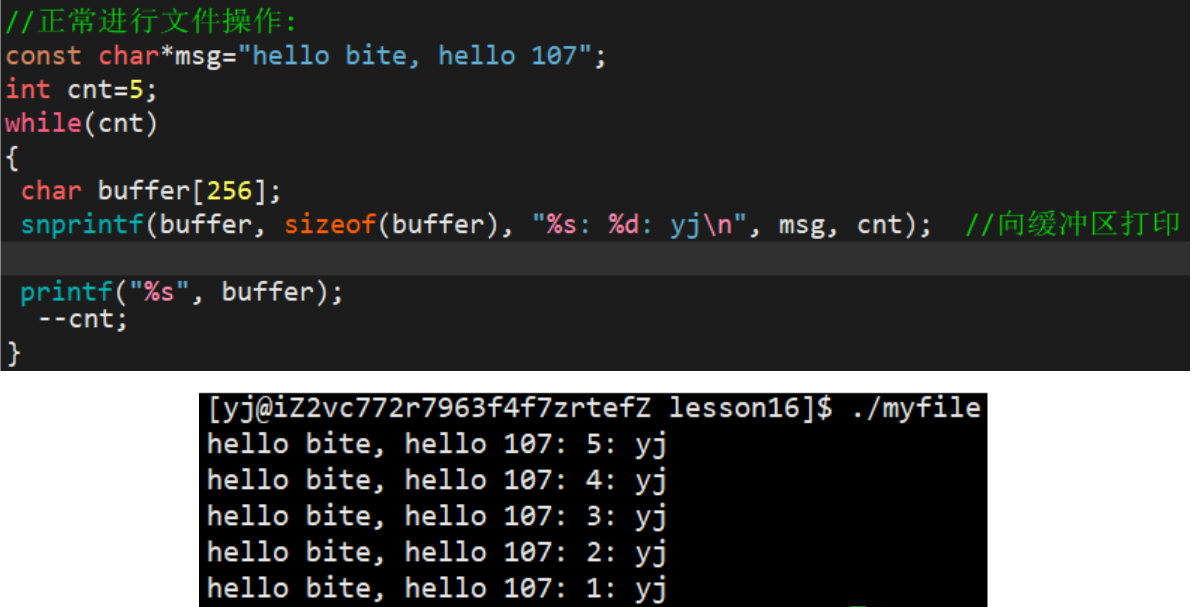
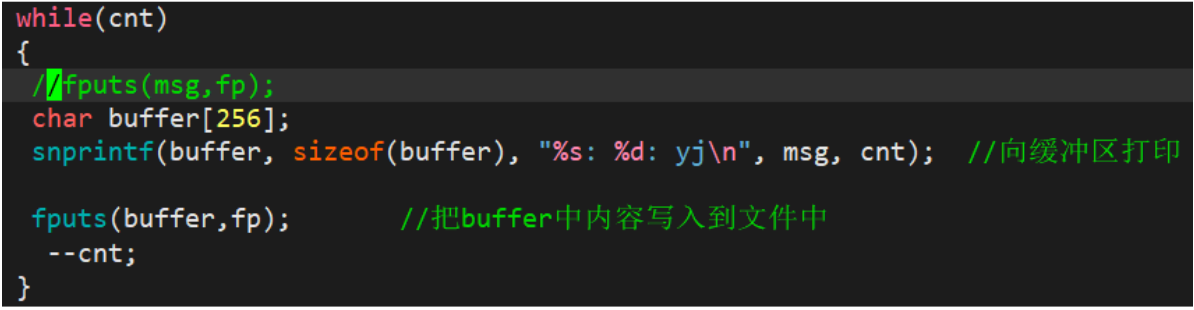
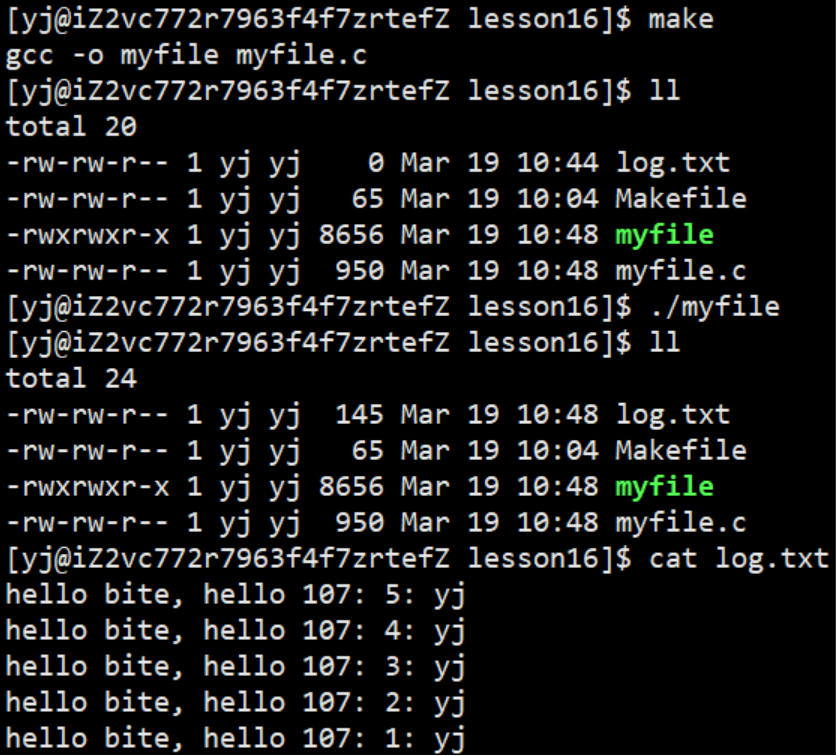
1.2.2 读文件
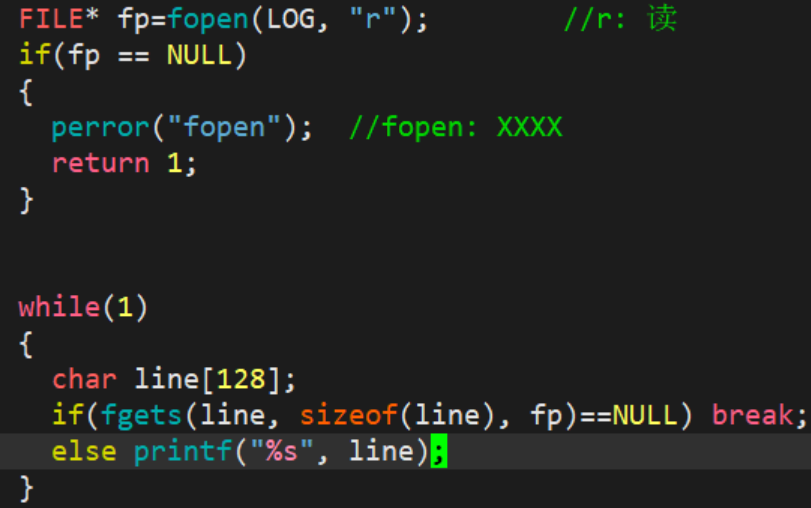
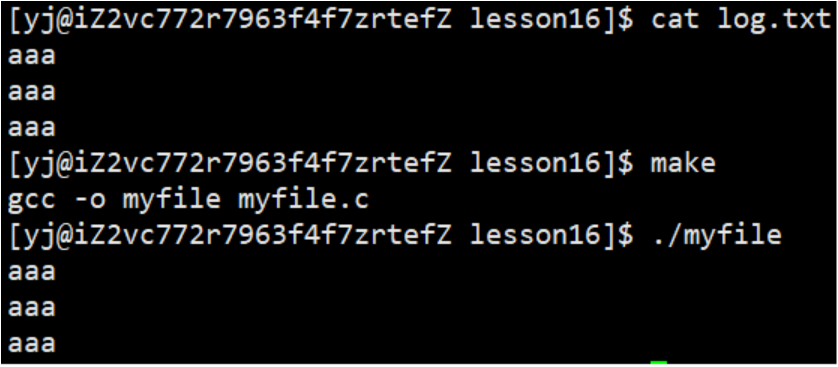
1.2.3 向文件追加
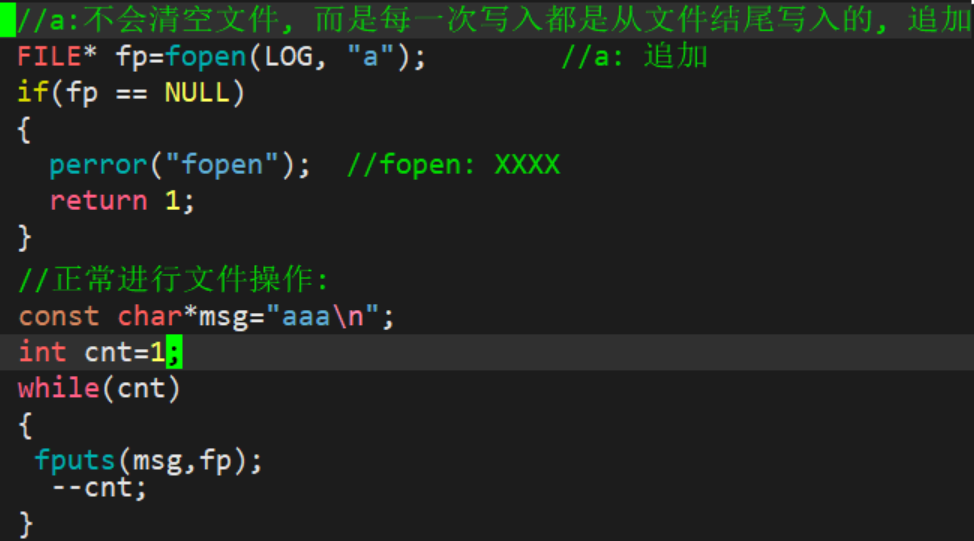
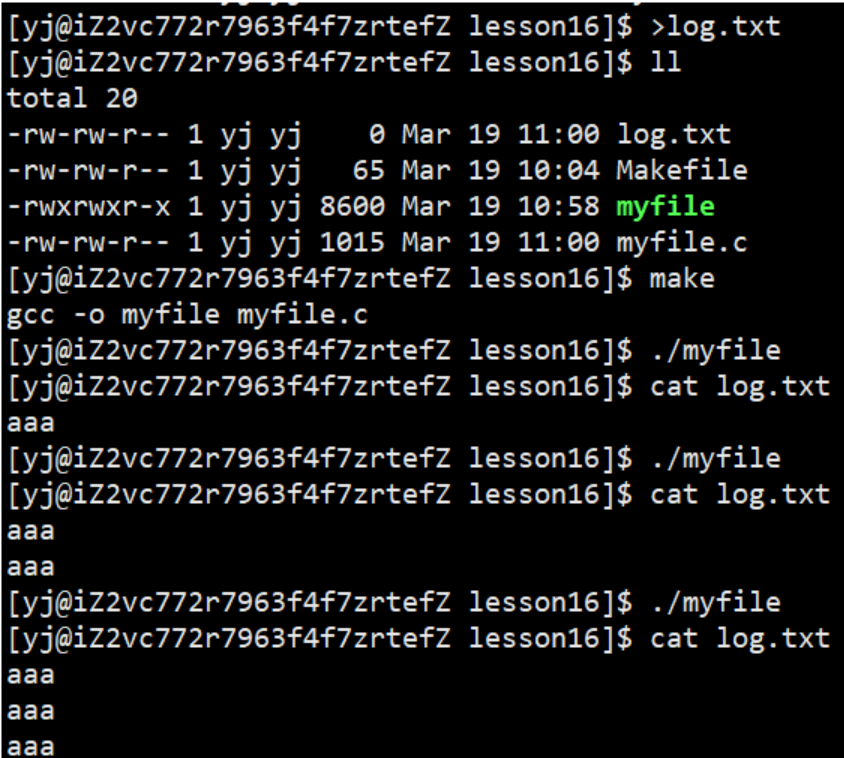
1.3 文件操作的系统调用
以下的内容也可以称为文件操作的系统方案
1.3.1 OS接口open的介绍(比特位标记)
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
pathname: 要打开或创建的目标文件
flags: 打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行“或”运算,构成flags。
参数:
O_RDONLY: 只读打开
O_WRONLY: 只写打开
O_RDWR : 读,写打开
这三个常量,必须指定一个且只能指定一个
O_CREAT : 若文件不存在,则创建它。需要使用mode选项,来指明新文件的访问权限
O_APPEND: 追加写
返回值:
成功:新打开的文件描述符
失败:-1
关于第二个参数flags, 是一种位图结构:

小演示:
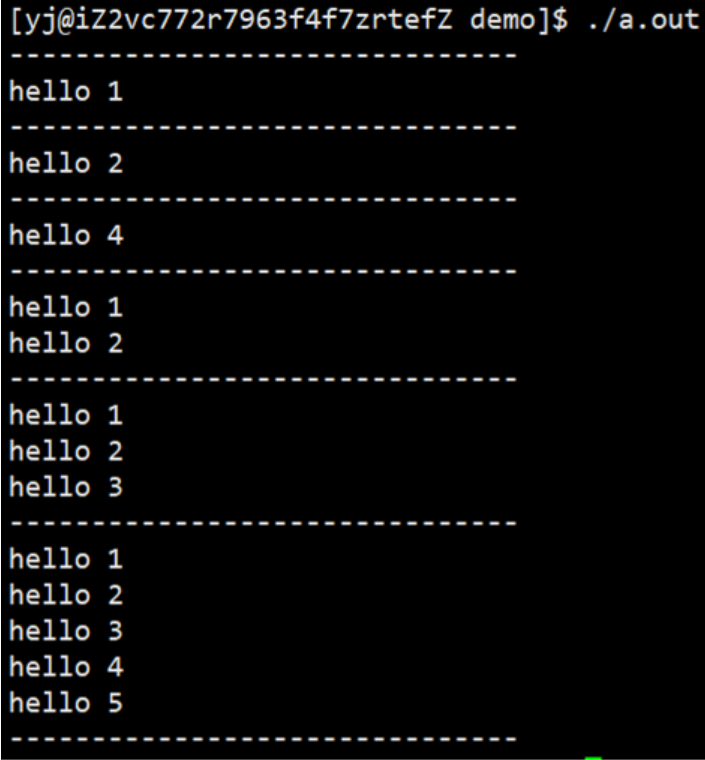
如下代码:
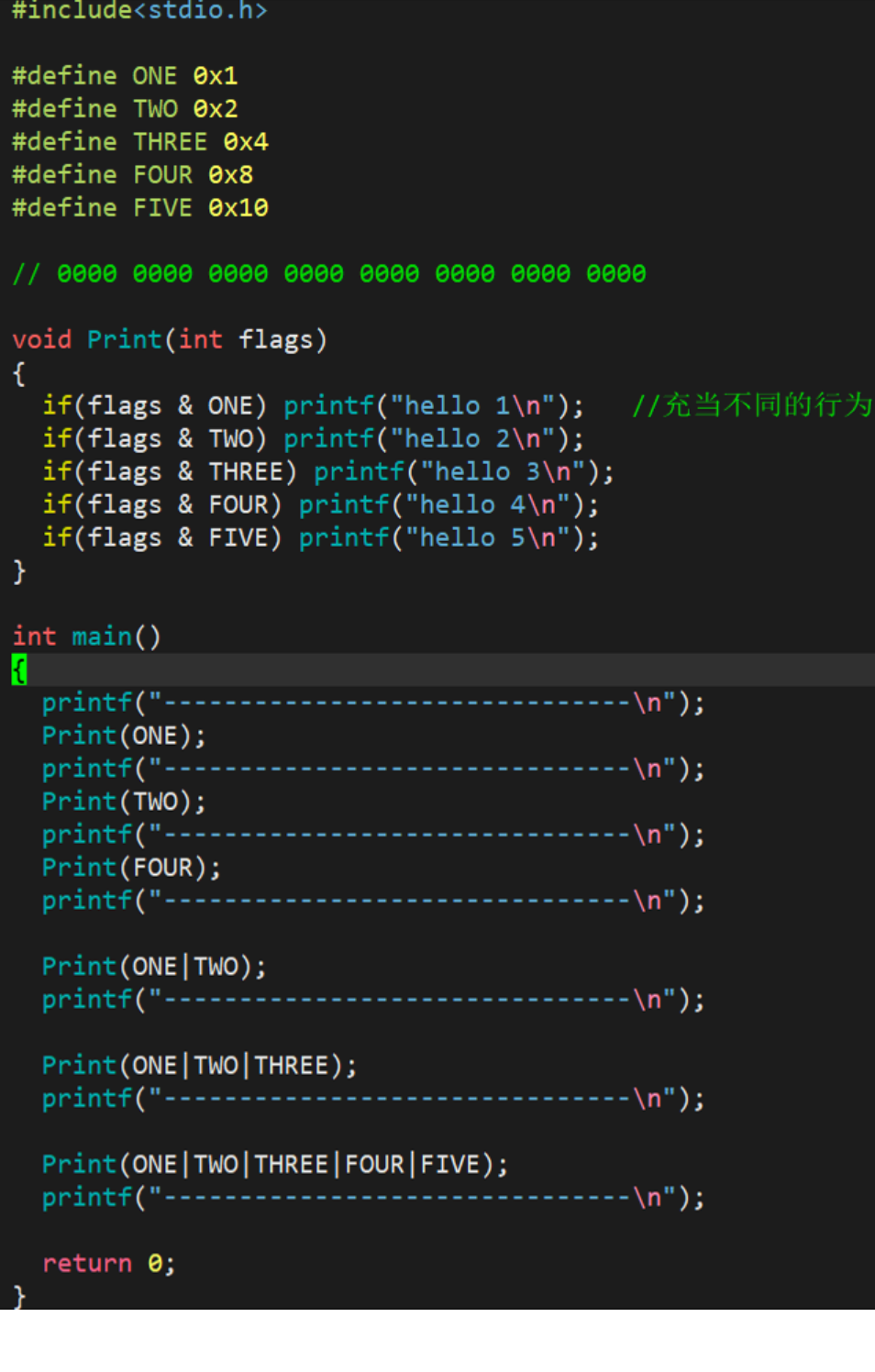
运行结果:
1.3.2 写入操作
int fd = open(FILE_NAME, O_WRONLY | O_CREAT | O_TRUNC, 0666);
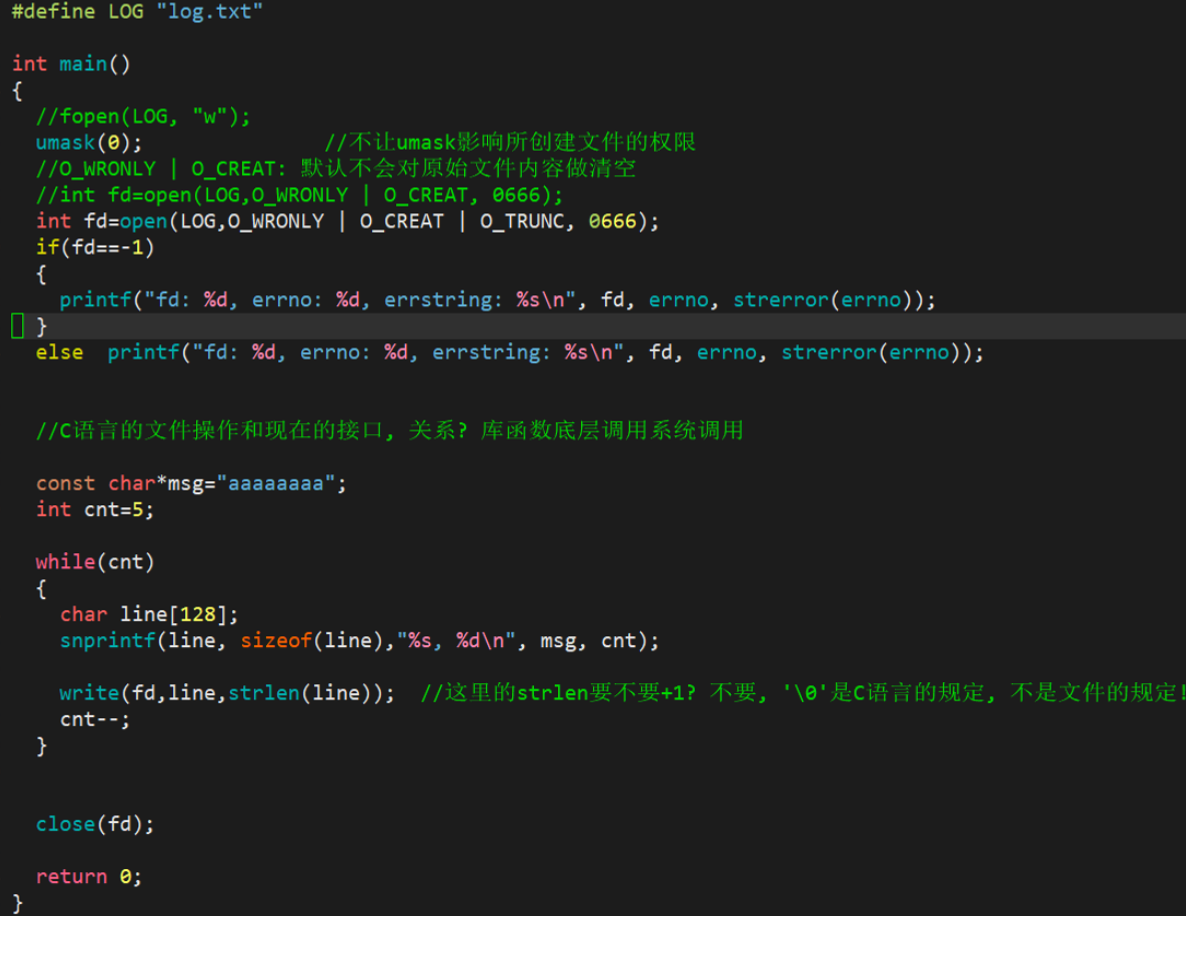
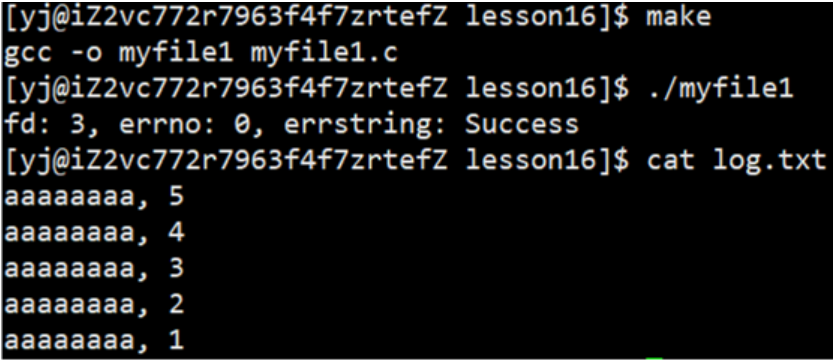
1.3.3 追加操作
int fd = open(FILE_NAME, O_WRONLY | O_CREAT | O_APPEND, 0666);
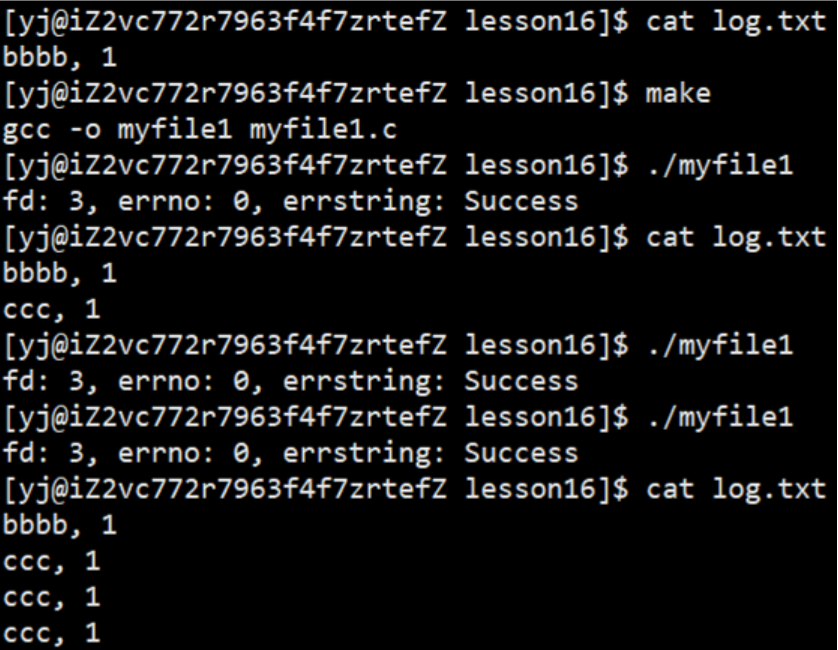
1.3.4 只读操作
int fd = open(FILE_NAME, O_RDONLY);

1.4 回答问题
回答上面提出的问题:
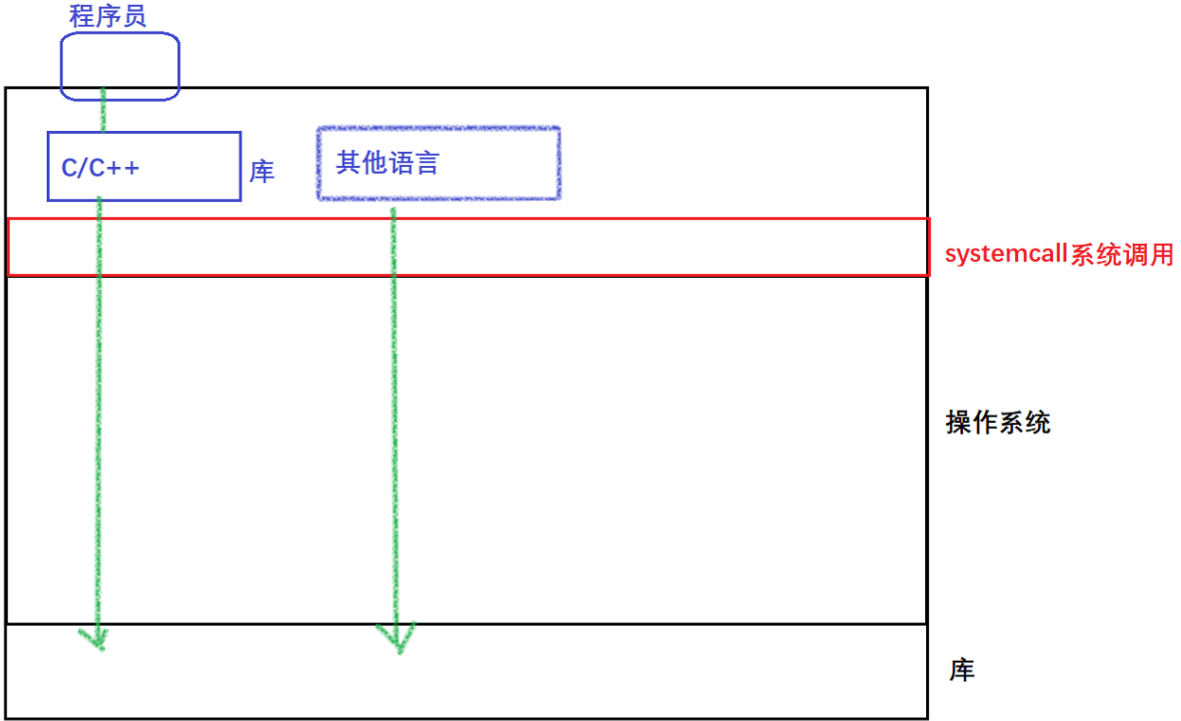
- 是不是只有C/C++有文件操作呢? python, java, go…他们的文件操作方法不同,如何理解这种现象呢?有没有一种统一视角看待所有的语言文件操作呢?
不只是C/C++有文件操作,其他语言也有; 各个语言文件操作方法不同是因为不同语言对文件操作做了个性化封装以满足不同语言的语法范式;统一视角看待所有的语言文件操作: 都是去调用系统的接口来完成文件操作的
- 操作文件的时候,第一件事情都是打开文件,打开文件是做什么呢?如何理解呢?
打开文件的本质就是将需要的文件属性加载到内存中, 每一个被打开的文件,都要在OS内创建对应文件对象的struct 结构体,可以将所有的struct file结构体用某种数据结构链接起来 => 在OS内部,对被打开的文件进行管理,就被转换成了对链表的增删查改
2. 深入理解文件系统调用
2.1 文件描述符
- 学习文件系统调用函数open,我们发现open函数会有一个返回值, 这个返回值就是文件描述符, 文件描述符就是一个小整数
以写的方式打开LOG文件(log.txt文件)并接收这个返回值, 打印出文件描述符, 观察运行结果
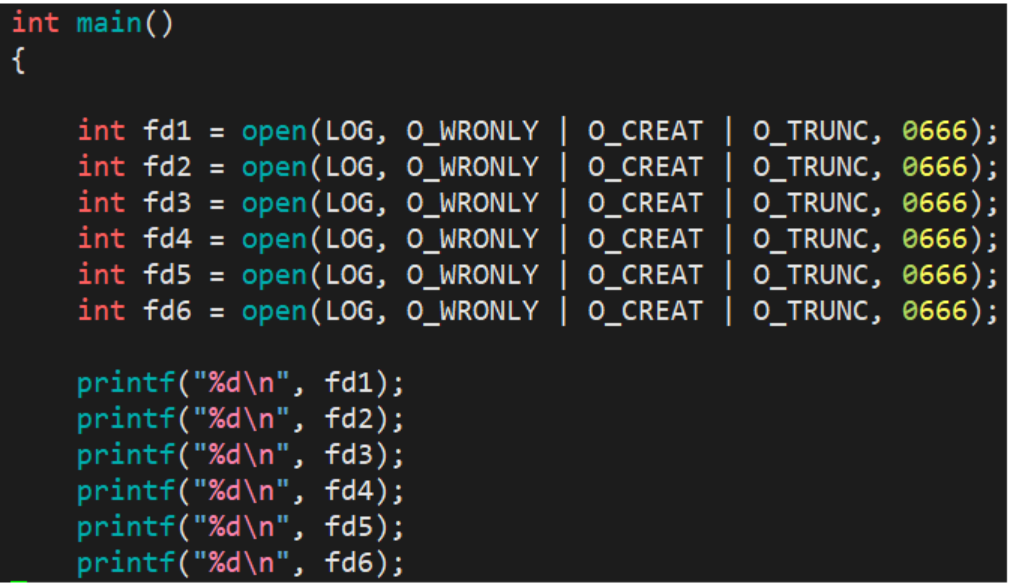
运行结果:
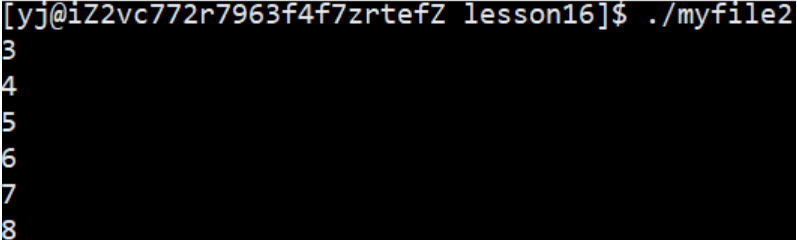
我们会发现, 打印结果是从3开始,依次连续递增, 于是我们就引出了两个问题:
- 为什么结果是从3开始,而不是从0开始,依次0, 1 , 2…
- 什么样的结构会像上面的结果一样连续依次递增呢?
下面我们来解决这两个问题
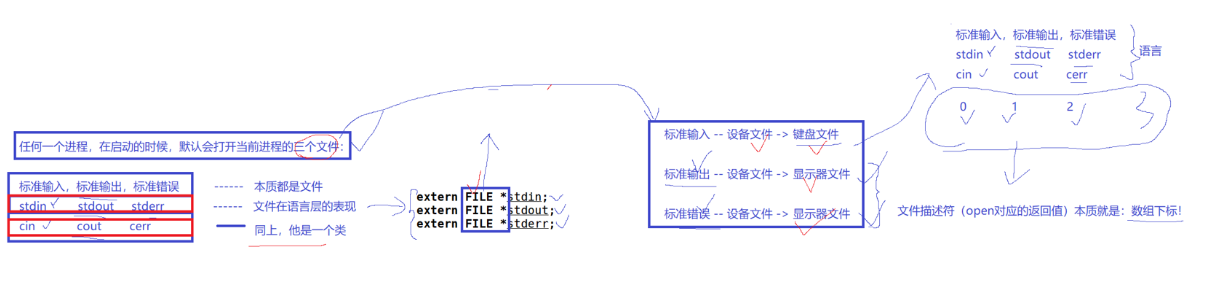
2.1.1 stdin & stdout & stderr
C默认会打开三个输入输出流,分别是stdin, stdout, stderr
仔细观察发现,这三个流的类型都是FILE, fopen返回值类型,文件指针*
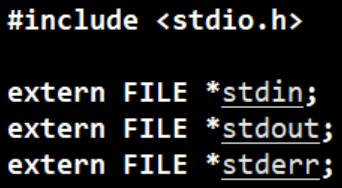
小演示:
写如下代码:
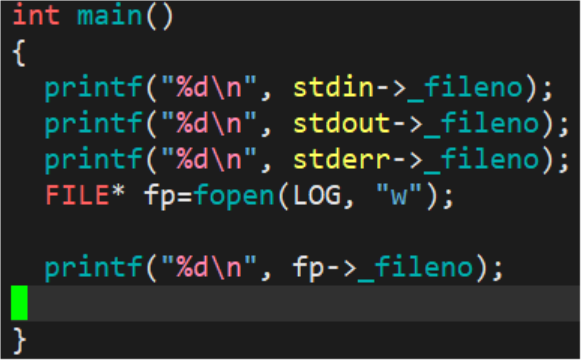
运行观察发现:
这时打印出了0, 1, 2
因此这也就解释了为什么文件描述符默认是从3开始的,因为0,1,2默认被占用。我们的C语言的这批接口封装了系统的默认调用接口。同时C语言的FILE结构体也封装了系统的文件描述符。
理解FIEL
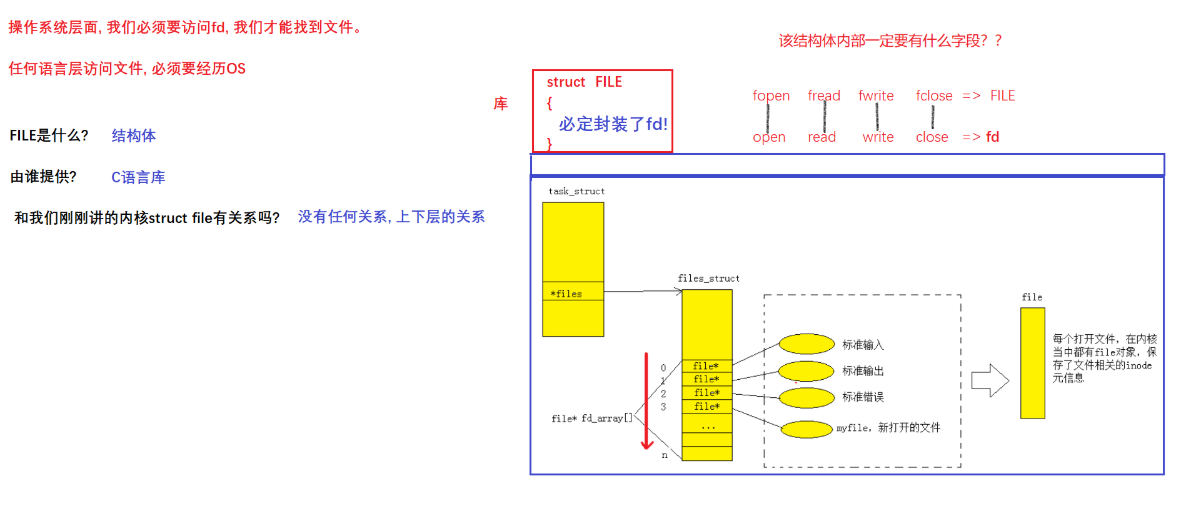
总结
- Linux进程默认情况下会有3个缺省打开的文件描述符,分别是标准输入0, 标准输出1, 标准错误2.
- 0,1,2对应的物理设备一般是:键盘,显示器,显示器
2.1.2 文件描述符的本质
解决第二个问题,什么样的结构会像上面的结果一样连续依次递增呢?
如下图:
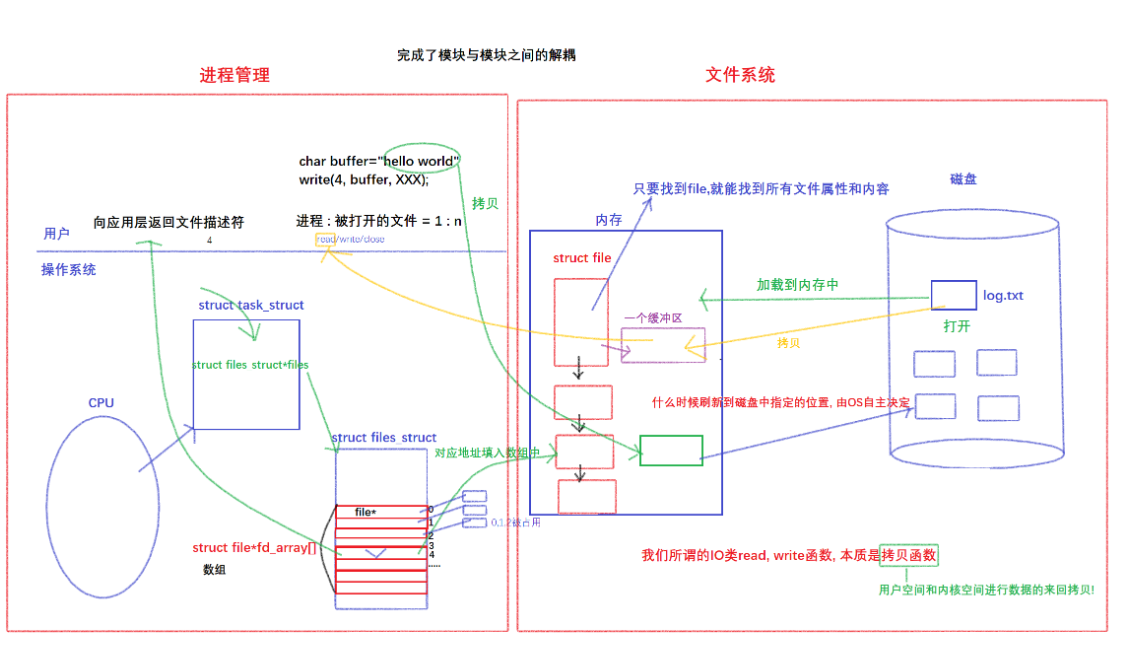
PCB中包含一个files指针,他指向一个属于进程和文件对应关系的一个结构体:struct files_struct,而这个结构体里面包含了一个数组叫做struct file* fd _array[]的指针数组,因此如图前三个0、1、2被键盘和显示器调用,这也就是为什么之后的文件描述符是从3开始的,然后将文件的地址填入到三号文件描述符里,此时三号文件描述符就指向这个新打开的文件了。
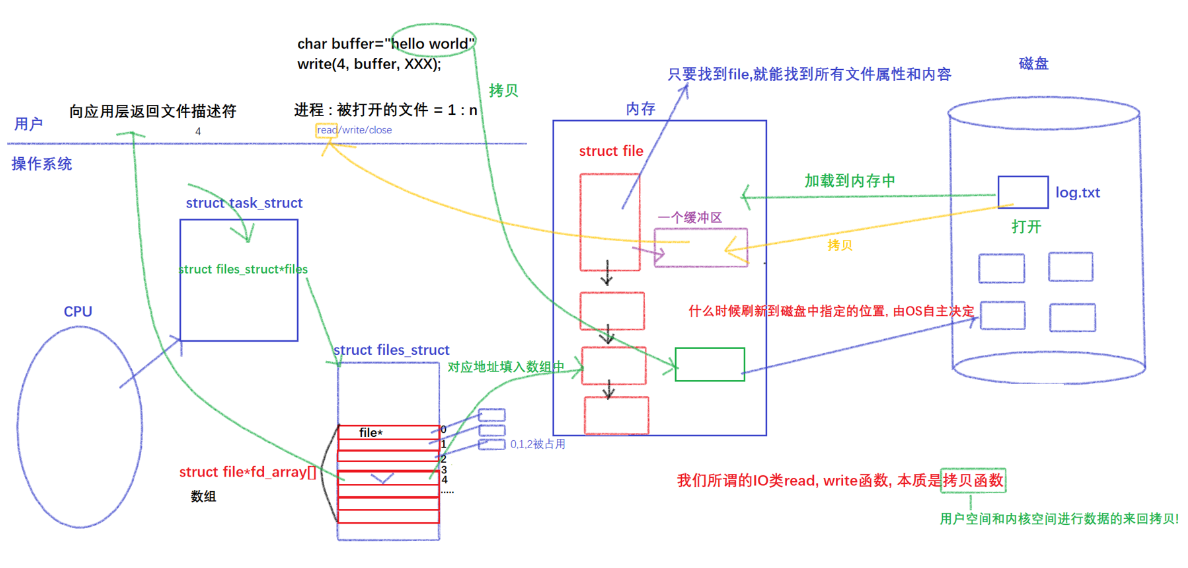
再把3号描述符通过系统调用给用户返回就得到了一个数字叫做3,所以在一个进程访问文件时,需要传入3,通过系统调用找到对应的文件描述符表,从而通过存储的地址找到对应的文件,文件找到了,就可以对文件进行操作了。因此文件描述符的本质就是数组下标。
那么这样做有什么好处呢?
如下图, 左边是进程管理,右边是文件系统,完成了模块与模块之间的解耦
2.1.3 文件fd的分配规则
直接看代码:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
int fd = open("myfile", O_RDONLY);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}
输出发现是 fd: 3
关闭0或2,再看
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
close(0);
//close(2);
int fd = open("myfile", O_RDONLY);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}
发现是结果是: fd: 0 或者 fd 2
文件描述符的分配规则:在files_struct数组当中,找到当前没有被使用的最小的一个下标,作为新的文件描述符。
3. 重定向
3.0 什么是重定向
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
close(1);
int fd = open("myfile", O_WRONLY|O_CREAT, 00644);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}
根据上面讲到的文件描述符的分配规则,这段代码我们按照顺序进行解释:
首先关闭文件描述符1所对应的stdout(标准输出:输出到显示器),然后通过f分配,这个文件的fd会从小到大扫描发现1的位置没有被使用,于是就会将这个新创建的文件myfile与对应的指针进行连接:
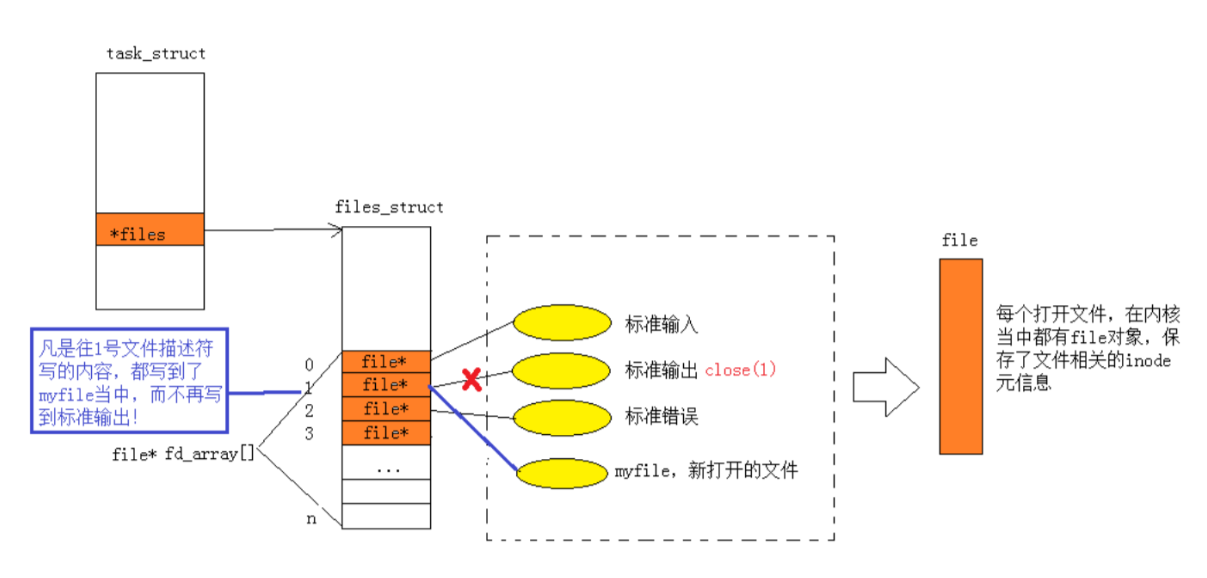
因此当我们的printf打印到stdout时,由于上层的文件描述符stdout对应的还是1,就会在内核中找到array[1]中对应的文件进行操作,但此时1对应的已经不是标准输出到显示器,而是myfile文件,因此我们在打印时也就不会在显示器中看到fd的值,而是在myfile文件中。
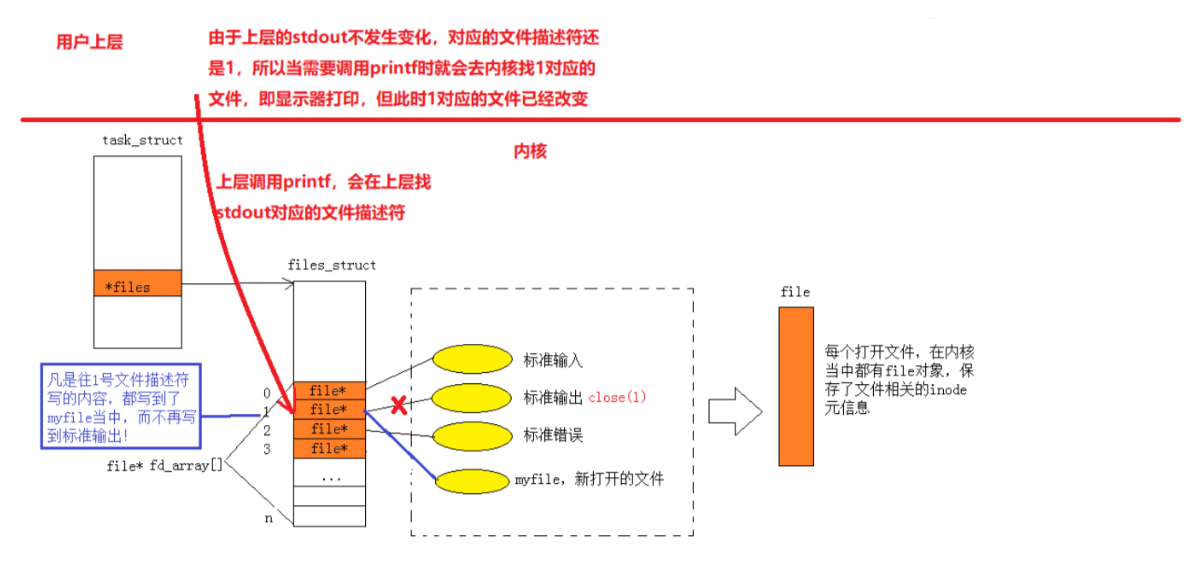
- 重定向的本质: 在上层无法感知的情况下,在OS内部,更改进程对应的文件的描述符表中特定的下标
3.1 3种重定向
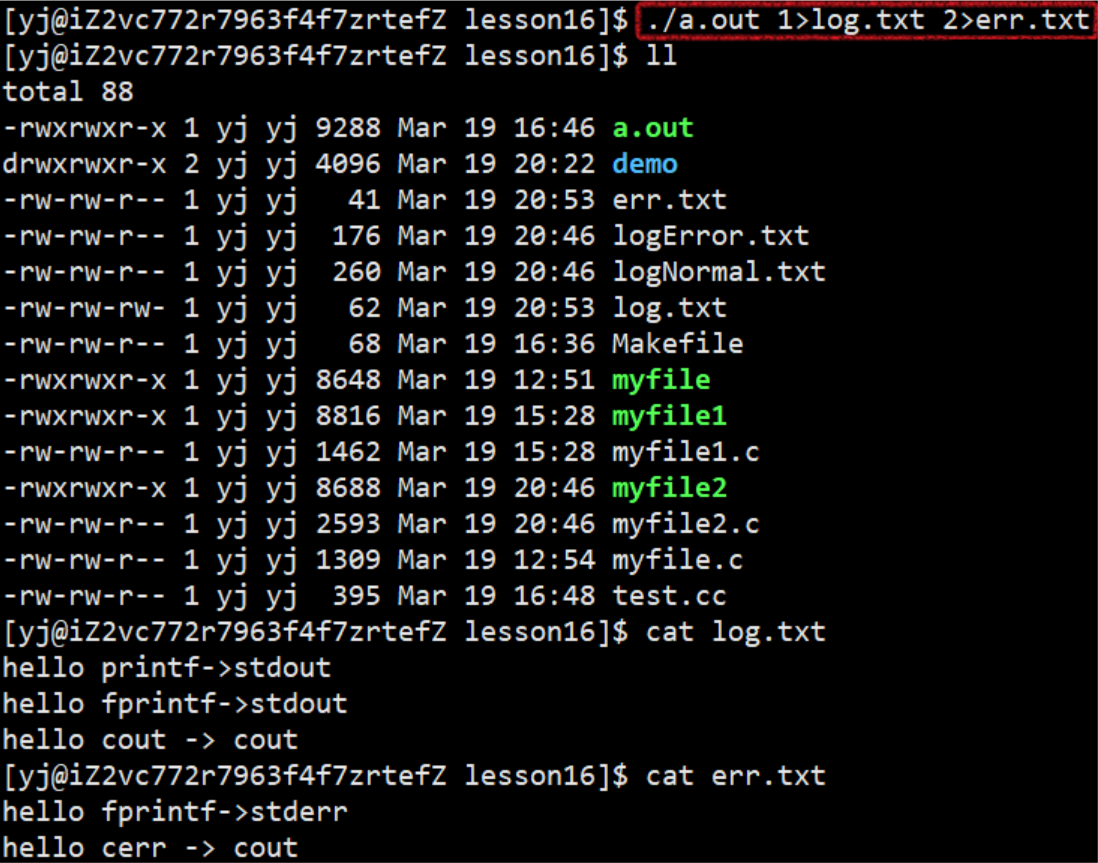
3.1.1 输出重定向
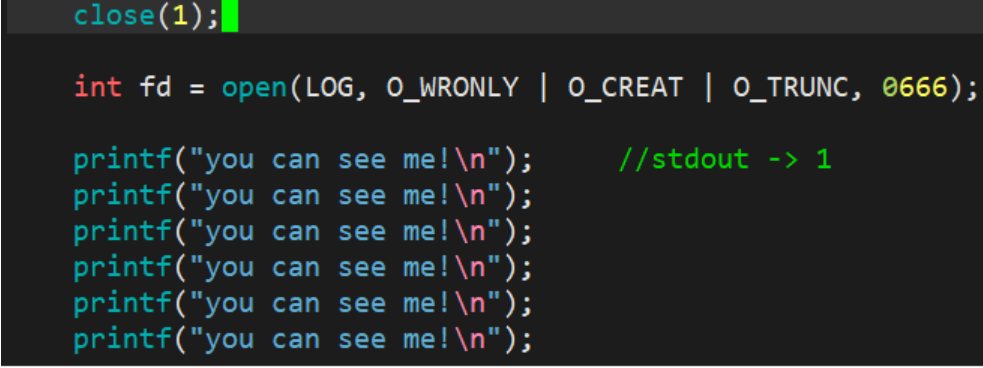
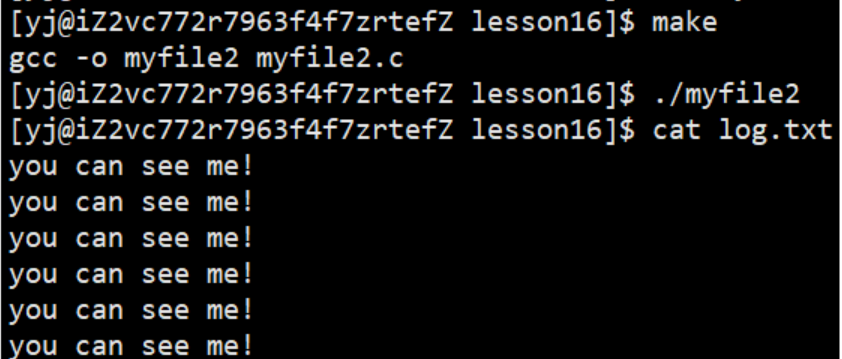
此时,我们发现,本来应该输出到显示器上的内容,输出到了文件log.txt当中,其中,fd=1。这种现象叫做输出重定向。
3.1.2 输入重定向
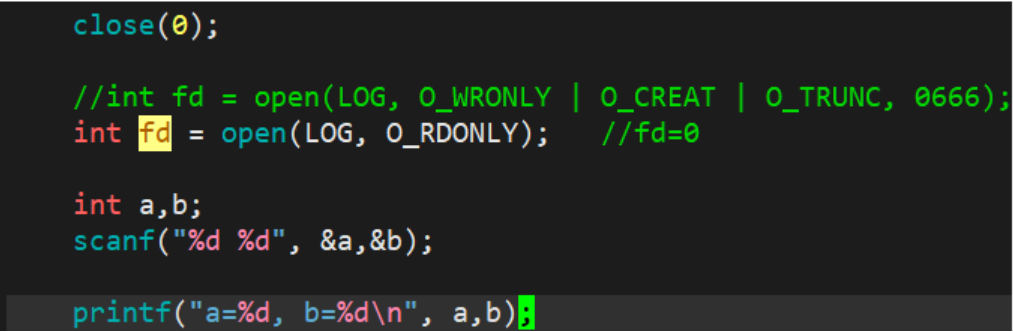
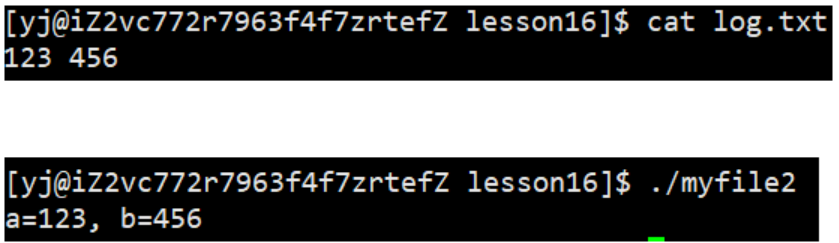
此时,我们发现,本来应该通过键盘来输入内容,直接从文件log.txt中读取内容,其中,fd=0。这种现象叫做输入重定向。
3.1.3 追加重定向
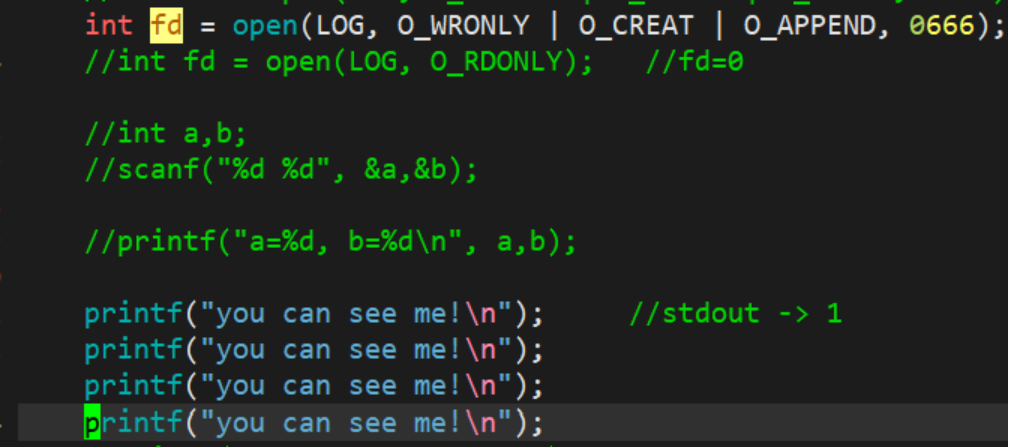
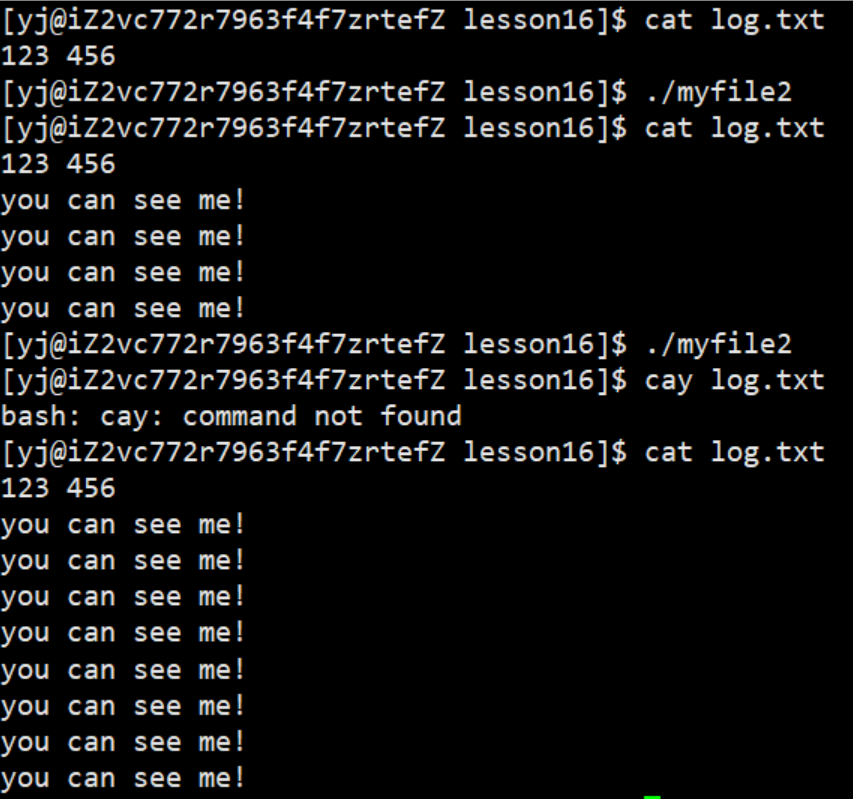
此时,我们发现,本来应该追加输出到显示器上的内容,追加输出到了文件log.txt当中,其中,fd=1。这种现象叫做追加重定向。
3.1.4 补充
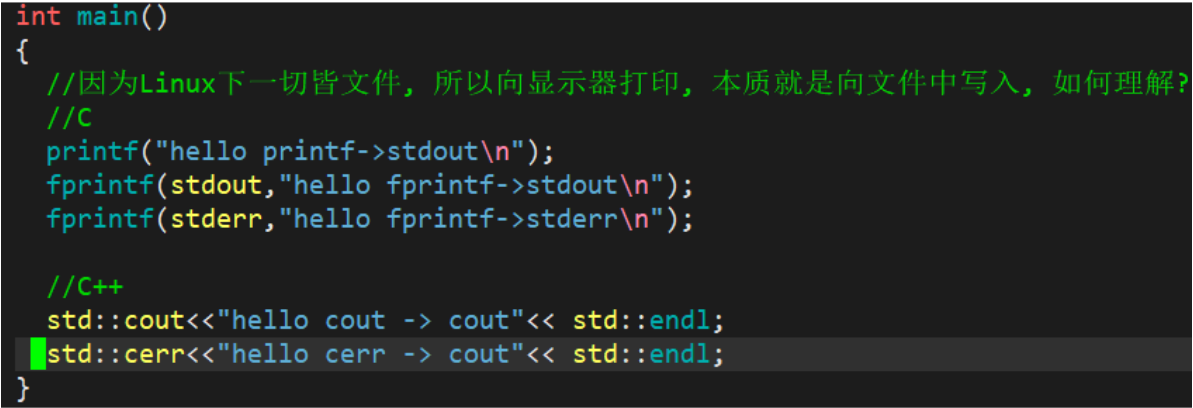
运行结果:

一起打印到显示器上:
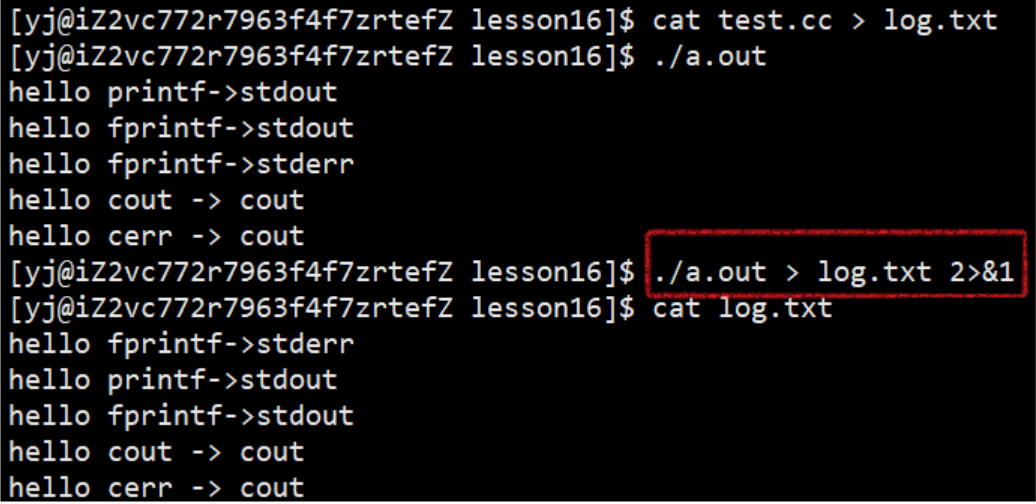
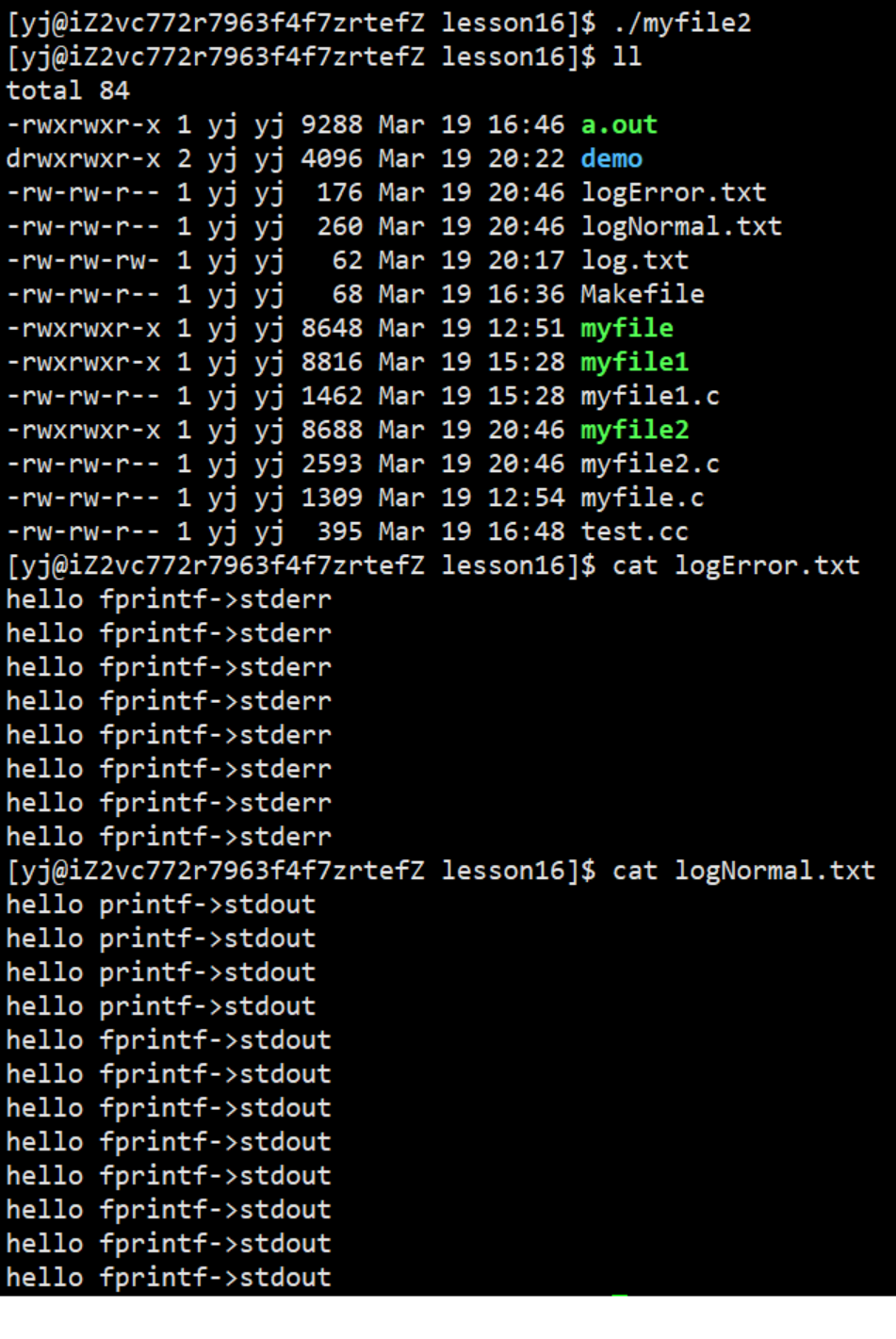
常规消息打印到log.normal, 异常消息打印到log.error
解决方法:
- 写代码:
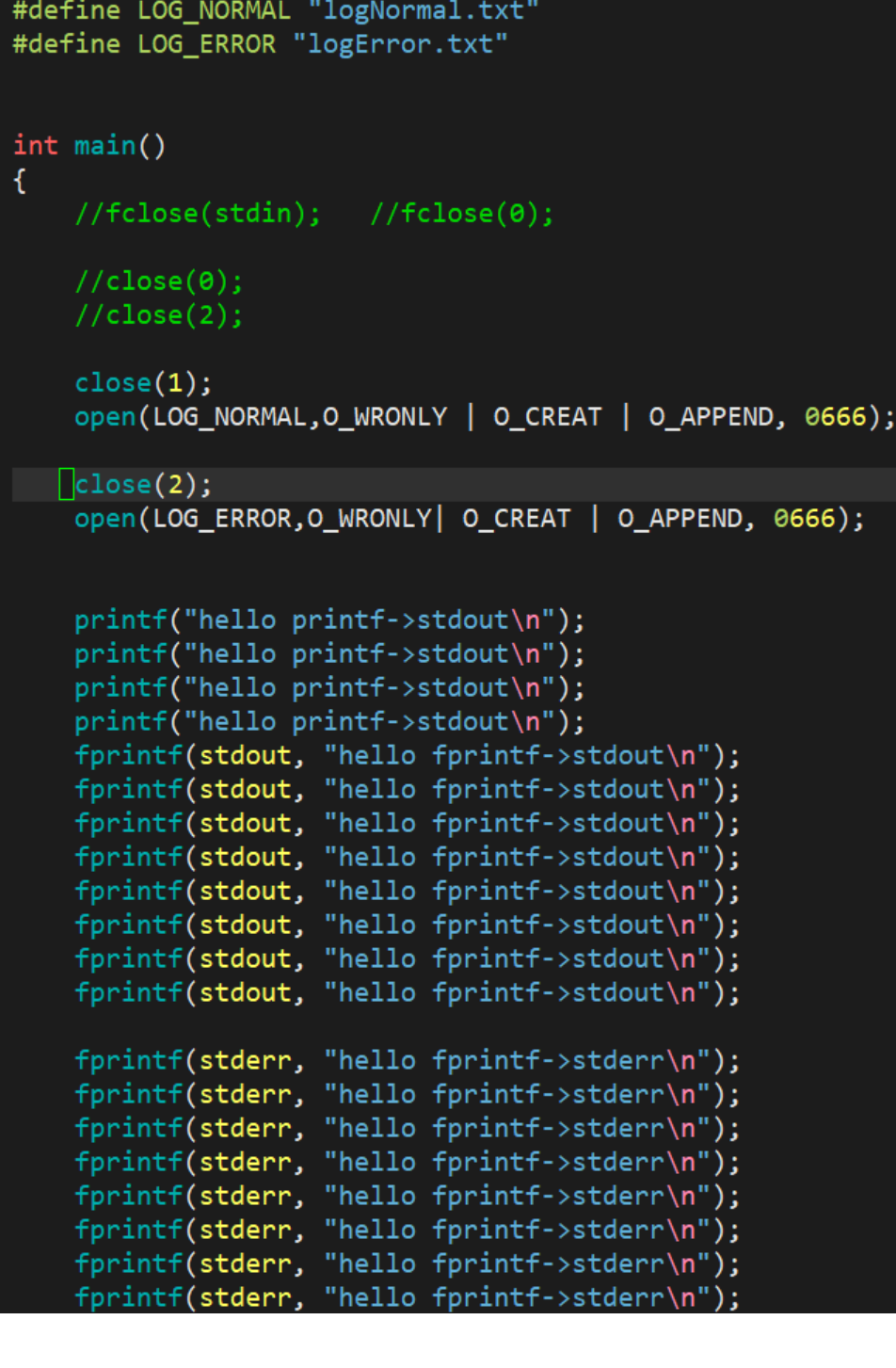
- 几句简单重定向指令:
3.2 dup2 系统调用的重定向
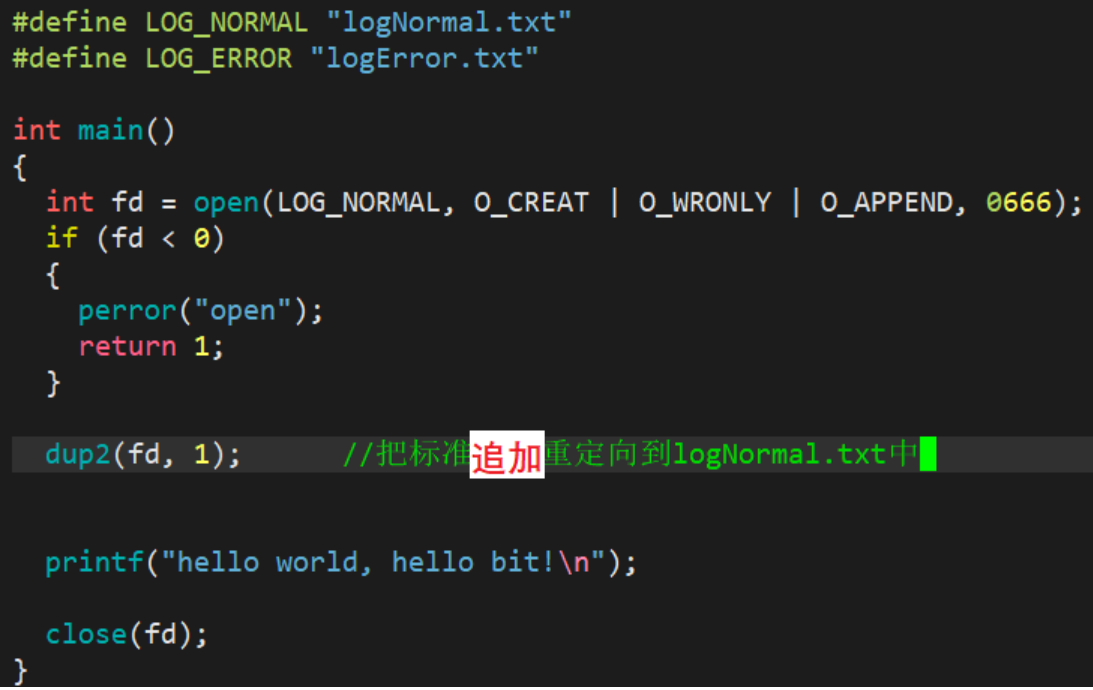
在上面演示的无论是分配规则还是重定向,直接以close关闭的操作非常的麻烦,因为这样的close操作不够灵活,所以现在介绍一个系统调用的重定向接口:dup2
int dup2(int oldfd, int newfd);//newfd的内容最终会被oldfd指向的内容覆盖
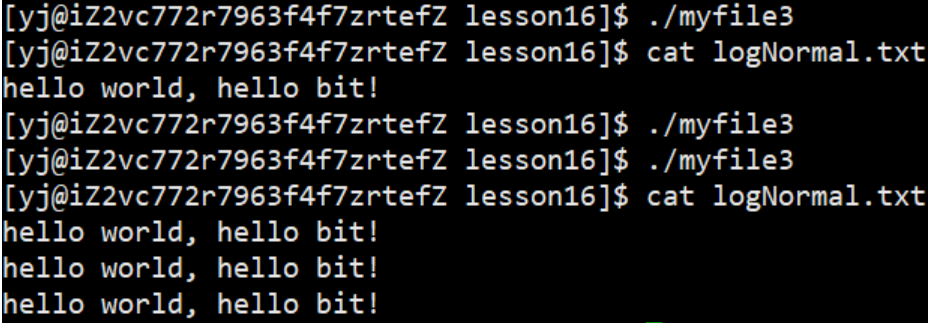
演示:
4. 如何理解Linux下一切皆文件
5. 缓冲区
5.1 知识介绍
5.1.1 引入现象
分别用C语言的函数和系统调用接口向显示器上打印字符串
#include <stdio.h>
#include <unistd.h>
#include<string.h>
int main()
{
//C库
fprintf(stdout, "hello fprintf\n");
//系统调用
const char *msg = "hello write\n";
write(1, msg, strlen(msg)); //+1?
return 0;
}
结果:

在此代码的基础上添加fork后
#include <stdio.h>
#include <unistd.h>
#include<string.h>
int main()
{
//C库
fprintf(stdout, "hello fprintf\n");
//系统调用
const char *msg = "hello write\n";
write(1, msg, strlen(msg)); //+1?
//代码结束之前,进行创建子进程
fork();
return 0;
}
结果:
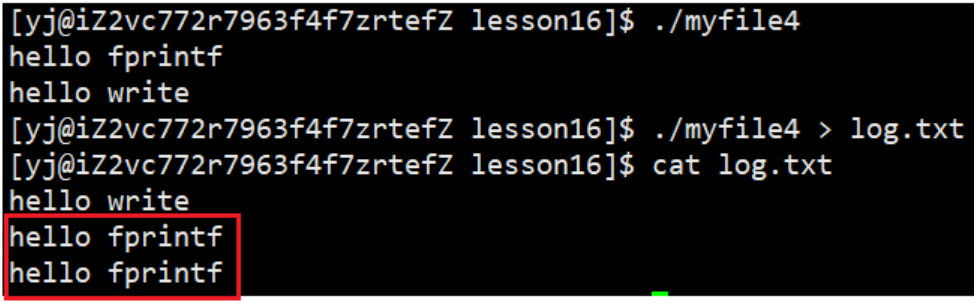
直接运行仍是正常的现象,但当重定向到log.txt中,C接口的打印了两次,为什么会出现这种现象呢?
5.1.2 理解缓冲区
5.1.2.1 为什么要有缓冲区
举一个例子:
A与B两人互为好友, 一天在西安的A想给在北京的B寄东西, 他可以选择从西安骑自行车到北京把东西交给B, 理论上可以, 但会耗费A大量的时间; 于是他选择把东西交给快递公司, 让快递公司帮他寄东西, 很快B就收到了。

现实生活中,快递行业的意义就是节省发送者的时间,而对于这个例子来说,西安就相当于内存,发送者A相当于进程,包裹就是进程需要发送的数据,北京就相当于磁盘,B就是磁盘上的文件,那么可以看成这样:

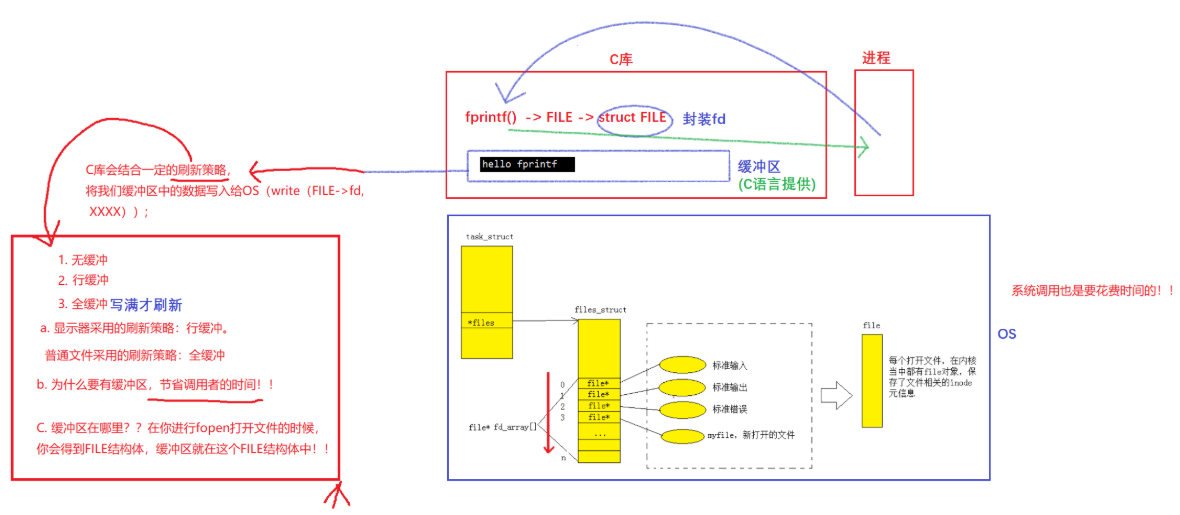
在冯诺依曼体系中,我们知道内存直接访问磁盘这些外设的速度是相对较慢的,即正如我们所举的例子一样,A亲自送包裹会占用A大量的时间,因此顺丰同样属于内存中开辟的一段空间,将我们在内存中已有的数据拷贝到这段空间中,拷贝函数就直接返回了,即A接收到顺丰的通知就离开了。在执行你的代码期间,顺丰对应的内存空间的数据也就是包裹就会不断的发送给对方,即发送给磁盘。而这个过程中,顺丰这块开辟的空间就相当于缓冲区。
那么缓冲区的意义是什么呢?——节省调用者的时间。系统调用也是要花费时间的
5.1.2.2 缓冲区刷新策略
- 无缓冲,立即刷新
- 行缓冲,行刷新
- 全缓冲,缓冲区写满才刷新
(1) 显示器采用刷新策略: 行缓冲
(2) 普通文件采用刷新策略: 全缓冲
5.1.2.3 缓冲区在哪里
在你进行fopen打开文件的时候, 你会得到FILE结构体, 缓冲区就在这个FILE结构体中
5.1.3 解释打印两次原因
-
write是系统调用, 没有缓冲区, 直接调用写给操作系统, 所以在两种情况下都只会打印1次
-
向显示器打印时, 刷新方案是行缓冲, fork之前字符串已经从缓冲区中被刷新走了, fork啥也没干
-
重定向到文件时, fprintf 将数据写入缓冲区, 刷新方案由行缓冲变成全缓冲, 一句字符串没有办法把缓冲区写满, fork之前fprintf要写的字符串仍在缓冲区里并没有被刷新, fork后创建子进程, stdout属于父进程,创建子进程时,紧接着就是进程退出!无论谁先退出,都一定会进行缓冲区的刷新(就是修改缓冲区)一旦修改,由于进程具有独立性,因此会发生写时拷贝,因此数据最终会打印两份。
5.2 自主封装FILE
以下是实现的是一个demo版本,重点在于呈现原理
提前说明一下: 当我们关闭文件的时候, fclose(FILE*), C语言要帮助我们进行冲刷缓冲区
mystdio.h
#pragma once
#include<stdio.h>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<malloc.h>
#include<fcntl.h>
#include<unistd.h>
#include<assert.h>
#define NUM 1024
#define BUFF_NONE 0x1 //无缓冲
#define BUFF_LINE 0x2 //行缓冲
#define BUFF_ALL 0x4 //全缓冲
typedef struct _MY_FILE
{
int fd;
char outputffer[NUM]; //输出缓冲区
int flags; //刷新方式
int current; //outputbuffer下一次要写入的位置
}MY_FILE;
MY_FILE *my_fopen(const char *path, const char *mode);
size_t my_fwrite(const void *ptr, size_t size, size_t nmemb, MY_FILE *stream);
int my_fclose(MY_FILE *fp);
int my_fflush(MY_FILE *fp);
mystdio.c
#include "mystdio.h"
// fopen("/a/b/c.txt", "a");
// fopen("/a/b/c.txt", "r");
// fopen("/a/b/c.txt", "w");
MY_FILE *my_fopen(const char *path, const char *mode)
{
//1. 识别标志位 --- 判断文件打开方式
int flag=0;
if(strcmp(mode, "r")==0) flag |= O_RDONLY;
else if(strcmp(mode, "w")==0) flag |= (O_CREAT | O_WRONLY | O_TRUNC);
else if(strcmp(mode, "a")==0) flag |= (O_CREAT | O_WRONLY | O_APPEND);
else{
//其他的一些打开方式
}
//2. 尝试打开文件
mode_t m = 0666; //设置创建文件的默认权限
int fd=0;
if(flag & O_CREAT) fd = open(path, flag, m);
else fd = open(path, flag);
if(fd<0) return NULL;
//3. 给用户返回MY_FILE对象, 需要先进行构建
MY_FILE* mf = (MY_FILE*)malloc(sizeof(MY_FILE));
if(mf == NULL) //打开文件失败
{
close(fd);
return NULL;
}
//4. 初始化MY_FILE对象
mf->fd=fd;
mf->flags=BUFF_LINE; //默认刷新方式: 行刷新
memset(mf->outputffer, '\0', sizeof(mf->outputffer));
//或: my->outputbuffer[0]=0; //初始化缓冲区
mf->current=0; //开始时, 缓冲区中数据为0
//5. 返回打开的文件
return mf;
}
// 我们今天返回的就是一次实际写入的字节数,我就不返回个数了
size_t my_fwrite(const void *ptr, size_t size, size_t nmemb, MY_FILE *stream)
{
//1. 缓冲区如果已经满了,就直接刷新
if(stream->current == NUM) my_fflush(stream);
//2. 根据缓冲区剩余情况, 进行数据拷贝即可
size_t user_size = size*nmemb; //用户想写的字节
size_t my_size=NUM - stream->current; //我还剩余的字节
size_t writen = 0; //实际所写字节数
if(my_size >= user_size) //足以容纳用户想写的数据
{
memcpy(stream->outputffer+stream->current, ptr, user_size);
//3. 更新计数器字段
stream->current+=user_size;
writen=user_size;
}
else //空间不够
{
memcpy(stream->outputffer+stream->current, ptr, my_size);
//3. 更新计数器字段
stream->current+=my_size;
writen = my_size;
}
//4. 开始计划刷新, 他们高效体现在哪里 --- TODO
//不发生刷新的本质, 不进行写入, 就是不进行IO, 不进行系统调用, 所以my_write函数调用会非常快, 数据会暂时保存在缓冲区中
// 可以在缓冲区中挤压多份数据, 统一进行刷新写入, 本质: 就是一次IO可以IO更多的数据, 提高IO效率
if(stream ->flags & BUFF_ALL)
{
if(stream->current ==NUM) my_fflush(stream);
}
else if(stream ->flags & BUFF_LINE)
{
if(stream->outputffer[stream->current-1] =='\n') my_fflush(stream);
}
else
{
//TODO
}
return writen;
}
int my_fflush(MY_FILE *fp)
{
assert(fp);
write(fp->fd, fp->outputffer, fp->current);
fp->current=0;
fsync(fp->fd); //强制刷新
return 0;
}
int my_fclose(MY_FILE *fp)
{
assert(fp);
//1. 冲刷缓冲区
if(fp->current > 0) my_fflush(fp);
//2. 关闭文件
close(fp->fd); //关闭文件描述符
//3. 释放堆空间
free(fp);
//4. 指针置为NULL --- 可以设置
fp=NULL;
return 0;
}
main.c
#include "mystdio.h"
#define MYFILE "log.txt"
int main()
{
MY_FILE *fp = my_fopen(MYFILE, "w");
if(fp == NULL) return 1;
const char*str="hello my fwrite";
int cnt=5;
//操作文件
while(cnt)
{
char buffer[1024];
snprintf(buffer, sizeof(buffer), "%s: %d\n", str, cnt--);
size_t size = my_fwrite(buffer,strlen(buffer), 1,fp);
sleep(1);
printf("当前成功写入: %lu个字节\n", size);
}
my_fclose(fp);
return 0;
}
5.3 缓冲区与OS的关系
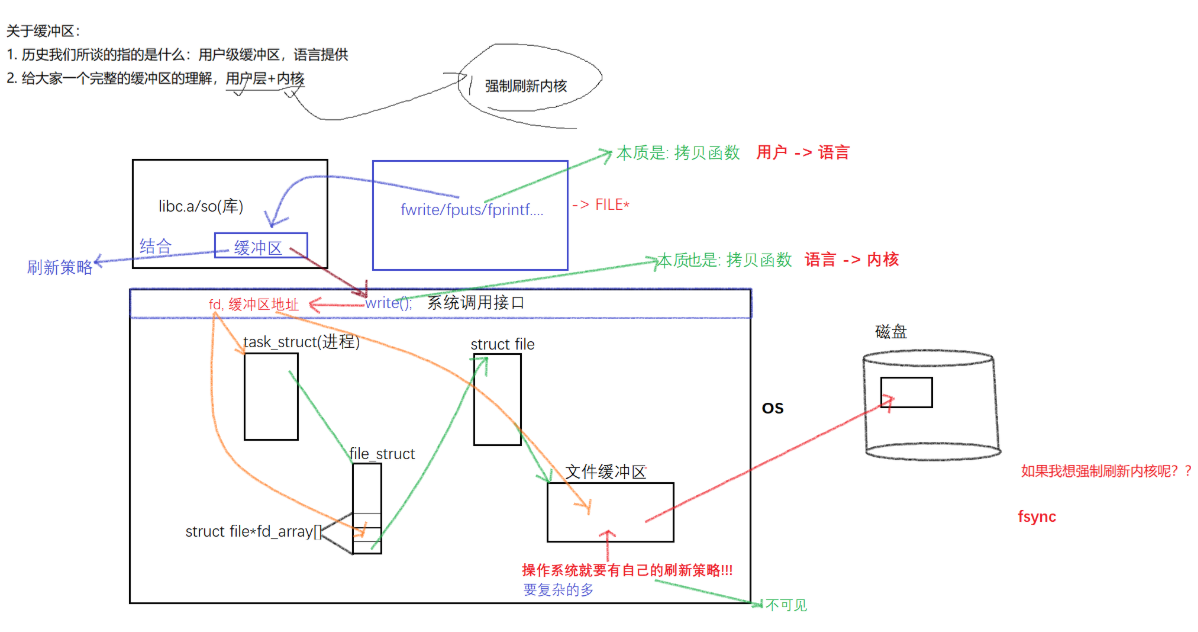
我们所写入到磁盘的字符串是按照行刷新进行写入的,但并不是直接写入到磁盘中,而是先写到操作系统内的文件所对应的缓冲区里,对于操作系统中的file结构体,除了一些接口之外还有一段内核缓冲区,而我们的数据则通过file结构体与文件描述符对应,再写到内核缓冲区里面,最后由操作系统刷新到磁盘中,而刷新的这个过程是由操作系统自主决定的,而不是我们刚才所讨论的一些行缓冲、全缓冲、无缓冲……,因为我们提到的这些缓冲是在应用层C语言基础之上FILE结构体的刷新策略,而对于操作系统自主刷新策略则比我们提到的策略复杂的多,因为操作系统需要考虑自己的存储情况而定,因此数据从操作系统写到外设的过程和用户毫无关系。
所以一段数据被写到硬件上(外设)需要进行这么长的周期:首先通过用户写入的数据进入到FILE对应的缓冲区,这是用户语言层面的,然后通过我们提到的刷新的策略刷新到由操作系统中struct file*的文件描述符引导写到操作系统中的内核缓冲区,最后通过操作系统自主决定的刷新策略写入到外设中。如果OS宕机了,那么数据就有可能出现丢失,因此如果我们想及时的将数据刷新到外设,就需要一些其他的接口强制让OS刷新到外设,即一个新的接口:int fsync(int fd),调用这个函数之后就强制把内核缓冲区的数据刷新到外设中
5.4 总结
因此以上我们所提到的缓冲区有两种:用户缓冲区和内核缓冲区,用户缓冲区就是语言级别的缓冲区,对于C语言来说,用户缓冲区就在FILE结构体中,其他的语言也类似;而内核缓冲区属于操作系统层面,他的刷新策略是按照OS的实际情况进行刷新的,与用户层面无关。
6. 磁盘文件
在前半部分学习中,我们学习的都是被打开的文件,如果没有被打开的文件呢?如果一个文件没有被打开,该如何被OS管理呢?(文章后半部分主要谈论磁盘文件)
- 没有被打开的文件只能在磁盘等外设中静静的存储着
磁盘上面有大量的文件,而其中的大部分都是处于未被打开的状态,这些文件也需要被静态管理起来,方便我们随时找到并打开,那磁盘是如何管理的呢?
6.1 磁盘的结构
磁盘是我们计算机中唯一的一个机械结构。要理解操作系统如何对磁盘上的未打开文件进行管理,首先我们需要对磁盘这个设备的物理结构、存储结构与逻辑结构进行理解,然后再在此基础上理解操作系统对磁盘的管理方法。
6.1.1 磁盘的物理结构
总体来说,硬盘结构包括:盘片、磁头、盘片主轴、控制电机、磁头控制器、数据转换器、接口、缓存等几个部分

盘片: 磁盘是按摞的,也就是说一个磁盘有很多个盘片。
盘面: 一个盘片有两个盘面。
磁头: 每一面都有一个磁头。也就是说假如磁盘有五片,那么就有十面,也就有十个磁头。磁头和盘面是没有接触的,是悬浮在盘面上的,一旦盘面高速旋转,磁头就会漂浮起来,因此磁盘必须防止抖动,否则磁头就会上下摆动,给盘面刮花,造成磁盘上的二进制数据丢失。
马达: 盘片加电之后,马达会使盘片逆时针告高速旋转,此时的磁头会来回的左右摆动。因此马达设备可以控制磁头摆动与盘片旋转。

可以发现,在磁盘内部也有自己的硬件电路,硬件电路有硬件逻辑,可以称之为磁盘本身的伺服系统,即可以通过硬件电路组成伺服系统,从而给磁盘发送二进制指令,让磁盘定位或者寻址某个特定的区域,从而读取磁盘上对应的数据。
扩展:
笔记本电脑装载的不是机械磁盘,而是SSD。磁盘是我们计算机中唯一的一个机械设备。相对于其他设备而言,由于磁盘是一个硬件结构+外设,所以硬盘访问相对较慢(只是相对的),因此操作系统就需要处理很多工作。虽然目前很少见到磁盘,但在企业端,磁盘依旧是主流,由于SSD成本太高,且有读写限制,容易被击穿,即便访问速度远超磁盘,但也不能将磁盘完全替代。
注: 磁盘密封性很强, 可以拆开, 但在普通外界环境下一旦拆开就会报废
6.1.2 磁盘的存储结构
理解磁盘存储结构尝试在硬件上, 理解数据的一次读和写
盘片
一个磁盘由多个盘片(如下图中的 0 号盘片)叠加而成。
盘片的表面涂有磁性物质,这些磁性物质用来记录二进制数据。因为正反两面都可涂上磁性物质,故一个盘片可能会有两个盘面。

磁道、扇区
每个盘片被划分为一个个磁道,每个磁道又划分为一个个扇区。如下图:

柱面
每个盘面对应一个磁头。所有的磁头都是连在同一个磁臂上的,因此所有磁头只能“共进退”。所有盘面中相对位置相同的磁道组成柱面。如下图
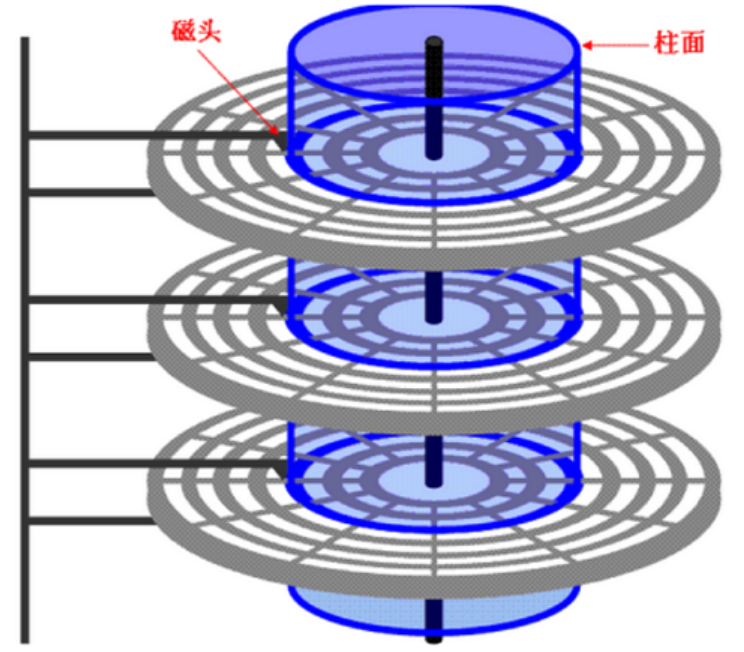
由上,**可用(柱面号,盘面号,扇区号)来定位任意一个“磁盘块”。**即:CHS定位法。
6.1.3 磁盘的逻辑结构
前提:
上面的内容, 主要说明的是如果OS能够得知任意一个CHS地址, 就能访问任意一个扇区。
那么在OS内部是不是直接使用的CHS地址呢? 不是
为什么在OS内部不使用CHS定位法来定位地址呢?
- OS是软件, 磁盘是硬件,硬件定位一个地址,CHS,但是如果OS直接用了这个地址,万一硬件变了呢? OS是不是也要跟着变化,OS要和硬件做好解耦工作
- 即便是扇区, 512字节,单位IO的基本数据量也是很小的,硬件: 512字节,OS实际进行IO, 基本单位是4KB(可以调整的) — 磁盘:块设备。所以,OS需要有一套新的地址,来进行块级别的访问
以下图的磁带来类比磁盘,把磁带盒拆开后,将磁带扯出来后其结构是线性的,也就是说,磁带里面的数据是按线性方式来读取的。

将磁盘的盘面按线性方式展开:
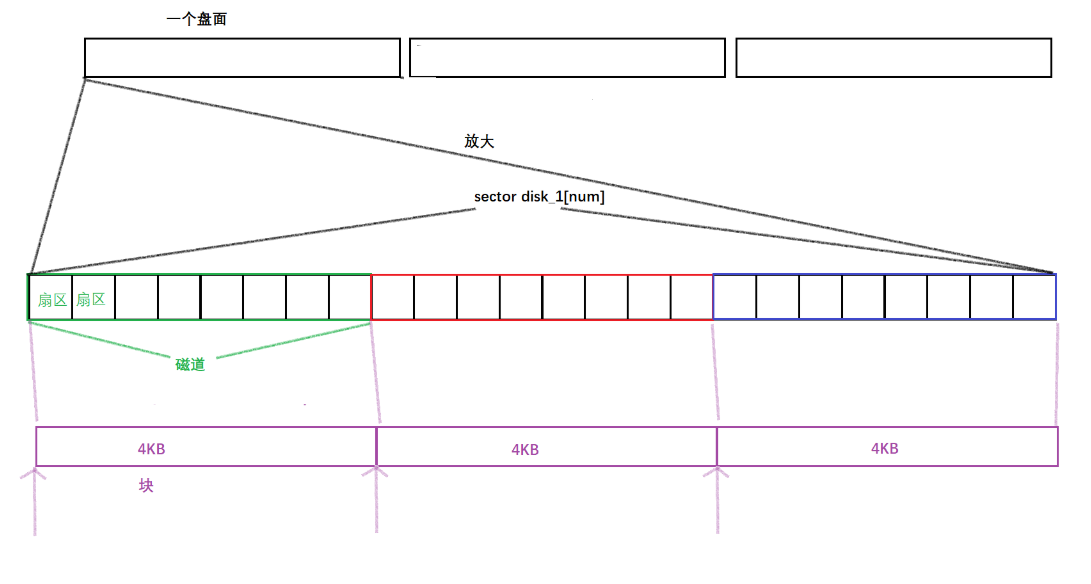
可以把一个磁道看成一个数组,此时定位一个扇区时只需要通过数组下标就可以完成定位
OS是以4KB为单位进行IO的,故一个OS级别的文件块要包括8个扇区
计算机常规的访问方式: 起始地址+偏移量的方式, 我们也可以把数据块看做一种类型,同理只需要知道数据块的起始地址(第一个扇区的下标地址) + 4KB (块的类型) 就可以访问
所以块的地址,本质就是数组的一个下标,以后我们表示一个块,可以采用线性下标的方式,定位一个块
那此时,如果想要找到指定的扇区,只要知道这个扇区的下标就可以定位磁盘指定的扇区。在操作系统内部,我们称这种地址为LBA地址(Logical Block Address),即逻辑块地址。
可是我们的磁盘只认CHS地址,所以我们可以通过某种方式来实现 CHS地址 和 LBA地址的相互转化
如:
逻辑扇区号LBA的公式:
LBA(逻辑扇区号)=磁头数 × 每磁道扇区数 × 当前所在柱面号 + 每磁道扇区数 × 当前所在磁头号 + 当前所在扇区号 – 1
例如:CHS=0/0/1,则根据公式LBA=255 × 63 × 0 + 63 × 0 + 1 – 1= 0
6.2 理解文件系统
6.2.1 磁盘的分区与分组
比如对于一个500GB的磁盘,文件系统IO单位为4KB时显然不够大,我们将其分为每区,每100GB为一个分区时也不方便管理, 所以我们需要对这100GB进行分组, 每5GB一组来管理
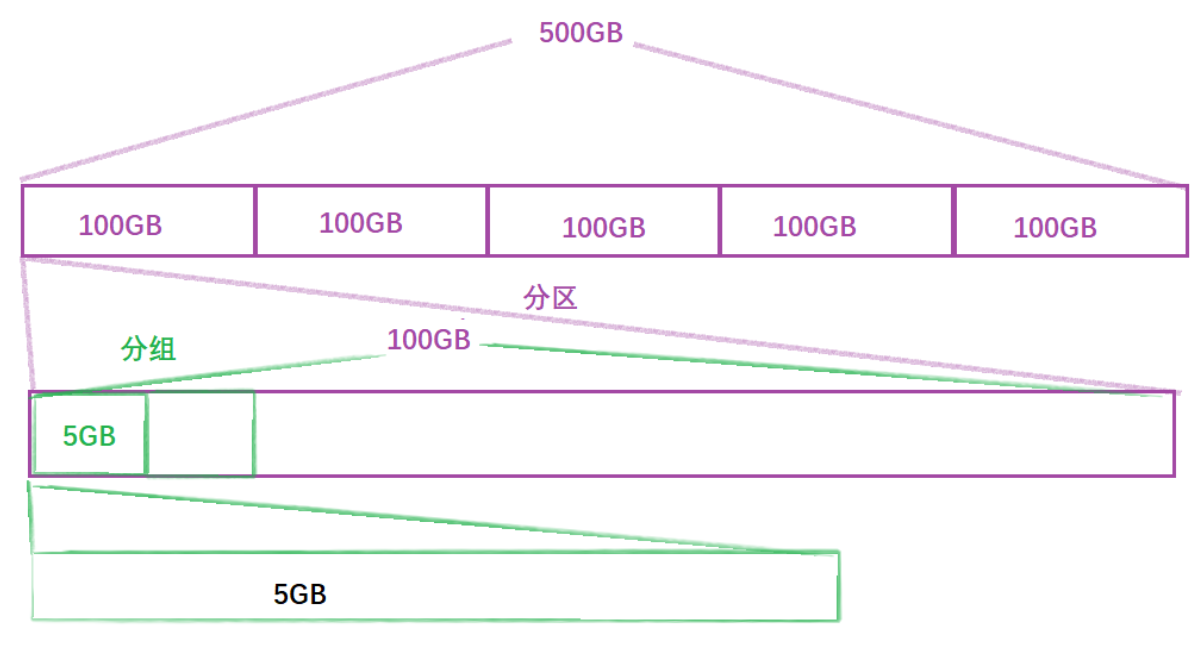
分好组后,如果能将一组管理好,那么其他组只需复制这组的管理方法用同样的方式也能管理好这一个分区;再将一个分区的管理模式复制到其他分区就可以管理好整个磁盘了 。采用分治的思想,只要管理好这5GB的磁盘空间,那么整个磁盘空间就能管理好。以上述方式,分组之后产生的需要管理的部分就变成了如下的结构:
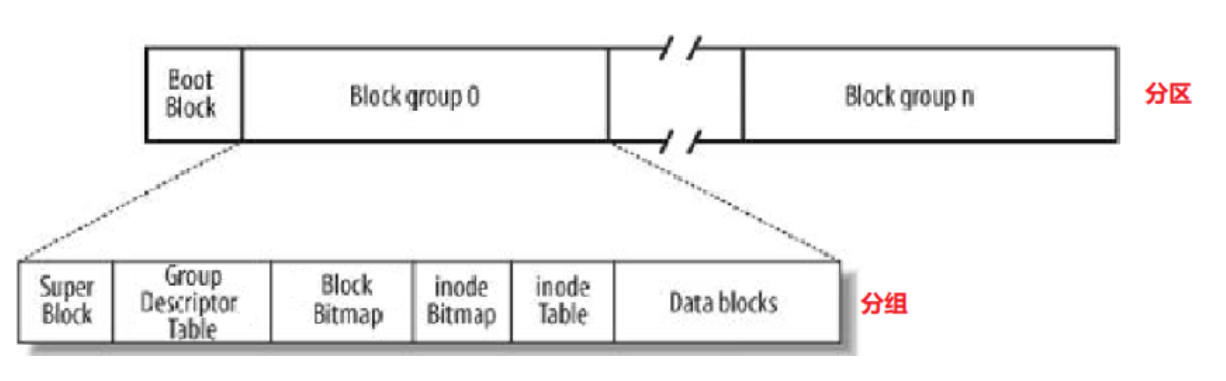
-
Block Group:ext2 文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。政府管理各区的例子
-
每个分区的第一部分数据是 Boot Block 启动块,后面才是各个分组,它与计算机开机相关,我们不用关心。
6.2.2 分组的管理方法
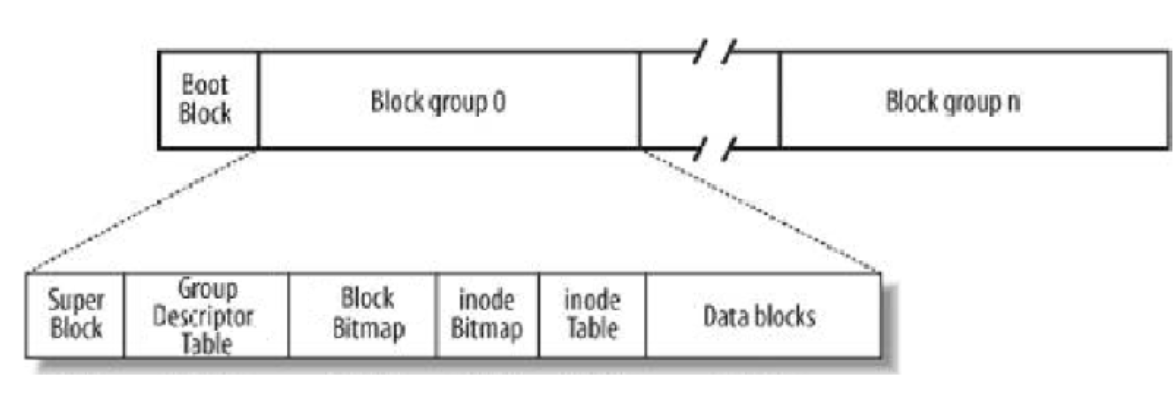
-
超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。Super Block没有像 Boot Block一样放在分区的位置而是每个组都有一个是为了备份, 一旦其他Super Block出现异常,就会把其他正常的Super Block拷贝过来。
-
GDT,Group Descriptor Table:块组描述符,描述块组属性信息
-
inode
文件 = 内容+属性,Linux操作系统中文件的内容和属性是分离的,inode来存储文件属性。inode是固定大小的,一个文件一个inode。在分组的内部,可能会存在多个inode, 需要将inode区分开来,每一个inode都有自己的inode编号,所以inode编号也属于对应文件的属性id -
inode Table
在一个分区中,内部会存在的大量的文件即会存在大量的inode节点,一个组中需要有一个区域来专门存放该组内所有文件的inode节点, 这个区域就是inode Table。 -
Data blocks
数据块,一个文件的内容是变化的,我们是用数据块来进行文件内容保存的,所以一个有效文件,要保存内容,就需要[1,n]个数据块,那么如果有多个文件,就需要更多的数据块 — Data blocks -
inode Bitmap
inode对应的位图结构。每个bit表示一个inode是否空闲可用 -
Block Bitmap
每一个bit表示data block是否空闲可用
6.2.3 深入理解inode
(1) inode VS 文件名
Linux系统只认inode编号,文件的inode属性中,并不存在文件名。文件名是给用户用的
(2) 重新认识目录
目录是文件吗? 是的;目录有inode编号吗? 有的。通过 ls - il就可以查看文件的 inode
目录有内容吗? 有,内容是什么?
任何一个文件一定在一个目录内部,所以目录要有内容就需要数据块,目录的数据块里面保存的是该目录下的文件名和文件inode编号对应的映射关系,而且在目录内,文件名和inode互为key值
(3)访问文件的基本流程
当我们访问一个文件的时候,我们是在特定的目录下访问的。比如要 cat log.txt(打印文件内容)的基本流程:
- 先在当前目录下,找的哦log.txt的inode编号
- 一个目录也是一个文件,也一定隶属与一个分区,结合inode, 在该分区中找到分组,在该分组中的 inode Table 中,找到文件的inode
- 通过inode和对应 data block 的映射关系,找到该文件的数据块,加载到OS并完成显示到显示器
6.2.4 如何理解文件的增删查改
删除文件
- 先根据文件名构建data block和inode的映射关系,找到这个文件的 inode编号
- 根据inode编号和inode属性中的映射关系,将block bitmap对应的比特位置为0即可
- 根据inode编号将 inode bitmap对应的比特位设置为0
所以删除文件只需要修改位图即可
创建文件
在 inode bitmap 里面查找为0的比特位编号,置为1,然后将文件的所有属性填写到 inode table 对应编号下标的空间中;再在 block bitmap 中查找一个/多个为0的比特位编号,将其置为1,然后将文件的所有内容填写到 data blocks 对应编号下标的空间中;最后再修改 super block、同时,需要将新文件文件名与 inode 的映射关系写入到目录的 data block 中。
6.2.5 补充细节
- 如果文件被误删了,怎么办?
理论上来讲,1. 知道被删文件的inode编号,先拿着inode编号在特定被删文件的分组中将 inode bitmap 对应的bit位由0置为1,此时该文件就不会被覆盖了;2. 再根据inode 读取inode表,从inode表中提取当前文件所占用的数据块,将数据块所对应的 bitmap再置1。此时该文件的属性和对应内容就被恢复出来了。
不过这一切的前提是原文件的 inode 没有被新文件使用 – 如果新文件使用了原文件的 inode,那么对应的 inode table 以及 data block 里面的数据都会被覆盖,所以文件误删之后最好的做法就是什么都别做,避免新建文件将原文件的 inode 占用。
实际恢复文件时,最好是使用相关工具来恢复。
-
inode编号是在一个分区内唯一有效,不可以跨分区(一般一个分区是一个文件系统); 所以可以用inode编号来确定分组
-
我们学习到的分区和分组,填写系统属性,谁做的呢?什么时候做的呢?
OS做的,在分区完成之后,后面要让分区能够正常使用,我们需要对分区做格式化,格式化的过程,其实是OS向分区写入文件系统的管理属性信息
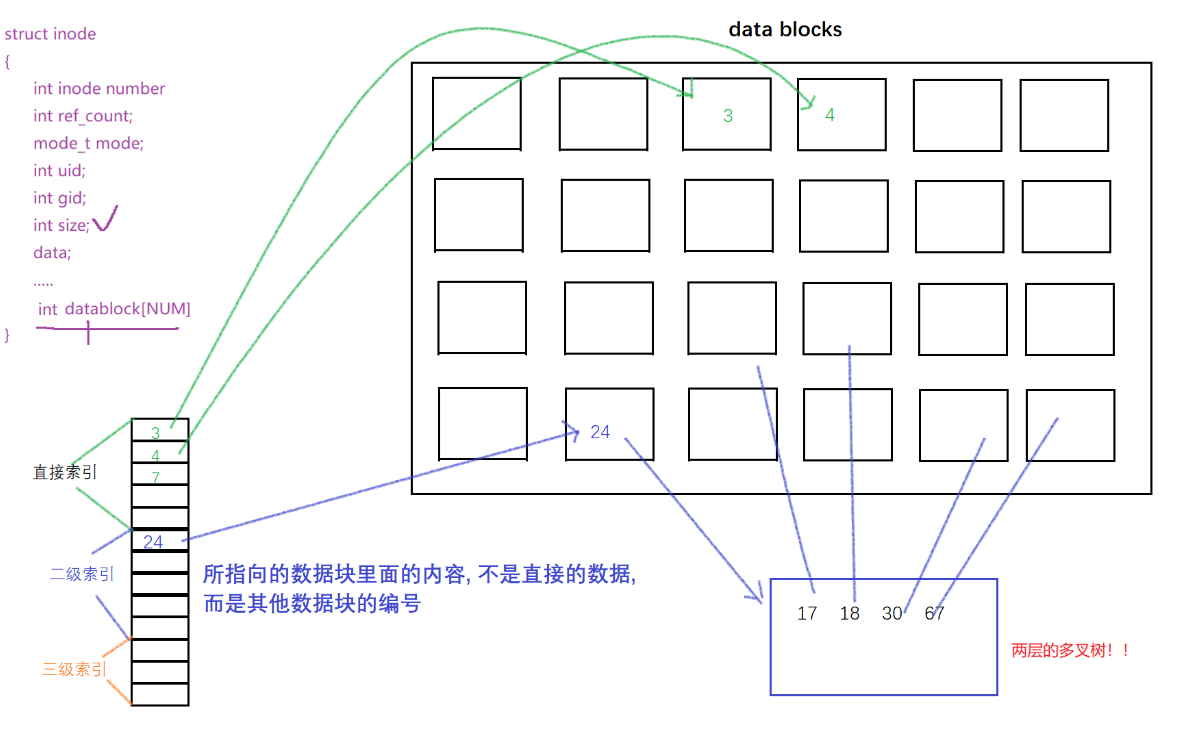
- inode如果只是单单的用数组建立和data block的映射关系,假设一个data block存4kb数据,有15个数组,是不是意味着一个文件内容最多放入 15*4=60kb的数据呢? 不是的
- 有没有可能,一个分组,数据块没用完,inode没了,或者inode没用完,data block用完了?有可能,但是这种情况基本不会出现
7. 软硬链接
7.1 软链接(符号链接)
ls -n 文件名 所创建软链接名
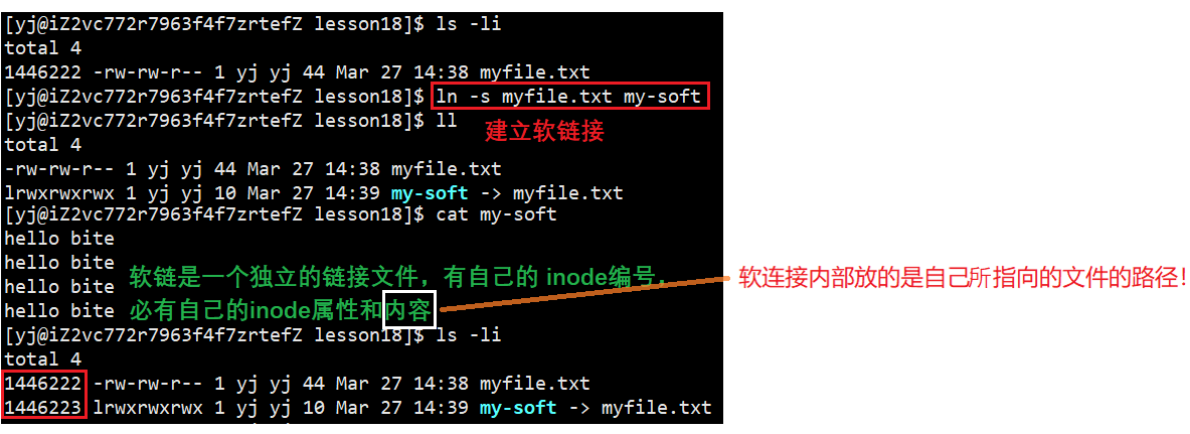
用途
在一个很深的目录下的可执行程序我们想要把它运行起来的常规方法:

其实我们可以对此程序创建软链接,使其运行起来
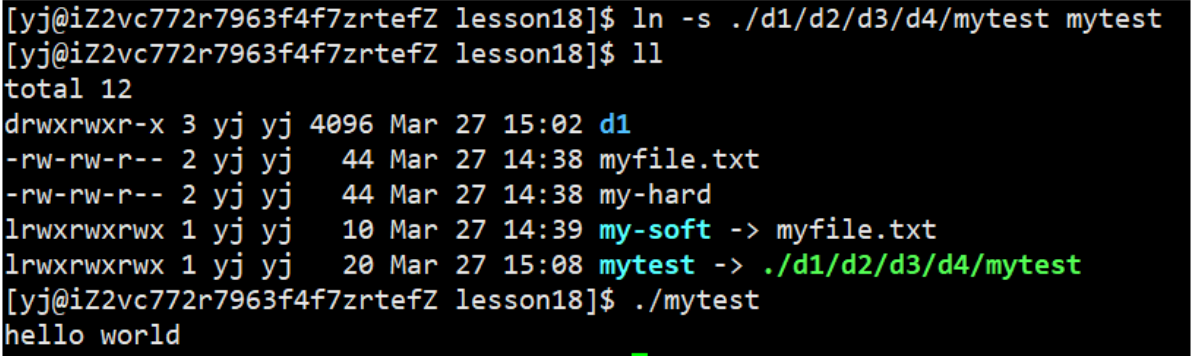
可以看出,软链接就相当于Windows的快捷方式
7.2 硬链接
ln 文件名 所创建硬链接名
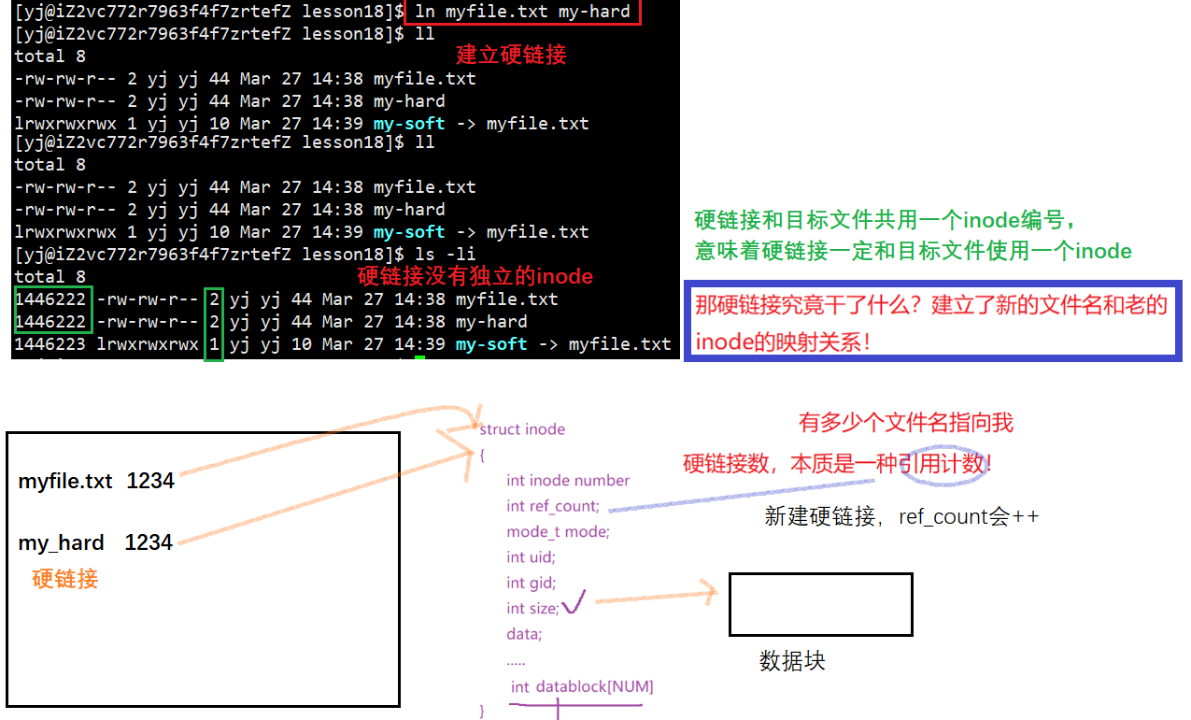
如果将myfile.txt删掉,通过硬链接仍然可以访问到该文件的内容,因为只是去掉了一个映射关系,计数器减1,还存在一个映射关系可以访问。因此可以看出,只有当硬链接计数器为0时,才算是将一个文件真正的删掉
想要删除一个硬链接: 可以直接以rm方式删除,也可以 unlink 硬链接名方式删除
7.3 理解 .
在当前路径下,我们创建一个普通文件和一个空目录

观察发现,两者硬链接数目不同,普通文件是1,目录是2,其实就间接说明了仍有一个文件与dir的Inode相同,构成硬链接。进入dir目录观察:
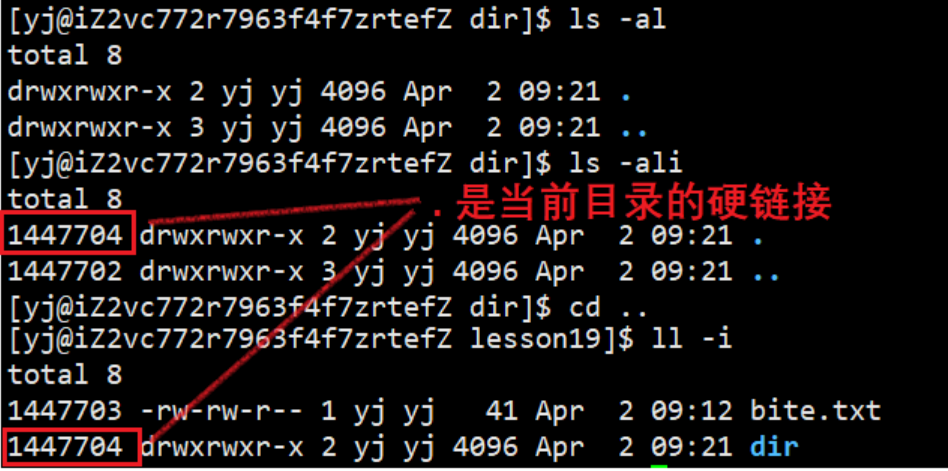
我们发现隐含的.实际上就是dir的硬链接,且.文件是自动生成的,所以目录初始的硬链接为2的原因就是因为.的硬链接。
所以在目录中,. 是当前目录的硬链接
7.4 理解 …
我们可以验证在当前目录下,以绝对路径方式和 . 方式查看 inode编号,两者完全相同;
以同样的方式: 绝对路径和相对路径 … 方式查看上级目录的 inode编号,发现两者也是完全相同的;上级目录lesson19下有3个硬链接,分别是:lesson19本身, . ,. . 。


这也更加验证了linux下文件是一个多叉树结构
所以在目录中,.. 是上级目录的硬链接
那么能否给目录主动建立硬链接呢?

我们发现,这是不被允许的,那Linux为什么不允许普通用户给目录硬链接呢?
容易造成环路路径问题
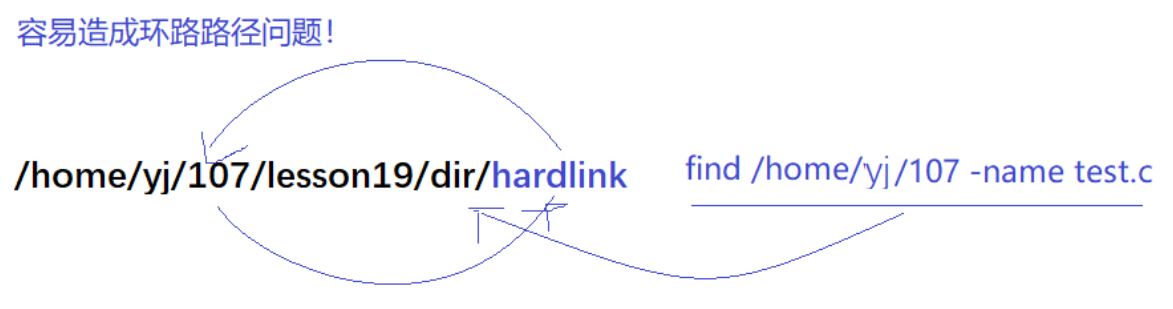
.和..的硬链接是OS自己建立的。
7.5 补充
acm
下面解释一下文件的三个时间:
Access: 最后访问时间
Modify: 文件内容最后修改时间
Change: 属性最后修改时间
8. 动态库和静态库
8.1 见一见库
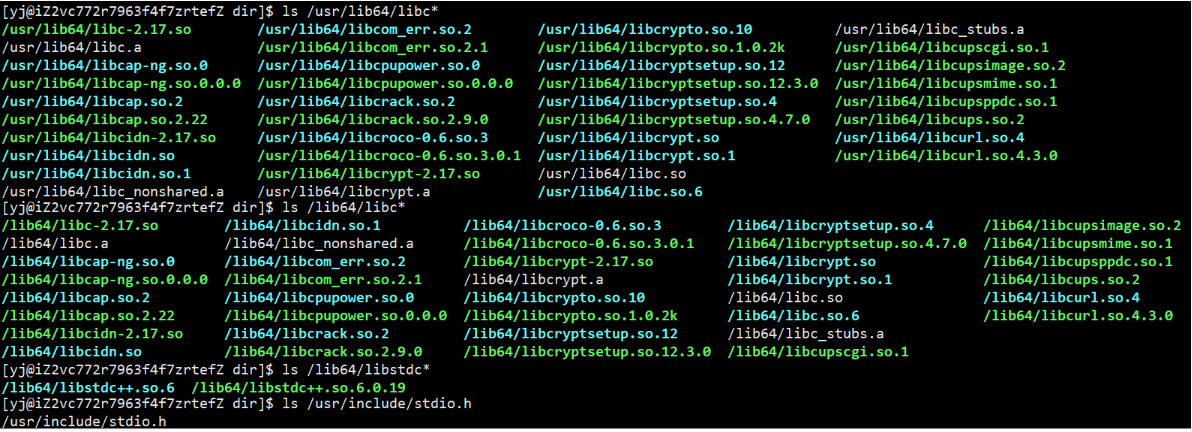
上面就是linux系统下的库
结论:
- 系统已经预装了C/C++的头文件和库文件,头文件提供方法说明,库提供方法的实现,头和库是有对应关系的,要组合在一起使用的
- 头文件是在预处理阶段就引入的,链接本质其实就是链接库
理解现象:
- 所以,我们在VS2022下安装开发环境 — 安装编译器软件,其实是安装要开发的语言配套的库和文件。
- 我们在使用编译器时,都会有语法的自动提醒功能,这需要先包含头文件。自动提醒功能是依赖头文件的。
- 我们在写代码的时候,我们的环境怎么知道我们的代码中有哪些地方有语法报错,那些地方定义变量有问题?不要小看编译器,有命令行的模式,还有其他自动化的模式帮助我们不断进行语法检查
8.2 为什么要有库
简单来说就是提高开发效率
8.3 设计一个库
8.3.1 预备知识
静态库(.a):程序在编译链接的时候把库的代码链接到可执行文件中。程序运行的时候将不再需要静态库
动态库(.so):程序在运行的时候才去链接动态库的代码,多个程序共享使用库的代码。
库命名: 库的真实名称是去掉前缀 lib, 去掉首次遇到的点之后(或版本号)
比如这两个库: libstdc++.so.6 libc-2.17.so
真实名称分别是: stdc++ c
一般云服务器,默认只会存在动态库,不存在静态库,静态库需要单独安装
动态库和静态库同时存在时,系统默认采用动态链接
编译器,在链接的时候,如果既提供了动态库又提供了静态库,优先使用动态库;只有静态库时,只能使用静态库
8.3.2 设计一个静态库
比如需要实现一个简单的加减运算:
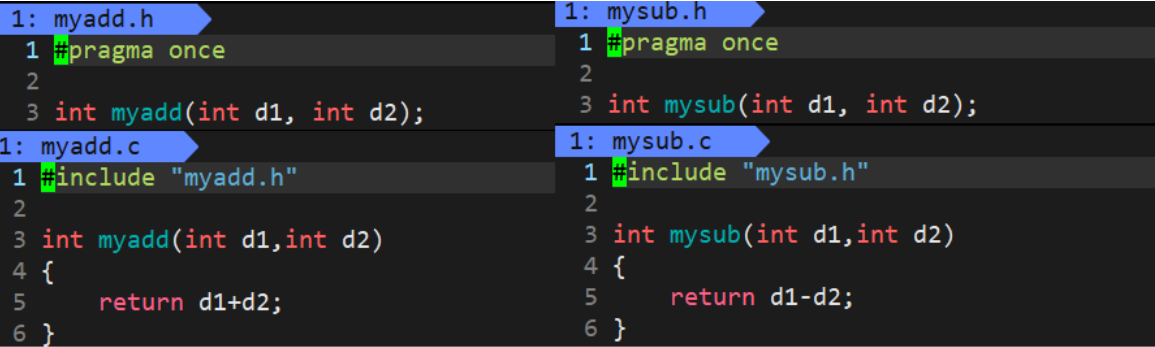
otherPerson自己实现的main.c
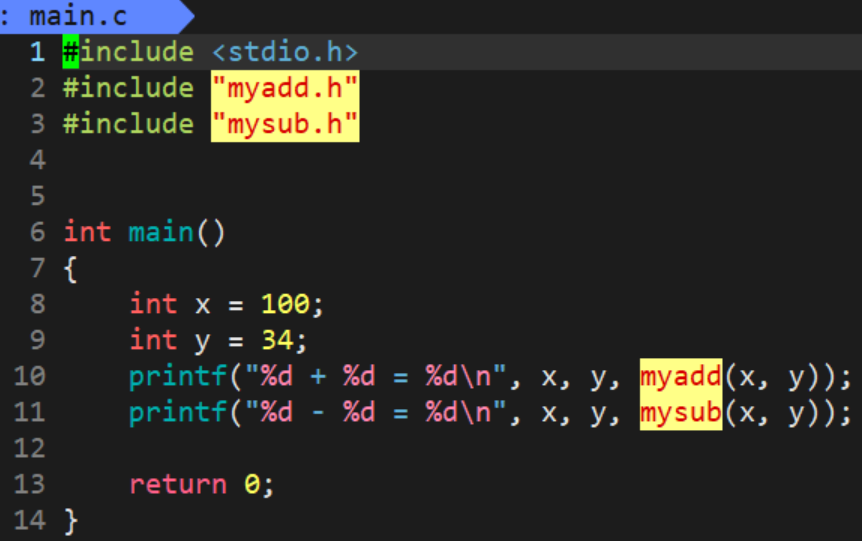
现在有一个otherPerson目录代表其他用户,他需要这个加减法运算的实现,但是我们并不想把源文件直接给他,而是把头文件和 .c文件编译生成的.o文件给他,他再写一个main.c文件并将.c文件编译生成.o文件,将这些 . o文件都链接起来就可以实现运算
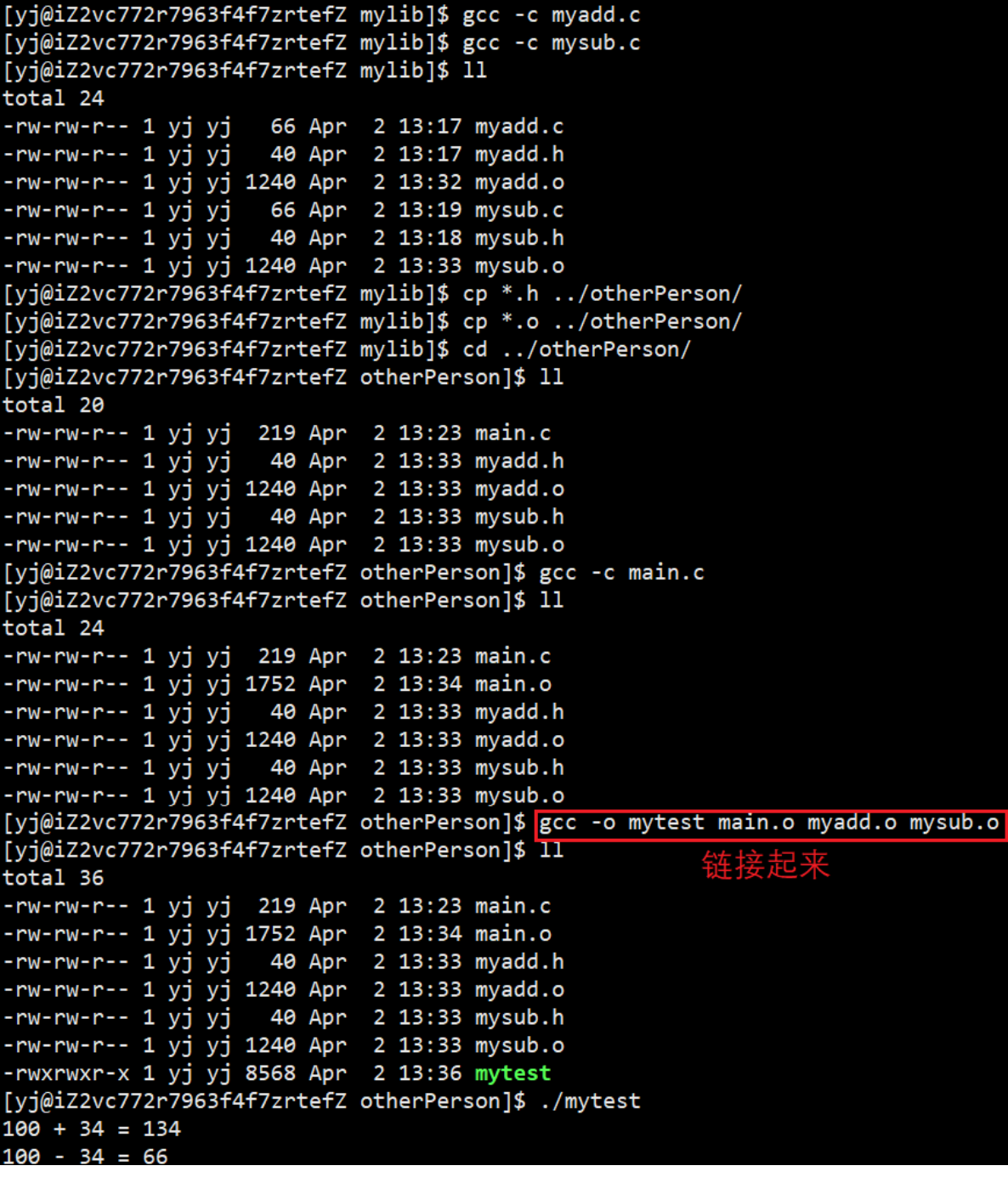
但是这样直接把.o文件给 otherPerson的方法太麻烦,如果 .o文件特别多时;
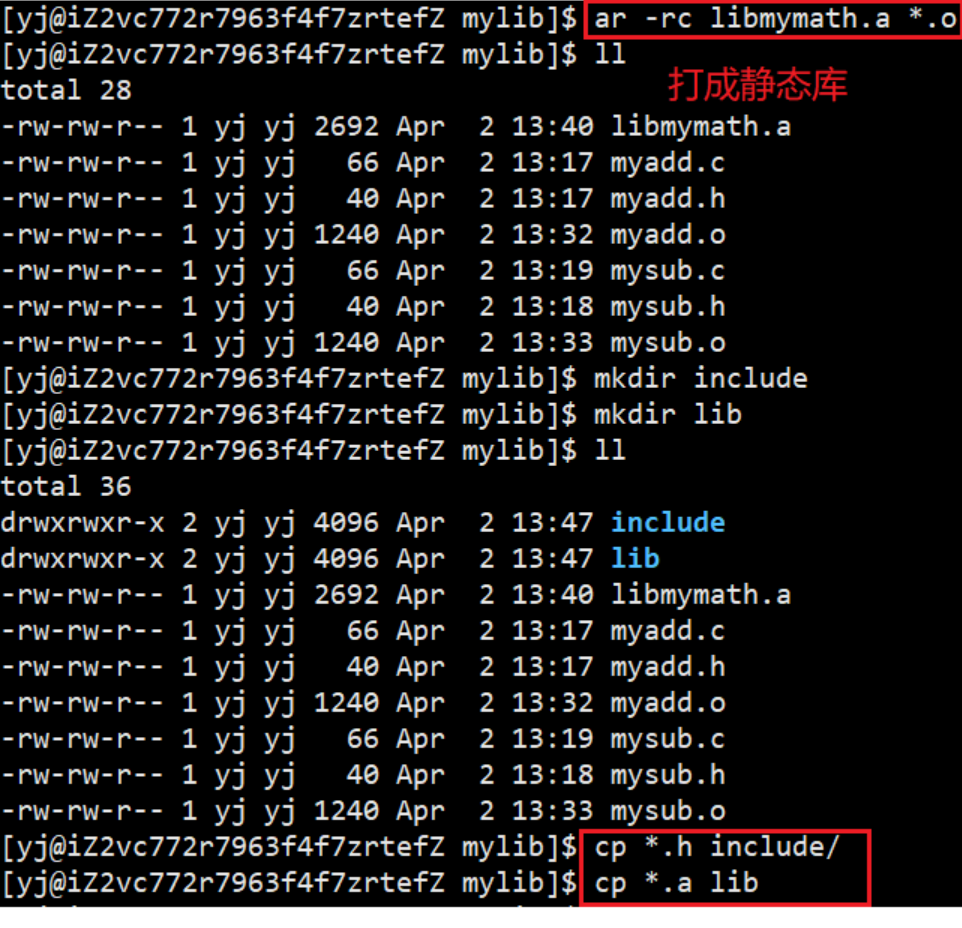
我们采用一种新的方法,现将所有的 .o 文件通过ar -rc libmymath.a *.o命令打成静态库
创建两个新的目录,将.o文件都放在lib目录中, .h文件都放在include目录中,并将这两个目录都打包成压缩包给 otherPerson,otherPerson通过解压就可以得到这两个目录下的文件
链接 main.c文件, .o文件.h文件并且指定刚才的静态库名后就可以生成可执行程序mytest, 运行mytest即可
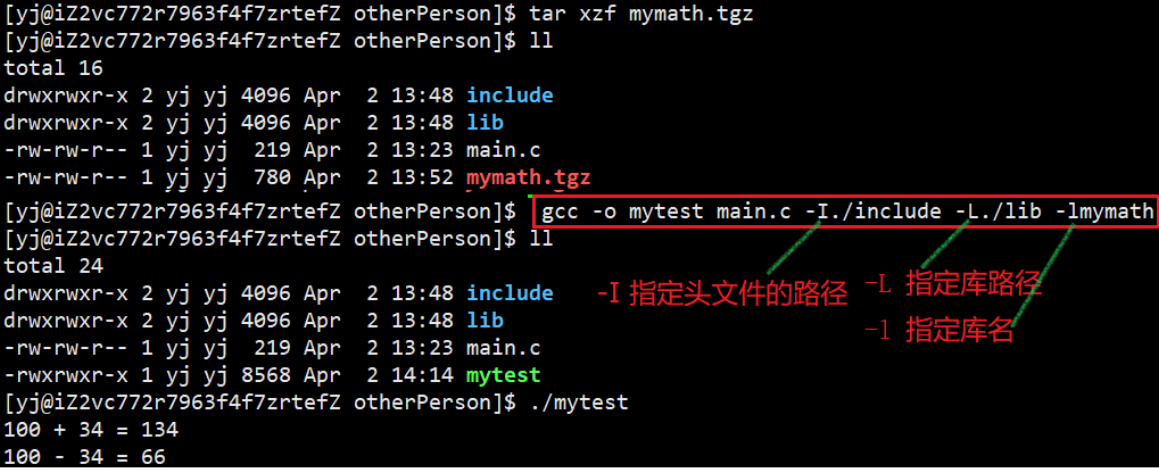
第三方库的使用
- 需要指定头文件和库文件
- 如果没有默认安装到系统gcc, g++默认的搜索路径下,用户必须指明对应的选项,告知编译器:
a. 头文件在哪里
b. 库文件在哪里
c. 库文件具体是谁 - 将我们下载下来的库文件和头文件,拷贝到系统默认路径下 — 其实就是在linux下安装库
那么卸载呢? 对任何软件而言,安装和卸载的本质就是拷贝到系统特定的路径下 - 如果我们安装的库是第三方的(语言,操作系统接口是第一,二方)库,我们要正常使用,即便是已经全部安装到了系统中,gcc, g++必须用
-l指定具体库的名称
理解现象:
无论你是从网络中未来直接下好的库,或者是源代码(编译方法) — make install安装的命令 — 就是cp ,安装到系统中,我们安装大部分指令,库等等都是需要sudo的或者超级用户操作
8.3.3 动态库的配置
还是上面的场景, 这时我们想要建立动态库来,来让 otherPerson执行代码
在建立动态库之前,我们先需要: gcc -fPIC -c myadd.c和 gcc -fPIC -c mysub.c 形成 .o文件(fPIC:产生位置无关码)
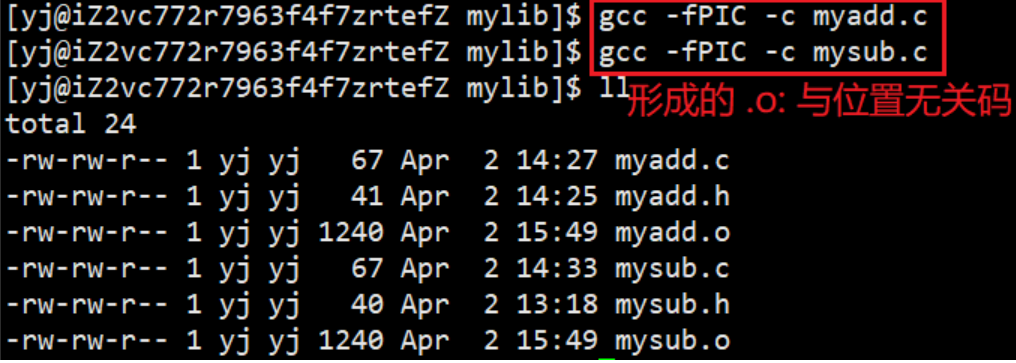
然后通过gcc -shared -o libmymath.so *.o 打成动态库
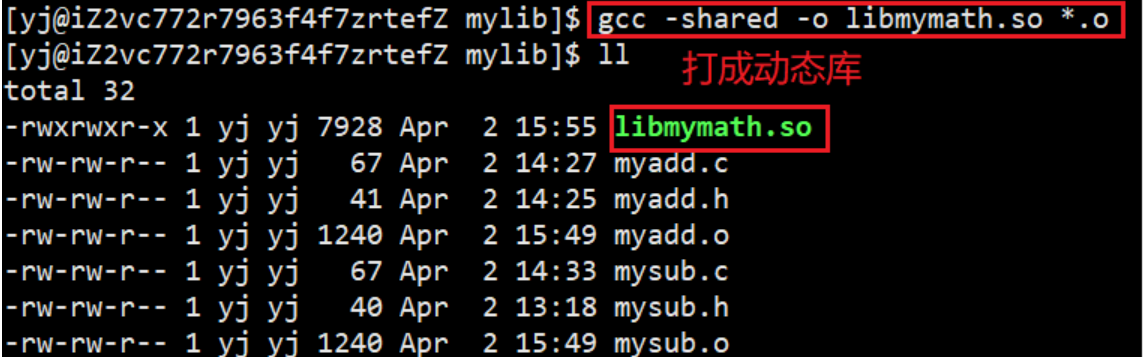
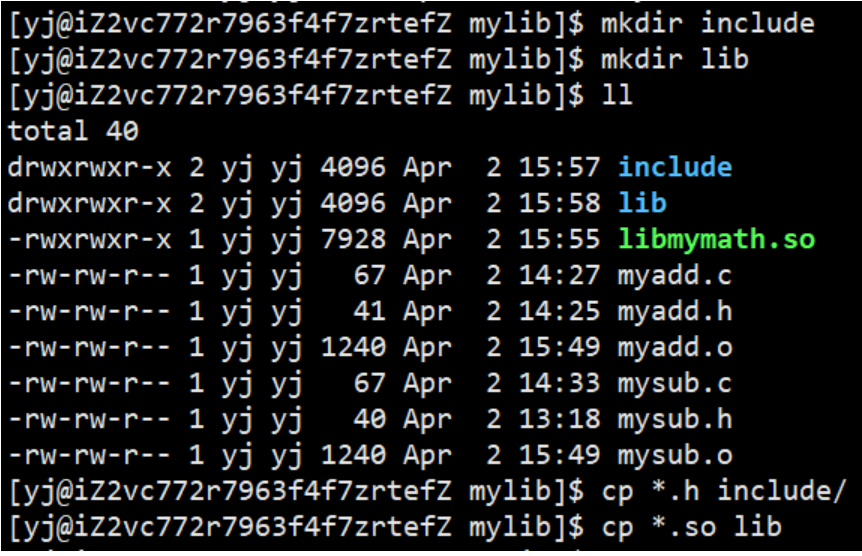
和上面静态库一样的操作,创建好两个目录,将.h文件和库文件分别放入目录中,然后打包成压缩包,拷贝给otherPerson目录
otherPerson目录下去解压后,像静态库一样链接生成可执行程序后去执行这个程序,发现无法执行
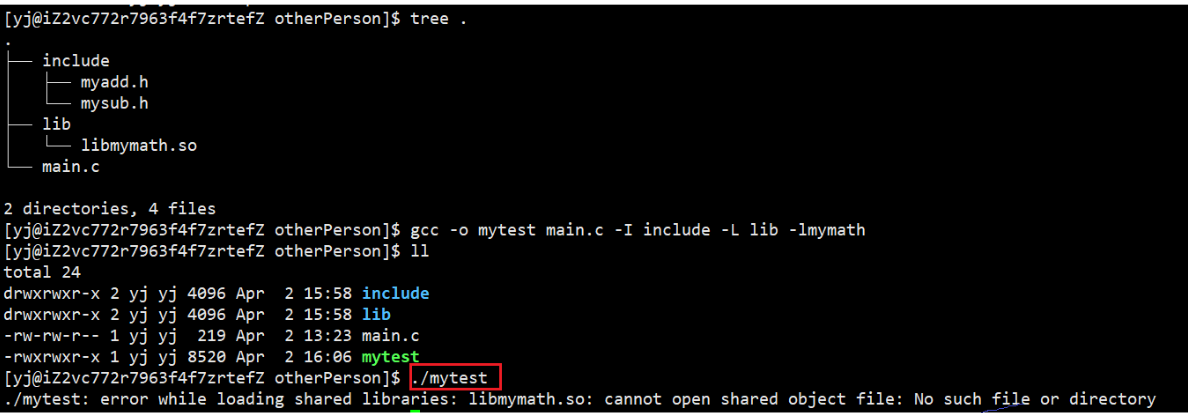
我们很疑惑,不是已经告诉系统,我的库在哪里,叫什么了吗?为什么还是找不到呢?
其实并不是告诉了系统,而是告诉了编译器
运行的时候,因为你的 .so 并没有在系统的默认路径下,所以OS依旧找不到
那为什么静态库就能找到呢?
静态库的链接原则: 将用户使用的二进制代码直接拷贝到目标可执行程序中, 但是动态库不会
我们可以采用以下3种方案,让OS去查找动态库:
环境变量方案
LD_LIBRARY_PATH
将动态库添加到环境变量中,方便OS和Shell找到
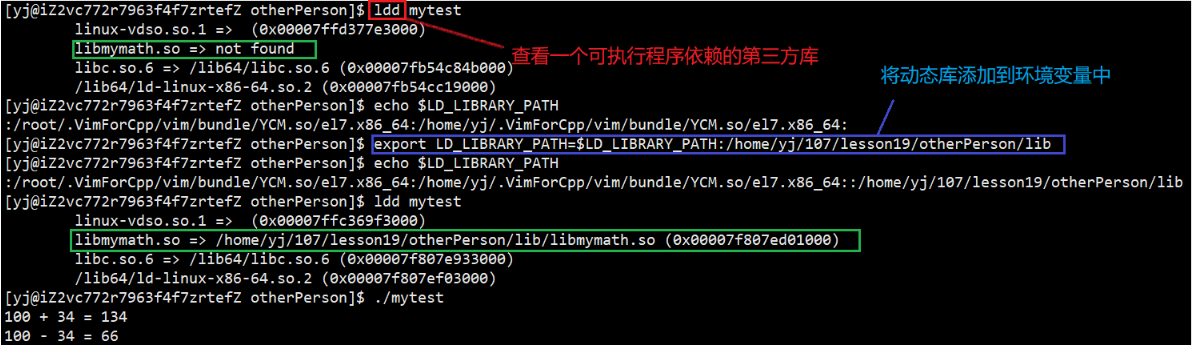
但是由于环境变量具有临时性,下次去登录,我们自定义的环境变量就没有了
软链接方案
把软链接建立在系统的默认搜索路径下

配置文件方案
8.4 动静态库的加载理解
8.4.1 加载静态库
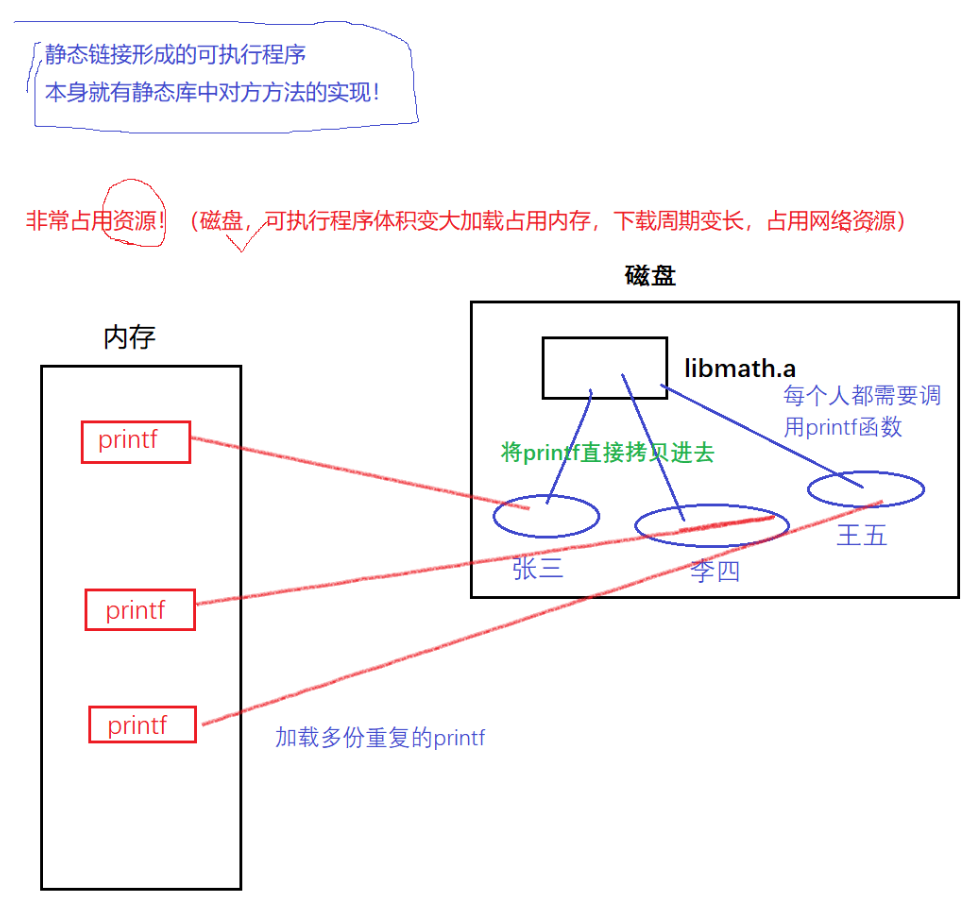
对于静态库来讲,静态库不需要加载,而程序需要加载。当静态库链接的时候,实际上是将代码(printf)拷贝进程序中,所以后面程序运行的时候就不再依赖于静态库。
而一旦有很多程序,静态库就会拷贝大量重复的代码分给不同的程序。通过进程地址空间的知识我们知道当静态库拷贝代码给程序时,实际上是把代码拷贝进了代码区。因此在程序运行形成进程地址空间时,静态库中的代码只能被映射到进程地址空间相应的代码区中,未来的这段代码,必须通过相对确定的地址位置进行访问。
8.4.2 加载动态库
具体步骤:
-
对于动态链接来说,可执行程序中存放的是动态库中某具体 .o 文件的地址,同时,由于组成动态库的可重定向文件是通过位置无关码 fPIC 生成的,所以这个地址并不是 .o 文件的真正地址,而是该 .o 文件在动态库中的偏移量;(与C++中的虚函数表一样)
-
然后就是程序运行的过程:操作系统会将磁盘中的可执行程序加载到物理内存中,然后创建 mm_struct,建立页表映射,然后开始执行代码,当执行到库函数时,操作系统发现该函数链接的是一个动态库的地址,且该地址是一个外部地址,操作系统就会暂停程序的运行,开始加载动态库;
-
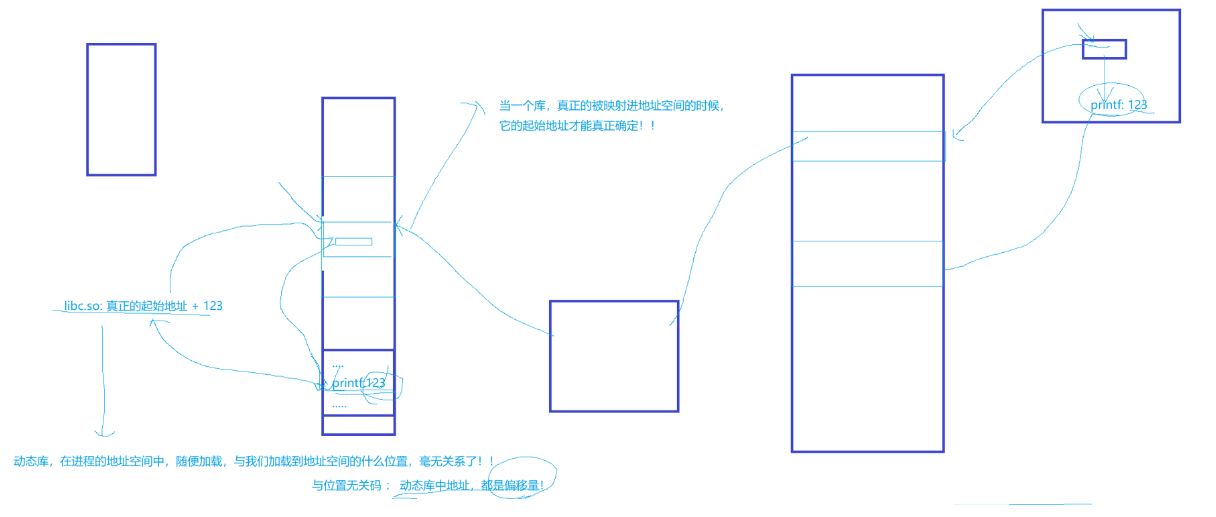
加载动态库:操作系统会将磁盘中动态库加载到物理内存中,然后通过页表将其映射到该进程的地址空间的共享区中,然后立即确定该动态库在地址空间中的地址,即动态库的起始地址,然后继续执行代码;
-
此时操作系统就可以根据库函数中存放的地址,即 .o 文件在动态库中的偏移量,再加上动态库的起始地址得到 .o 文件的地址,然后跳转到共享区中执行函数,执行完毕后跳转回来继续执行代码段后面的代码。这就是完整的动态库的加载过程。
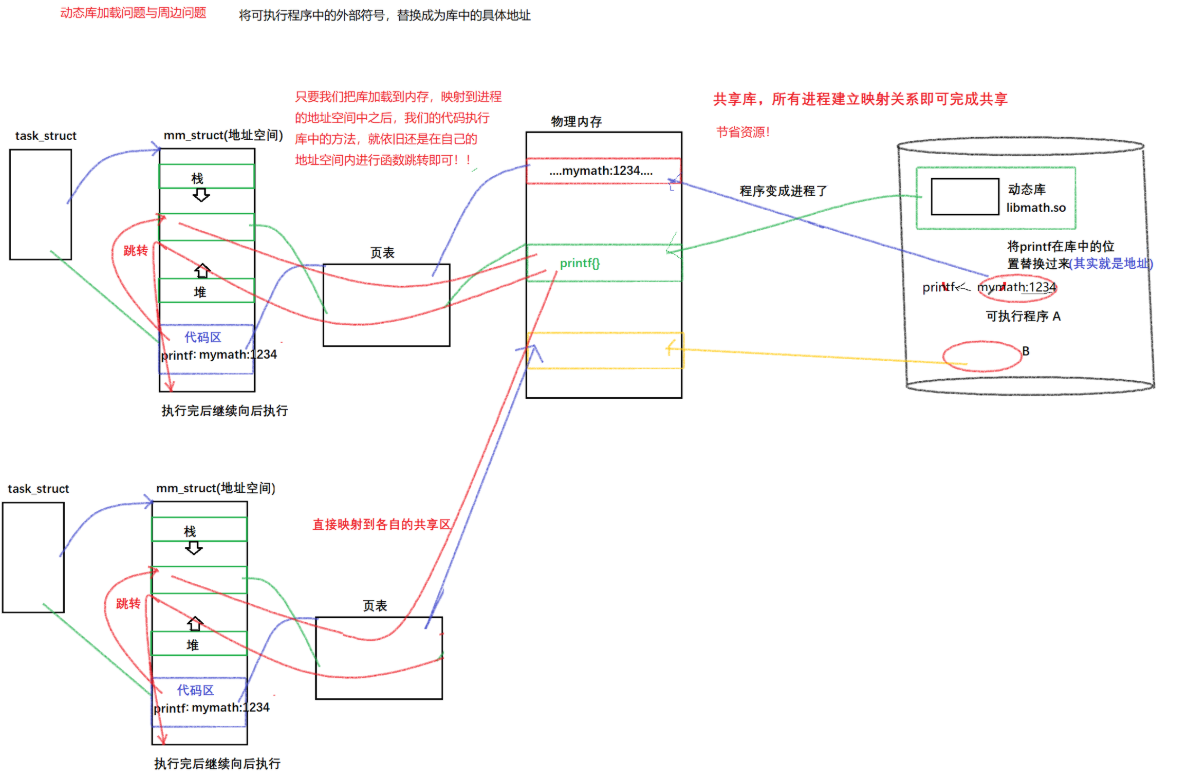
因此可以看出,动态库并不像静态库一样,不需要拷贝大量的相同代码,所有进程建立映射关系即可达到多个程序共享一份动态库中的代码。
8.4.3 库中地址的理解
比如这样的场景,你站在操场50米处,你的朋友想要来找你,你可以这样告诉他: 1. 我在操场50米处 2. 我在操场数的左边,大约距离20米处;1是一种绝对编址 ;2是一种相对编址。如果有一天学校把操场的前后加宽了,那么对于1地址来说必然改变,对于2地址来说依然不变(只要树的位置不变)
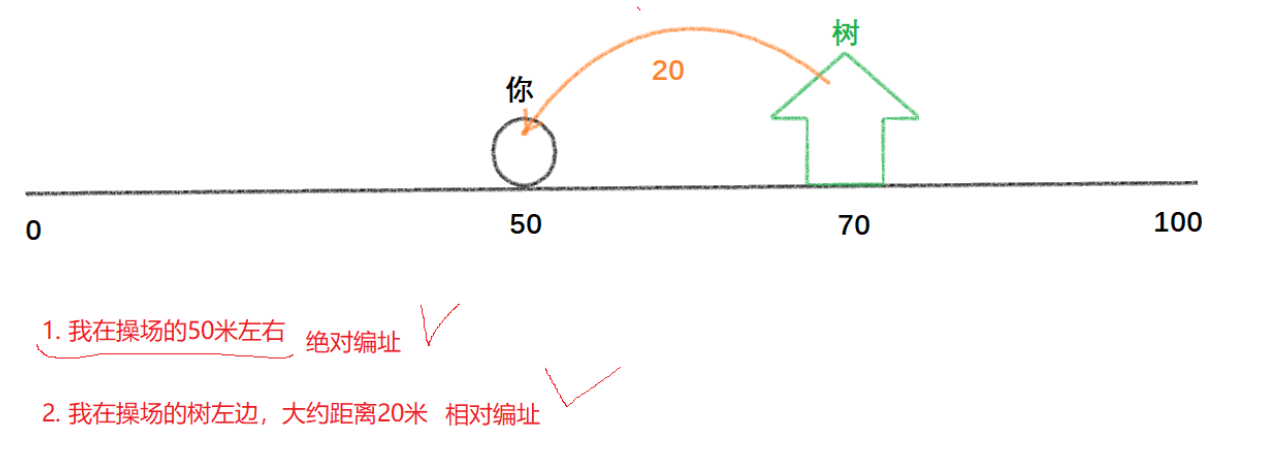
以上面的例子来类比动静态库
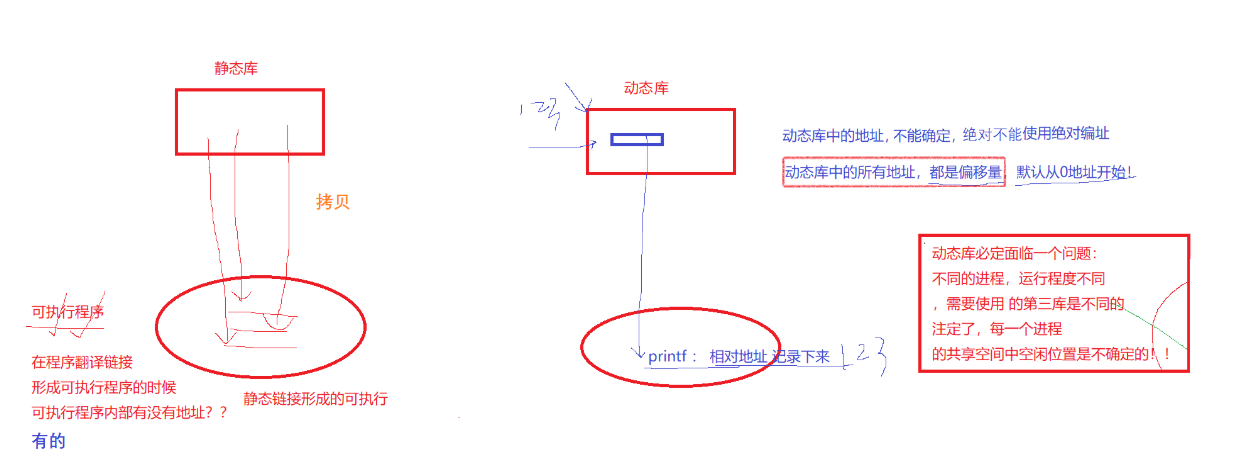
fPIC:产生位生位置无关码,本质是偏移量