往期类似文章:
实时数仓之 Kappa 架构与 Lambda 架构_奔跑者-辉的博客-CSDN博客
目录

补充几句话:这篇分享,内容分成了一个个小块知识呈现的,大家可结合文章概览看看对哪部分/哪几部分更为感兴趣,或者哪部分知识点掌握程度有待加深。然后直接找到对应的小模块浏览学习。期待你在留言区里讨论交流。
一、深入实时数仓架构
实时数仓的查询需求
在正式讨论实时数仓前,我们先看下行业对实时数仓的主要需求,这有助于我们理解实时数仓各种方案设计的初衷,了解它是基于哪些需求应运而生的。
这也将帮助我们从更多维度上思考需求、条件、落地难点等等一些关键要素之间如何评估和权衡,最终实现是基于现有条件下的功能如何将其价值最大化。
传统意义上我们通常将数据处理分为离线的和实时的。对于实时处理场景,我们一般又可以分为两类:
一类诸如监控报警类、大屏展示类场景要求秒级甚至毫秒级;
另一类诸如大部分实时报表的需求通常没有非常高的时效性要求,一般分钟级别,比如10分钟甚至30分钟以内都可接受。

基于以上查询需求,业界常见的实时数仓方案有这几种。
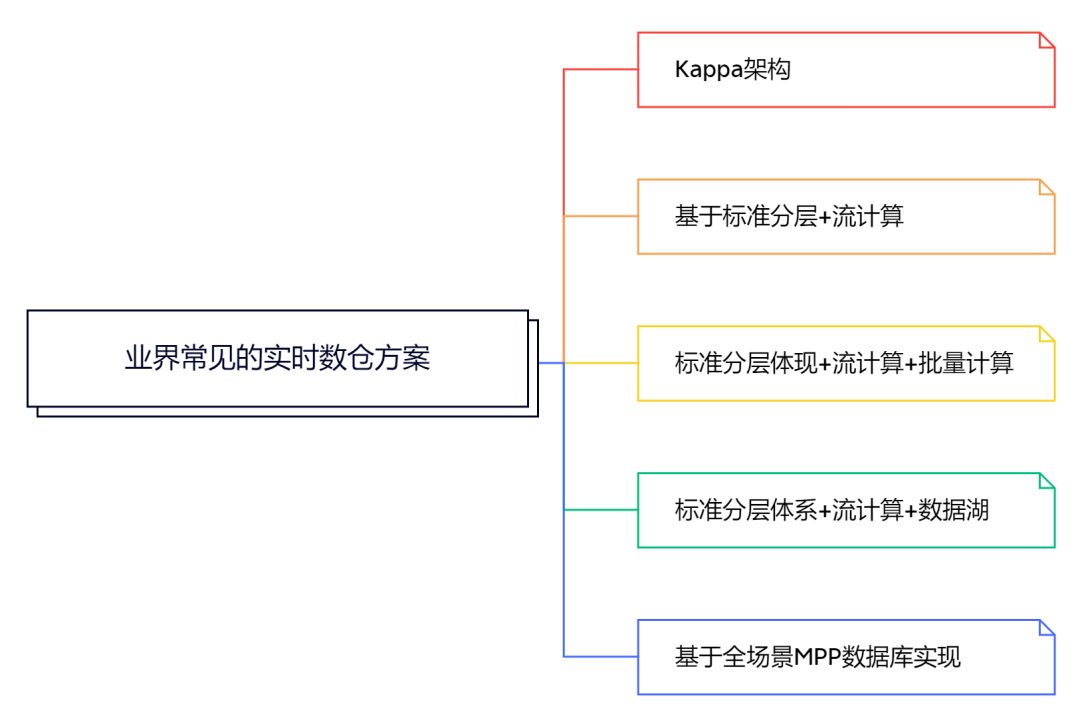
目前大部分还在使用的标准分层体现+流计算+批量计算的方案。未来大家可能都会迁移到标准分层体系+流计算+数据湖,和基于全场景MPP数据库实现的方案上,我也会重点介绍这两个方案,也希望大家能够多花点时间加以理解。
方案 1:Kappa 架构
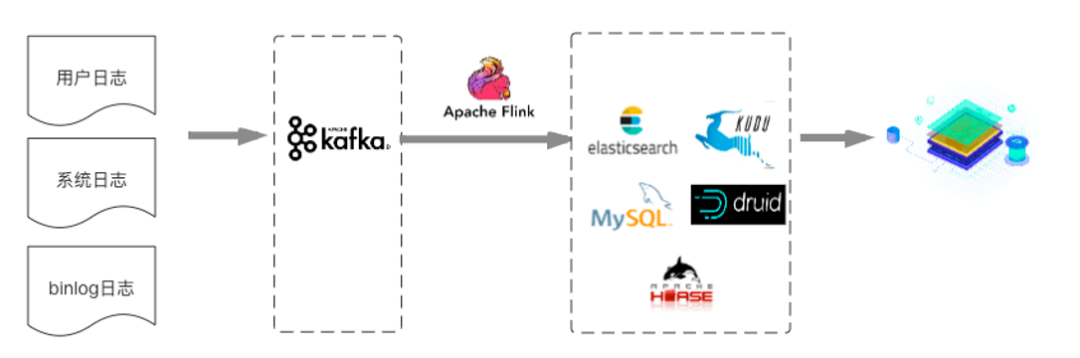
首先看下Kappa架构,Kappa架构将多源数据(用户日志,系统日志,BinLog日志)实时地发送到Kafka中。
然后通过Flink集群,按照不同的业务构建不同的流式计算任务,对数据进行数据分析和处理,并将计算结果输出到MySQL/ElasticSearch/HBase/Druid/KUDU等对应的数据源中,最终提供应用进行数据查询或者多维分析。
这种方案的好处有二,方案简单;数据实时。
不过有两个缺点:
① 用户每产生一个新的报表需求,都需要开发一个Flink流式计算任务,数据开发的人力成本和时间成本都较高。
② 对于每天需要接入近百亿的数据平台,如果要分析近一个月的数据,则需要的Flink集群规模要求很大,且需要将很多计算的中间数据存储在内存中以便多流Join。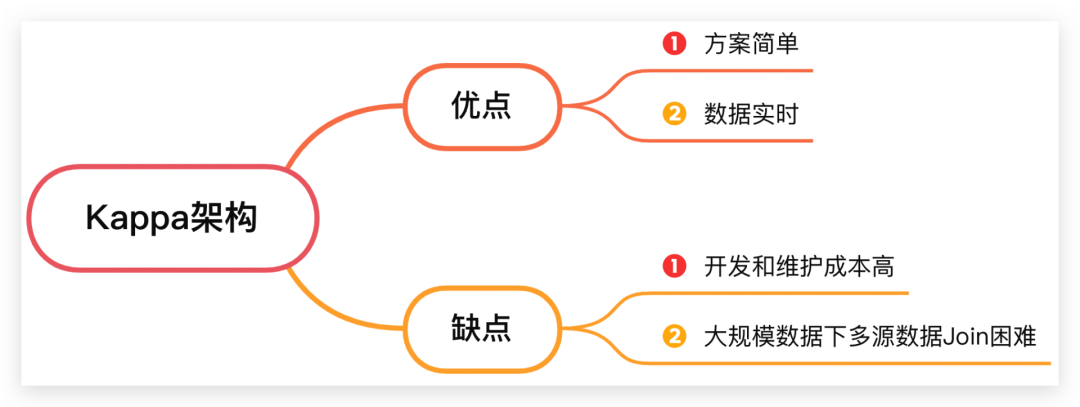
方案 2:基于标准分层 + 流计算
为了解决方案1中将所有数据放在一个层出现的开发维护成本高等问题,于是出现了基于标准分层+流计算的方案。
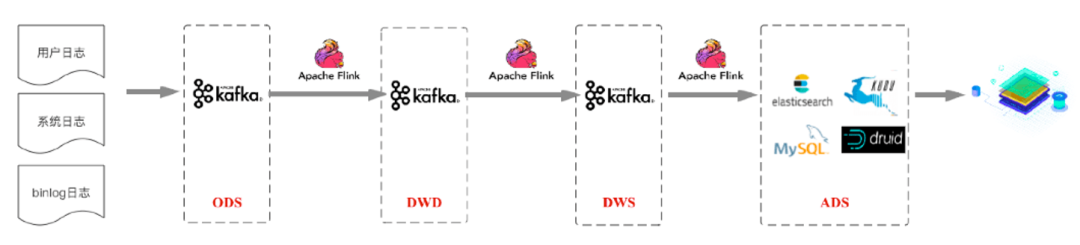
接下来咱们看下这种方案,在传统数仓的分层标准上构建实时数仓,将数据分为ODS、DWD、DWS、ADS层。首先将各种来源的数据接入ODS贴源数据层,再对ODS层的数据使用Flink的实时计算进行过滤、清洗、转化、关联等操作,形成针对不同业务主题的DWD数据明细层,并将数据发送到Kafka集群。
之后在DWD基础上,再使用Flink实时计算进行轻度的汇总操作,形成一定程度上方便查询的DWS轻度汇总层。最后再面向业务需求,在DWS层基础上进一步对数据进行组织进入ADS数据应用层,业务在数据应用层的基础上支持用户画像、用户报表等业务场景。
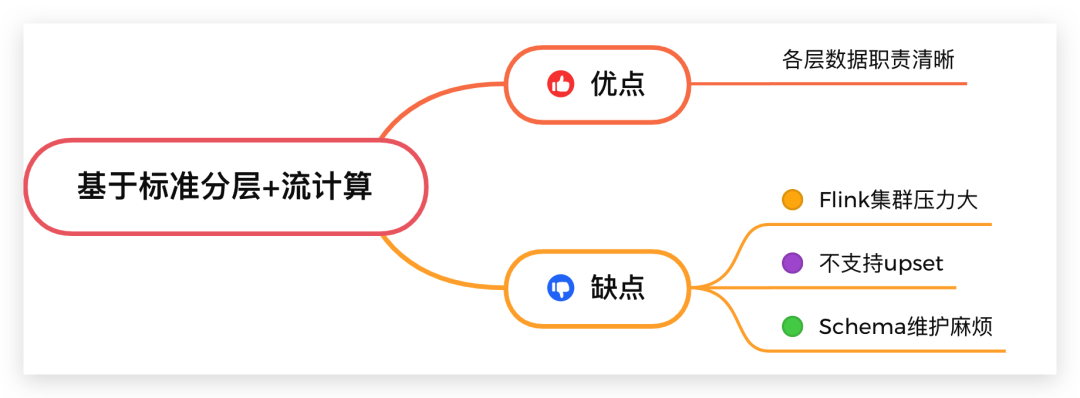
这种方案的优点:各层数据职责清晰。
缺点:是多个Flink集群维护起来复杂,并且过多的数据驻留在Flink集群内也会增大集群的负载,不支持upset操作,同时Schema维护麻烦。
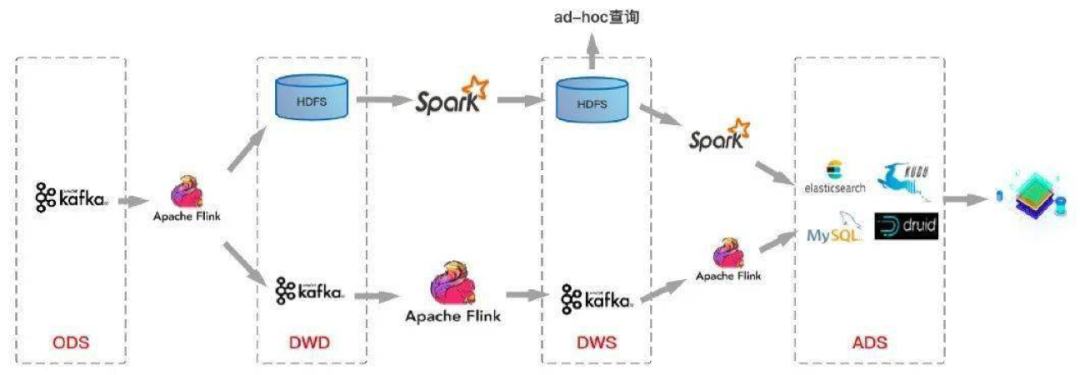
方案 3:标准分层体现+流计算+批量计算
为了解决方案2不支持upset和schema维护复杂等问题。我们在方案2的基础上加入基于HDFS加Spark离线的方案。也就是离线数仓和实时数仓并行流转的方案。
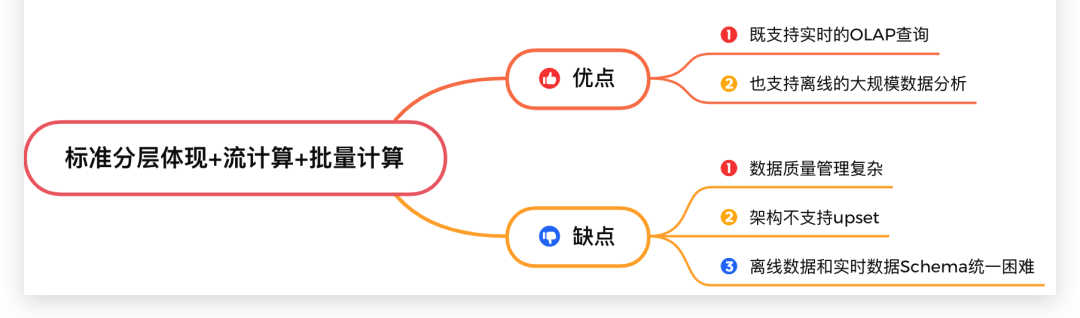
这种方案带来的优点:既支持实时的OLAP查询,也支持离线的大规模数据分析。
缺点:数据质量管理复杂,需要构建一套兼容离线数据和实时数据血缘关系的数据管理体系,本身就是一个复杂的工程问题。离线数据和实时数据Schema统一困难,架构不支持upset。
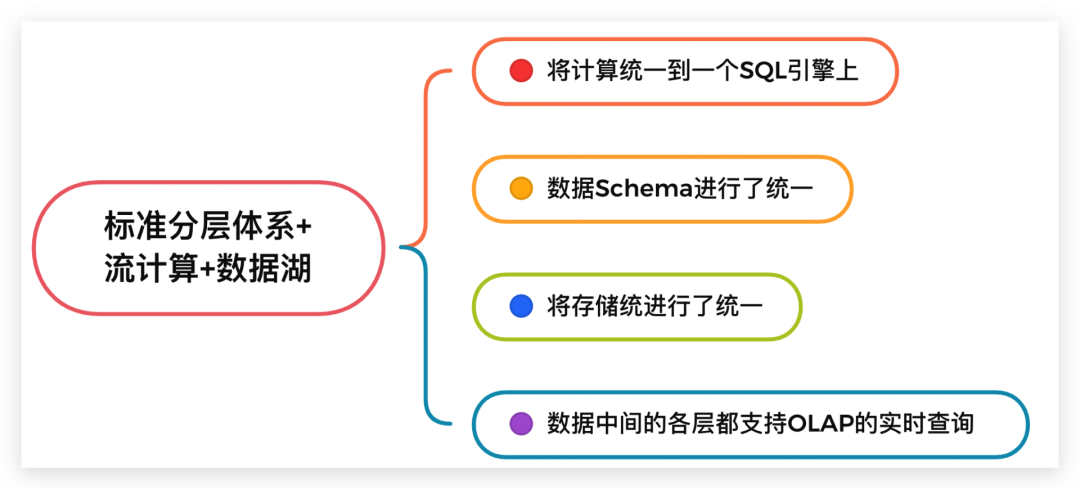
方案 4:标准分层体系+流计算+数据湖
随着技术的发展,为了解决数据质量管理和upset 问题。出现了流批一体架构,这种架构基于数据湖三剑客 Delta Lake / Hudi / Iceberg 实现 + Spark 实现。
我们以Iceberg为例介绍下这种方案的架构,从下图可以看到这方案和前面的方案2很相似,只是在数据存储层将Kafka换为了Iceberg。
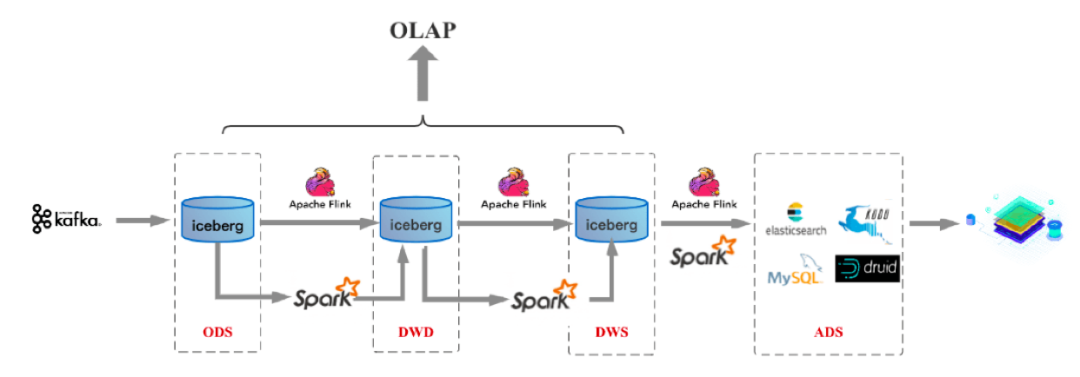 它有这样的几个特点,其中第2、3点,尤为重要,需要特别关注下,这也是这个方案和其他方案的重要差别。
它有这样的几个特点,其中第2、3点,尤为重要,需要特别关注下,这也是这个方案和其他方案的重要差别。
① 在编程上将流计算和批计算统一到同一个SQL引擎上,基于同一个Flink SQL既可以进行流计算,也可以进行批计算。
② 将流计算和批计算的存储进行了统一,也就是统一到Iceberg/HDFS上,这样数据的血缘关系的和数据质量体系的建立也变得简单了。
③ 由于存储层统一,数据的Schema也自然统一起来了,这样相对流批单独两条计算逻辑来说,处理逻辑和元数据管理的逻辑都得到了统一。
④ 数据中间的各层(ODS、DWD、DWS、ADS)数据,都支持OLAP的实时查询。
那么为什么 Iceberg 能承担起实时数仓的方案呢,主要原因是它解决了长久以来流批统一时的这些难题:
① 同时支持流式写入和增量拉取。
② 解决小文件多的问题。数据湖实现了相关合并小文件的接口,Spark / Flink上层引擎可以周期性地调用接口进行小文件合并。
③ 支持批量以及流式的 Upsert(Delete) 功能。批量Upsert / Delete功能主要用于离线数据修正。流式upsert场景前面介绍了,主要是流处理场景下经过窗口时间聚合之后有延迟数据到来的话会有更新的需求。这类需求是需要一个可以支持更新的存储系统的,而离线数仓做更新的话需要全量数据覆盖,这也是离线数仓做不到实时的关键原因之一,数据湖是需要解决掉这个问题的。
④ 同时 Iceberg 还支持比较完整的OLAP生态。比如支持Hive / Spark / Presto / Impala 等 OLAP 查询引擎,提供高效的多维聚合查询性能。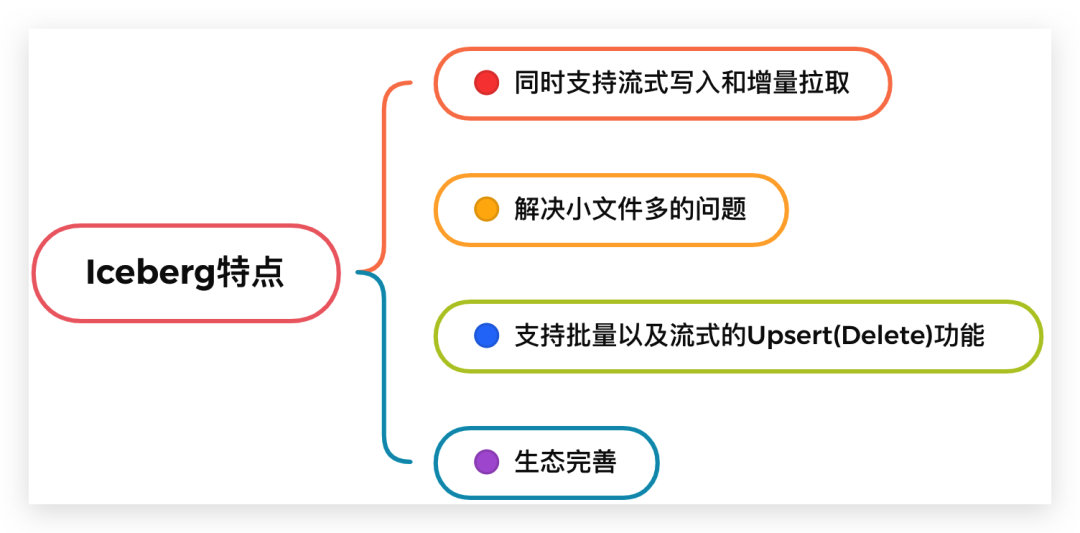
Iceberg 实战
上面介绍了基于Iceberg的标准分层体系+流计算+数据湖的架构,下面从实战角度看下Iceberg如何使用。
lceberg写入流式数据代码实现如下:
data.writeStream.format("iceberg")
.outputMode("append")
.trigger(Trigger.ProcessingTime(1, TimeUnit.MINUTES)).option("data_path", tableIdentifier)
.option("checkpointLocation", checkpointPath)
.start()上述代码会将data_path下的数据以流的形式,实时加入到系统中进行计算。
lceberg数据过滤代码实现如下:
Table table = ... Actions.forTable(table).rewriteDataFiles() .filter(Expressions.equal("date", "2022-03-18"))
.targetSizeInBytes(500 * 1024 * 1024) // 500 MB
.execute();上述代码过滤出date为2022-03-18的数据。
方案 5:基于全场景MPP数据库实现
前面的四种方案,是基于数仓方案的优化。方案仍然属于比较复杂的,如果我能提供一个数据库既能满足海量数据的存储,也能实现快速分析,那岂不是很方便。这时候便出现了以StartRocks和ClickHouse为代表的全场景MPP数据库。
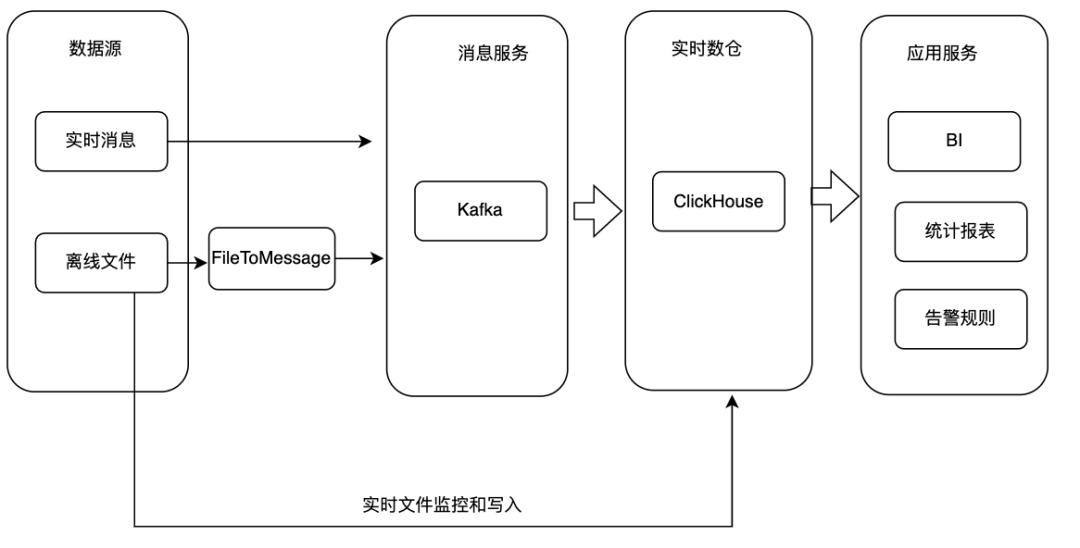
① 基于Darios或者ClickHouse构建实时数仓。来看下具体的实现方式:将数据源上的实时数据直接写入消费服务。
② 对于数据源为离线文件的情况有两种处理方式,一种是将文件转为流式数据写入Kafka,另外一种情况是直接将文件通过Sql导入ClickHouse集群。
③ ClickHouse接入Kafka消息并将数据写入对应的原始表,基于原始表可以构建物化视图、Project等实现数据聚合和统计分析。
④ 应用服务基于ClickHouse数据对外提供BI、统计报表、告警规则等服务。
二、具体选型建议
对于这5种方案,在具体选型中,我们要根据具体业务需求、团队规模等进行技术方案选型。
说到这儿,我有这样的几点具体建议,希望或多或少可以给你提供一些可供参考、借鉴的新视角或者新思路:
① 对于业务简单,且以流式数据为主数据流的大数据架构可以采用方案1的Kappa架构。
② 如果业务以流计算为主,对数据分层,数据权限,多主题数据要求比较高,建议使用方案2的基于标准分层+流计算。
③ 如果业务的流数据是批数据都比较多,且流数据和批数据直接的关联性不大,建议使用方案3的标准分层体现+流计算+批量计算。这种情况下分别能发挥流式计算和批量计算各自的优势。
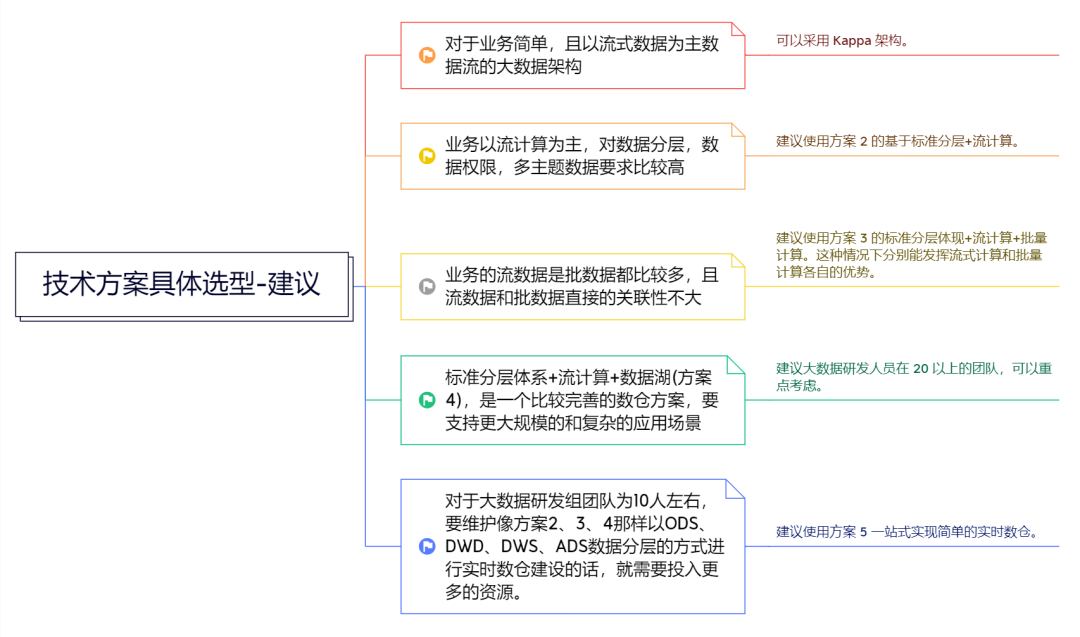
④ 方案4是一个比较完善的数仓方案,要支持更大规模的和复杂的应用场景,建议大数据研发人员在20以上的团队,可以重点考虑。
⑤ 对于大数据研发组团队为10人左右,要维护像方案2、3、4那样以ODS、DWD、DWS、ADS数据分层的方式进行实时数仓建设的话,就需要投入更多的资源。建议使用方案5一站式实现简单的实时数仓。
三、大厂方案分享
介绍了这么多实时数仓方案,那么很多小伙伴会问了,大厂到底用的那种方案呢?其实每个大厂根据自己业务特点的不同,也会选择不同的解决方案。下面为大家简要分享下OPPO、滴滴和比特大陆、美团实例方案,以便大家能够更好地理解这篇分享中五种架构的具体落地。
不过具体架构细节我不会进行过多的介绍,有了前面的内容基础,相信大家再通过架构图就能很快了解每个架构的特点。这里只是希望大家能够通过大厂的经验,明白他们架构设计的初衷和要解决的具体问题,同时也给我们的架构设计提供一些思路。
举例来说,OPPO实时计算平台架构,其方案其实类似于方案2的基于标准分层+流计算。
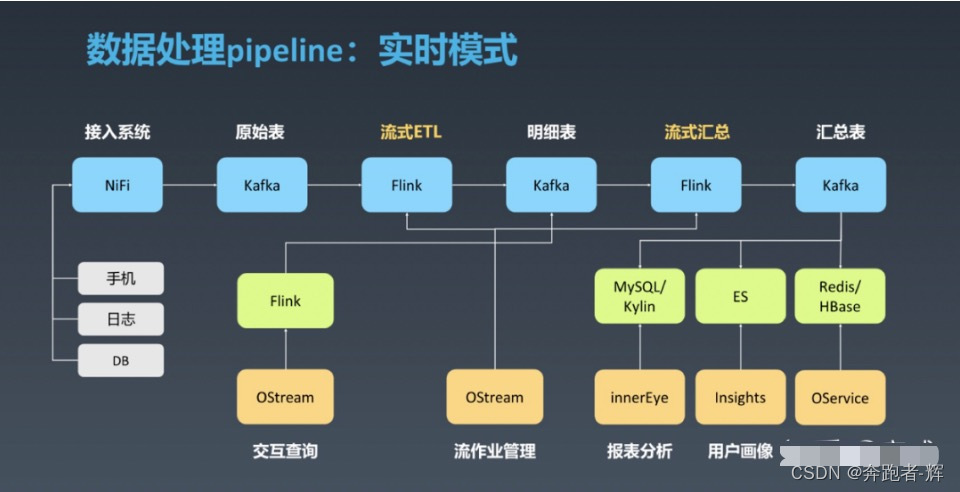
滴滴的大数据平台架构是这样的,它的方案其实类似于方案2的基于标准分层+流计算。
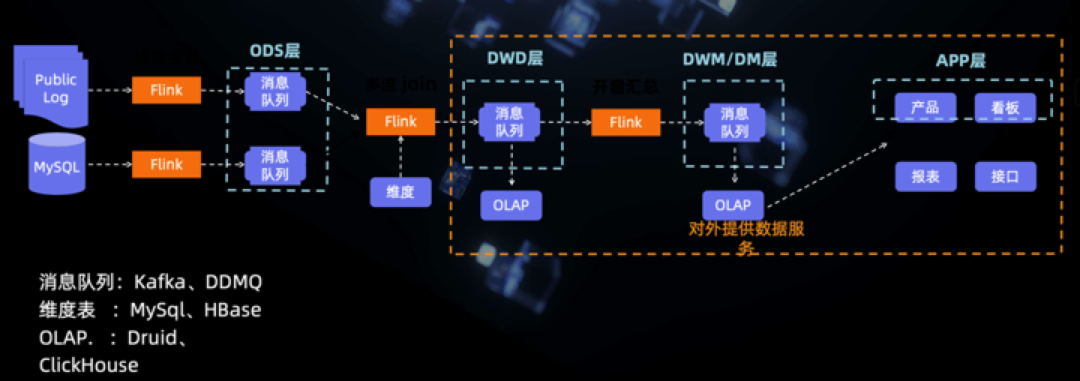
滴滴顺风车实时数仓案例

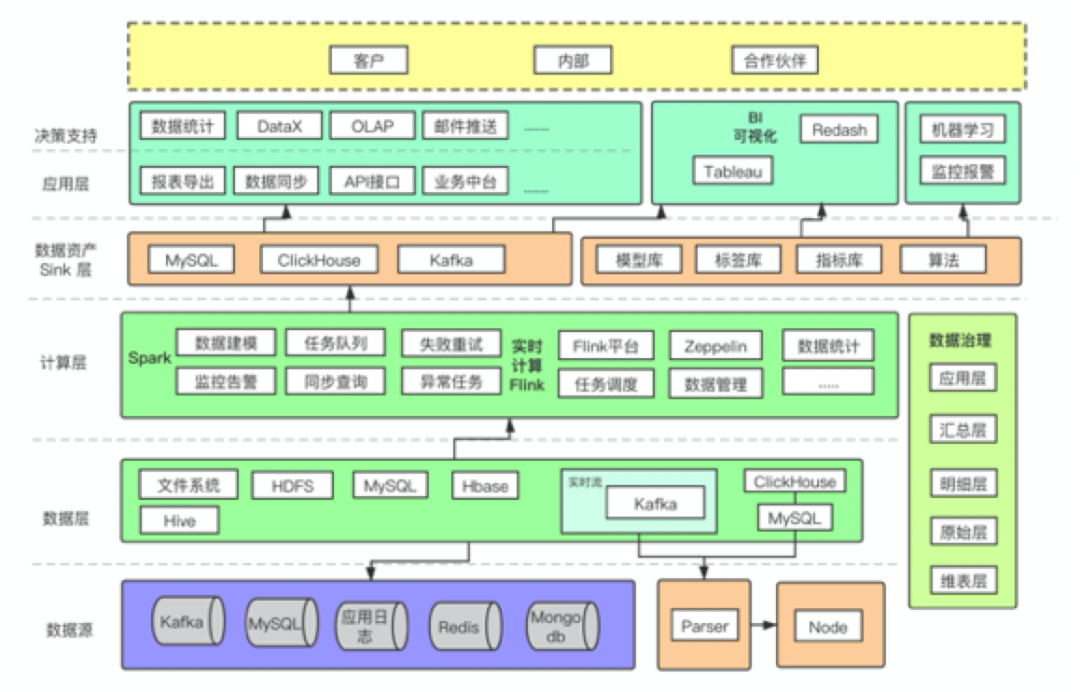
再结合比特大陆的方案看下,其方案类型方案3的标准分层体现+流计算+批量计算,同时也引入了ClickHouse,可以看到比特大陆的数据方案是很复杂的。
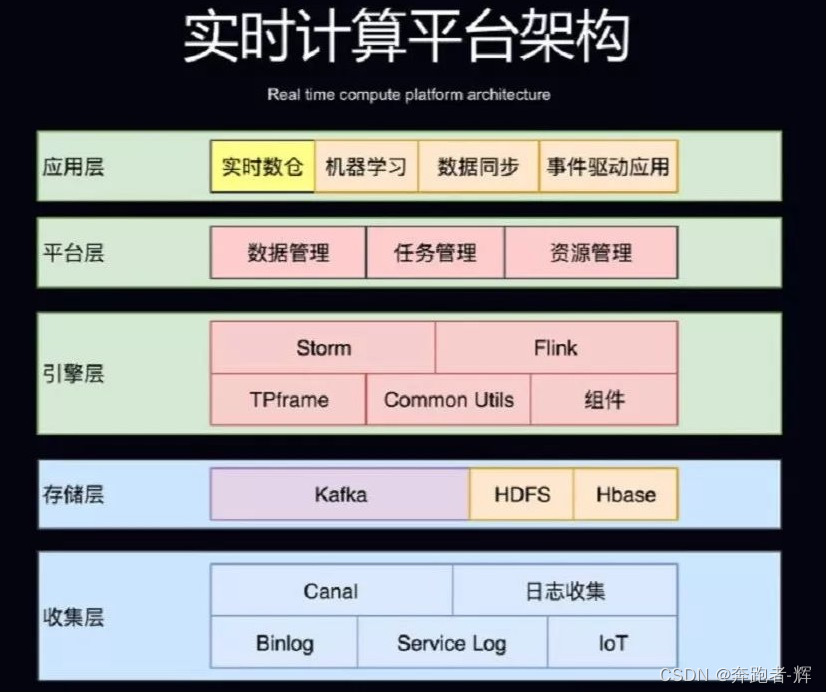
美团点评基于Flink的实时数仓平台实践
四、结语 & 延申思考
本文介绍了市面上常见实时数仓方案,并对不同方案的优缺点进行了介绍。在使用过程中我们需要根据自己的业务场景选择合适的架构。
另外想说明的是实时数仓方案并不是“搬过来”,而是根据业务“演化来”的,具体设计的时候需要根据自身业务情况,找到最适合自己当下的实时数仓架构。
延申思考
我们在实时数仓的构建过程中比较大的争议是采用标准分层体系+流计算+数据湖的方案,还是试用基于全场景MPP数据库实现 ?
在讨论过程中大家比较大的分歧是基于全场景MPP数据库实现到底算是一个数仓方案不,毕竟该方案没有标准的数仓分层的思想,而是围绕大规模数据统计的需求来实现的。
但是我的观点是:一切方案都需要以实际需求为出发点,我们的80%的需求就是在一个180多个字段的大宽表(每天80亿条,3TB数据量)上可以灵活的统计分析,快速为业务决策提供依据。因此我们选择了基于全场景MPP数据库方案。
新的技术层出不穷,对我们技术人来说尝鲜是很爽的一件事情,但是实际落地还是建议大家把需求收敛好后再做决策,保持冷静的思维,有时候适当地“让子弹飞一会”也是有好处的。