一、视频读写
1. 从文件中读取视频并播放
在OpenCV中我们要获取一个视频,需要创建一个VideoCapture对象,指定你要读取的视频文件:
(1)创建读取视频的对象
cap = cv.VideoCapture(filepath)
参数:
- filepath: 视频文件路径
(2)视频的属性信息
获取视频的某些属性
retval = cap.get(propId)
参数:
- propId: 从0到18的数字,每个数字表示视频的属性
常用属性有:

修改视频的属性信息
cap.set(propId,value)
参数:
- proid: 属性的索引,与上面的表格相对应
- value: 修改后的属性值
(3)判断图像是否读取成功
isornot = cap.isOpened()
若读取成功则返回true,否则返回False
(4)获取视频的一帧图像
ret, frame = cap.read()
参数:
- ret: 若获取成功返回True,获取失败,返回False
- Frame: 获取到的某一帧的图像
(5)显示图像
调用cv.imshow()显示图像,在显示图像时使用cv.waitkey()设置适当的持续时间,如果太低视频会播放的非常快,如果太高就会播放的非常慢,通常情况下我们设置25ms就可以了。
(6)释放视频
最后,调用cap.realease()将视频释放掉
示例:
import numpy as np
import cv2 as cv
# 1.获取视频对象
cap = cv.VideoCapture('DOG.wmv')
# 2.判断是否读取成功
while(cap.isOpened()):
# 3.获取每一帧图像
ret, frame = cap.read()
# 4. 获取成功显示图像
if ret == True:
cv.imshow('frame',frame)
# 5.每一帧间隔为25ms
if cv.waitKey(25) & 0xFF == ord('q'):
break
# 6.释放视频对象
cap.release()
cv.destoryAllwindows()
2. 保存视频
在OpenCV中我们保存视频使用的是VedioWriter对象,在其中指定输出文件的名称,如下所示:
(1)创建视频写入的对象
out = cv2.VideoWriter(filename,fourcc, fps, frameSize)
参数:
- filename:视频保存的位置
- fourcc:指定视频编解码器的4字节代码
- fps:帧率
- frameSize:帧大小
(2)设置视频的编解码器,如下所示,
retval = cv2.VideoWriter_fourcc( c1, c2, c3, c4 )
参数:
- c1,c2,c3,c4: 是视频编解码器的4字节代码,在fourcc.org中找到可用代码列表,与平台紧密相关,常用的有:
- 在Windows中:DIVX(.avi)
- 在OS中:MJPG(.mp4),DIVX(.avi),X264(.mkv)。
(3)利用cap.read()获取视频中的每一帧图像,并使用out.write()将某一帧图像写入视频中。
(4)使用cap.release()和out.release()释放资源。
示例:
import cv2 as cv
import numpy as np
# 1. 读取视频
cap = cv.VideoCapture("DOG.wmv")
# 2. 获取图像的属性(宽和高,),并将其转换为整数
frame_width = int(cap.get(3))
frame_height = int(cap.get(4))
# 3. 创建保存视频的对象,设置编码格式,帧率,图像的宽高等
out = cv.VideoWriter('outpy.avi',cv.VideoWriter_fourcc('M','J','P','G'), 10, (frame_width,frame_height))
while(True):
# 4.获取视频中的每一帧图像
ret, frame = cap.read()
if ret == True:
# 5.将每一帧图像写入到输出文件中
out.write(frame)
else:
break
# 6.释放资源
cap.release()
out.release()
cv.destroyAllWindows()
二、视频追踪
1. meanshift
1.1 原理
meanshift算法的原理很简单。假设你有一堆点集,还有一个小的窗口,这个窗口可能是圆形的,现在你可能要移动这个窗口到点集密度最大的区域当中。
如下图:

最开始的窗口是蓝色圆环的区域,命名为C1。蓝色圆环的圆心用一个蓝色的矩形标注,命名为C1_o。
而窗口中所有点的点集构成的质心在蓝色圆形点C1_r处,显然圆环的形心和质心并不重合。所以,移动蓝色的窗口,使得形心与之前得到的质心重合。在新移动后的圆环的区域当中再次寻找圆环当中所包围点集的质心,然后再次移动,通常情况下,形心和质心是不重合的。不断执行上面的移动过程,直到形心和质心大致重合结束。 这样,最后圆形的窗口会落到像素分布最大的地方,也就是图中的绿色圈,命名为C2。
meanshift算法除了应用在视频追踪当中,在聚类,平滑等等各种涉及到数据以及非监督学习的场合当中均有重要应用,是一个应用广泛的算法。
图像是一个矩阵信息,如何在一个视频当中使用meanshift算法来追踪一个运动的物体呢? 大致流程如下:
-
首先在图像上选定一个目标区域
-
计算选定区域的直方图分布,一般是HSV色彩空间的直方图。
-
对下一帧图像b同样计算直方图分布。
-
计算图像b当中与选定区域直方图分布最为相似的区域,使用meanshift算法将选定区域沿着最为相似的部分进行移动,直到找到最相似的区域,便完成了在图像b中的目标追踪。
-
重复3到4的过程,就完成整个视频目标追踪。
通常情况下我们使用直方图反向投影得到的图像和第一帧目标对象的起始位置,当目标对象的移动会反映到直方图反向投影图中,meanshift 算法就把我们的窗口移动到反向投影图像中灰度密度最大的区域了。如下图所示:

直方图反向投影的流程是:
假设我们有一张100x100的输入图像,有一张10x10的模板图像,查找的过程是这样的:
- 从输入图像的左上角(0,0)开始,切割一块(0,0)至(10,10)的临时图像;
- 生成临时图像的直方图;
- 用临时图像的直方图和模板图像的直方图对比,对比结果记为c;
- 直方图对比结果c,就是结果图像(0,0)处的像素值;
- 切割输入图像从(0,1)至(10,11)的临时图像,对比直方图,并记录到结果图像;
- 重复1~5步直到输入图像的右下角,就形成了直方图的反向投影。
1.2 实现
在OpenCV中实现Meanshift的API是:
cv.meanShift(probImage, window, criteria)
参数:
- probImage: ROI区域,即目标的直方图的反向投影
- window: 初始搜索窗口,就是定义ROI的rect
- criteria: 确定窗口搜索停止的准则,主要有迭代次数达到设置的最大值,窗口中心的漂移值大于某个设定的限值等。
实现Meanshift的主要流程是:
- 读取视频文件:cv.videoCapture()
- 感兴趣区域设置:获取第一帧图像,并设置目标区域,即感兴趣区域
- 计算直方图:计算感兴趣区域的HSV直方图,并进行归一化
- 目标追踪:设置窗口搜索停止条件,直方图反向投影,进行目标追踪,并在目标位置绘制矩形框。
示例:
import numpy as np
import cv2 as cv
# 1.获取图像
cap = cv.VideoCapture('DOG.wmv')
# 2.获取第一帧图像,并指定目标位置
ret,frame = cap.read()
# 2.1 目标位置(行,高,列,宽)
r,h,c,w = 197,141,0,208
track_window = (c,r,w,h)
# 2.2 指定目标的感兴趣区域
roi = frame[r:r+h, c:c+w]
# 3. 计算直方图
# 3.1 转换色彩空间(HSV)
hsv_roi = cv.cvtColor(roi, cv.COLOR_BGR2HSV)
# 3.2 去除低亮度的值
# mask = cv.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((180.,255.,255.)))
# 3.3 计算直方图
roi_hist = cv.calcHist([hsv_roi],[0],None,[180],[0,180])
# 3.4 归一化
cv.normalize(roi_hist,roi_hist,0,255,cv.NORM_MINMAX)
# 4. 目标追踪
# 4.1 设置窗口搜索终止条件:最大迭代次数,窗口中心漂移最小值
term_crit = ( cv.TERM_CRITERIA_EPS | cv.TERM_CRITERIA_COUNT, 10, 1 )
while(True):
# 4.2 获取每一帧图像
ret ,frame = cap.read()
if ret == True:
# 4.3 计算直方图的反向投影
hsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)
dst = cv.calcBackProject([hsv],[0],roi_hist,[0,180],1)
# 4.4 进行meanshift追踪
ret, track_window = cv.meanShift(dst, track_window, term_crit)
# 4.5 将追踪的位置绘制在视频上,并进行显示
x,y,w,h = track_window
img2 = cv.rectangle(frame, (x,y), (x+w,y+h), 255,2)
cv.imshow('frame',img2)
if cv.waitKey(60) & 0xFF == ord('q'):
break
else:
break
# 5. 资源释放
cap.release()
cv.destroyAllWindows()
下面是三帧图像的跟踪结果:

2. Camshift
大家认真看下上面的结果,有一个问题,就是检测的窗口的大小是固定的,而狗狗由近及远是一个逐渐变小的过程,固定的窗口是不合适的。所以我们需要根据目标的大小和角度来对窗口的大小和角度进行修正。CamShift可以帮我们解决这个问题。
CamShift算法全称是“Continuously Adaptive Mean-Shift”(连续自适应MeanShift算法),是对MeanShift算法的改进算法,可随着跟踪目标的大小变化实时调整搜索窗口的大小,具有较好的跟踪效果。
Camshift算法首先应用meanshift,一旦meanshift收敛,它就会更新窗口的大小,还计算最佳拟合椭圆的方向,从而根据目标的位置和大小更新搜索窗口。如下图所示:
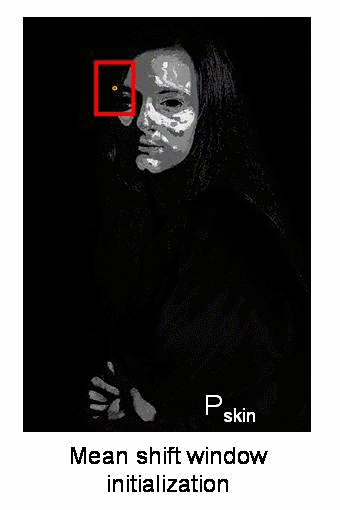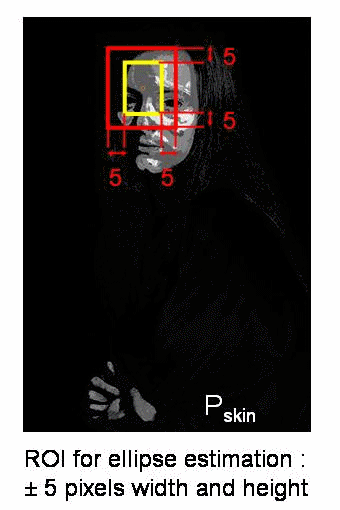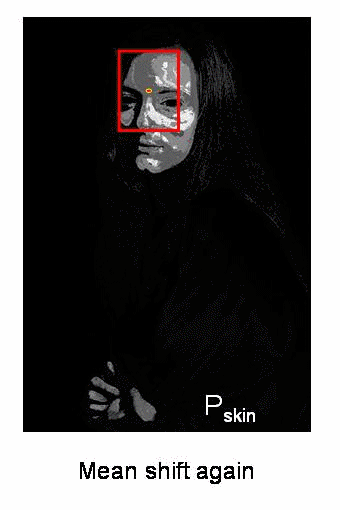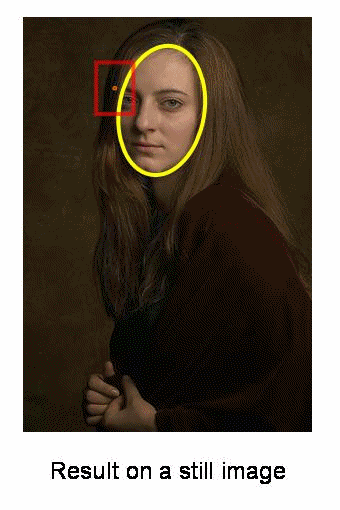
Camshift在OpenCV中实现时,只需将上述的meanshift函数改为Camshift函数即可:
将Camshift中的:
# 4.4 进行meanshift追踪
ret, track_window = cv.meanShift(dst, track_window, term_crit)
# 4.5 将追踪的位置绘制在视频上,并进行显示
x,y,w,h = track_window
img2 = cv.rectangle(frame, (x,y), (x+w,y+h), 255,2)
改为:
#进行camshift追踪
ret, track_window = cv.CamShift(dst, track_window, term_crit)
# 绘制追踪结果
pts = cv.boxPoints(ret)
pts = np.int0(pts)
img2 = cv.polylines(frame,[pts],True, 255,2)
3. 算法总结
Meanshift和camshift算法都各有优势,自然也有劣势:
-
Meanshift算法:简单,迭代次数少,但无法解决目标的遮挡问题并且不能适应运动目标的的形状和大小变化。
-
camshift算法:可适应运动目标的大小形状的改变,具有较好的跟踪效果,但当背景色和目标颜色接近时,容易使目标的区域变大,最终有可能导致目标跟踪丢失。