本章,来一波获取情头,有女朋友,或者没女朋友想换高清,好看头像的可以看过来了。
结尾会附上源码地址。
先看图:
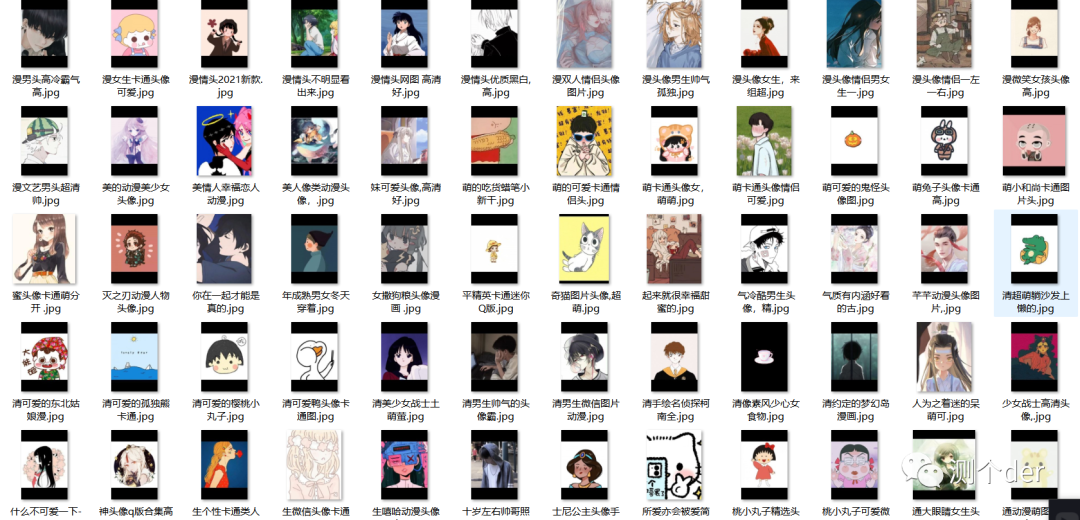
该网站唯一的缺点就是爬取多了会限制获取速度,导致获取一段时间后只能一张张获取,不过索性,速度还不是特别慢,也久0.几一张吧。
解决的办法还是有的,不过稍微有那么一丢丢麻烦,咱们就先不管了。干了再说。
老规矩先看目标地址:https://www.umei.cc/touxiangtupian/katongtouxiang
再简单抓个包看看:
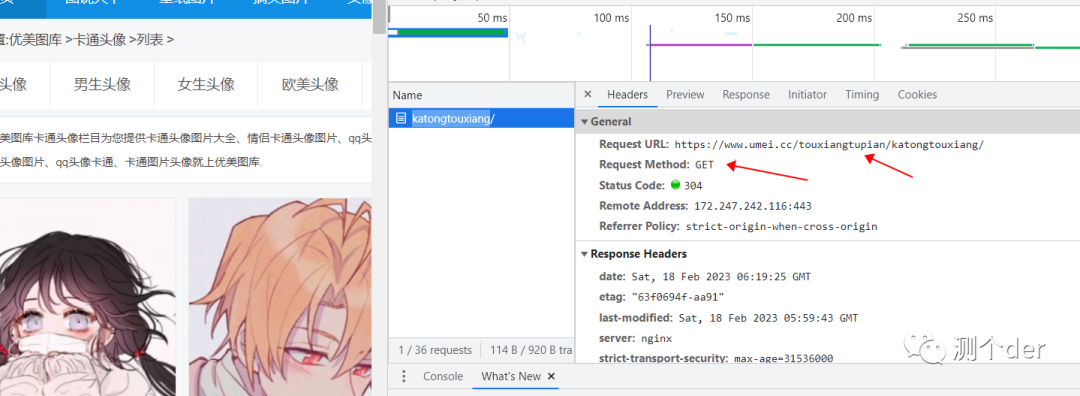
那么接下来问题就不大了。直接开造,先请求一下主页并获取相关的url跟标题:
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8'
html = etree.HTML(response.text)
get_href = html.xpath('//*[@id="infinite_scroll"]/div/div/div/a/img/@data-original')
get_title = html.xpath('//*[@id="infinite_scroll"]/div/div/div/a/img/@alt')由于编码问题,所以不得不加上encoding来解决。这里也是一口气直接锁定了图片的url,所以,能一口气干完的活,别拖拖拉拉,影响速率。
然后我们再来一个写入操作,另起一个函数
def writer_img(urls, titles, headers):
for href, title in zip(urls, titles):
try:
pic_res = requests.get(href, headers=headers).content
with open(path + f'/{title[1:10]}' + ".jpg", 'wb') as w:
w.write(pic_res)
print("下载成功!{}".format(href))
except:
print("出了点错,跳过吧")由于前面我们获取的是一个list,所以不得不循环一下了,再者,需要发起图片地址的请求,所以更得循环啦。
为了便捷一点,不再像以前一样指定桌面文件,所以我决定,引入os模块帮助我检测一下。
if __name__ == '__main__':
path = os.getcwd() + "/情头"
if os.path.isdir(path):
print("已经存在目录,继续获取~~")
else:
os.mkdir('情头')既如此,可以爬取了吗,没错。
不过问题又出现了,这样只能获取一页的,那么我想获取多页呢?
那就的看看url变化了
'https://www.umei.cc/touxiangtupian/katongtouxiang'
'https://www.umei.cc/touxiangtupian/katongtouxiang/index_2.htm'看到二者变化了吗。所以我们直接一不做二不休的,决定循环遍历:
for i in range(10):
if i == 0:
url = 'https://www.umei.cc/touxiangtupian/katongtouxiang'
else:
url = 'https://www.umei.cc/touxiangtupian/katongtouxiang/index_{}.htm'.format(i)为什么这么写,你悟!!!
好了,再后面就是调用的事情了,就不再多阐述了,上源码地址:https://gitee.com/qinganan_admin/reptile-case.git