文章目录
abstract
本篇文章主要介绍了一个缓存优化的方法,这个方法专门对大吞吐量的架构,比如GPU应用,因为作者发现在SIMT架构上对内存密集型应用GPU L1 D cache没有很好的发挥效用,对于非常多的应用程序,作者发现,GPU的L1 D-cache有着非常底的reuse率,这样降低了缓存的效率
对此作者门开发了一个高效本地监控机制,这个机制可以动态的过滤access stream的cache 的插入操作,此时的L1 Dcache只允许高reuse的数据存在这上面
introduction
这里主要的介绍了GPU L1 Dcache为什么会成为瓶颈,这里作者说了,因为大量的线程并行,导致L1的Dcache京城exceeds,并且因为大量的内存income请求,导致L1的Dcache不断地将reuse高的cache 驱逐出去,(cache pollution)就算一些高级的缓存驱逐算法(RRIP,SHiP)在这个问题上页捉襟见拙,并且大量的线程并发导致非常多cache中我们不可预料的情况发生,还会导致大量的资源拥堵,我们为了避免一些高reuse的缓存过早的被驱逐,cache by-pass被提及在cpu和GPU中,CPU的cache bypass一般在LLC(last level cache)中,因为一些数据早就已经在之前的缓存层级中过滤掉,但是因为GPU的workload不同,他要保证吞吐量,所以要处理大量的数据,所以他会资源堵塞,所以我们直接的预测会非常困难
问题背景
首先我们先说一下最基本的SM调度原则,首先一个指令到达一个SM,SM将其分配给一个ready warp,这个warp会进入compution/memory pipeline state,我们用户可以控制globa mamory和shared memory(SM中),并且硬件在数据局部性访问的时候可以隐式的控制L1 Dcache,因为GPU不常规的内存访问导致我们高效的显式内存变得非常困难,通常而言,多个SM都通过一个内部连接网络连接到内存模块,这个模块中有每个SM独享的L2缓存(SM中所有线程共享),还有SM独享的DRAM partition,GPU的L1缓存时write through(当L1中的cache被更改直接刷新到L2和DRAM中)的,发生write miss可以是write allocate或者是write no allocate,L2是write back(先写入cache的page中,当要驱逐的时候再写入main memory)with write allocate
数据局部性也是我们常说的空间局部性
这里还要介绍一下write allocate和write no allocate,WA(write allocate)和WNA(write no allocate)都是在发生write miss的时候产生的2种策略,
write allocate:在我们写这个数据之前,先将它从内存中拖到cache中再写,写完后看是write through还是write back 刷新主存
write no allocate:发生cache miss后直接在主存中改数据
victim cache 和hardware prefetching在GPU中一般不用
内存请求处理
我们一个内存相关指令到memory pipeline后(warp发送的),load_store单元将会甄别这个指令所访问的类型,然后根据内存访问的类型把指令发送到shared memory或者L1 D-cache等等,当我们指令访问的对象是global memory或者local memory,且线程都属于一个warp,他会将指令发送给coalescing unit,此时我们访问L1 Dcache就有2条线路如下如
首先第一条线路,warp的内存访问指令如果是访问内存首先会发给L1·Dcache,如果缓存命中将会立即把L1-Dcache中存储的东西返回给core的寄存器,假如缓存不命中,miss处理的逻辑是先查找MSHR(miss status holding register),一个miss状态的寄存器,关于cache miss和MSHR entire的创建或者写入信息参考我下面写的
关于MSHR建议看后面的链接https://miaochenlu.github.io/2020/10/29/MSHR/
简单介绍一下MSHR是no-block cache才会用到的,什么是no block cache?就是我们一个cache miss发生后,其他的访问该cache line的请求会不会block,假如会block就叫做block cache,不会block就是no-block cache,MSHR只有no block cache 发生cache miss的时候才会用,当我们的cache miss发生我们去找MSHR,看我们请求的cache block在不在里面,如果在里面(说明前一个指令也是请求相同的cache block),那么我们这个指令就会将自己load还是store这个cache的信息写入MSHR,写完后就不访问内存找数据,而是等待,假如我们的MSHR没有cache block的信息(访问的cache block第一次发生miss),我们就会为这个cache block创建一个MSHR entire,然后去内存请求数据,在这个时候就如我们上面所说,其他的指令如果访问这个cache block miss后发现这个cache block已经有了MSHR entire,就会将自己指令是准备load还是store这个数据写入对应的cache block的MSHR entire中(就不准备去内存拿数据),等创建这个cache block对应MSHR entire的指令从内存返回(此时已经拿到cache block对应的数据)然后更具其他指令存入的MSHR entire的信息(store/load)返回给相应的指令,最后删除这个MSHR entire
假如MSHR太多了,我们一个指令准备创建发现MSHR entire太多了,达到上限,此时指令就stall住
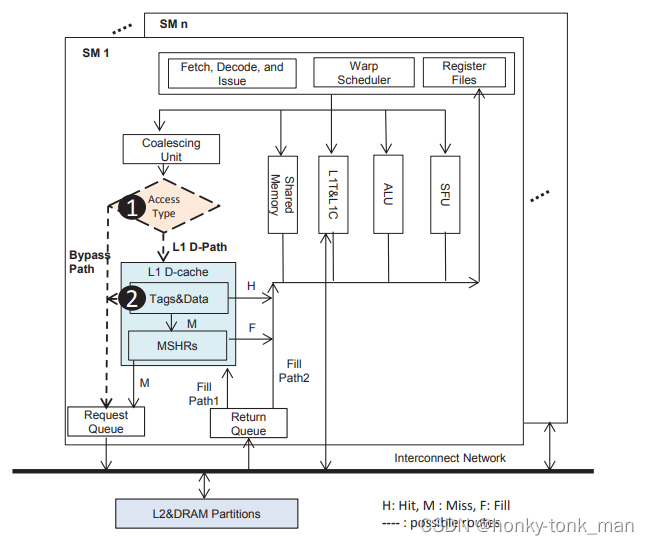
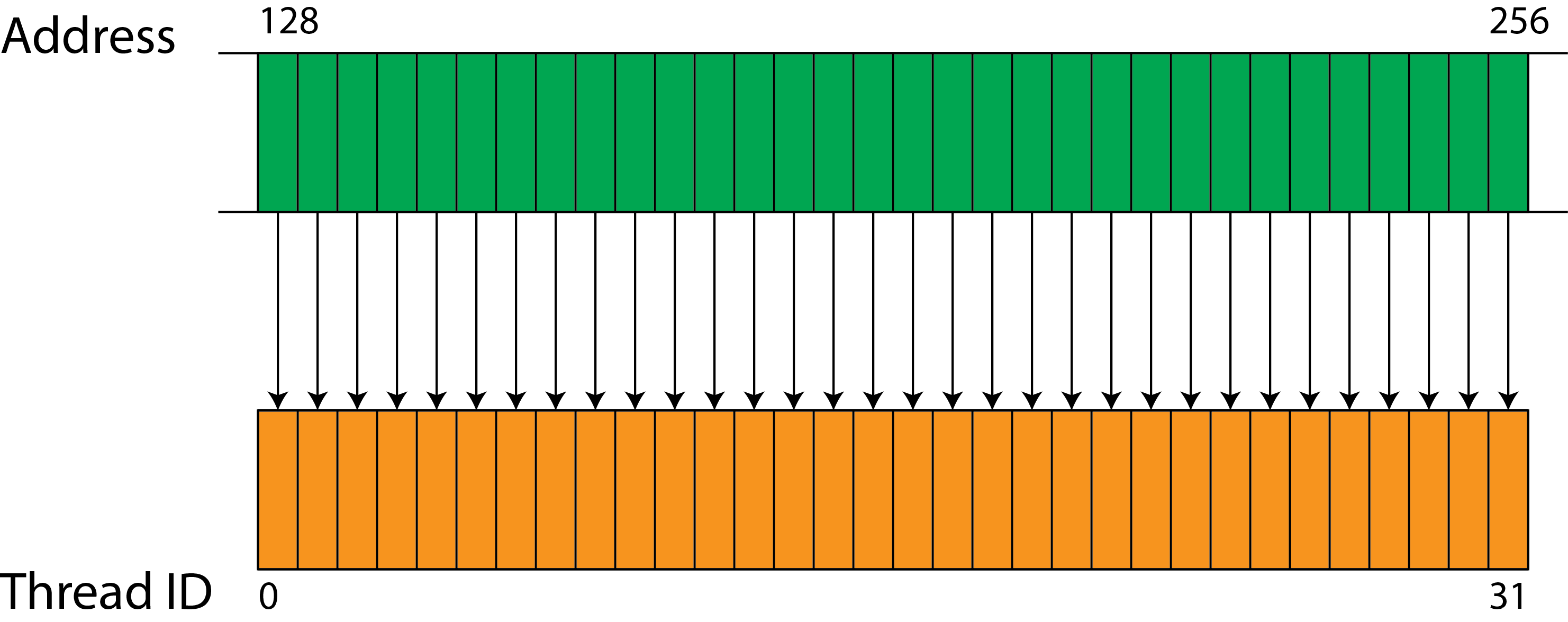
coalescing unit:首先什么是coalescing memory access,这个coalescing memory access就是集多个内存访问成一个transaction(内存的transaction就是内存一次访问),在K20的GPU上一个warp发起一次transaction可以访问128个连续字节,但是当我们的内存不是连续的(warp中每个线程所需要的数据不是连续的)那么我们就会引起uncoalesced load,什么叫做uncoalesced load就是内存访问变成线性,比如我们的thread本可以同时访问自己的所需要的内存,但是因为一次transaction捞起来的内存不是连续的(不是按照线程顺序排列或者稀疏,比如线程1要访问transaction捞起来的内存中下标为1的数据,但是线程二需要的数据在transaction捞起来的内存中下标为10,线程3需要的数据在transaction捞起来的内存中下标为12,这样不同线程之间所需要的数据步调不一致,这样导致我们第一个线程访问的时候其他的线程都han住了,因为其他的线程不知道offset为多少),下面就是一个coalescing memory access,每个线程对应的数据都是直接对齐,线程1需要第一个字节的内存,线程2需要第二个字节的内存,线程三需要第三个字节的内存,
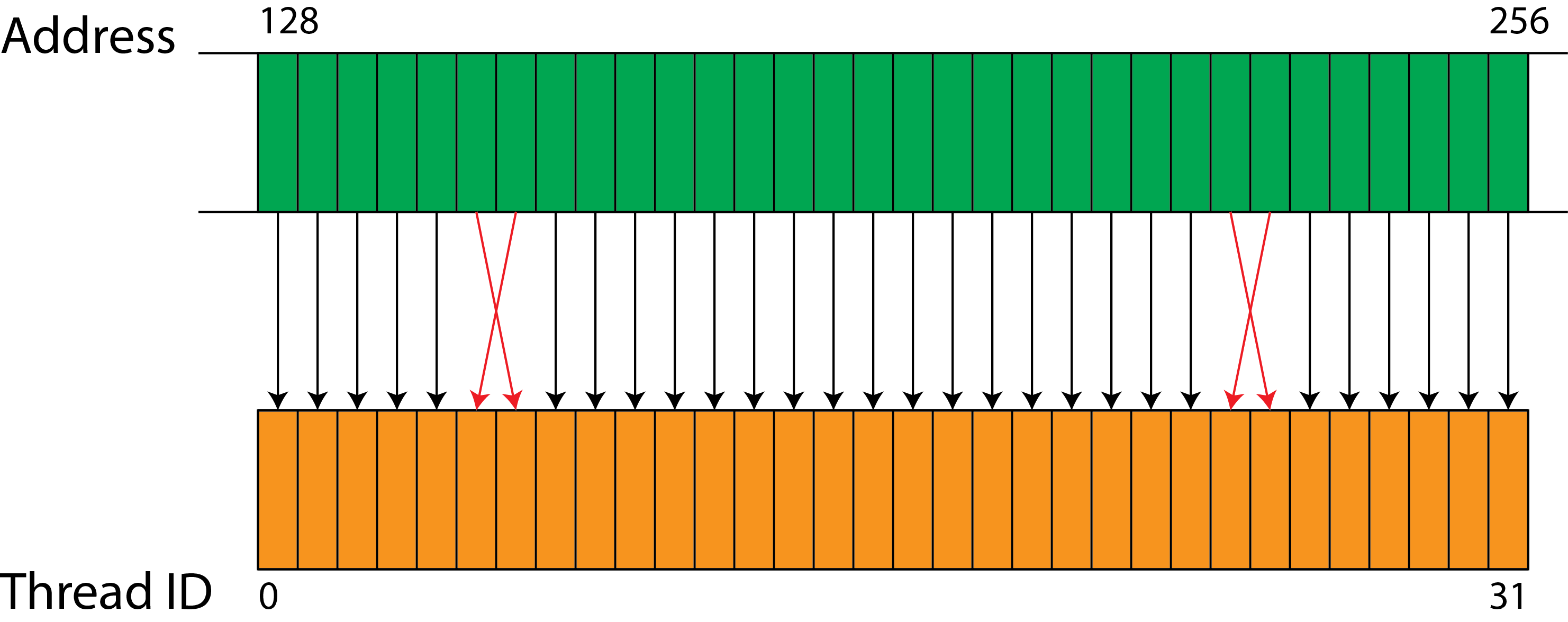
下面是一个线程和线程所需数据对齐但是顺序不一致的访问(也是uncoalesced load)
上图会导致并发效果没有第一个coalescing memory完全对齐,且顺序一致的并发效果那么好,因为我们要多加一个判断判断线程顺序和内存顺序不一致的那几个线程的访问
下面是未对齐内存但是线程顺序和内存一一对应那么此时我们只需要加上偏移量就可以达到coalescing memory的效果
下面是我们一个coalesced memory access 的操作,我们先假设一个线程访问一个元素,且线程所访问的元素顺序和线程顺序一样,且每个元素大小相等,我们一次事务将global mem中warp所需要的所有数据都放到shared mem中shared_mem[threadIdx.x] = global_mem[blockIdx.x * blockDim.x + threadIdx.x];下面的访问就不是coalesced memory access ,因为我们设置了偏移量(步调),但是还是可以得到很好的并发效果
stride = 4; shared_mem[threadIdx.x] = global_mem[stride * blockIdx.x * blockDim.x + stride * threadIdx.x]参考如下
https://cvw.cac.cornell.edu/gpu/coalesced
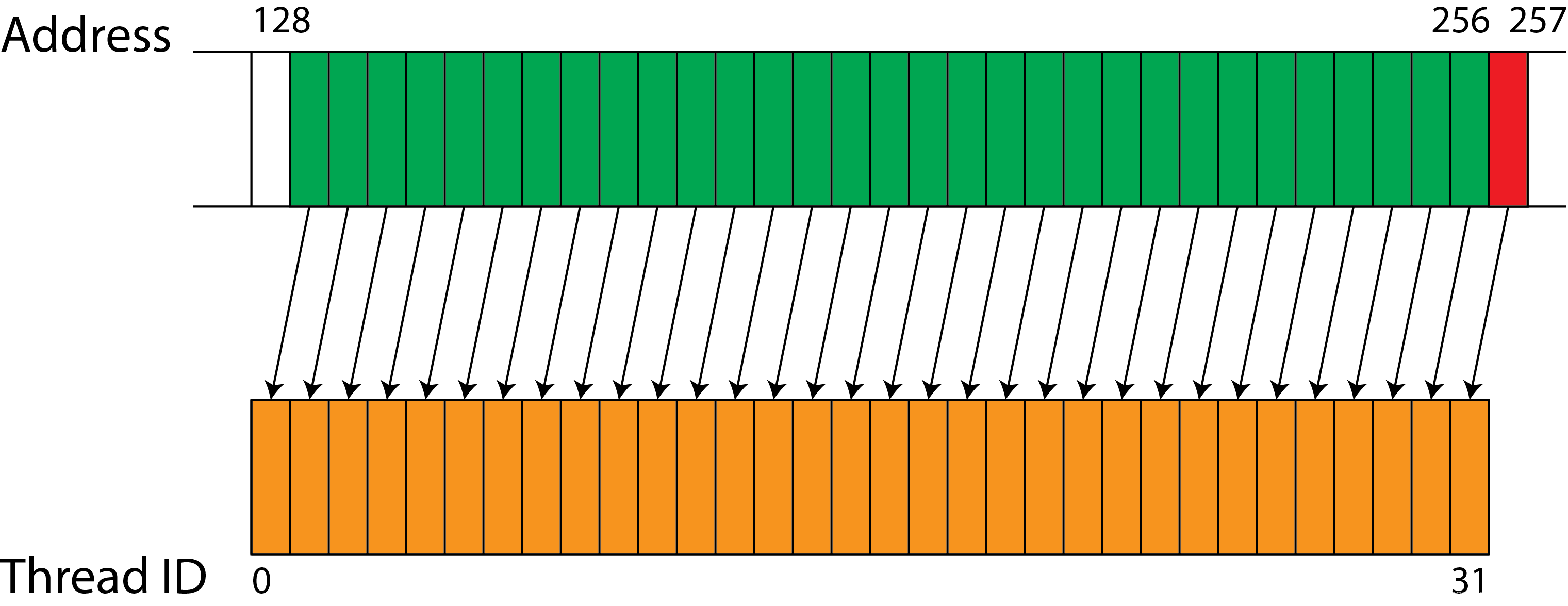
上面所说的都是cache access,还有一种访问叫做un-cache access,这里不是指缓存未命中,而是bypass L1 cache到我们的L2缓存或者global memory
假如我们的cache在L1缓存中,那么我们的cache access会比bypass L1cache快很多,延迟也会低很多,但是我们在高并行的场景下会引发,hight stall cycle,因为资源争用,而且还会一直驱逐cache block,所以我们需要一个局限性监控机制来将高reuse的内存请求走我们cache access线路,低reuse的内存请求走我们L1bypass线路
GPU缓存效率分析
作者的分析手段是用不同的应用(可以看成不同的benchmark),比如Particular Filter(PTF),HotSpot(HS),B+ Tree(BT),然后对应不同的数量的input,再指定类型比如,CNF(cache Not friendly),CI(Cache insensitive),CF(cache friendly),如下图
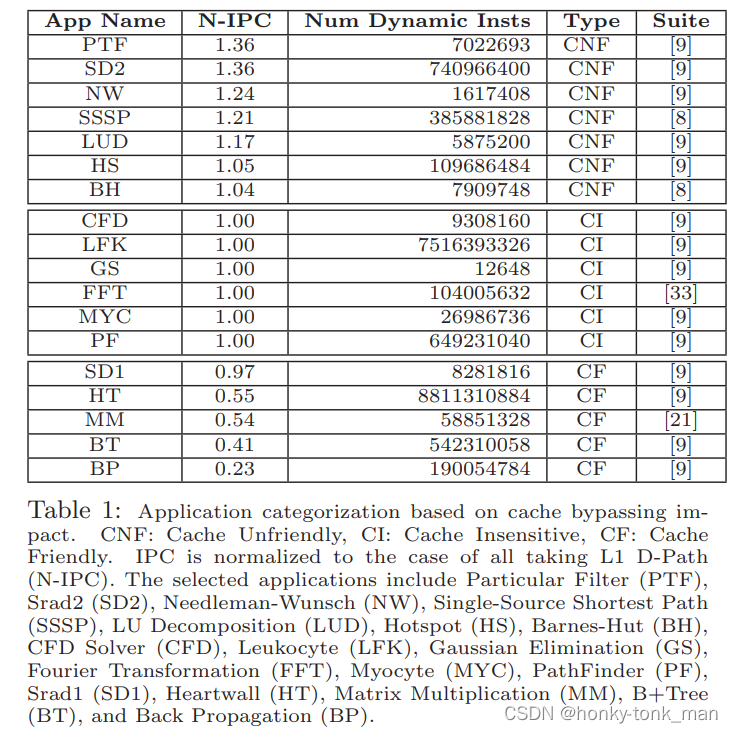
这些benchmark来自GPGPU-sim,CUDA SDK,AMD SDK等等,
作者使用这些benchmark评估他自己的方法有多少提升不是用的运行时间差,而是用N-IPC(normalized instruction pre cycle)
我们通过上图的第二列(先看CNF也就是cahce not friendly)的部分N-IPC会逐步下降更具不同的benchmark(这些benchmark都是cache not friendly的),表明我们寻常的方法会在cache unfriendly下影响性能
在第二部分(CI也就是cache insensitive)的第二列N-IPC在不同的benchmark之间性能几乎没变,说明之前的cache access方法对CI类型的benchmark几乎没有影响
第三部分(CF也就是cache friendly)的第二列N-IPC在不同的benchmark中性能急剧下降,说明之前的cache access对性能的影响极大!
像是英伟达的Fermi架构就是典型的cache access 架构,而kepler架构对于global memory的访问将会bypass L1 cache只有处理register spills(寄存器溢出)到local memory的时候才会使用L1 cache
寄存器溢出(register spills),首先我们的编译器在编译阶段会将一些本地自动变量(就是一个block中的局部变量)或者本地表达式的结果放到处理器的寄存器中,假如寄存器不够用就用local memory(CPU中是用主存)存储这些数据,而在英伟达kepler架构,发生寄存器溢出就把溢出的数据放到L1cache中
典型的L1-Dcahce内竞争发生在以下3个场景
- warp内竞争之cache miss:L1cache是一个SM共享,所以一个warp也能同时访问,fermi和kepler架构通常有16到48KM的一级缓存,有些应用会发生cache pollution,cache 频繁的刷新,导致reuse高但是distance(虽然reuse率高,但是使用间隔长,这样导致缓存被别的数据刷新了)的远
- warp内竞争之Conflict Miss: 首先我们的cache是2-way或者4way之类的(总直低于32也就是warp内线程的数量),什么是2-way,或者4-way,就是cpu可以多少路并行的访问cache,2-way就是cpu可以允许同时2个线程同时去访问L1 cache,如果32个线程同时发起,那么同时只能允许2个线程下发指令去cahce中取数据(假如cache是two-way),其他的线程就会stall
- 其他的资源拥塞:比如我们上面提到的MSHR数量满了,那么我们的指令如果cache miss且需要创建MSHR(此cache block之前没有发生MSHR,或者目前该指令是第一个对此数据cache miss的)就会stall住等待,等待其他的指令release MSHR entire
我们列出了上述的缺点后我们怎么优化呢?
最直观的我们增加了路数(way),增加了L1 & L2缓存的大小,这些操作增加了我们的延迟,增加了功率消耗,增加了我们显卡大小,现如今这种优化并不能很好的支持,作者做了关于这种优化后CNF类benchmark的对比,最后发现性能的瓶颈不再L2缓存上,并且L1缓存增加后对性能的提升也有限
现如今最先经的(2015年)的bypass策略叫做PDP(protection distance prediction)用于CPU的LLC上,其基本的策略是为每一个cache line分配一个叫做PD(protection distance) counter的东西记录每一次访问,假如某个cache line的PD为0则这个cache line被标记成unprotection,假如没有一个cache line是unprotection的那么我们就bypass,但是有个问题,我们的warp除了cache miss,还有resource竞争,conflict miss等问题,因为hit rate 并不能直接关系到GPU的性能(后面会讲到),还有就是我们CF环境下,应用因为已经设计成缓存友好型,我们如果一些不是那么常用的数据占据cache,其他常用的数据岂不是要一直bypass,这在CF环境下还不如不用PDP
我们开始分析,我们那些方面可以影响我们应用的性能
首先L1-Dcache对C1没有太多的影响,这个主要分为以下的几个方面
- CI的一些benchmark LEK,CFD这些workload从global memory去读数据
- MYC和GS这些workload主要将精力放在多分支上,而不是内存访问上
- 一些流的载入就像FFT,这个workload只有在将输入的信号集从global memory载入shared memory的时候才会访问global memory
对于一些CS(cache sensitive)的应用比如CNF和CF
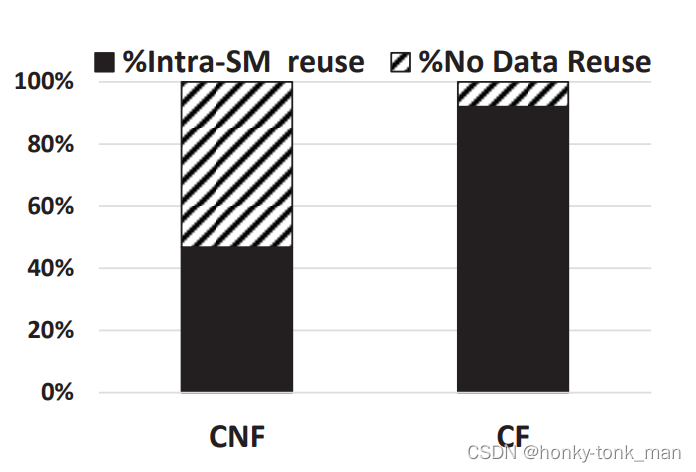
对于CNF,假如我们对NW,PTE,SD2 bypass所有的L1 cache访问那么我们的性能会提升24.2%,36.8%,36.6%分别
因为我们CNF对SM内L2缓存的数据的no data reuse率非常少达到53.2%,而CF对数据no data reuse仅有7.9%,如下如
过滤器的设计
我们更具GPU的架构,我们的过滤器可以放在2个地方
- 首先放在coalescing 单元和L1 D-cache中间,也就是第一张图标1的位子
- 我们还可以将我们的过滤器放在L1 D-cache里面,把我们的过滤器集成在L1 D-cache里面
作者选择的是第二种方法,将过滤器集成在L1D-cache里面,因为可以根据L1 D-cache里面的tags去识别我们的请求,因为它使用的空间小,效率高,所以作者建议解耦L1 D-cache种的tag和data store,并通过较小的硬件扩展将位置过滤能力集成到标签存储中,这样可以管理独立的标签存储,并且可以控制一些内存请求可以在分配data line
decoupled 设计
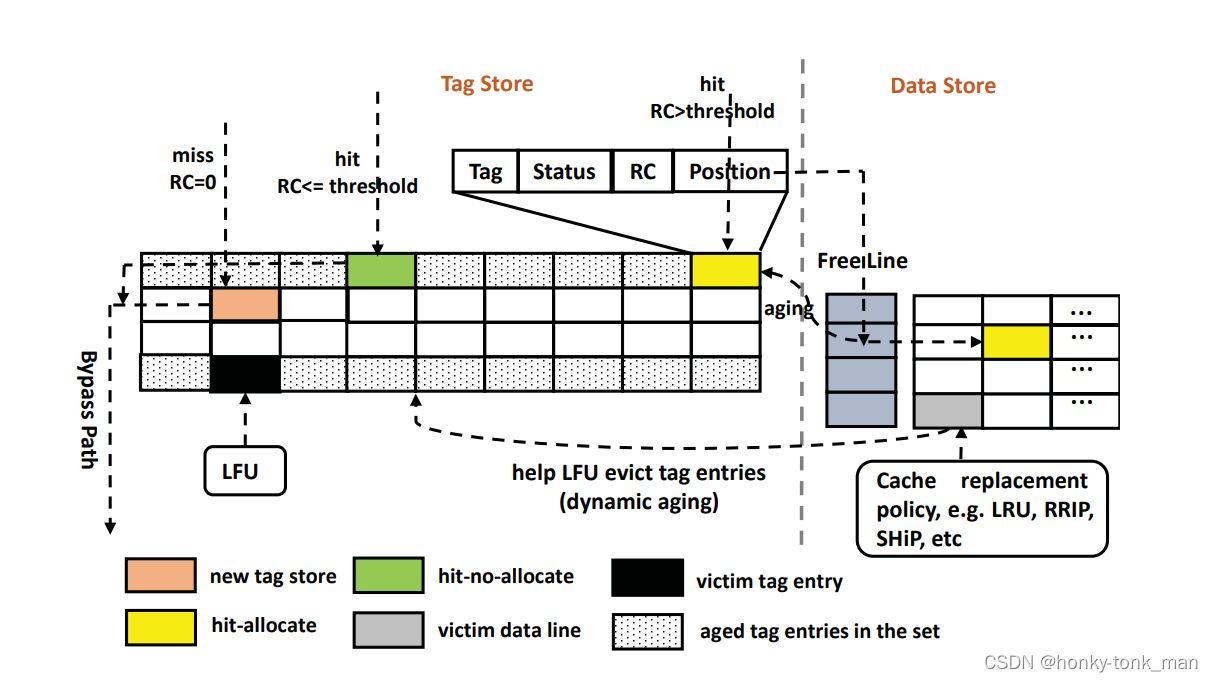
首先我们L1缓存中tag和data结构是分离的,我们设计的decoupled tag store扩展了原有的tag store
原有的tag filed包括address tag,status field,LRU counter filed
我们额外添加的新的tag entire包括reference count(RC),Position field
RC有6bit,其保存reuse的频率(对于这个set的地址来说)
Position field保存的是一个指针指向这个tag对应的data line
Decoupled L1D:operation
初始化,每个tag-store entire和data line都是cleared的(position 位被置为invalid)
假设一个miss发生(通过tag store条目检索),然后一个新的tag entire将会被allocated,然后将会返回bypass 状态,注意bypass状态不会触发cache miss handler,而是直接bypass,不会分配一个新的data store
假设我们miss发生,且tag entire满了,我们就用LFU算法统计tag的RC条目然后驱除victim tag entire
作者对RC field用了动态老化技术(作者自定义的)在以下的几个场景
- 在data store中发生allocate和驱逐操作时对应的tag entire减一
假设我们探测到cache hit(通过探测tag store),这里有2个不同的操作,取决于Position field是否指向分配的data line
假如tag的Position的field指向了一个data store,那么直接cache hit,并且对RC + 1,然后对比局限性阈值,这个阈值是事先基于workload定义的,假如比预先设置的阈值低就不允许插入到L1cache中,如下
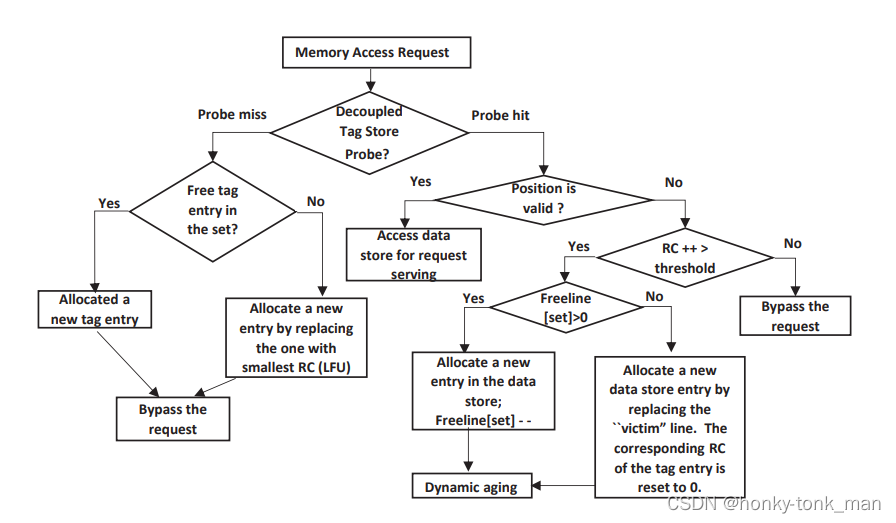
上述的优化方法是对于CNF来说的,我们对于CF应用只需要最大限度用L1 D-cache即可,此时还是我们提出的模型,只需要把RC设置为0即可
最开始会根据tag去探测,假如一个数据A之前没有访问过,tag绝对会没有对应的数据,所以首先探测会miss,然后给他分配一个tag(Position为)如上上图中橙黄色的方块然后走bypass路线,分配后第二次访问数据A先探测tag会探测到(RC++),然测后再看position是否是vaild的假如不是vaild再比较RC是否大于我们设置的阈值,大于就探测free line是否空闲,假如不空闲就驱逐一个,最后把这个空闲的free line对应的数据占为己有
SM Dueling
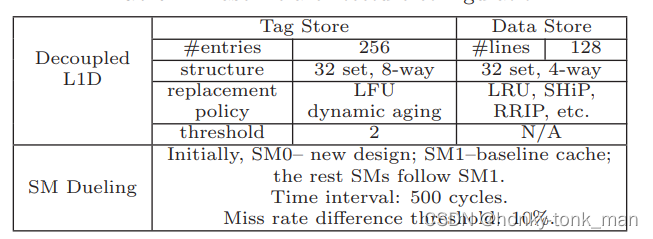
首先作者的设计是针对提升CNF应用的,对于CF应用当然是BL(访问L1 cache)快,因为作者的decouple的RC可能会延迟数据存入L1 D-cache中,所以我们可以disable RCcheck对于CF的benchmark(RC直接设置为0),除此之外作者还设计了一个叫做SM dueling 的技术,假设我们有N个SM,第一个SM可能会执行decouple L1 Dcache,第二个SM就会使用原始的L1 D-cache,然后2个SM会对比cache miss,谁的低就使用那个方法
实验
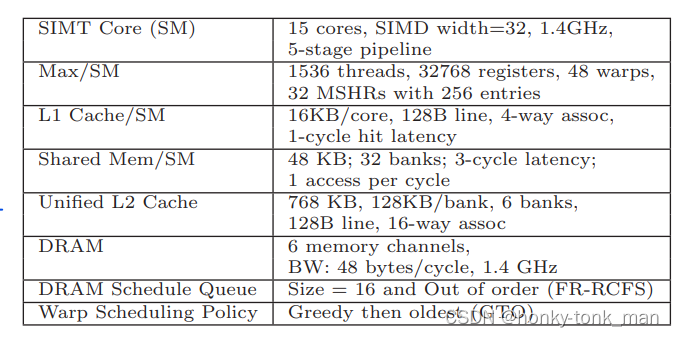
实验环境用的是GPGPU-sim 3.2.2,baseline是基于Fermi 架构,作者的ideal还可以适用于Kepler和Maxwell架构
我们架构配置如下
我们decouple L1 D-cache后如下
我们的benchmark达到18种还是我们之前测试的那些
这些benchmark基本上可以代替所有的应用
性能评估
在评估之前我我们先说明我们用了最新的页面置换算法,(LRU,RRIP)
为了公平的对比,作者用的缓存替换策略用的是LRU,为了对比我们设置了3种架构,分别是Base line(BL),还有BALL(bypass all mem)
BL和BALL配置如下
base line(BL)
base line中所有对global/local mem的访问都会直接插入到L1 Dcache中,假如资源不够用就pipeline stall,当然这个架构对cache friendly非常有用,当然这个也是最常见的架构
bypass all (BALL)
对于所有的global和local mem的访问我们都bypass掉L1 D-cahce,这个是CNF(cache Not friendly)最爱
profiled-bypass
说实话没看懂
MRPB
这个是当时最新的GPU动态bypass应用(2015年),他的基本原理非常简单,当我们出现resource unavailable,这个unavailable也许会让pipelline stall发生,然后memory的request直接bypass L1 D-cache,直到resource变得可用,(这里的resource指的是L1 Dcache的way数,MSHR等资源不够)
当然MRPB维护了memory request reordering queues
PDP-best
这个是最新的CPU bypass approach for LLC
对于上述的一些方法我们制定了以下的一些观察和分析,对比CNF场景
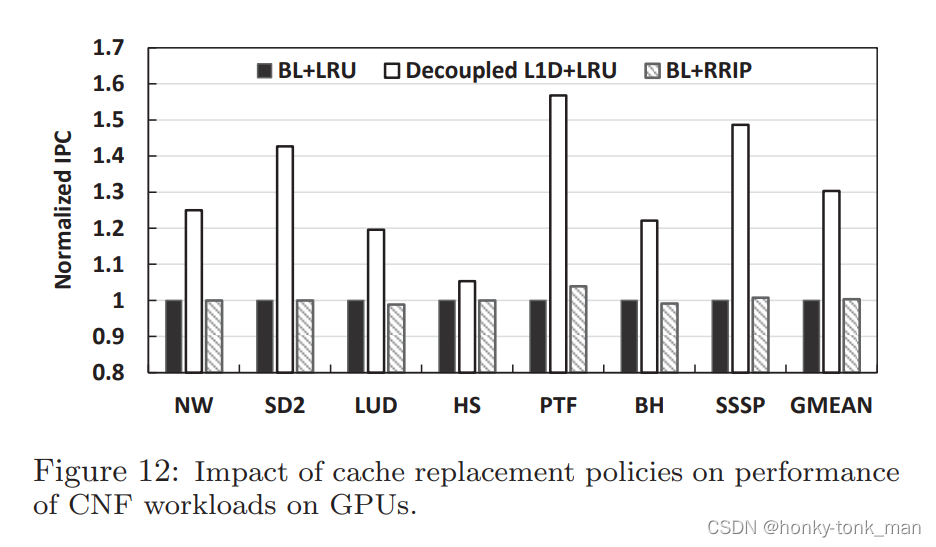
- 对上述的方法在CNF workload上进行对比,最后发现作者设计的Decoupled L1D对比BL(base line所有的访问都通过L1 cache),性能最高提升百分之50多,平均提升30.3%,BALL(all bypass)只引起了非常小的resource stall ,为什么BL会在CNF场景下发生这么大的性能损耗?因为各种资源的竞争,缓存的污染,等等原因导致效率低下
- 在CNF各种benchmark,作者设计的decoupled L1Dcache对比MRPB,效率最高提升了36%,平均提升11%,因为MRPB的大致原理是遇见stall就bypass,几乎没有考虑数据的reuse特性
对比CF和CI场景如下图所示
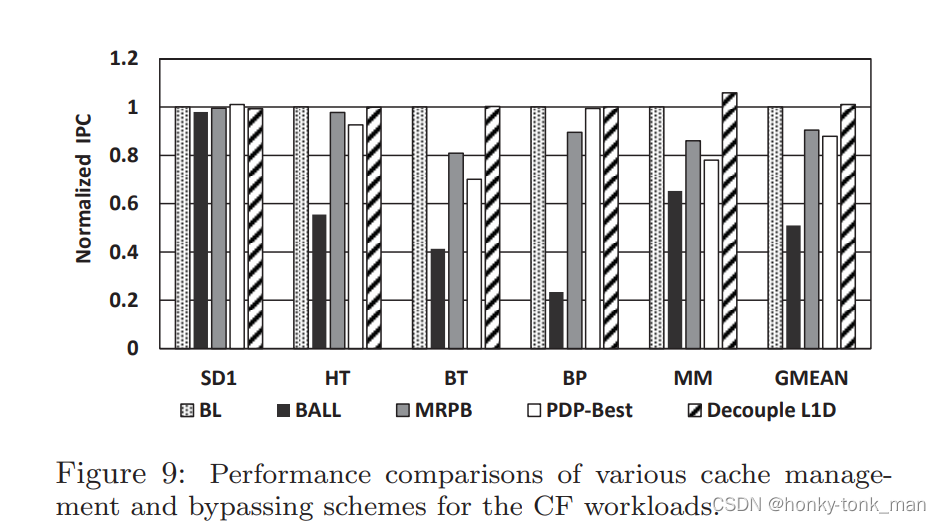
- 如上图所观察BALL,MRPB,PDP-best于BL相比有明显的性能损失,但是我们并没有看到作者的设计有着明显的损失,因为SM Dueling探测的存在
- 在CNF上作者设计的decoupled L1D比BL在缓存命中率上提升了38.5%如下图,再对比PDP-best,在一些benchmark上比如SD2,LUD,SSP,分别提升了71%,24%,13%,这进一步的证明缓存命中率的提高和提高性能的关系不是特别特别大,对性能影响特别大的是减少资源stall,但是MRPB这种方法只提升了17.4%,因为他bypass颗粒度非常大
- CNFworkload的PTF为例子,重用距离长,,重用率低的数据不会insert入L1 D-cache,如上图横坐标表示距离,比如2048代表什么,2048*cache line size = 2048 * 128B = 256kB,也就是说第一个数据和第二个需要用的数据相隔256KB,这么远直接bypass
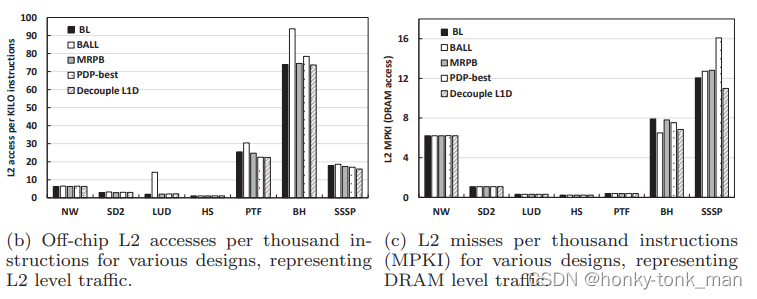
- 在CNF下作者设计的方法decouple-L1Dcache对于L2和DRAM的访问更小,如下图
- 最后作者谈到缓存替换算法对于整个设计的行性能影响,首先一些比较先进的缓存替换算法,比如RRIP,SHiP去缓冲cache冲突,在CPU的LLC中,尽管RRIP和SHiP可以减少缓存冲突,但是遇到long distance reuse也没辙虽然CPU中不是啥问题,但是在GPU中没什么卵用如下图,我们可以看到缓存替换策略对于BL(base line)的影响非常小,因为GPU的L1cache非常的小,long reuse distance会驱逐有用的数据,所以相比较缓存替换策略我们bypass策略更为的重要在新能提升方面