简介:从数据中寻找真正有价值的信息叫数据分析,而这个jupyter nootbook正是数据分析的工具
一、Series和DataFrame的创建
Series(一维)的创建:
首先要导入相关包/库
form pandas import Series
创建Series:第一个参数是data用于传值,第二个参数是index(索引),如果没有传入index,会默认0-N递增。
params = Series(data=[ ],index=[ ])
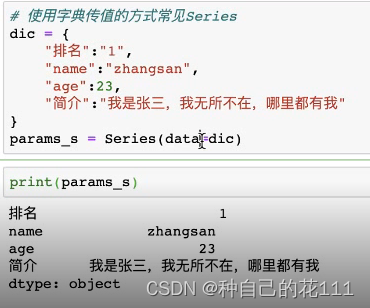
也可以使用一个字典传进去创建一个Series
创建Series例子:
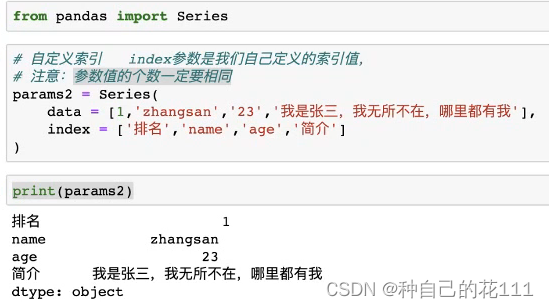
使用字典传值:
DataFrame(二维)的创建:
第一步导包:
from panads import DataFrame,Series
创建DataFrame:有三个参数,data,index(行索引),columns(列索引)
也可以使用字典创建一个DataFranme数据
创建DataFrame:


二、Series和DataFrame的操作
1.Series常用属性:
values:获取数据的值,返回list类型
index:获取索引的值,返回index类型,to_list转换成列表
items:获取每对索引和值,返回zip类型,使用list(series.items())转换成列表
values:

index:
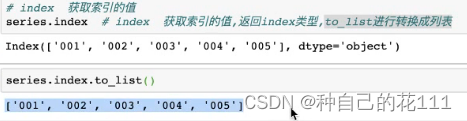
items:

2.Series的取值:
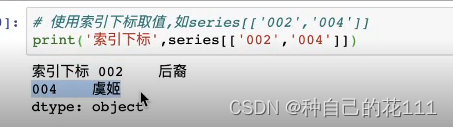
使用索引下标取值,如series[['002';004']]
支持切片取值,如sel['a':'c'],使用切片时,使用单层括号
我们自定义的index值叫索引下标,没有设置index值得时候,会有一个默认的值叫位置索引
下标索引取值:
切片取值:

位置下标:

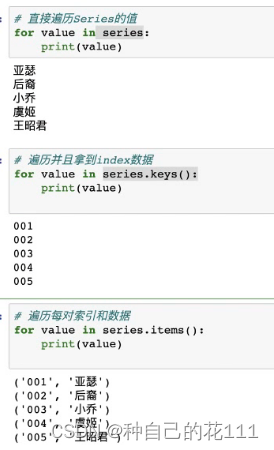
3.Series遍历:
for value in series:遍历直接拿到data数据
for value in series.keys():遍历并拿到index数据
for value in series.items():遍历并拿到每对索引和数据
4.DataFrame属性:
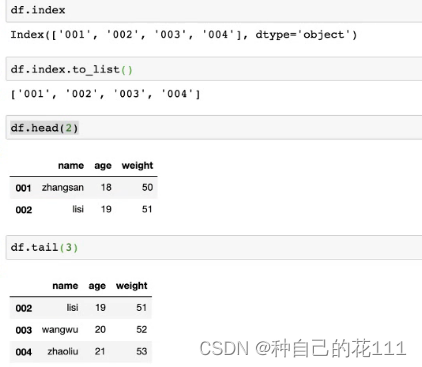
df.index.tolist(),获取行索引列表
df.columns.tolist()),获取列索引列表
df.head(2)获取前两条,tail(2)获取后两条
5.DataFrame的取值:
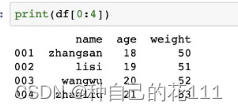
切片获取:多行里面的某几列如: df[1:3][['name','age']]
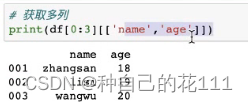
获取多列:df[['name','age']]
行标签索引筛选loc[ ],通过行位置索引筛选iloc[ ]
切片索引:
获取多列:
loc:行在左列在右
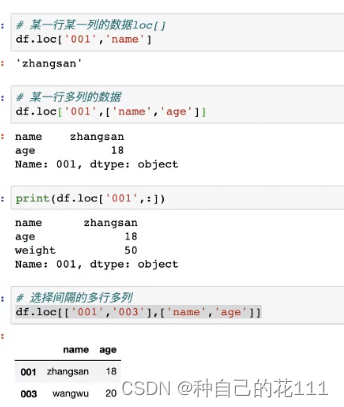
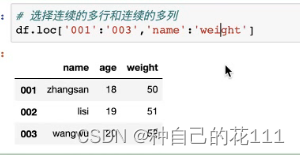
iloc:

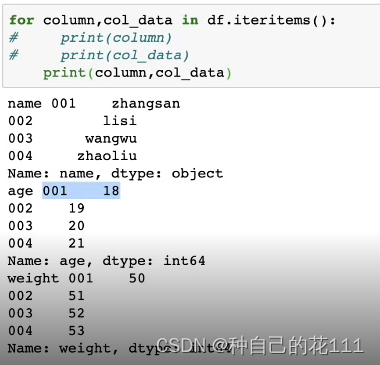
6.DataFrame遍历
iterrows():按行遍历,将DataFrame的每一行转化为(index, Series)对
iteritems():按列遍历,将DataFrame的每一列转化为(column, Series)对
按行:
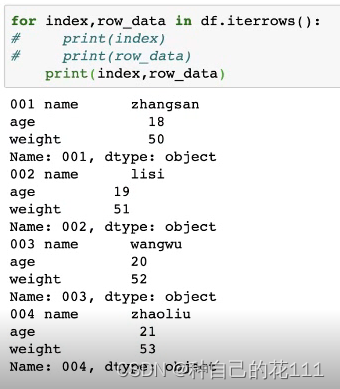
按列:
三、数据的读写
1.数据写入
1.永久性保存,支持的文件格式有HTML、CSV. JSON、Excel
2. to. csv()的path_ or. buf参数:需要指定的文件的本地路径
3. to_ csv()的index参 数:设置为False就可以不存储DataFrame的行索引信息
4. to. csv()的encoding参数:设置"utf 8. sig"后解决文件打开后乱码

2.数据的读取:
1.使用read, csv()、 read_ excel()等方法读取
2. read_ csv()第一个参数填文件的路径
3.默认会将文件中的第一行作为数据的列索引使用header参数设置(指定行位置索引、None)
4.一个Excel文件可以存多个表,一个csv只有一 个表.
5.读取某个表时,使用sheet_name指定(多个表时)

四、数据的操作
1.删除数据:
1. df.drop()删除一行或者一列
2. axis共有0/1两个值,0表示删除行,1表示删除列,默认0
3. inplace:是否在当前df中执行此操作;
True表示在原来数据基础上修改;
False表示返回一个新的值,不修改原有数据

2.空值的处理:
1. df.dropna()只要含有NaN的整行数据删掉
2.参数how='all',删除整行都是空值的数据
3. axis参数,axis=1表示列, axis=0表示行
4.参数thresh=n保留至少有n个非NaN数据的行5.对空值填充,df.dillna(),括号内是要填充的数据,填地df.mean()使用平均值填充
3.删除重复数据:
1. duplicated()检测数据是否为重复的数据行
2.通过DataFrame的duplicated( )去除重复行数据
3. f.drop. duplicates(['A'])只判断某一列数据中是否重复
五、数据的合并,筛选,排序
合并pd.concat()方法:
1. pd.concat()沿一个轴将多个DataFrame对象连接在一起
2. axis参数值: 0表示行,1表示列
3. join参数: outer并 集处理,inner交集 处理4.ignore_index = Ture重新整理一个新的index

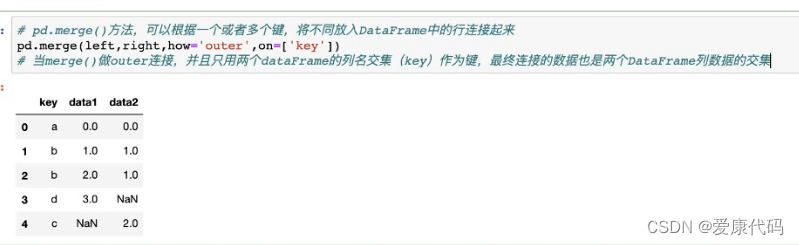
合并merge()方法:
4. merge()函数通过指定连接键拼接列数据
5. how:连接方式,有inner. left. right. outer, 默认为inner
6. on:指的是用于连接的列索引名称
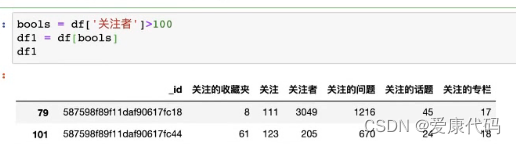
2.数据的筛选:
1. df['列名']> 100,返回每一行是否符合该条件的Bool类型的Series
2. df[bool1 & bool2],如果多个条件可以将判断条件之间使用逻辑运算符
3.数据的排序
1. sort_jindex()是按照行索引进行排序
2. sort_values()可以指定具体列进行排序
3. sort _values的by参数:决定了是按数据中的哪一列进行排序
4. ascending=False:将数据按照从大到小的顺序排列,默认True,升序
5. inplace=True:用来控制是否直接对原始数据进行修改

六、对数据分组
1.数据的分组
1.使用groupby()方法进行分组
2. group.size()查看分组后每组的数量
3. group.groups查看分组情况
4. group.get_ group('F')根据分组后的名字选择分组数据
 对一列数据分组:
对一列数据分组:
![]()
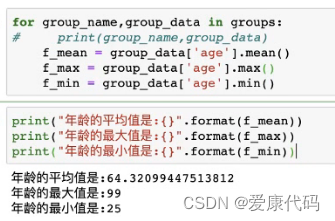
2.对分组进行遍历:
1.使用for..in...可以对分组后的对象进行遍历
2.遍历时可获取到两个对象,分组后的名字和对应组的数据
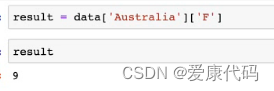
3.按多列进行分组
1.使用groupby()方法进行按多列分组
2.将多个列名放到列表中传给groupby做参数
3.分组后的数据会有多层索引,获取数据需要从外到里逐层获取
获取数据:
4.分组后统计
1. pandas提供了- - 些常用的统计函数
2. agg()聚合函数,传入sum()等系统提供的函数时需要以字符串形势,自定义的传入函数名
