文章目录
文章整理自:
Redis Cluster集群原理+实战+故障切换
一、redis 7.0.0安装
1.redis 7.0.0新特性
-
Redis Functions:Redis函数,一种新的通过服务端脚本扩展Redis的方式,函数与数据本身一起存储。函数还被持久化到AOF文件,并从主文件复制到副本,因此它们与数据本身一样持久,见:https://redis.io/topics/functions-intro;
-
ACL改进:支持基于key的细粒度的权限,允许用户支持多个带有选择器的命令规则集,见:https://redis.io/topics/acl#key-permissions 和https://redis.io/topics/acl#selectors;
-
sharded-pubsub:分片发布/订阅支持,之前消息会在整个集群中广播,而与订阅特定频道/模式无关。发布行为会连接到集群中的所有节点,而不用客户端连接到所有节点都会收到订阅消息。见 https://redis.io/topics/pubsub#sharded-pubsub
-
在大多数情况下把子命令当作一类命令处理(Treat subcommands as commands)(影响 ACL类别、INFO 命令统计等)
-
文档更新:提供命令的元数据和文档,文档更完善,见https://redis.io/commands/command-docs 、https://redis.io/topics/command-tips
-
Command key-specs:为客户端定位key参数和读/写目的提供一种更好的方式;
-
多部分 AOF 机制避免了 AOF 重写的开销;
-
集群支持主机名配置,而不仅仅是 IP 地址;
扫描二维码关注公众号,回复: 14724646 查看本文章
-
客户端驱逐策略:改进了对网络缓冲区消耗的内存的管理,并且提供一个选项,当总内存超过限制时,剔除对应的客户端;
-
提供一种断开集群总线连接的机制,来防止不受控制的缓冲区增长;
-
AOF:增加时间戳和对基于时间点恢复的支持;
-
Lua:支持 EVAL 脚本中的函数标志;
-
Lua:支持 Verbatim 和 Big-Number 类型的 RESP3 回复;
-
Lua:可以通过 redis.REDIS_VERSION、redis.REDIS_VERSION_NUM来获取 Redis 版本。
2.redis cluster环境规划
三主三从-节点交叉模型
| IP | 主机名 | 端口号 | 节点 |
|---|---|---|---|
| 192.168.0.203 | redis-1 | 6379 | master |
| 192.168.0.203 | redis-1 | 6702 | slave—>redis-2 |
| 192.168.0.2 | redis-2 | 6379 | master |
| 192.168.0.2 | redis-2 | 6702 | slave—>redis-3 |
| 192.168.0.3 | redis-3 | 6379 | master |
| 192.168.0.3 | redis-3 | 6702 | slave—>redis-1 |
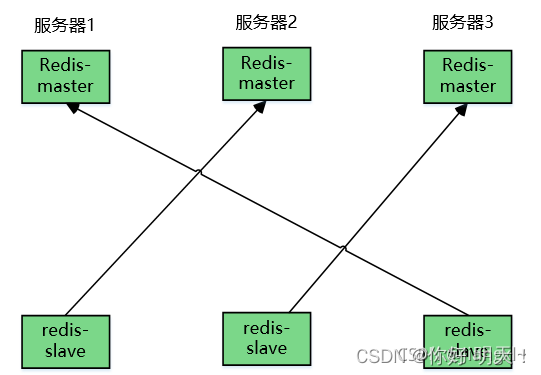
3.redis cluster架构图
Reids集群采用三主三从交叉复制架构,由于服务器数量有限,在一台机器中模拟出集群的效果,在实际生产环境中,需要准备三台机器,每台机器中分别部署两台Redis节点,一主一从,交叉备份。
4. redis官网配置详解:
5 redis6.0以来配置项如下, cluster主要配置带注释的行:
bind 0.0.0.0
protected-mode no #关闭保护模式
port 6379 #端口号
tcp-backlog 511
timeout 0
tcp-keepalive 300
daemonize yes #后台运行
pidfile /data/redis-6.2.6-cluster/var/redis_6379.pid #pid存放
loglevel notice
logfile /data/redis-6.2.6-cluster/logs/redis_6379.log #日志存放路径
databases 16
always-show-logo yes #是否显示总日志
set-proc-title yes
proc-title-template "{title} {listen-addr} {server-mode}"
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename redis_6379.rdb #持久化数据文件名称
rdb-del-sync-files no
dir /data/redis-6.2.6-cluster/data #持久化数据文件存放路径
replica-serve-stale-data yes
replica-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-diskless-load disabled
repl-disable-tcp-nodelay no
replica-priority 100
acllog-max-len 128
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
replica-lazy-flush no
lazyfree-lazy-user-del no
lazyfree-lazy-user-flush no
oom-score-adj no
oom-score-adj-values 0 200 800
disable-thp yes
appendonly no
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
aof-use-rdb-preamble yes
lua-time-limit 5000
cluster-enabled yes #开启集群模式
cluster-config-file nodes_6379.conf #集群模式配置文件名称
cluster-node-timeout 15000 #集群超时时间
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
stream-node-max-bytes 4096
stream-node-max-entries 100
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit replica 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
dynamic-hz yes
aof-rewrite-incremental-fsync yes
rdb-save-incremental-fsync yes
jemalloc-bg-thread yes
二、配置Redis Cluster三主三从交叉复制集群
1.二进制安装Redis程序
redis-1 、redis-2 、redis-3 三台物理机都要做此步骤
1.下载reids
[root@redis-cluster /data/]# wget https://download.redis.io/releases/redis-7.0.0.tar.gz
2.解压并安装redis
[root@redis-cluster /data/]# tar xf redis-7.0.0.tar.gz
[root@redis-cluster /data/]# cd redis-7.0.0
[root@redis-cluster /data/redis-7.0.0]# make
2.redis-1 配置6379,6702实例
1.创建Redis Cluster各集群节点的配置文件存放路径
[root@redis-1 ~]# mkdir -p /data/redis_cluster/redis_{6379,6702}/{conf,data,logs,pid}
[root@redis-1 ~]# ll /data/redis_cluster/
总用量 0
总用量 0
drwxr-xr-x 6 root root 53 10月 19 10:12 redis_6379
drwxr-xr-x 6 root root 53 10月 19 10:12 redis_6702
2.准备两个配置文件一个6379,一个6702
[root@redis-1 ~]# cat > /data/redis_cluster/redis_6379/conf/redis_6379.conf <<EOF
bind $(ifconfig | awk 'NR==2{print $2}')
protected-mode no
port 6379
daemonize yes
logfile /data/redis_cluster/redis_6379/logs/redis_6379.log
pidfile /data/redis_cluster/redis_6379/pid/redis_6379.pid
dbfilename "redis_6379.rdb"
dir /data/redis_cluster/redis_6379/data
cluster-enabled yes
cluster-config-file node_6379.conf
cluster-node-timeout 15000
EOF
3.启动6379
[root@redis-1 ~]# redis-server /data/redis_cluster/redis_6379/conf/redis_6379.conf
3.1关闭6379
[root@redis-1 ~]# redis-cli -c -h 192.168.0.203 -p 6379 shutdown
4.准备6702配置文件
[root@redis-1 ~]# cat > /data/redis_cluster/redis_6702/conf/redis_6702.conf <<EOF
bind $(ifconfig | awk 'NR==2{print $2}')
protected-mode no
port 6702
daemonize yes
logfile /data/redis_cluster/redis_6702/logs/redis_6702.log
pidfile /data/redis_cluster/redis_6702/pid/redis_6702.pid
dbfilename "redis_6702.rdb"
dir /data/redis_cluster/redis_6702/data
cluster-enabled yes
cluster-config-file node_6702.conf
cluster-node-timeout 15000
EOF
5.启动6702
[root@redis-1 ~]# redis-server /data/redis_cluster/redis_6702/conf/redis_6702.conf
6.查看redis进程状态
[root@localhost bin]# ps -ef |grep redis
root 300582 1 0 01:46 ? 00:00:00 redis-server 192.168.0.203:6702 [cluster]
root 305302 1 0 01:49 ? 00:00:00 redis-server 192.168.0.203:6379 [cluster]
root 305402 254887 0 01:49 pts/3 00:00:00 grep --color=auto redis
3.redis-2 配置6379,6702实例
配置同上
4.redis-3 配置6379,6702实例
配置同上
5.配置集群节点相互发现
5.1.相互发现概念
cluster集群互相发现只需要在一个节点上配置,所有节点都会接收到配置信息并自动加入到配置文件中
只要在集群的任意一个节点配置,集群的所有节点都会自动添加配置:
即:redis-1的6379与redis-1的6702、redis-2的6702/6379、redis-3的6702/6379进行一次连接配置即可
5.2.redis-1/2/3开放通讯端口
否则:集群meet连接不上
firewall-cmd --add-port=6379/tcp --permanent --zone=public
firewall-cmd --add-port=6702/tcp --permanent --zone=public
firewall-cmd --add-port=16379/tcp --permanent --zone=public
firewall-cmd --add-port=16702/tcp --permanent --zone=public
firewall-cmd --reload
5.3.所有节点进行互相发现
# 1.配置互相发现
[root@localhost ~]# redis-cli -h 192.168.0.203 -p 6379
192.168.0.203:6379> CLUSTER MEET 192.168.0.203 6379
OK
192.168.0.203:6379> CLUSTER MEET 192.168.0.2 6379
OK
192.168.0.203:6379> CLUSTER MEET 192.168.0.2 6702
OK
192.168.0.203:6379> CLUSTER MEET 192.168.0.3 6379
OK
192.168.0.203:6379> CLUSTER MEET 192.168.0.3 6702
OK
# 2.查看配置文件是否增加,所有节点的配置文件都会生成
[root@localhost logs]# cat /data/redis_cluster/redis_6379/data/node_6379.conf
adf30f1f313782ca3428dee7430e23ce4f09a172 192.168.0.2:6702@16702 master - 0 1666266863238 0 connected
640b815137a4816b33ecd348408ed9b3ffc62bdd 192.168.0.3:6702@16702 master - 0 1666266861326 4 connected
9007f10fb9063f86d3868e21caeb5f5ec1a15eff 192.168.0.2:6379@16379 master - 0 1666266859716 2 connected
34f09b708af07231a5778c92d565b64fcc086d81 192.168.0.3:6379@16379 master - 0 1666266862733 3 connected
6fe539c672877bd8aa33e2ab8f949b0e63842446 192.168.0.203:6702@16702 master - 0 1666266861728 1 connected
a6774ac96b79df344f03f6db2fde386257e0760e 192.168.0.203:6379@16379 myself,master - 0 1666266857000 5 connected
vars currentEpoch 5 lastVoteEpoch 0
6.cluster集群分配操作
6.1.redis cluster通讯流程
集群内消息传递是同步的
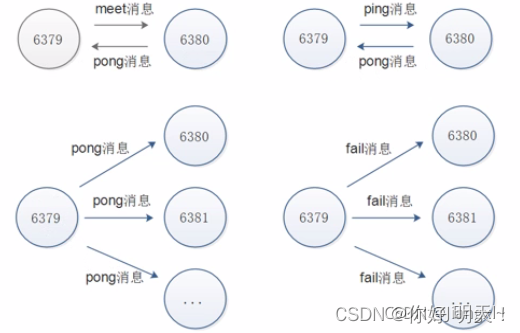
在分布式存储中需要提供维护节点元数据信息的机制,所谓元数据是指:节点负责哪些数据,是否出现故障灯状态信息,redis集群采用gossip协议,gossip协议工作原理就是节点彼此不断交换信息,一段时间后所有的节点偶会指定集群完整信息,这种方式类似于流言传播,因此只需要在一台节点配置集群信息所有节点都能收到信息
通信过程:
1.集群中的每一个节点都会单独开辟一个tcp通道用于节点之间彼此通信,通信端口在基础端口上增加10000
2.每个节点在固定周期内通过特定规则选择结构节点发送ping消息
3.接收到ping消息的节点用pong作为消息响应,集群中每个节点通过一定规则挑选要通信的节点,每个节点可能知道全部节点的信息,也可能知道部分节点信息,只要这些节点彼此可以正常通信,最终他们就会达成一致的状态,当节点出现故障,新节点加入,主从角色变化等,彼此之间不断发生ping/pong消息,最终达成同步的模板
通讯消息类型:gossip,信息交换,常见的消息分为ping、pong、meet、fail
通讯示意图:
6.2 为cluster集群分配槽位:后才可以使用
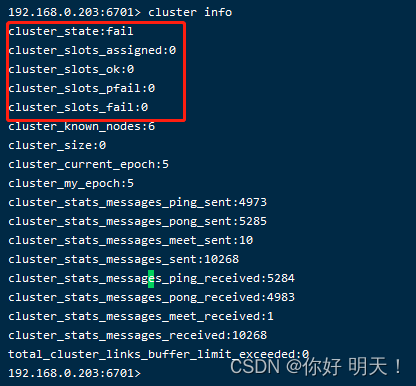
注意:没有分配槽位时集群的状态,所有节点执行cluster info,cluster_state都是fail,fail状态表示集群不可用,没有分配槽位,cluster_slots都会显示0;如下图:
6.3手动配置集群槽位
每个cluster集群都有16384个槽位,我们有三台机器,想要手动分配平均就需要使用16384除3
| 主机 | 槽位范围 |
|---|---|
| redis-1 | 0-5461 |
| redis-2 | 5462-10922 |
| redis-3 | 10923-16383 |
槽位语法:
分配槽位语法格式(交互式):CLUSTER ADDSLOTS 0 5461
分配槽位语法(范围式):redis-cli -h 192.168.81.210 -p 6380 cluster addslots {0…5461}
删除槽位分配语法格式: redis-cli -h 192.168.0.203 -p 6379 cluster delslots {5463…10921}
1.分配槽位
[root@localhost logs]# redis-cli -h 192.168.0.203 -p 6379 cluster addslots {0..5461}
OK
[root@localhost logs]# redis-cli -h 192.168.0.2 -p 6379 cluster addslots {5462..10922}
OK
[root@localhost logs]# redis-cli -h 192.168.0.3 -p 6379 cluster addslots {10923..16383}
OK
2.查看集群状态,到目前为止集群已经是可用的了
[root@localhost logs]# redis-cli -c -h 192.168.0.203 -p 6379 cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:5
cluster_stats_messages_ping_sent:6138
cluster_stats_messages_pong_sent:6459
cluster_stats_messages_meet_sent:10
cluster_stats_messages_sent:12607
cluster_stats_messages_ping_received:6457
cluster_stats_messages_pong_received:6148
cluster_stats_messages_meet_received:2
cluster_stats_messages_received:12607
total_cluster_links_buffer_limit_exceeded:0
3.查看节点槽位
[root@localhost logs]# redis-cli -c -h 192.168.0.203 -p 6379 cluster nodes
adf30f1f313782ca3428dee7430e23ce4f09a172 192.168.0.2:6702@16702 master - 0 1666269025729 0 connected
640b815137a4816b33ecd348408ed9b3ffc62bdd 192.168.0.3:6702@16702 master - 0 1666269026735 4 connected
9007f10fb9063f86d3868e21caeb5f5ec1a15eff 192.168.0.2:6379@16379 master - 0 1666269024723 2 connected 5462-10922
34f09b708af07231a5778c92d565b64fcc086d81 192.168.0.3:6379@16379 master - 0 1666269025000 3 connected 10923-16383
6fe539c672877bd8aa33e2ab8f949b0e63842446 192.168.0.203:6702@16702 master - 0 1666269023717 1 connected
a6774ac96b79df344f03f6db2fde386257e0760e 192.168.0.203:6379@16379 myself,master - 0 1666269022000 5 connected 0-5461
6.4创建key验证集群是否可用
登录方式不同会导致设置值错误:需要以redis-client -c 集群方式登录。
6.4.1 非集群方式登录:部分失败
以redis-cli非集群方式登录时,插入值集群会对key进行hash后,如果不符合本机hash,就会报错,提示去另外的方式去操作,如下图:

6.4.2 集群方式登录:成功
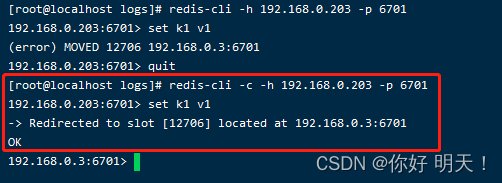
6.4.3 为什么-c能执行成功
ASK路由机制:解决key创建提示去别的主机创建
6.5.验证hash分配是否均匀
1.插入一千条数据,查看三个节点是否分配均已
插入的时候使用-c,自动在某个节点上插入数据
[root@redis-1 ~]# for i in {1..1000}
do
redis-cli -c -h 192.168.0.203 -p 6379 set key_${i} value_${i}
done
[root@localhost ~]# redis-cli -h 192.168.0.2 -p 6379
192.168.0.2:6379> dbsize
(integer) 336
192.168.0.2:6379> quit
[root@localhost ~]# redis-cli -h 192.168.0.3 -p 6379
192.168.0.3:6379> dbsize
(integer) 331
192.168.0.3:6379> quit
[root@localhost ~]# redis-cli -h 192.168.0.203 -p 6379
192.168.0.203:6379> dbsize
(integer) 334
192.168.0.203:6379>
7.配置cluster集群三主三从高可用
7.1步骤:
1.使用cluster replicate将主机的6702redis节点交叉成为别的主机6379节点的从库
2.查看集群状态即可
7.2.将每一个节点都配置rdb持久化
1.将6379添加配置
[root@localhost data]#
echo "
#持久化配置
save 60 10000
save 300 10
save 900 1
" >> /data/redis_cluster/redis_6379/conf/redis_6379.conf
2.检查6379配置是否成功
[root@localhost data]# tail /data/redis_cluster/redis_6379/conf/redis_6379.conf
dir /data/redis_cluster/redis_6379/data
cluster-enabled yes
cluster-config-file node_6379.conf
cluster-node-timeout 15000
#持久化配置
save 60 10000
save 300 10
save 900 1
3.将6702添加配置
[root@localhost data]#
echo "
#持久化配置
save 60 10000
save 300 10
save 900 1
" >> /data/redis_cluster/redis_6702/conf/redis_6702.conf
4.重启6个redis
[root@localhost data]# redis-cli -h 192.168.0.203 -p 6379 shutdown
[root@localhost data]# redis-cli -h 192.168.0.203 -p 6702 shutdown
[root@localhost data]# redis-server /data/redis_cluster/redis_6379/conf/redis_6379.conf
[root@localhost data]# redis-server /data/redis_cluster/redis_6702/conf/redis_6702.conf
7.3配置三主三从
1.查看几个主节点的节点id
[root@localhost data]# redis-cli -c -h 192.168.0.203 -p 6379 cluster nodes |grep 6379 | awk '{print $1,$2}'
9007f10fb9063f86d3868e21caeb5f5ec1a15eff 192.168.0.2:6379@16379 #redis-2
34f09b708af07231a5778c92d565b64fcc086d81 192.168.0.3:6379@16379 #redis-3
a6774ac96b79df344f03f6db2fde386257e0760e 192.168.0.203:6379@16379 #redis-1
2.分别登录到从节点redis-6702,并执行
# redis-1
[root@localhost data]# redis-cli -h 192.168.0.203 -p 6702 CLUSTER REPLICATE 9007f10fb9063f86d3868e21caeb5f5ec1a15eff
# redis-2
[root@localhost data]# redis-cli -h 192.168.0.2 -p 6702 CLUSTER REPLICATE 34f09b708af07231a5778c92d565b64fcc086d81
# redis-3
[root@localhost data]# redis-cli -h 192.168.0.3 -p 6702 CLUSTER REPLICATE a6774ac96b79df344f03f6db2fde386257e0760e
3.查看集群节点
[root@localhost data]# cat /data/redis_cluster/redis_6379/data/node_6379.conf
9007f10fb9063f86d3868e21caeb5f5ec1a15eff 192.168.0.2:6379@16379 master - 0 1666278673000 2 connected 5462-10922
adf30f1f313782ca3428dee7430e23ce4f09a172 192.168.0.2:6702@16702 slave 34f09b708af07231a5778c92d565b64fcc086d81 0 1666278674460 3 connected
640b815137a4816b33ecd348408ed9b3ffc62bdd 192.168.0.3:6702@16702 slave a6774ac96b79df344f03f6db2fde386257e0760e 0 1666278668000 5 connected
34f09b708af07231a5778c92d565b64fcc086d81 192.168.0.3:6379@16379 master - 0 1666278672449 3 connected 10923-16383
6fe539c672877bd8aa33e2ab8f949b0e63842446 192.168.0.203:6702@16702 slave 9007f10fb9063f86d3868e21caeb5f5ec1a15eff 0 1666278673454 2 connected
a6774ac96b79df344f03f6db2fde386257e0760e 192.168.0.203:6379@16379 myself,master - 0 1666278669000 5 connected 0-5461
vars currentEpoch 5 lastVoteEpoch 0
7.4.模拟故障转移
三主三从架构允许最多坏一台主机,模拟将redis-1机器的主库6380挂掉,查看集群间的故障迁移
思路:
1.将redis-1的6379主库关掉,查看集群状态信息是否将slave自动切换为master
2.当master上线后会变成一个节点的从库
3.将master通过cluster failover重新成为主库
7.4.1.模拟坏掉redis-1的主库并验证就能是否可用
1.挂掉redis-1的主库
[root@redis-1 ~]# redis-cli -h 192.168.0.203 -p 6379 shutdown
2.查看集群节点信息
[root@redis-1 ~]# redis-cli -h 192.168.0.203 -p 6702 cluster nodes
如下图: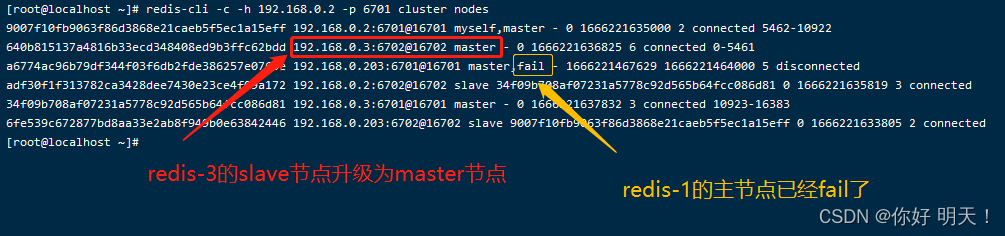
3.查看日志
先是由于主库挂了状态变成fail,当从库变成主库后,状态再次变为ok
[root@redis-1 ~]# tail -f /data/redis_cluster/redis_6379/logs/redis_6379.log
124058:S 03 Feb 13:16:00.233 # Cluster state changed: fail
124058:S 03 Feb 13:17:01.857 # Cluster state changed: ok
4.查看集群状态
[root@localhost ~]# redis-cli -h 192.168.0.2 -p 6379 cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:2
cluster_stats_messages_ping_sent:3905
cluster_stats_messages_pong_sent:3907
cluster_stats_messages_auth-ack_sent:1
cluster_stats_messages_sent:7813
cluster_stats_messages_ping_received:3907
cluster_stats_messages_pong_received:3902
cluster_stats_messages_fail_received:1
cluster_stats_messages_auth-req_received:1
cluster_stats_messages_received:7811
total_cluster_links_buffer_limit_exceeded:0
7.4.2.redis-1节点的主库恢复目前的架构图
redis-1 的6379 实例恢复后变成redis-3的 slave从库
1.启动redis-1的6379主库
[root@redis-1 ~]# redis-server /data/redis_cluster/redis_6379/conf/redis_6379.conf
2.查看集群信息
[root@redis-1 ~]# redis-cli -c -h 192.168.0.2 -p 6379 cluster nodes
如下图:
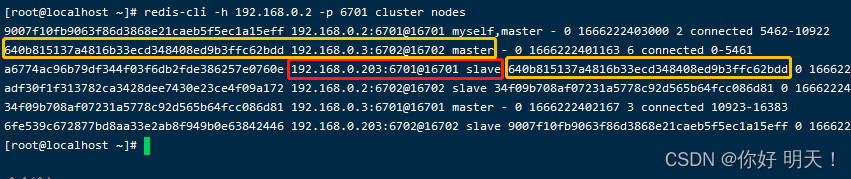
7.4.3.将恢的主库重新变为主库
目前redis-1主库已经重新上线了,现在需要将集群架构恢复成我们设计的模型,不能1台物理机上同时全是master或slave,每次故障处理后一定要把架构修改会原来的样子
cluster falover指令:可变为主库
cluster falover确实也类似于关系互换,简单理解就是原来的从变成了主,现在的主变成了从,这样一来就可以把故障恢复的主机重新变为主库
cluster falover原理:falover原理也就是先执行了slave no one,然后在对应的由主库变为从库的机器上执行了slave of
1.将故障上线的主库重新成为主库
[root@redis-1 ~]# redis-cli -h 192.168.0.203 -p 6379
192.168.0.203:6379> CLUSTER FAILOVER
OK
2.查看集群信息,192.168.0.203的发现6380重新成为了master,192.168.0.3的从库变成了slave
[root@redis-1 ~]# redis-cli -h 192.168.0.203 -p 6702 cluster nodes
如下图:
6702端口已全变为slave

8.redis cluster需要注意的几点
生产环境数据量可能非常大,当主库故障重新上线时,执行CLUSTER FAILOVER会很慢,因为这个就相当于是主从复制切换了,从库(刚上线的原来主库)关闭主从复制,主库(主库坏掉前的从库)同步从库(刚上线的原来主库)数据,然后从库(刚上线的原来主库)重新变为主库,这个时间一定要等,切记,千万不要因为慢在主库上(主库坏掉前的从库)同步手动进行了CLUSTER REPLICATE,这样确实会非常快的将主库(主库坏掉前的从库)重新变为从库,但也意味着这个节点数据全部丢失,因为clusert replicate相当于slaveof,slaveof会把自己的库清掉,这时候从库(刚上线的原来主库)在执行这CLUSTER FAILOVER同步着主库(主库坏掉前的从库)的数据,主库那边执行了replicate去同步从库(刚上线的原来主库),从而导致从库(刚上线的原来主库)还没有同步完主库(主库坏掉前的从库的数据),主库(主库坏掉前的从库)数据就丢失,整个集群还是可以用的,只是这个主库节点和从节点数据全部丢失,其他两个主库从库还能使用。
切记,当从库执行CLUSTER FAILOVER变为主库时,一定不要在主库上执行CLUSTER REPLICATE变为从库,虽然CLUSTER REPLICATE变为从库很快,但是会清空自己的数据去同步主库,这时主库还没有数据,因此就会导致数据全部丢失
CLUSTER FAILOVER:首先执行slave on one变为一个单独的节点,然后在要变成从库的节点上执行slaveof,只要从库执行完slave of,执行CLUSTER FAILOVER的节点就变成了主库
CLUSTER REPLICATE:只是执行了slaveof使自身成为从节点
当redis cluster主从正在同步时,不要执行cluster replicate,当主从复制完在执行,如何看主从是否复制完就要看节点的rdb文件是否是.tmp结尾的,如果是tmp结尾就说明他们正在同步数据,此时不要对集群做切换操作
总结
1.3.0版本以后推出集群功能
2.cluster集群有16384个槽位,误差在2%之间
3.槽位与序号顺序无关,重点是槽的数量
4.通过发现集群,与集群之间实现消息传递
5.配置文件无需手动修改,都是自动生成的
6.分配操作,必须将所有的槽位分配完毕
7.理清复制关系,画图,按照图形执行复制命令
8.当集群状态为ok时,集群才可以正常使用
9.反复测试,批量插入key,验证分配是否均匀
10.测试高可用,关闭任意主节点,集群是否自动转移
11.当主节点修复后,执行主从关系切换
12.做实验尽量贴合生成环境,尽量使用和生成环境一样数量的数据
13.评估和记录同步数据、故障转移完成的时间
14.向领导汇报时要有图、文档、实验环境,随时都可以演示
当应用需要连接redis cluster集群时要将所有节点都写在配置文件中