-
JDBC方式: 就是说通过数据库的jdbc链接来进行quartz的一个配置 Quartz支持了很好的支持
demo用例 使用mysql作为例子进行演示
相比简单配置多出了 :
-
数据库
-
数据库结构 (需要我们手动去初始化一些表格)
-
配置 quartz.properties
-
-
实际上是否使用jdbc模式的quartz 完全取决于 业务 , 当定时任务比较多的时候, 可以选择使用jdbc方式
简单来看这种方式的优点就是我们可以进行一些简单的改造就能达到 动态控制定时任务的效果,缺点就是 他的性能远不如ram方式 毕竟他是建立在jdbc链接上也部分依赖于网络速度
-
make it :
-
mysql 安装
-
导入 初始化数据库.sql文件 的下载
我在官网文档中查看 发现并没有写在文档中
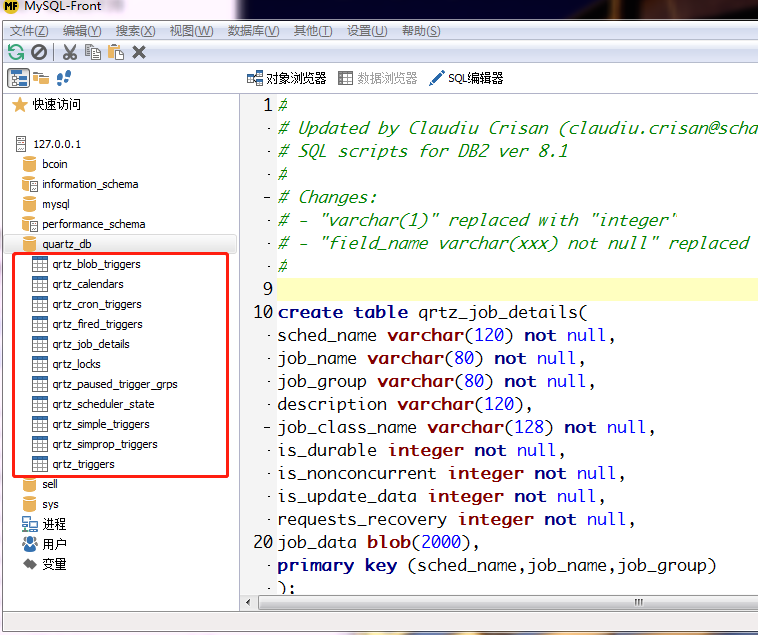
在下载的quartz压缩包中的 .\docs\dbTables 有各种数据库的初始话的.sql文件
压缩包我上传了git: (https://github.com/wunian7yulian/GITHUB_WORKSPACE) 2.23 版本
-
选择 tables_db2_v8.sql 进行导入
-
-
-
为了防止重复 都加了 qrtz作为表名的前缀
-
表实际上在 第一章 5. 中有过相应的介绍
-
-
代码编写
-
第一章 7. 中 介绍了quartz相关的可以更改的配置(quartz.properties ):
//调度标识名 集群中每一个实例都必须使用相同的名称 (区分特定的调度器实例) org.quartz.scheduler.instanceName:DefaultQuartzScheduler //ID设置为自动获取 每一个必须不同 (所有调度器实例中是唯一的) org.quartz.scheduler.instanceId :AUTO //数据保存方式为持久化 org.quartz.jobStore.class :org.quartz.impl.jdbcjobstore.JobStoreTX //表的前缀 org.quartz.jobStore.tablePrefix : QRTZ_ //设置为TRUE不会出现序列化非字符串类到 BLOB 时产生的类版本问题 //org.quartz.jobStore.useProperties : true //加入集群 true 为集群 false不是集群 org.quartz.jobStore.isClustered : false //调度实例失效的检查时间间隔 org.quartz.jobStore.clusterCheckinInterval:20000 //容许的最大作业延长时间 org.quartz.jobStore.misfireThreshold :60000 //ThreadPool 实现的类名 org.quartz.threadPool.class:org.quartz.simpl.SimpleThreadPool //线程数量 org.quartz.threadPool.threadCount : 10 //线程优先级 org.quartz.threadPool.threadPriority : 5(threadPriority 属性的最大值是常量 java.lang.Thread.MAX_PRIORITY,等于10。最小值为常量 java.lang.Thread.MIN_PRIORITY,为1) //自创建父线程 //org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread: true //数据库别名 org.quartz.jobStore.dataSource : qzDS //设置数据源 org.quartz.dataSource.qzDS.driver:com.mysql.jdbc.Driver org.quartz.dataSource.qzDS.URL:jdbc:mysql://localhost:3306/quartz org.quartz.dataSource.qzDS.user:root org.quartz.dataSource.qzDS.password:123456 org.quartz.dataSource.qzDS.maxConnection:10使用jdbc方式需要配置数据源:
#my datasource 配置自己的数据库链接 org.quartz.dataSource.qzDS.driver:com.mysql.jdbc.Driver org.quartz.dataSource.qzDS.URL:jdbc:mysql://localhost:3306/quartz_db org.quartz.dataSource.qzDS.user:root org.quartz.dataSource.qzDS.password:123456 org.quartz.dataSource.qzDS.maxConnection:10
-
先创建job
package com.ws.quartzdemo1001.job02_JDBC_HelloWorld; import com.ws.quartzdemo1001.job01_HelloWorld.HelloJob; import org.quartz.Job; import org.quartz.JobExecutionContext; import org.quartz.JobExecutionException; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.text.SimpleDateFormat; import java.util.Date; public class MyJobForJDBCQuartz implements Job { private static Logger log = LoggerFactory.getLogger(MyJobForJDBCQuartz.class); @Override public void execute(JobExecutionContext context) throws JobExecutionException { log.info("MyJobForJDBCQuartz is start .................."); log.info("Hello JDBC Quartz !!! "+ new SimpleDateFormat("yyyy-MM-dd HH:mm:ss ").format(new Date())); log.info("MyJobForJDBCQuartz is end ....................."); } }
-
编写调度程序
package com.ws.quartzdemo1001.job02_JDBC_HelloWorld; import org.quartz.*; import org.quartz.impl.StdSchedulerFactory; public class QuartzJDBCTest { public static void main(String[] args) throws SchedulerException { // 1 创建 一个jobDetail 实例 JobDetail jobDetail = JobBuilder.newJob(MyJobForJDBCQuartz.class) .withIdentity("jdbcJob_01","jdbcGroup_01") .storeDurably(true) .build(); // 2 创建 简单的调度器 SimpleScheduleBuilder simpleScheduleBuilder = SimpleScheduleBuilder //设置执行次数 .repeatSecondlyForTotalCount(5); // 3 创建 触发器 Trigger Trigger trigger = TriggerBuilder.newTrigger() .withIdentity("jdbcTrigger_01","jdbcTriggerGroup_01") .startNow().withSchedule(simpleScheduleBuilder).build(); // 4 获取 调度器 Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler(); scheduler.start(); // 5 执行 相关调度 scheduler.scheduleJob(jobDetail,trigger); // 6 关闭 调度器 scheduler.shutdown(); } }
运行时发现启动不起来 原来忘了没有数据库的一个驱动 jar 做path 引入:
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.35</version> </dependency>
然后启动 发现 正确执行并打印了5次
其中JobDetail在创建时 : storeDurably(true) 标识任务将会记录在数据库中保存起来
当下次执行时不需要重复创建jobDetail
尝试多次执行: 抛出:
Exception in thread "main" org.quartz.ObjectAlreadyExistsException: Unable to store Job : 'jdbcGroup_01.jdbcJob_01', because one already exists with this identification. at org.quartz.impl.jdbcjobstore.JobStoreSupport.storeJob(JobStoreSupport.java:1108) at org.quartz.impl.jdbcjobstore.JobStoreSupport$2.executeVoid(JobStoreSupport.java:1062) at org.quartz.impl.jdbcjobstore.JobStoreSupport$VoidTransactionCallback.execute(JobStoreSupport.java:3703) at org.quartz.impl.jdbcjobstore.JobStoreSupport$VoidTransactionCallback.execute(JobStoreSupport.java:3701) at org.quartz.impl.jdbcjobstore.JobStoreSupport.executeInNonManagedTXLock(JobStoreSupport.java:3787) at org.quartz.impl.jdbcjobstore.JobStoreTX.executeInLock(JobStoreTX.java:93) at org.quartz.impl.jdbcjobstore.JobStoreSupport.storeJobAndTrigger(JobStoreSupport.java:1058) at org.quartz.core.QuartzScheduler.scheduleJob(QuartzScheduler.java:886) at org.quartz.impl.StdScheduler.scheduleJob(StdScheduler.java:249) at com.ws.quartzdemo1001.job02_JDBC_HelloWorld.QuartzJDBCTest.main(QuartzJDBCTest.java:25) -
当我回去看的时候发现日志里面打印了类如:
14:29:35.085 [QuartzScheduler_DefaultQuartzScheduler-NON_CLUSTERED_MisfireHandler] DEBUG org.quartz.impl.jdbcjobstore.JobStoreTX - MisfireHandler: scanning for misfires... 14:29:35.086 [QuartzScheduler_DefaultQuartzScheduler-NON_CLUSTERED_MisfireHandler] DEBUG org.quartz.impl.jdbcjobstore.JobStoreTX - Found 0 triggers that missed their scheduled fire-time. 14:29:55.106 [DefaultQuartzScheduler_QuartzSchedulerThread] DEBUG org.quartz.core.QuartzSchedulerThread - batch acquisition of 0 triggers这里其实是一个任务进度的扫描 misfires 也是quartz 的一个独有 且完善的一个机制 他保证了我们的所有该执行的任务不会丢失掉
由此看来 quartz的 是一个高度可用 有着非常完美的适用方案的一个调度框架
-
-
五.Demo 其他了解
作为简单demo 我们需要充分了解该demo 适用工作中的业务场景
如:
-
定时发邮件场景
-
耗时任务场景 - 并发
-
集群场景
-
其他需要注意
-
定时发邮件场景
因为我们定时任务的实现类 再编写的时候 只是去实现Job接口 中的 execute() 接口
public void execute(JobExecutionContext context) throws JobExecutionException
而再发邮件业务中 我们需要再任务执行的时候知道 接收方邮件的地址
再execute 的 形参中 我们无法进行自定义处理
当然,我们可以 设置成 再execute 里面查出列表 一个for 循环搞定
但是我们可以考虑一下 如何进行传参 将邮件地址传入进来
JobDataMap quartz 提供了一个map来方便我们业务的书写
-
设置值: (在jobdetail 创建的时候)
job.usingJobData("age", 18) //方法一 加入age属性到JobDataMap job.getJobDataMap().put("name", "quertz"); //方法二 加入属性name到JobDataMap-
取值: (在execute 中)
JobDetail detail = context.getJobDetail(); JobDataMap map = detail.getJobDataMap(); //方法一:获得JobDataMap 然后进行取值
或者
private int age; public void setAge(String age) { //方法二: 声明对应属性的setter 方法 会自动注入 this.age = age; }
对于同一个JobDetail实例,执行的多个Job实例,是共享同样的JobDataMap,也就是说,如果你在任务里修改了里面的值,会对其他Job实例(并发的或者后续的)造成影响,因为JobDataMap 引用的是同一个对象
除了JobDetail,Trigger同样有一个JobDataMap,共享范围是所有使用这个Trigger的Job实例。
-
-
耗时任务场景
Job是有可能并发执行的,比如一个任务要执行10秒中,而调度算法是每秒中触发1次,那么就有可能多个任务被并发执行。
有时候我们并不想任务并发执行,比如这个任务要去”获得数据库中未进行发放红包的用户“,如果是并发执行,就需要一个数据库锁去避免一个数据被多次处理。这个时候一个@DisallowConcurrentExecution解决这个问题。
@DisallowConcurrentExecution public class DoNothingJob implements Job { public void execute(JobExecutionContext context) throws JobExecutionException { System.out.println("do nothing"); } }
注意,@DisallowConcurrentExecution是对JobDetail实例生效,也就是如果你定义两个JobDetail,引用同一个Job类,是可以并发执行的。
-
集群场景
http://www.cnblogs.com/zhenyuyaodidiao/p/4755649.html 参考这位大神文章 如果有用到的机会 看一下
其实各种场景和demo 官方都有提供
集群的的介绍也是在Terracotta收购后更加完善了
-
其他注意点 :(持续补充)
JobExecutionException
Job.execute()方法是不允许抛出除JobExecutionException之外的所有异常的(包括RuntimeException),所以编码的时候,最好是try-catch住所有的Throwable,小心处理。
Durability(持久)
如果一个任务不是durable,那么当没有Trigger关联它的时候,它就会被自动删除。
RequestsRecovery
如果一个任务是"requests recovery",那么当任务运行过程非正常退出时(比如进程崩溃,机器断电,但不包括抛出异常这种情况),Quartz再次启动时,会重新运行一次这个任务实例。
可以通过JobExecutionContext.isRecovering()查询任务是否是被恢复的