摘要
众所周知,现在网页上面的内容。如果遇到优秀的资源和文章,如果不尽快保存下来的话,可能过段时间就被屏蔽或者下架了,那么在这种前提下,如何以较为完整的格式和模板,将所需的内容保存下来,已经成为我们的必修课。
文章给大家提供如何快速保存指定的知乎问答回复的内容。
找到所要提取的指定内容
必须根据指定的回答链接才可以提取,例如下图这种
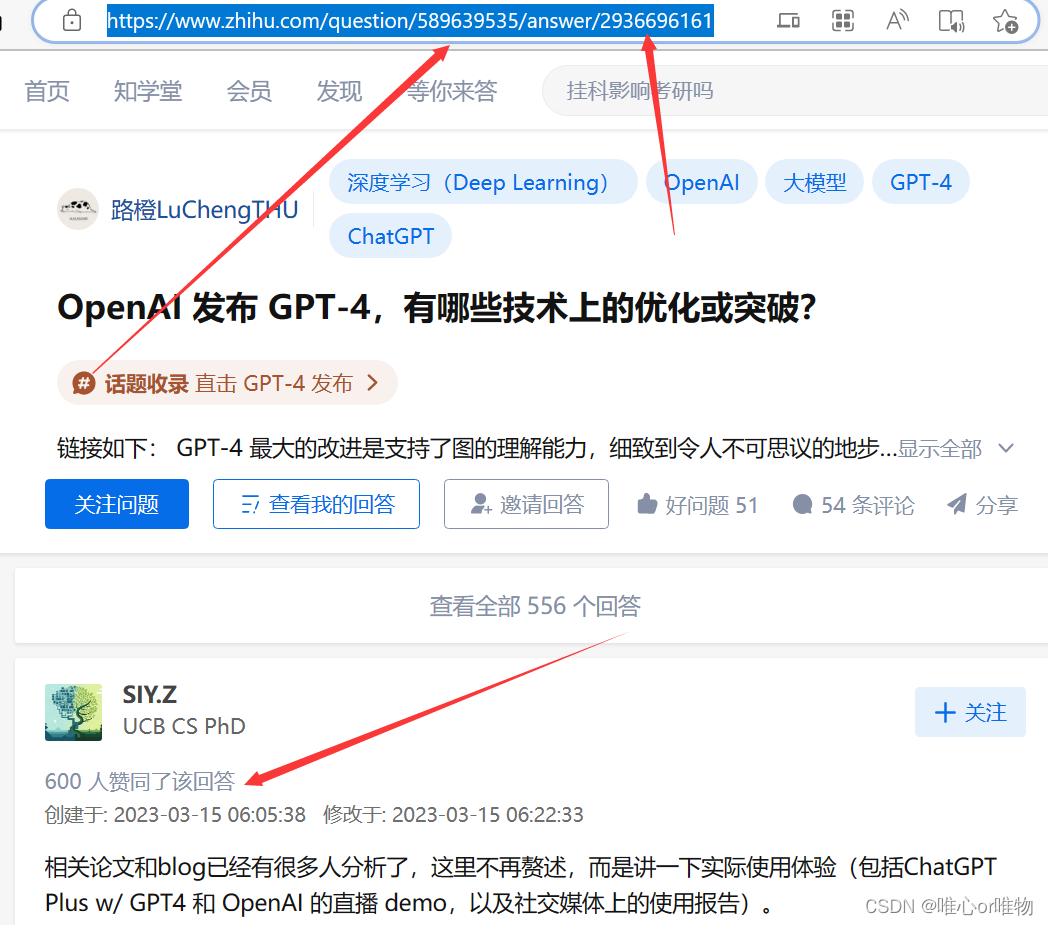
如果是只有问题的链接,没有回答的链接,怎么处理呢?
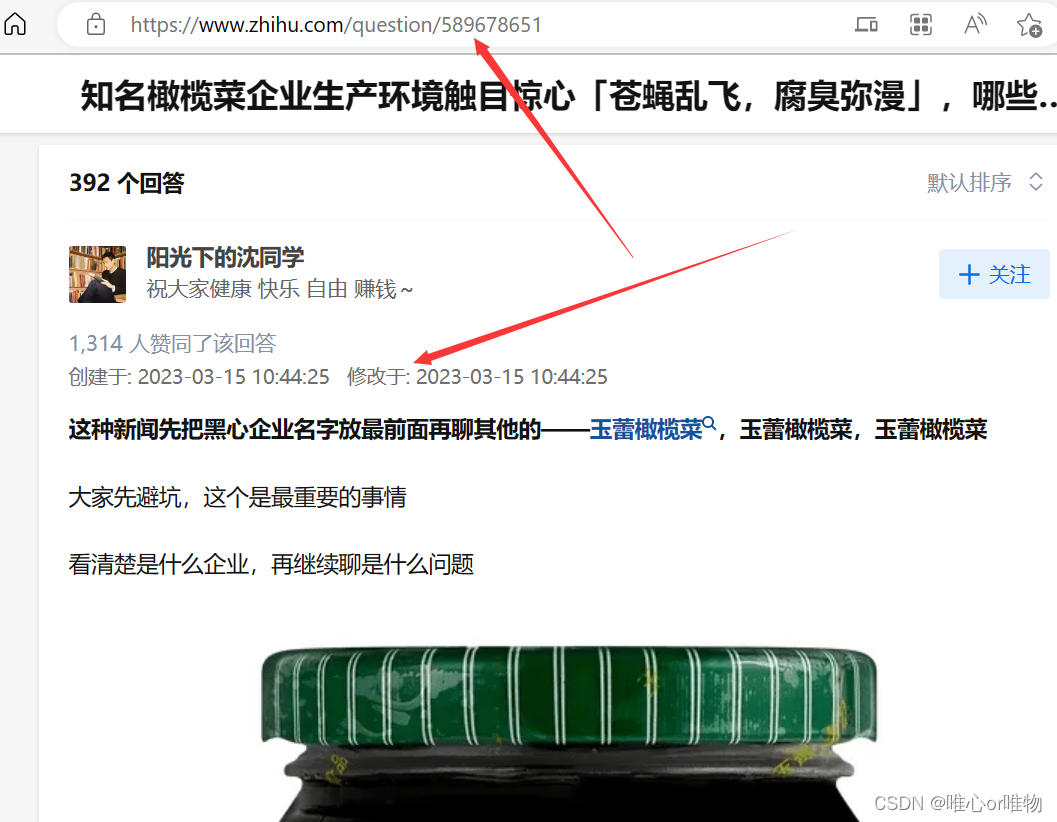
根据你所需要的保存到回答,找到该答主的个人主页,根据回答问题的时间,找到该回答
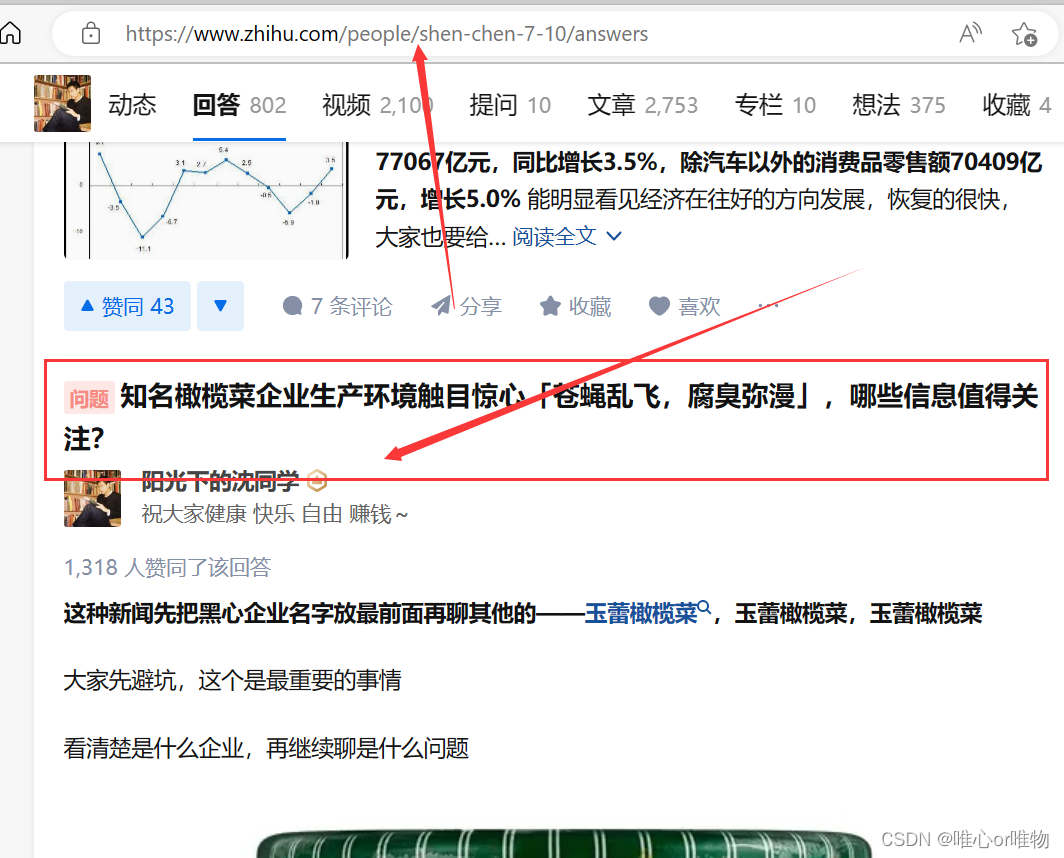
之后点击该问题的标题,即可以跳转到该用户回答的链接地址,即可以进行提取
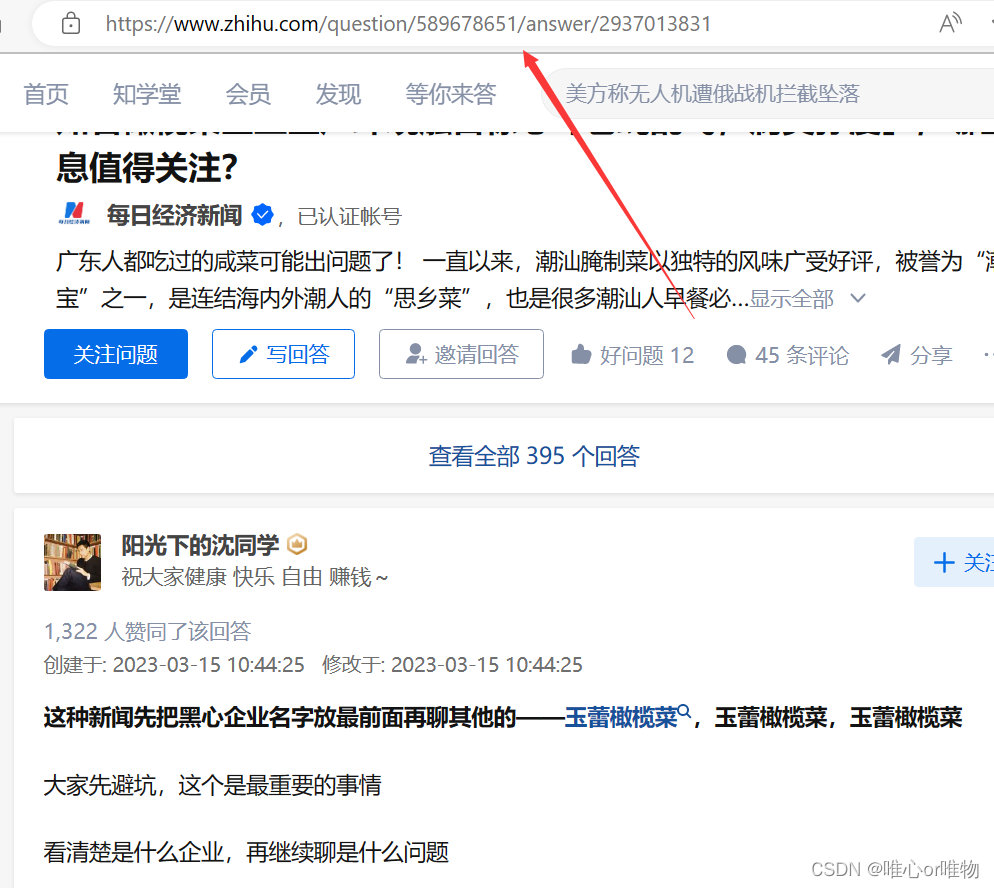
根据链接信息提取文章内容,代码如下:
import os
import requests
from bs4 import BeautifulSoup
import base64
import imghdr
import sys
"""用于爬取知乎上面的指定回答"""
def fetch_url_content(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
return response.text
except Exception as e:
print(f"获取URL内容时发生错误: {url}。错误信息: {e}")
return None
def extract_answer_content(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
answer = soup.find('div', class_='RichContent-inner')
if answer:
return str(answer)
else:
return None
def embed_images_in_base64(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
images = soup.find_all('img')
prev_image_src = None
for img in images:
image_url = None
if 'data-actualsrc' in img.attrs:
image_url = img['data-actualsrc']
elif 'src' in img.attrs:
image_url = img['src']
if not image_url or image_url.startswith('data:image'):
continue
# 如果相邻的图像具有相同的src属性,则删除一个
if prev_image_src == image_url:
img.extract()
continue
response = requests.get(image_url)
response.raise_for_status()
image_data = response.content
image_ext = imghdr.what(None, image_data)
if not image_ext:
print(f'未知的图片格式: {image_url}')
continue
base64_encoded_image = base64.b64encode(image_data).decode('utf-8')
data_uri = f'data:image/{image_ext};base64,{base64_encoded_image}'
img['src'] = data_uri
prev_image_src = image_url
return str(soup)
def save_answer_to_html(answer_content, file_path):
html_template = '''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>知乎答案</title>
<style>
body {
{
font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Helvetica, Arial, sans-serif, 'Apple Color Emoji', 'Segoe UI Emoji', 'Segoe UI Symbol';
font-size: 16px;
line-height: 1.6;
color: #333;
max-width: 800px;
margin: 0 auto;
padding: 20px;
}}
img {
{
max-width: 100%;
height: auto;
}}
</style>
</head>
<body>
{content}
</body>
</html>
'''
with open(file_path, 'w', encoding='utf-8') as f:
f.write(html_template.format(content=answer_content))
def main(save_dir=None):
print("请输入知乎问题/答案的URL:")
zhihu_answer_url = input()
print("请输入输出文件的路径(按Enter默认当前工作路径):")
save_dir = input()
if not save_dir.strip():
save_dir = os.getcwd() # 默认当前工作路径
else:
save_dir = os.path.abspath(save_dir) # 它会将相对路径转换为绝对路径,以便程序可以正确找到文件或目录。
# 无论用户输入相对路径还是绝对路径,程序都能正确地输出HTML文件到指定的位置。
# 将最终下载的内容保存到outputfile文件夹中
save_dir = os.path.join(save_dir, 'outputfile')
# 确保 outputfile 文件夹存在,如果不存在则创建
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 获取答案的HTML内容
html_content = fetch_url_content(zhihu_answer_url)
if not html_content:
print("无法获取答案HTML内容")
return
# 提取答案中的文字和图片
answer_content = extract_answer_content(html_content)
if not answer_content:
print("无法提取答案内容")
return
# 将图片转换为Base64并嵌入到答案内容中
answer_content_with_embedded_images = embed_images_in_base64(answer_content)
# 将答案内容保存为HTML文件
if not os.path.exists(save_dir):
os.makedirs(save_dir)
html_file_path = os.path.join(save_dir, 'answer.html')
save_answer_to_html(answer_content_with_embedded_images, html_file_path)
print(f"答案已保存到: {html_file_path}")
# 下载完成后,并打开
# output_file_path = os.path.join(save_dir, 'answer.html') # 具体可能需要替换
# webbrowser.open(output_file_path)
if __name__ == "__main__":
main()
os.system('pause') # 按任意键继续。
当图片无法加载出来的时候,使用兼容模式ie浏览器
exe文件提取
如果不想运行代码,可以直接使用封装好的exe文件进行处理
链接:https://pan.baidu.com/s/1K6rodH5iXUHdUf_PyB_1mg?pwd=75ec
提取码:75ec