近日,第二届 SSLAD(Self-supervised Learning for Next-Generation Industry-level Autonomous Driving) 2022 Workshop&Challenge 在 ECCV 2022 上举行。
SSLAD workshop 致力于解决目前自动驾驶领域全监督学习模型训练过程中需要大量有标注数据的问题,促进学术界和工业界对自动驾驶算法领域中自监督、弱监督、终身学习方向的研究,尝试利用少量标注数据辅助海量无标注数据来解决当前自动驾驶模型训练的问题。同时 SSLAD 2022 举行了自动驾驶方向的挑战赛,包含 5 个赛道。
旷视研究院获得 track 2 3D 目标检测赛道和 track 5 多任务训练赛道的冠军。这也是旷视研究院连续第二年获得 SSLAD track 2 3D 目标检测赛道的冠军。


Track 2 赛题介绍
在 3D 目标检测赛道,参赛队伍需要基于官方提供的 ONCE 数据集进行训练,利用点云/RGB数据检测场景中的机动车、非机动车和行人,并给出目标精确的中心坐标,空间尺寸和朝向角度。主办方将根据各参赛队伍提交算法的mAPH(Mean Average Precision with Heading )进行排名。
Track 2 夺冠算法介绍
我们使用了 anchor-free 的单阶段目标检测器,由点云预处理(体素化)、3D 特征提取、2D 特征提取和 anchor-free head 四个部分构成。
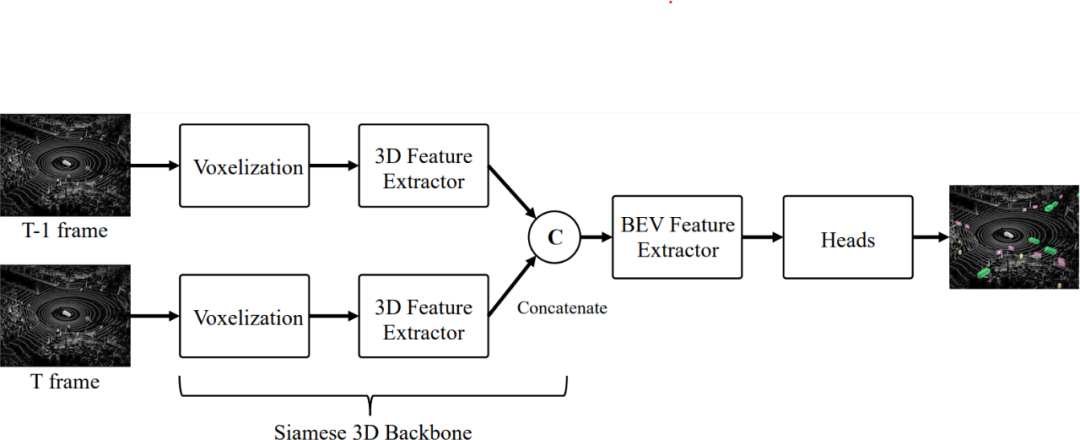
输入模型的点云数据会被分割成众多的体素,随后送入 3D 特征提取的网络。
3D 特征提取网络由稀疏 3D 卷积和稀疏 3D 子流形卷积等堆叠而成,我们在这个基础上加入了 SE 的注意力结构。
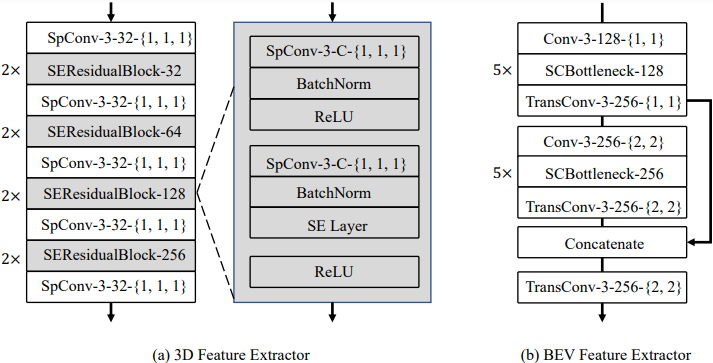
随后特征会被堆叠在 BEV 送入 2D 特征提取网络。在这个模块中,我们设计了上下采样的倍率来尽可能的保留更多的空间信息。这个设计对于提升模型在小目标尤其是行人检测上的性能非常重要。
我们将 ONCE 数据集中的机动车合并为一类,并设计了多种不同划分形式的子任务。每个子任务都有 3 个分支:分类(输出置信度)、回归(输出物体的坐标和空间尺寸等)以及 IoU(预测框和对应目标的重合程度)。
在标签分配上,我们使用了类似 FCOS 的一对多的分配策略,9 个最近的点会被分配为正样本,出现冲突的时候,会使用最近的目标作为最终的标签。
损失函数由分类损失,回归损失和 IoU 预测损失构成。回归损失包含中心点偏移、空间尺寸、角度以及 IoU 回归损失。此外我们还使用了自动权重的方法来平衡多个损失函数。
我们还使用多帧融合的技术,相邻两帧的点云分别经过独立的 3D 特征提取,并在 BEV 下进行堆叠,从而进一步提升模型进行小目标尤其是行人检测的效果。
Track 5 赛题介绍
Track 5 是多任务训练赛道。这个赛道发布了新的多任务标注数据集 AutoScenes。AutoScenes 包含 3,390 帧数据,每帧数据收集了点云与图像数据,并对点云中的3D物体、车道线以及路面分割进行了标注。参赛者需要利用多模态的数据输入,使用单模型同时对 3D目标检测、车道线检测、道路分割等多个任务进行训练,探索多任务训练在自动驾驶领域中降低算力以及挖掘多任务关联数据的能力。本赛道使用 NDS 来评价 3D 目标检测任务,使用 mIOU 来评价车道线检测和路面分割任务,这两项指标的平均分将作为比较各方案的依据。
Track 5 旷视夺冠算法介绍
我们基于 BEVFusion [1] 的基线方法,使用多模态特征相加来聚合多模态特征,使用两阶段的训练策略来训练模型对多任务的感知能力。另外,为了解决 AutoScenes 数据量过小的问题,我们使用 ONCE 数据集开发了预训练模型,基于此在 AutoScenes 数据集上做进一步训练。
从工作流来看,我们的模型首先使用两个 CNN 模块分别处理 lidar 点云输入和图像输入,得到形状一致的 BEV 特征。融合特征通过对这两个模态的特征相加来产生。最后,我们在融合特征上使用检测头执行 3D 目标的预测,使用分割头执行车道线检测和路面分割任务。
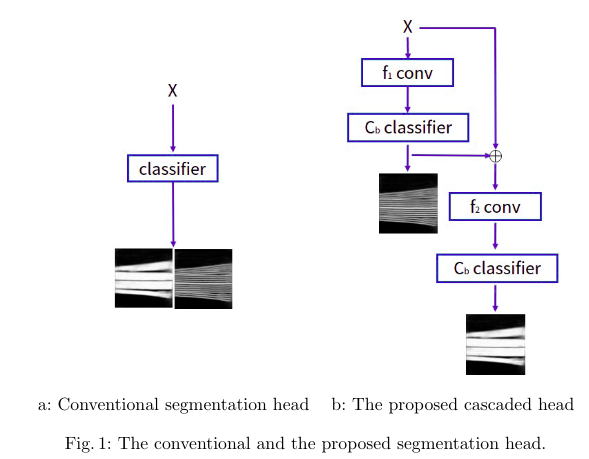
在分割头的设计上,我们使用了级联模块来产生对车道线和可行驶区域的预测(见下图),而不是传统的在通道维度并联的形式。我们发现,当负责预测车道线的特征参与到预测路面分割过程,对应的车道线层可以接收到来自路面分割的监督;相比于传统的预测车道线和可行驶区域的联合分布,这样做能够提升模型在车道线检测任务上的表现。
我们设计了两阶段的训练策略来解决 3D 目标检测和车道线检测/路面分割的多任务联合训练。具体地,第一阶段从 ONCE 预训练模型出发,使用较小的学习率来更新预训练层(包括检测头),使用较大的学习率更新分割头。这一阶段同时做到了训练分割任务和微调 3D 检测任务。在第二阶段,我们使用较小学习率来微调分割任务,同时用更小的学习率来更新检测头,使其避免在分割任务主导更新的特征上坍塌。另外,我们对不同层使用不同的 ema 衰减系数,进一步提升模型的多任务性能。
参考文献
[1]. Liu Z, Tang H, Amini A, et al. BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation[J]. arXiv preprint arXiv:2205.13542, 2022.
实习生招聘
欢迎对视觉感知、融合感知、决策规划、建图定位和跟踪预测算法感兴趣的同学投递简历至:[email protected]。
点击阅读原文了解具体职位要求。
