Batch Normalization
Batch Normalization, 批标准化, 和普通的数据标准化类似, 是将分散的数据统一的一种做法, 也是优化神经网络的一种方法
发现问题
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VSKs9rAb-1651503083980)(C:\Users\pc\AppData\Roaming\Typora\typora-user-images\image-20220209221828190.png)]](https://img-blog.csdnimg.cn/dae41cf539ca457ba2c2cfc04fa6cac9.png)
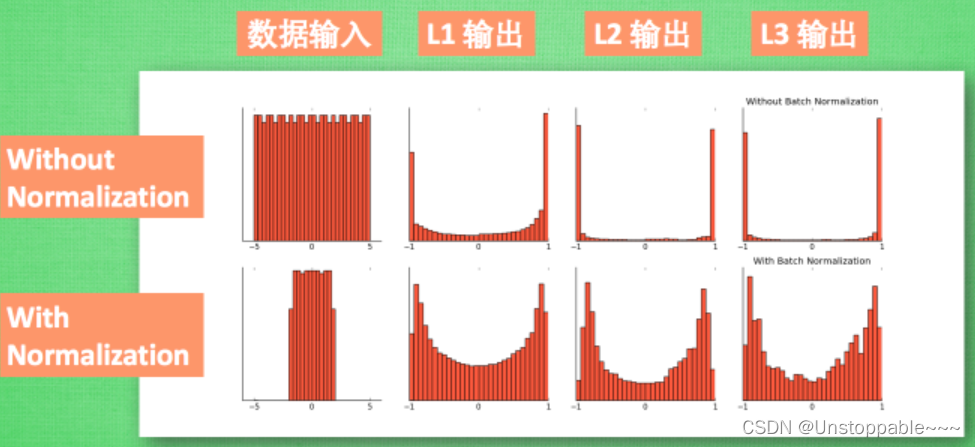
如上图所示,在神经网络中, 数据分布对训练会产生影响. 比如某个神经元 x 的值为1, 某个 Weights 的初始值为 0.1, 这样后一层神经元计算结果就是 Wx = 0.1; 又或者 x = 20, 这样 Wx 的结果就为 2. 现在还不能看出什么问题, 但是, 当我们加上一层激励函数, 激活这个 Wx 值的时候, 问题就来了. 如果使用 像 tanh 的激励函数, Wx 的激活值就变成了 ~0.1 和 ~1, 接近于 1 的部已经处在了 激励函数的饱和阶段, 也就是如果 x 无论再怎么扩大, tanh 激励函数输出值也还是 接近1. 换句话说, 神经网络在初始阶段已经不对那些比较大的 x 特征范围 敏感了.
BN添加位置的探究
Batch normalization 的 batch 是批数据, 把数据分成小批小批进行随机梯度下降(stochastic gradient descent). 而且在每批数据进行前向传递的时候, 对每一层都进行 normalization 的处理(Batch Normalization 就被添加在每一个全连接和激励函数之间.)
我们假设所有的激活函数都是relu,也就是使得负半区的卷积值被抑制,正半区的卷积值被保留。而bn的作用是使得输入值的均值为0,方差为1,也就是说假如relu之前是bn的话,会有接近一半的输入值被抑制,一半的输入值被保留。
所以bn放到relu之前的好处可以这样理解:bn可以防止某一层的激活值全部都被抑制,从而防止从这一层往前传的梯度全都变成0,也就是防止梯度消失。(当然也可以防止梯度爆炸)
BN的效果
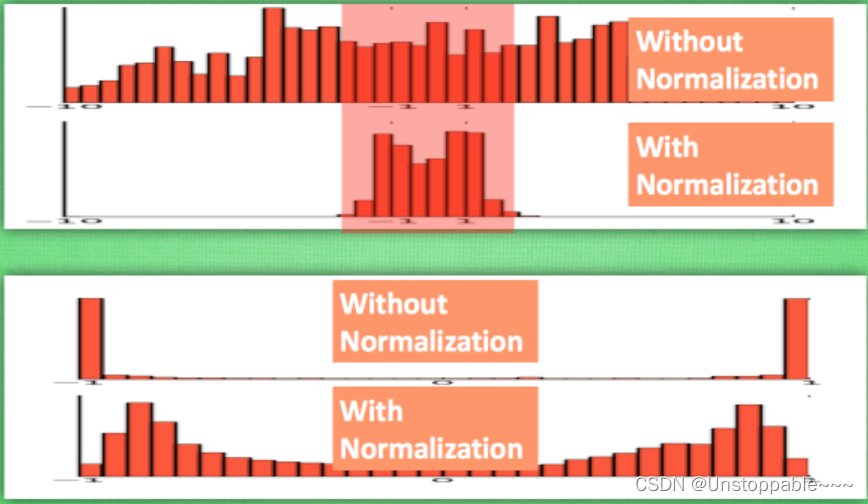
如下图所示,没有 normalize 的数据 使用 tanh 激活以后, 激活值大部分都分布到了饱和阶段, 也就是大部分的激活值不是-1, 就是1, 而 normalize 以后, 大部分的激活值在每个分布区间都还有存在. 再将这个激活后的分布传递到下一层神经网络进行后续计算, 每个区间都有分布的这一种对于神经网络就会更加有价值. Batch normalization 不仅仅 normalize 了一下数据, 还进行了反 normalize 的手续(防止normalize没有用,对normalize的效果进行抵消).
BN算法
如下图所示,我们引入一些 batch normalization 的公式.但是公式的后面还有一个反向操作, 将 normalize 后的数据再扩展和平移. 原来这是为了让神经网络自己去学着使用和修改这个扩展参数 gamma, 和 平移参数 β, 这样神经网络就能自己慢慢琢磨出前面的 normalization 操作到底有没有起到优化的作用, 如果没有起到作用, 我就使用 gamma 和 belt 来抵消一些 normalization 的操作.

流程:
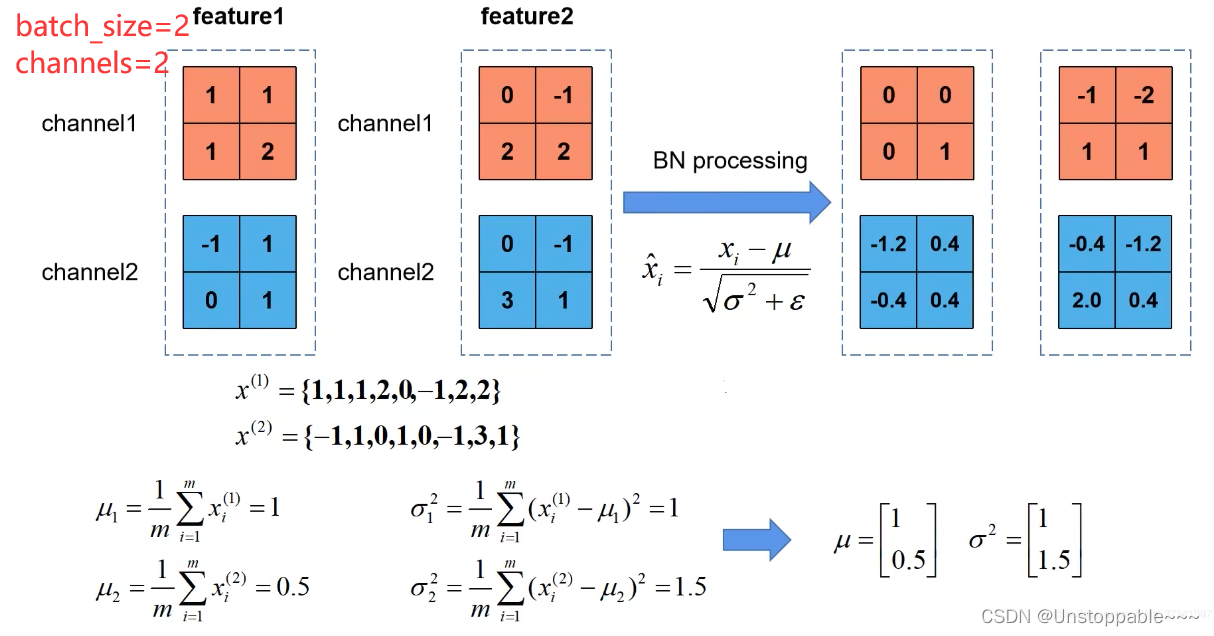
- 首先计算对与每一批次的每个通道的均值μ和方差σ方 (所求到的均为向量,向量的维度为通道的数量,每个通道对应一个结果)
- 其次进行标准化处理,得到均值为0方差为1的数据
- 在进行调整(或者说抵消),γ调整方差,β调整均值(这两个参数通过反向传播学习得到γ初始值为1,β初始值为0)
计算实例:
在使用BN时需要注意
- 训练时将training参数设置为True,验证时将training参数设置为False(使用历史统计的均值和方差,不需要重新计算),在pytorch中可通过model.train()和model.eval()设置
- batch_size尽可能设大一点(过小则表现效果很差),设的越大求得均值和防擦好越接近整个训练集的均值和方差
- BN放在卷积层和激活层(Relu)之间,卷积层不要使用偏置bias
注意:
- μ和σ是在正向传播中统计得到的, γ和β是在反向传播训练中得到的