目录
2-1、HTTP/1.0如何通过请求头和响应头来支持不同类型的数据
一、超文本传输协议 HTTP/0.9
HTTP/0.9,主要用于网络之间传递 HTML,所以被称为超文本传输协议。
它的实现很简单,采用基于请求和响应的模式,客户端发请求,服务器端响应数据。
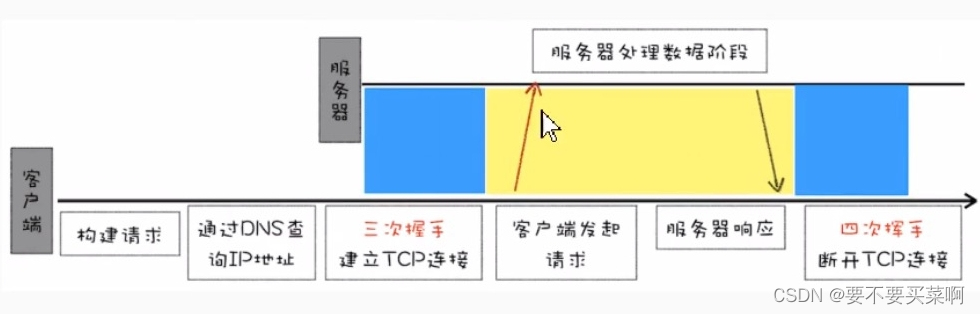
上图是一个HTTP/0.9的一个完整的请求流程。
1、HTTP是基于TCP协议的,客户端基于IP和端口与服务器建立TCP连接,而建立连接的过程就是TCP协议的三次握手的过程。
2、建立TCP连接以后,会发送一个GET请求行的信息,如:
GET /top index.html // 用来获取 index.html
http://47.108.197.28:4000/api/article
// 抓包以下网址,就可以看到请求行3、服务器接收到请求信息之后,读取对应的HTML文件,并将数据以ASCII字符流返回给客户端
4、数据传送完毕,断开连接。
总的来说,当时的需求很简单,就是用来传输体积很小的HTML文件,所以
HTTP/0.9实现有以下三个特点:
1、只有一个请求行,没有HTTP请求头以及请求体和响应头。因为只需要一个请求行,就可以完整表达客户端需求。
2、服务器也没有返回响应头信息,这是因为服务器并不需要告诉服务端什么信息,只需要返回数据。
3、返回的文件内容是以ASCII字符流传输的,因为是HTML格式的,所以使用ASCII字节码来传输最合适。
总结:因为请求的数据类型很简单,所以不需要将请求和响应设计地复杂。
二、被浏览器推动的HTTP/1.0
19941 年,网景公司推出了一款基于拨号上网的浏览器,从此万维网就不局限在学术交流了,进入了高速发展的阶段。HTTP/0.9已经不能适用于当时新兴的网络,因为浏览器展示的已经不是单纯的HTML文件了,还包括JavaScript、CSS、图片、音视频等不同类型的文件。因而,支持多类型文件下载是HTTP/1.0的核心诉求。因为文件的格式不能紧紧局限于ASCII编码,还有很多类型编码的文件。
如何实现多种类型文件的下载?
HTTP/0.9建立连接以后,只会发送类似 GET/index.html 这样简单的请求命令,没有告诉服务器更多的信息。如文件的编码、类型等等。 为了让客户端和服务器但进行更加深入的交流。HTTP/1.0引入了请求头和响应头,他们都以key-value形式保存的,在HTTP发送请求时,会带上请求头信息,服务器返回数据时,会返回响应头信息。

2-1、HTTP/1.0如何通过请求头和响应头来支持不同类型的数据
要支持多种类型的文件,我们就需要解决一下问题:
1、浏览器告诉服务器它需要什么语言版本的界面;
2、浏览器要知道服务器返回的数据是什么类型,然后浏览器才能根据不同类型的数据进行针对性处理。
3、由于万维网所支持的应用变得越来越广,所以单个文件的数据量也越来越大,为了减轻传输性能,服务器会对数据进行压缩后再传输,所以服务器要知道浏览器要知道服务器压缩数据的方式。
4、各种文件的编码形式可能不一样,浏览器需要知道文件的编码类型。
基于以上问题,HTTP/1.0的方案是通过请求头和响应头进行协商,在发起请求时会通过HTTP请求头它期待返回什么类型的文件,采取什么像是压缩,提供什么语言文件以及文件的具体编码。
最终发出来的请求头内容如下:
accept:text/html // 请求的文件类型
accept-encodeing: gzip,deflate // 服务器采用的压缩方式
accept-charset: utf-8 // 文件的编码格式
accept-language:zh-CN,zh // 页面显示的语言 服务器接收到浏览器发送过来的请求头信息以后,会根据请求头信息来响应数据。之后浏览器就根据响应头信息,处理数据。
content-encoding :gzip // 服务器响应数据的压缩格式
content-type:text/html;charset=UTF-8 // 服务器响应的 数据类型 和 编码格式有了响应头,浏览器会使用gzip方式来解压文件,再按照UTF-8的编码格式来处理原始文件,最后使用HTML的方式来解析文件。这就是 HTTP/1.0支持多文件的一个基本流程。
HTTP/1.0除了对多文件提供良好的支持,还依据当时的实际需求引入了很多其他也行,这些特地性都是通过请求头和响应头来实现的。
1、有的请求服务器可能无法处理或者处理出错,这时候就需要告诉浏览器服务器最终处理该请求的情况,这就引入了状态码,状态码通过响应行的方式来通知浏览器的
2、为了减轻服务器的压力,在HTTP/1.0中提供了 Cache 机制,用来缓存已经下载过的数据。
3、服务器需要统计客户端的基础信息,比如windows1和macOS的用户数量分别是多少,所以HTTP/1.0的请求头还加入了用户代理字段。
三、HTTP/1.1
随着需求的迭代,HTTP/1.0已经不能满足用户的需求了,所以HTTP/1.1在HTTP/1.0的基础上做了大量的更新。
1、改进持久连接
HTTP/1.0每进行一次HTTP通信,都需要经历TCP连接,输出HTTP数据,断开TCP三个阶段。
在HTTP/1.0时代,由于通信文件较小,而且每个页面的引用也不多,所以这种传输形式没什么大问题。但是随着浏览器的普及,每个页面的图片文件越来越多,例如像淘宝首页,单个页面就包含看几百个引用的资源文件,如果在下载每个文件的时候,都需要简历TCP连接,断开连接这样的步骤,无疑会增加无谓的开销。
为了解决这个问题,HTTP/1.1中增加了持久化连接的方法,它的特点是在一个TCP连接上可以传输多个HTTP请求,只要浏览器或服务器没有明确断开连接,那么该TCP会一直保持。
HTTP的持久化连接可以有效减少TCP连接的次数,可以减少服务器额外的负担,并提升整体HTTP的请求时长。
持久化连接在HTTP/1.1中是默认开启的( Connection: keep-alive ),如果不需要持久连接,也可以在HTTP请求头加上 Connection:close。目前浏览器对于同一个域名,默认允许同时建立6个TCP持久连接。
2、提供虚拟主机的支持
在HTTP/1.中,每一个域名单独绑定一个唯一的IP地址,因此一个服务器只能支持一个域名,但是随着虚拟主机技术的发展,需要在一个物理机上绑定多个虚拟机,每个虚拟机都有自己单独的域名,这些单独的域名都共用一个IP地址。
3、客户端Cookie、安全机制
四、HTTP/2.0
1、HTTP1.1的主要问题
对贷款的利用不理想,带宽是指每秒能够最大发送或者接收的字节数,每秒能够发送的最大字节数称之为上行带宽,每秒能够接收的最大字节数称之为下行带宽。
之所以说HTTP/1.1对带宽的利用率不理想,比如我们装的100M带宽,实际下载速度能达到12.5M/S,而采用HTTP/1.1时,也许再加载页面资源时最大只能使用 2.5M/s,很难讲12.5M全部用满。
之所以出现这个问题主要是以下三个原因导致的。
1. TCP的慢启动
TCP建立连接之后,就进入发送数据状态,刚开始TCP协议会采用一个非常慢的速度去发送数据,然后慢慢加快发送数据的速度,直到发送数据的速度达到一个理想状态,我们把这个过程称为慢启动。
我们可以把每个TCP发送数据的过程看成是一辆车启动的过程,当刚进入公路时,会有从0到一个稳定速度的提速过程,TCP的慢启动就类似于该过程。
慢启动是TCP为了减少网络拥堵的一种策略,我们是没有办法改变的。
之所以说慢启动会带来性能问题,是页面中的一下关键资源本来就不大,如HTML、CSS、JavaScript文件,通常将这些文件在TCP连接建立好以后就要发起请求的,但是这个过程是慢启动,所以耗费的时间比正常时间多很多,这样就推迟了宝贵的首次渲染的时间。
2、同时开启多条TCP连接,那么这些连接会竞争固定的带宽
当系统同时建立多条TCP连接,当带宽充足时,每条连接发送或接受速度会慢慢向上增加;而一旦带宽不足,这些TCP连接又会减慢发送或者接收的速度。
比如一个页面300个文件,使用了3个CDN,那么加载该网页的时候就需要建立6*3,也就是18个TCP连接来下载资源。在下载资源的过程中,当发现带宽不足时,各个TCP连接就需要动态减慢接收数据的速度。
这样就会出现一个问题,因为有的TCP连接下载的是一些关键资源,如CSS文件,JavaScript文件等,而有的TCP连接下载的是图片,视频等普通的资源文件,但是多条TCP连接之间不能协商让那些关键资源优先下载,这样就有可能影响那些关键资源的下载速度。
3、HTTP/1.1队头阻塞问题
HTTP/1.1中使用持久连接时,虽然能公用一个TCP管道,但是在一个管道中同一时刻只能处理一个请求,当前一个请求没有结束之前,其他的请求只能处于阻塞状态。这意味着,我们不能随意在一个管道中发送请求和接收数据。
这是一个很严重的问题,因为阻塞请求的因素有很多,还有一些不确定的因素,加入一个请求被阻塞5s,那么后续排队的请求都要延迟等待5s,这个等待过程就是对CPU和带宽的白白浪费。
浏览器在处理生成页面的过程中,是非常希望能提前接收到数据的。这样就可以对这些数据做预处理操作,比如提前接收到了图片,那么就可以提前进行编解码操作,等到需要使用该图片的时候,就可以直接给出处理后的数据了,这样能让用户感受到整体速度的提升。
但队头阻塞使得这些数据不能并行请求,所以队头阻塞很不利于浏览器优化。
2、HTTP/2 的多路复用
为了规避TCP慢启动和TCP连接之间的竞争问题。
基于此,HTTP/2的思想就是一个域名只使用一个TCP长连接来传输数据,这样整个页面的下载过程只需要一次慢启动,同时避免了多个TCP连接竞争带宽所带来的问题。
另外一个问题就是队头阻塞的问题,等待请求完成后才能去请求下一个资源,这种方式无疑是最慢的,所以HTTP/2需要实现资源的并行请求,也就是任何时候都可以将请求发送给服务器,而并不需要等待其他请求的完成。服务器也可以随时将处理好的数据返回给浏览器。
所以,HTTP/2的解决方案可以总结为:一个域名只使用一个TCP长连接 消除队头阻塞问题。
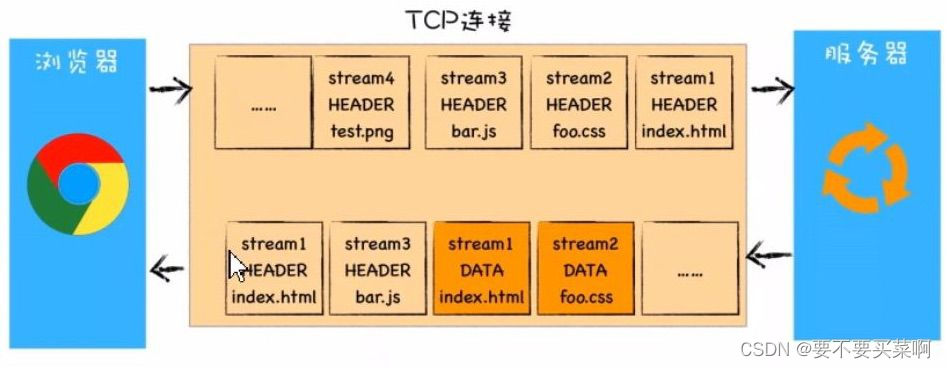
该图就是HTTP/2最核心,最重要的最具颠覆性的就是多路复用机制。从上图可以看到每个请求都有一个 对应的ID,如stream1对应index.html的请求,stream2表 示foo.cs请求。这样在浏览器端,就可以随时将请求发送服务器了。
服务器接收到这些请求后,会根据自己的喜好来决定优先返回那些内容。比如服务器可能早就缓存好了index.html和bar.js的响应头信息,那么当接收到请求时就可以立即把index.html和bar.js的响应头信息返回给浏览器,然后再将index.html和bar.js的响应体数据返回给浏览器。之所以可以随意发送,是因为每份数据都有对应的ID,浏览器接收到之后,会帅选出对应ID的内容,并拼接为完整的HTTP响应数据。
HTTP/2使用了多路复用技术,可以将请求分成一帧一帧的数据去传输,这样带来了一个额外的好处,就是当收到一个优先级高的请求时,比如接收到JavaScript或者CSS关键资源的请求,服务器可以暂停之前的请求来优先处理关键资源的请求。
多路复用的实现
二进制分帧层
1、浏览器准备好请求数据,包括请求行,请求头信息,如果是POST方法,那么还要请求体。
2、这些数据经过二进制分帧层处理后,会被转换为一个个带有请求ID编号的帧,通过协议栈将这些发送给服务器
3、服务器接收到所有帧之后,会将所有相同ID的帧合并为一条完整的请求信息。
4、之后服务器处理该请求,将处理的响应行,响应头和响应体分别发送至二进制分帧层。
5、同样,二进制层会将这些响应数据转换为一个个带有请求ID编号的帧,经过协议栈发送给浏览器。
6、浏览器接收到响应帧之后,会根据ID编号将帧的数据提交给对应的请求。
从以上流程可以看出,通过引入二进制分帧层,就实现了HTTP的多路复用技术。
HTTP/2 的其他特性
多路复用是HTTP/2最核心的功能,它能实现资源的并行传输,多路复用的技术使建立在二进制分帧层的基础之上。基于二进制分帧层,HTTP/2还实现其他很多功能。
1、可以设置的优先级
浏览器中有些数据是非常重要的。但是可能存在以下请求,发送请求时,重要的请求可能会晚于那些不怎么重要的请求,如果服务器按照请求顺序来回复数据,那么那个重要的数据可能会推迟很久才能送达浏览器,这对用用户体验非常不好。
为了解决这个问题,HTTP/2提供了请求优先级,可以在发送数据时,标上该请求的优先级,这样服务器接收到请求之后,会优先处理优先级高的请求。
2、服务器推送
除了设置请求的优先级,HTTP/2还可以直接将数据提前推送给浏览器。想象以下场景,用用户请求一个HTML页面之后,服务器知道该HTML页面会引用几个重要的JavaScript文件和CSS文件,那么在接收到HTML请求之后,附带将要使用的CSS文件和JavaScript文件一并发送给浏览器,这样当浏览器解析完HTML文件之后,就能直接拿到需要的CSS文件和JavaScript文件,这样可以加快页面的打开速度。
3、头部压缩
HTTP/2对请求头和响应头进行了压缩。你可能觉得一个HTTP的头部文件没有多个,压缩不压缩也没关系,但是你可以想一下,在浏览器发送请求的时候,基本上都是发送HTTP请求头,很少发送请求体,通信清晰下也没也有100个左右的资源,如果将这100个请求头的数据压缩为原来的20%,那么传输效率肯定能得到大幅提升。