一、解析过程
本人使用锤子手机做测试,型号是YQ601,首先打开开发者模式确保手机能与mac相连,打开Appium客户端,配置参数如图
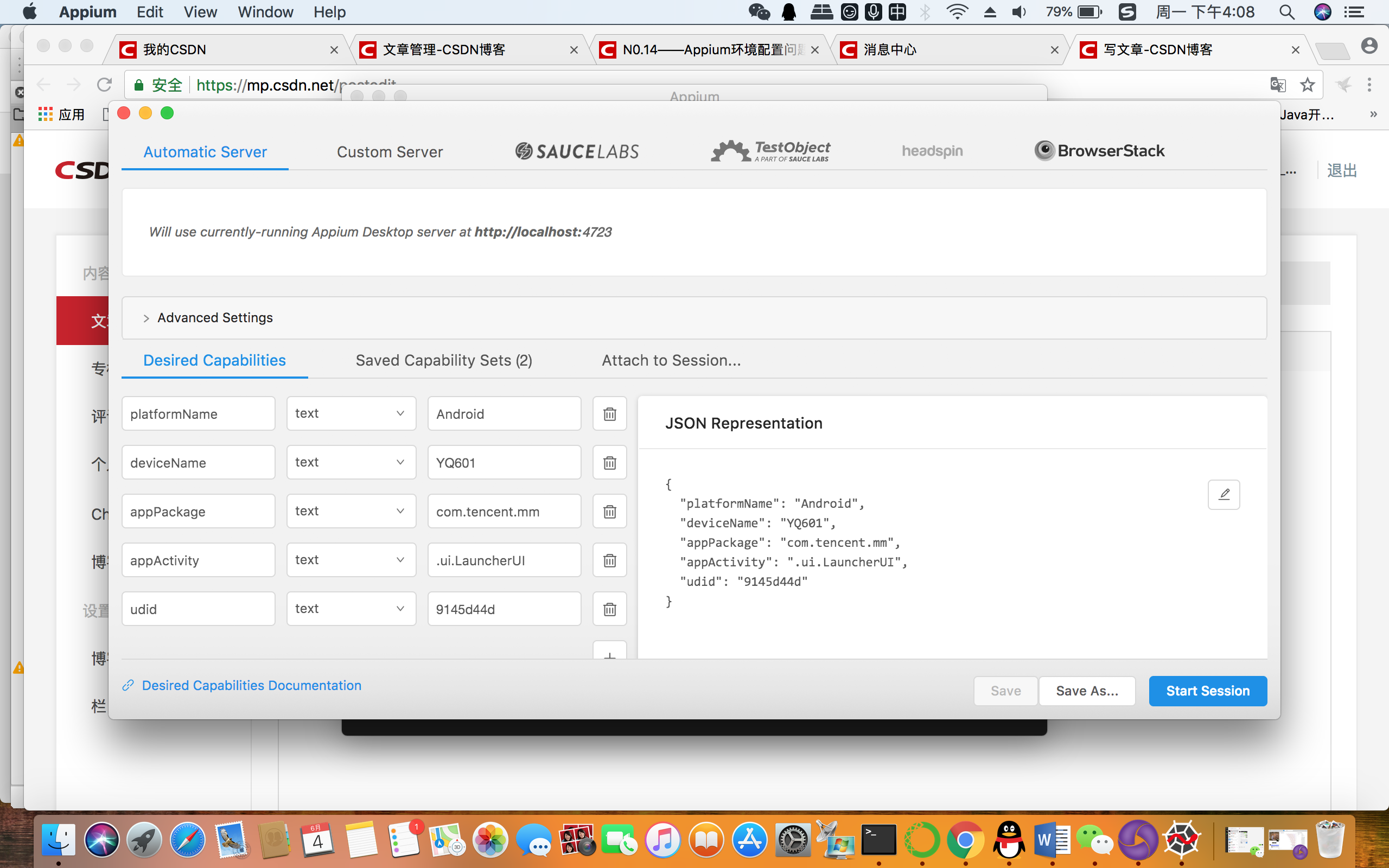
可以理解为Appuim继承自web端的selenium,同样可以执行一些自动化操作。Appium自带了一个XPATH选择器,给用户提供了选择结果,如图
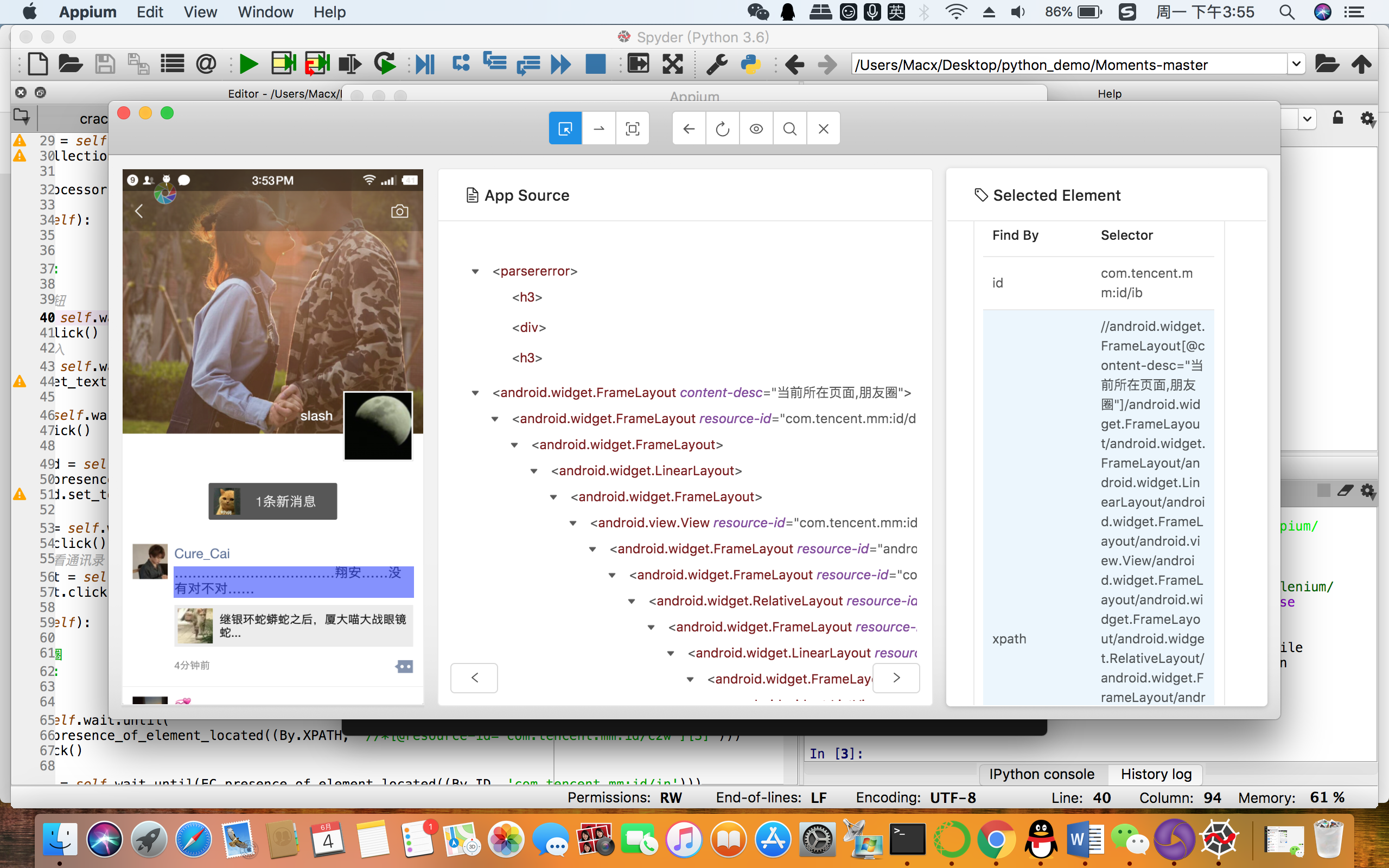
这个选择器给出的结果太繁琐,所以可以改成通过查找ID的方式来构造爬虫程序。但是这里要注意,估计微信提升了自己的反爬能力,在测试时发现,每次重新连接手机,对应特定节点的ID都会发生变化,保险起见,每次重新连接手机,都要对节点ID作更新。
这里把程序分为三部分:(1)模拟登陆(2)进入朋友圈(3)抓取动态(4)存入数据库
二、代码
import os
from appium import webdriver
from appium.webdriver.common.touch_action import TouchAction
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pymongo import MongoClient
from time import sleep
from processor import Processor
from config import *
class Moments():
def __init__(self):
"""
初始化
"""
# 驱动配置
self.desired_caps = {
'platformName': PLATFORM,
'deviceName': DEVICE_NAME,
'appPackage': APP_PACKAGE,
'appActivity': APP_ACTIVITY
}
self.driver = webdriver.Remote(DRIVER_SERVER, self.desired_caps)
self.wait = WebDriverWait(self.driver, TIMEOUT)
self.client = MongoClient(MONGO_URL)
self.db = self.client[MONGO_DB]
self.collection = self.db[MONGO_COLLECTION]
# 处理器
self.processor = Processor()
def login(self):
"""
登录微信
:return:
"""
# 登录按钮
login = self.wait.until(EC.presence_of_element_located((By.ID, 'com.tencent.mm:id/d75')))
login.click()
# 手机输入
phone = self.wait.until(EC.presence_of_element_located((By.ID, 'com.tencent.mm:id/hz')))
phone.set_text(USERNAME)
# 下一步
next = self.wait.until(EC.element_to_be_clickable((By.ID, 'com.tencent.mm:id/alr')))
next.click()
# 密码
password = self.wait.until(
EC.presence_of_element_located((By.XPATH, '//*[@resource-id="com.tencent.mm:id/hz"][1]')))
password.set_text(PASSWORD)
# 提交
submit = self.wait.until(EC.element_to_be_clickable((By.ID, 'com.tencent.mm:id/alr')))
submit.click()
# 是否查看通讯录
yesORnot = self.wait.until(EC.element_to_be_clickable((By.ID, 'com.tencent.mm:id/an2')))
yesORnot.click()
def enter(self):
"""
进入朋友圈
:return:
"""
# 选项卡
tab = self.wait.until(
EC.presence_of_element_located((By.XPATH, '//*[@resource-id="com.tencent.mm:id/b0w"][3]')))
tab.click()
# 朋友圈
moments = self.wait.until(EC.presence_of_element_located((By.ID, 'com.tencent.mm:id/a7f')))
moments.click()
def crawl(self):
"""
爬取
:return:
"""
while True:
# 当前页面显示的所有状态
items = self.wait.until(
EC.presence_of_all_elements_located(
(By.XPATH, '//*[@resource-id="com.tencent.mm:id/d58"]//android.widget.FrameLayout')))
# 上滑
self.driver.swipe(FLICK_START_X, FLICK_START_Y + FLICK_DISTANCE, FLICK_START_X, FLICK_START_Y)
# 遍历每条状态
for item in items:
try:
# 昵称
nickname = item.find_element_by_id('com.tencent.mm:id/as6').get_attribute('text')
# 正文
content = item.find_element_by_id('com.tencent.mm:id/ib').get_attribute('text')
# 日期
date = item.find_element_by_id('com.tencent.mm:id/dfw').get_attribute('text')
# 处理日期
date = self.processor.date(date)
print(nickname, content, date)
data = {
'nickname': nickname,
'content': content,
'date': date,
}
# 插入MongoDB
self.collection.update({'nickname': nickname, 'content': content}, {'$set': data}, True)
sleep(SCROLL_SLEEP_TIME)
except NoSuchElementException:
pass
def main(self):
"""
入口
:return:
"""
# 登录
self.login()
# 进入朋友圈
self.enter()
# 爬取
self.crawl()
if __name__ == '__main__':
moments = Moments()
moments.main()
import time
import re
class Processor():
def date(self, datetime):
"""
处理时间,转化成发布时间的时间戳
:param datetime: 原始时间
:return: 处理后时间
"""
if re.match('\d+分钟前', datetime):
minute = re.match('(\d+)', datetime).group(1)
datetime = time.strftime('%Y-%m-%d', time.localtime(time.time() - float(minute) * 60))
if re.match('\d+小时前', datetime):
hour = re.match('(\d+)', datetime).group(1)
datetime = time.strftime('%Y-%m-%d', time.localtime(time.time() - float(hour) * 60 * 60))
if re.match('昨天', datetime):
datetime = time.strftime('%Y-%m-%d', time.localtime(time.time() - 24 * 60 * 60))
if re.match('\d+天前', datetime):
day = re.match('(\d+)', datetime).group(1)
datetime = time.strftime('%Y-%m-%d', time.localtime(time.time()) - float(day) * 24 * 60 * 60)
return datetime