Monocular BEV Perception with Transformers in Autonomous Driving
A review of academic literature and industry practice as of late 2021
更新时间:
- Add DETR3D, 2021/11/07
- Add STSU, Translating images to maps, 2021/12/27
Mass production-grade autonomous driving requires scalable three-dimensional reasoning of the world. As the autonomous cars and other traffic agents move on the road, most of the time the reasoning does not need to account for height, making Birds-Eye-View (BEV) a sufficient representation.

An extremely simplified architecture of a traditional autonomous driving stack (Image by Author)
The above diagram illustrates a traditional autonomous driving stack (omitting here many aspects such as localization for simplicity). In this diagram, circles represent functional modules and are color-coded by the space they reside in. Green modules happen in 2D, and blue ones happen in BEV. Only camera perception takes place in 2D space, or more precisely, the perspective space where onboard camera images are obtained. It relies on Sensor Fusion with heavily hand-crafted rules to lift 2D detections to 3D, optionally with the help of 3D measurements from radar or lidar.
Here I say traditional for at least two reasons. First, camera perception still happens in perspective space (as opposed to a more recent trend of monocular 3D object detection, a review of which can be found here). Second, results from multimodal sensors are fused in a late-fusion fashion (as opposed to early-fusion where sensor data are fed into neural network for data-driven association and geometric reasoning).
BEV Perception is the future of camera perception
The diagram hints that it would be highly beneficial for the only outlier, camera perception, to move on to BEV. First of all, performing camera perception directly in BEV would make it straightforward to combine with perception results from other modalities such as radar or lidar as they are already represented and consumed in BEV. Perception results in BEV space would also be readily consumable by downstream components such as prediction and planning. Second, it is not scalable to purely rely on hand-crafted rules to lift 2D observations to 3D. The BEV representation lends itself to transition to an early fusion pipeline, making the fusion process completely data-driven. Finally, in a vision-only system (no radar or lidar), it then almost becomes mandatory to perform perception tasks in BEV as no other 3D hints would be available in sensor fusion to perform this view transformation.
Monocular Bird’s-Eye-View Semantic Segmentation for Autonomous Driving
A review of BEV semantic segmentation as of 2020

I wrote a review blog post one year ago in late 2020 summarizing the papers in academia on monocular BEV perception. This field studies how to lift monocular images into BEV space for perception tasks. Since then, I have been updating it with more papers I read to keep that blog post up to date and relevant. The scope of this field has been expanding steadily from semantic segmentation to panoptic segmentation, object detection, and even other downstream tasks such as prediction or planning.
Over the past year, largely three approaches emerged in monocular BEV perception.
- IPM: This is the simple baseline based on the assumption of a flat ground. Cam2BEV is perhaps not the first work to do this but is a fairly recent and relevant work. It uses IPM to perform the feature transformation, and uses CNN to correct the distortion of 3D objects that are not on the 2D road surface.
- Lift-splat: Lift to 3D with monodepth estimation and splat on BEV. This trend is initiated by Lift-Splat-Shoot, and many follow-up works such as BEV-Seg, CaDDN, and FIERY.
- MLP: Use MLP to model the view transformation. This line of work is initiated by VPN, and Fishing Net, and HDMapNet to follow.
- Transformers: Use attention-based transformers to model the view transformation. Or more specifically, cross-attention based transformer module. This trend starts to show initial traction as transformers take the computer vision field by storm since mid-2020 and at least till this moment, as of late-2021.
In this review blog post, I will focus on the last and latest trend — the use of Transformers for view transformation.
Almost ironically, many of the papers in literature, some before and some amid this recent wave of uprising of Transformers in CV, refer to their ad-hoc view transformation module as “view transformers”. This makes the searching in literature even more challenging to identify those who indeed used attention modules for view transformation.
To avoid confusion, in later text of this blog post, I will use capitalized Transformers to refer to the attention-based architecture. That said, the use of Transformers to perform view transformation by lifting images to BEV seems to be a good pun.
View transformation with Transformers
The general architecture of Transformers has been extensively interpreted in many other blogs (such as the famous The Illustrated Transformer), and thus we will not focus on it here. Transformers are more suitable to perform the job of view transformation due to the global attention mechanism. Each position in the target domain has the same distance to access any location in the source domain, overcoming the locally confined receptive fields of convolutional layers in CNN.
Cross-attention vs self-attention

The use of cross-attention and self-attention in Transformers (source)
There are two types of attention mechanisms in Transformers, self-attention in the Encoder and cross-attention in the Decoder. The main difference between them is the query Q. In self-attention, the Q, K, V inputs are the same, whereas in cross-attention Q is in a different domain from that for K and V.
As detailed in my previous blog, the shape of the output of the attention module is the same as the query Q. In this regard, self-attention can be seen as a feature booster in the original feature domain, whereas cross-attention can be viewed as a cross-domain generator.
The idea of cross-attention is actually the original attention mechanism, even before the creation of Transformers. The attention mechanism is first mentioned in the ICLR 2015 paper “Neural Machine Translation by Jointly Learning to Align and Translate”. The more innovative contribution of the original NeurIPS 2017 Transformer paper “Attention is All you Need” is actually replacing the bi-directional RNN encoder with self-attention modules. That is perhaps the reason why many people still prefers the term attention instead of transformers when referring to cross-attention. For a more colorful narration please see here.
Cross-attention is all you need
Many of the recent advances in Transformers in CV actually only leverages the self-attention mechanism, such as the heavily cited ViT (An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR 2021) or Swin Transformer (Hierarchical Vision Transformer using Shifted Windows, Arxiv 2021/03). They act as an enhancement to the backbone feature extractor. However, considering the difficulty in the deployment of the general Transformer architecture in resource-limited embedded systems typical on mass production vehicles, the incremental benefit of self-attention over the well-supported CNN can be hard to justify. Until we see some groundbreaking edge of self-attention over CNN, it would be a wise choice to focus on CNN for industry applications such as mass-production autonomous driving.
Cross-attention, on the other hand, has a more solid case to make. One pioneering study of applying cross-attention to computer vision is DETR (End-to-End Object Detection with Transformers, ECCV 2020). One of the most innovative parts of DETR is the cross-attention decoder based on a fixed number of slots called object queries. Different from the original Transformer paper where each query is fed into the decoder one by one (auto-regressively), these queries are fed into the DETR decode in parallel (simultaneously). The contents of the queries are also learned and do not have to be specified before training, except the number of the queries. These queries can be viewed as a blank, preallocated template to hold object detection results, and the cross-attention decoder does the work of filling in the blanks.

The Cross-Attention Decoder part of DETR can be viewed as a cross-domain generator (source)
This prompts the idea of using the cross-attention decoder for view transformation. The input view is fed into a feature encoder (either self-attention based or CNN-based), and the encoded features serve as K and V. The query Q in target view format can be learned and only need to be rasterized as a template. The values of Q can be learned jointly with the rest of the network.

The DETR architecture can be adapted for BEV transformation (Image by Author)
In the following session, we will review some most relevant work along this line, and also we will take a deep dive into the use of Transformers in Tesla’s FSD shared by Andrej Karpathy on Tesla AI Day (08/20/2021).
PYVA (CVPR 2021)
PYVA (Projecting Your View Attentively: Monocular Road Scene Layout Estimation via Cross-view Transformation, CVPR 2021) is among the first to explicitly mention that a cross-attention decoder can be used for view transformation to lift image features to BEV space. Similar to earlier monocular BEV perception work, PYVA performs road layout and vehicle segmentation on the transformed BEV features.

The architecture of PYVA uses an MLP and cross-attention (source)
PYVA first used an MLP to lift image features X in the perspective space to X’ in the (claimed) BEV space. A second MLP maps the X’ back to image space X’’, and uses the cycle consistency loss between X and X” to make sure this mapping process retains as much relevant information as possible.
The Transformer used by PYVA is a cross-attention module, with the query Q to be mapped BEV feature X’ in BEV space, and V and K are both the input X in perspective space (if we ignore the differences between X and X” in perspective space).
Note that there is no explicit supervision for X’ in the BEV space, and is implicitly supervised by the downstream task loss in the BEV space.
In PYVA, it seems to be the MLP that does the heavy lifting of view transformation, and the cross-attention is used to enhance the lifted features in BEV. Yet as there is no explicit supervision of the generated query in BEV space, technically it is hard to separate the contribution from the two components. An ablation study of this would have been useful to clarify this.
NEAT (ICCV 2021)
NEAT (Neural Attention Fields for End-to-End Autonomous Driving, ICCV 2021) uses Transformers to enhance the features in image feature space, before using MLP-based iterative attention to lift image features into BEV space. The goal of the paper is interpretable, high-performance, end-to-end autonomous driving, but we will only focus on the generation of the interpretable intermediate BEV representation here.

The architecture of NEAT (source)
The Transformers used in the Encoder block are based on self-attention. The authors also acknowledged that “the transformer can be removed from our encoder without changing the output dimensionality, but we include it since it provides an improvement as per our ablation study”. As we discussed above, encoders equipped with the self-attention module can be treated just as a glorified backbone, and it is not the focus of this study.
The most interesting part happens in the Neural Attention Field (NEAT) module. For a given output location (x, y), an MLP is used to take the output location and the image features as input, generate an attention map of the same spatial dimension as the input feature image. The attention map is then used to dot-product the original image feature to generate the target BEV features for the given output location. If we iterate through all possible BEV grid locations, then we can tile the output from the NEAT module into a BEV feature map.

Cross Attention module vs Neural Attention Field module (Image by Author)
This NEAT module is quite similar to the cross attention mechanism. The main difference is that the similarity measurement step between Q and K is replaced by an MLP. There are other minor details that we are ignoring here, such as the Softmax operation, and the linear projection of the value V. Mathematically, we have the following formulations for MLP, cross attention and NEAT.

The difference between MLP, Cross-attention, and NEAT (adapted from source)
The symbol convention follows my previous blog post on the difference between MLP and Transformers. In short, it is apparent that NEAT keeps the data-dependency nature of the cross-attention mechanism, but it does not have the permutation invariance of cross-attention anymore.
There is one more detail omitted in the discussion above for the clarity of comparison with cross-attention mechanism. In the implementation of NEAT, the input of the MLP is not the fully-fledged image feature c, but a globally pooled c_i which does not have any spatial extent. And iterative attention is adopted. The authors argue that it is more complex to feed the image feature c with much higher dimension than c_i into the MLP. Maybe one pass of MLP is not enough to compensate the loss of spatial content, thus multiple passes are required. The paper did not provide ablation study of this design choice.
The Decoder part also uses an MLP to generate the desired semantic meaning of the queried location (x, y). If we tile the NEAT output into a BEV feature map, the MLP taking the feature at a specific location and the location coordinates as input is equivalent to a 1x1 convolution over the BEV feature map, with (x, y) concatenated to the feature map. This operation is very similar to CoordConv (NeurIPS 2018). This is fairly standard practice to leverage the BEV feature map for downstream BEV perception tasks. We can even go beyond the 1x1 convolutions and further improve the performance with stacked 3x3 convolutions to increase the receptive field in BEV space.
In summary, NEAT uses a variant of cross-attention (MLP to replace the similarity measurement) to lift camera images to BEV space.
STSU (ICCV 2021)
STSU (Structured Bird’s-Eye-View Traffic Scene Understanding from Onboard Images, ICCV 2021) uses sparse queries for object detection, following the practice of DETR. STSU detects not only dynamic objects but also static road layouts. This is a follow-up work to BEV Feature Stitching by the same authors, a paper on BEV semantic segmentation reviewed in my other blog.

The architecture of STSU (source)
STSU uses two sets of query vectors, one set for centerlines and one for objects. What is most interesting is its prediction of the structured road layout. The lane branch includes several prediction heads.
- The detection head predicts if the lane encoded by a certain query vector exists.
- The control head predicts the location of R Bezier curve control points.
- The association head predicts an embedding vector for clustering.
- The association classifier takes in 2 embedding vectors and judges whether the centerline pairs are associated.
Bezier curves are a good fit for centerline since it allows us to model a curve of arbitrary length with a fixed number of 2D points.
The use of Transformers for lane prediction is also used in LSTR (End-to-end Lane Shape Prediction with Transformers, WACV 2011), which is still in image space. The structured road layout prediction can also be found in HDMapNet (An Online HD Map Construction and Evaluation Framework, CVPR 2021 workshop), which did not use Transformers.
DETR3D (CoRL 2021)
DETR3D (3D Object Detection from Multi-view Images via 3D-to-2D Queries, CoRL 2021) also uses sparse queries for object detection, following the practice of DETR. Similar to STSU, but DETR3D focuses on dynamic object. The queries are in BEV space and they enable DETR3D to manipulate prediction directly in BEV space instead of doing a dense transformation of the image features.

The architecture of DETR3D (source)
One advantage of BEV perception over mono3D is in the camera overlap regions where objects are more likely to be cropped by camera field-of-view. Mono3D methods have to predict the cropped objects in each camera based on the limited information from each camera viewpoint and rely on global NMS to suppress redundant boxes. DETR3D specifically evaluated on such cropped objects at image boundaries (about 9% of the entire dataset) and found significant improvement of DETR3D over mono3D methods. This is also reported in Tesla AI Day.

Multi-Cam predictions are better than Single cam results (source)
DETR3D uses several tricks to boost the performance. First is the iterative refinement of object queries. Essentially, the predicts the bbox centers in BEV is reprojected back to images with camera transformation matrices (intrinsics and extrinsics), and multi-cam image features are sampled and integrated to refine the queries. This process can be repeated multiple times (6 in this paper) to boost the performance.
The second trick is to use pretrained mono3D network backbone to boost the performance. Initialization seems to matter quite a lot for Transformers-based BEV perception network.
Translating Images into Maps (2021/10, Arxiv)
Translating Images into Maps notices that, regardless of the depth of the image pixel, there is a 1–1 correspondence between a vertical scanline in the image (image column), and a polar ray passing through the camera location in an BEV map. This is similar to the idea of OFT (BMVC 2019) and PyrOccNet (CVPR 2020), which smears the feature at a pixel location along the ray projected back into 3D space.

The use of axial cross-attention Transformers in the column direction and convolution in the row direction saves computation significantly.
Tesla’s Approach
On Tesla AI Day in 2021, Tesla revealed many intricate inner workings of the neural network powering Tesla FSD. One of the most intriguing building blocks is one dubbed “image-to-BEV transform + multi-camera fusion). At the center of this block is a Transformer module, or more concretely, a cross-attention module.

Tesla’s FSD architecture (source)
You initialize a raster of the size of the output space that you would like, and you tile it with positional encodings with sines and cosines in the output space, and then these get encoded with an MLP into a set of query vectors, and then all of the images and their features also emit their own keys and values, and then the queries keys and values feed into the multi-headed self-attention (Note by the author: this is actually cross-attention).
— Andrej Karpathy, Tesla AI Day 2021, source
Although Andrej mentioned that they used a multi-headed self-attention, but what he described is clearly a cross-attention mechanism, and the chart on the right in his slides also points to the cross-attention block in the original Transformers paper.
The most interesting part in this view transformation is the query in BEV space. It is generated from a raster in the BEV space (blank, preallocated template, as in DETR) and concatenated with Positional Encodings (PE). There is also a Context Summary that tiles with the positional encodings. The diagram does not show the details in how the context summary is generated and used with positional encodings, but I think there is a global pooling that collapses all the spatial information in the perspective space, and a tiling operation that tiles this 1x1 tensor across the predefined BEV grid.
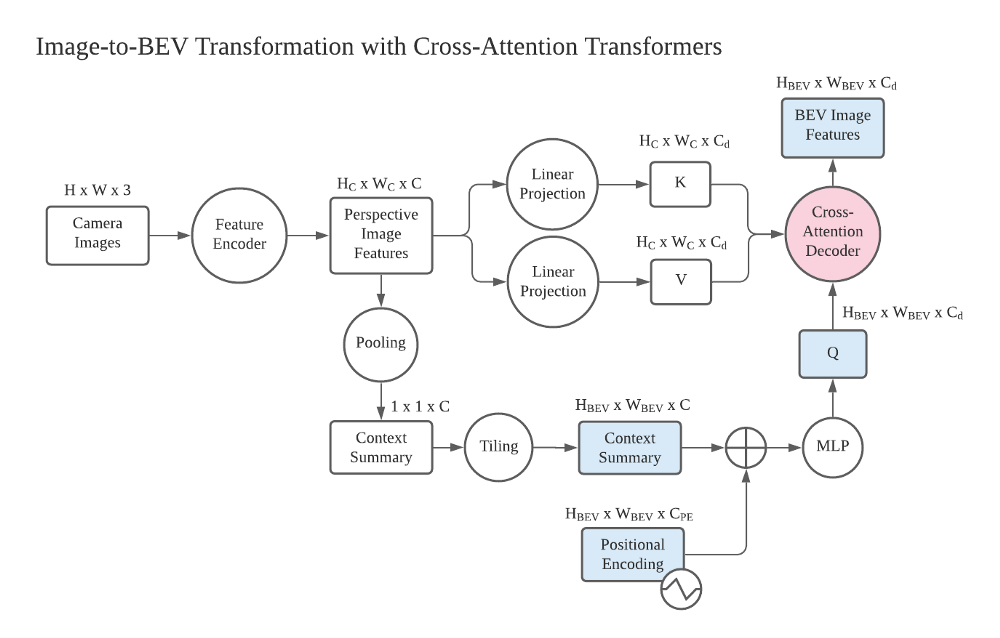
Building blocks and tensor shapes of the Image-to-BEV Transformation with cross-attention Transformers (Image by Author)
In the diagram above, I listed the more detailed blocks in the view transformation module (circles) and corresponding tensors with their shapes (squares), based on my understanding. The tensors in BEV space are color-coded blue, and the core cross-attention module is color-coded red. Hopefully, this helps interested readers in academia dig deeper in this direction.
A final word on Transformers vs MLP for BEV lifting
Illustrated Differences between MLP and Transformers for Tensor Reshaping
A deep dive into the math details, with illustrations.
(Lifting images to BEV space) is data dependent it’s really hard to have a fixed transformation for this component so in order to solve this issue we use a transformer to represent this space. — Andrej Karpathy, Tesla AI Day 2021
Andrej also mentioned that the view transformation problem is data-dependent and they opted for Transformers. Regarding the detailed usage of cross-attention for tensor reshaping and its difference from MLP is detailed in my previous blog, with some mathematical details and concrete illustrations. It also highlighted why the tensor reshaping by Transformers is data-dependent whereas MLP is not.
Takeaways
- Transformers are becoming more popular in academia and industry for view transformation.
- As discussed in my previous blog, though data dependency of Transformers makes it more expressive, it also makes it hard to train, and the break-even point with MLP may require tons of data, GPU and engineering efforts.
- The deployment of Transformers in the resource-limited embedded system in mass production autonomous vehicles may also be a major challenge. In particular, the current neural network accelerators or GPUs are highly optimized for convolutional neural networks (3x3 convolutions, for example).
Acknowledgment
I have had several rounds of discussion with Yi Gu, who is currently doing his Ph.D. research at the University of Macau. Our discussion prompted me to revisit the recent trend in the field of monocular BEV perception.
References
- NEAT: Neural Attention Fields for End-to-End Autonomous Driving, ICCV 2021
- PYVA: Projecting Your View Attentively: Monocular Road Scene Layout Estimation via Cross-view Transformation, CVPR 2021
- Tesla AI day, streamed live on Youtube on Aug 20, 2021
- Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D, ECCV 2020
- CaDDN: Categorical Depth Distribution Network for Monocular 3D Object Detection, CVPR 2021 oral
- FIERY: Future Instance Prediction in Bird’s-Eye View from Surround Monocular Cameras, ICCV 2021
- BEV-Seg: Bird’s Eye View Semantic Segmentation Using Geometry and Semantic Point Cloud, CVPR 2020 workshop
- HDMapNet: An Online HD Map Construction and Evaluation Framework, CVPR 2021 workshop
- DETR: End-to-End Object Detection with Transformers, ECCV 2020
- Attention is All you Need, NeurIPS 2017
- Neural Machine Translation by Jointly Learning to Align and Translate, ICLR 2015
- ViT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR 2021
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, Arxiv 2021/03
- CoordConv: An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution, NeurIPS 2018
- STSU: Structured Bird’s-Eye-View Traffic Scene Understanding from Onboard Images, ICCV 2021
- DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries, CoRL 2021
- Translating Images into Maps, Arxiv 2021/10