背景
利用图卷积神经网络处理推荐系统的问题任然有很大局限性,即使是LightGCN也存在的问题,关于LightGCN的知识和原理实现可以参考我的另外几篇博客:链接
其局限性主要在于:
(1)高度节点对表征学习的影响更大,低度(长尾)节点的推荐效果更差;
(2)表示容易受到噪声交互的影响,因为邻域聚合方案进一步扩大了观察到的边的影响。
(3)目前大多数推荐学习任务都是基于监督学习的范式,其中监督信号一般指用户和物品的交互数据。然而这些交互数据通常来说是异常稀疏的,不足以学习高质量的表征。
而自监督对比学习可以有效解决标记数据不足的网络训练困难、不准确的问题。可以参考我的博客:推荐系统笔记(七):自监督学习、对比学习简介_甘霖那的博客-CSDN博客
因此,将自监督学习(Self-supervised Learning, SSL)在用户-物品二部图上的应用,辅助推荐模型训练学习,应用self-discrimination来学习更加鲁棒的节点表征的想法油然而生。

论文链接: https://arxiv.org/abs/2010.10783v4
思想
其思想是在经典的有监督推荐任务的基础上增加一个辅助的自我监督任务,通过自我识别加强节点表示学习。具体来说,生成一个节点的多个视图,最大限度地提高同一节点不同视图之间的一致性。
原理
GCN模型最典型的例子是NGCF和LightGCN,这两种模型参考我的另外两篇博客:
推荐系统笔记(四):NGCF推荐算法理解 || 推荐系统笔记(五):lightGCN算法原理与背景
从概念上讲,SGL补充了现有的基于GCN的推荐模型:
(1) 节点自分辨提供了辅助监督信号,这是对经典监督信号的补充,而经典监督信号仅来自观察到的交互 ;
(2)dropout算子,通过有意减少高度节点的影响,有助于缓解度偏差 ;
(3)节点关于不同局部结构和邻域的多视图,增强了模型对交互噪声的鲁棒性。
其具体的原理如下:
1. 仍然使用GCN的架构
通过聚合相邻节点的表示来更新ego节点的表示:即对图进行近邻聚集策略(neighborhood aggregation scheme),每个节点聚集它的近邻的特征向量来计算它的新表征。
![]()
其中 Z(l) 表示第 l 层的表征, Z(0) 表示ID embedding,即训练参数, H 为近邻聚合。其中的H可以进一步表示为:
![]()
为了更新节点 u 获得其第 l 层表征,首先聚合其近邻 Nu 在(l−1)的表征,然后与自身表征 zu(l−1) 结合。这里的 和
可以有多种的实现,如LightGCN。在获取 L 层节点表征后,也许采用一个读出函数(readout function)生成最后的表征用于预测:

监督学习损失,一个预测层建立在最终表征上,预测 用户u 有多大可能会喜欢物品 i 。常见的做法即是算点击,可以支持快速的召回:
![]()
损失函数任然使用的是BPR loss损失函数,该损失函数可以参考我的其他博客,
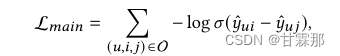
2. 自监督学习在推荐系统中的应用
(1)数据增强
直接照搬CV和NLP任务中采用的数据增强对于基于图形的推荐是不可行的,因为用户和项目的特征是离散的,并且交互图中的用户和项目本质上是相互连接和依赖的。因此需要重新设计数据增强的方法。论文中提出了三种不同的数据增强方法:
Node Dropout(ND):图中每个节点都可能以概率 ρ 被舍弃,连带其连接的边一起舍弃。具体 s1 和 s2 如下建模:
![]()
因为需要两个图才能进行对比,因此需要构建两个不同的子图,M’和M'’分别去drop掉数据。
Edge Dropout(ED):图中每条边都可能以概率 ρ被舍弃。具体如下表示:
![]()
Random Walk (RW):上述两个操作符生成的子图在图卷积的所有层中保持一致。而这里的RW是指的每一层的M'和M''都是不同的,即层与层之间的dropout不共享:
![]()
上述操作符只有dropout和masking操作,没有增加任何模型参数。
(2)对比学习
为每个节点建立增强视图后,我们将同一节点不同视图作为正样本对:
![]()
将不同节点的视图作为负样本对:
![]()
正样本对的辅助监督信号促进同一节点不同视图的一致性,负样本对的辅助监督信号强化不同节点视图间的差异性。最后采用采用了InfoNCE损失来达到上述目的:

用于计算两个向量的相似度,这里采用了余弦相似度, τ 表示温度系数,为了计算了物品测的对比损失
。最终的自监督任务目标函数为:
。
(3)多任务学习
最终采用了一个多任务学习的方式,如下:
![]()
Lmain 表示监督学习任务, λ1 和 λ2 分别用于控制自监督学习任务和正则化项的强度。
参数学习
参数学习和分析请参考Self-supervised graph learning for recommendation-自监督图学习增强的推荐 - 知乎
复杂度

这里对事件复杂度进行简单分析,其中 |E| 表示图中边的个数, ρ^=1−ρ , s 表示训练轮数, B 表示训练批次数, d 表示embedding的维度, L 表示GCN的层数。
Adjacency Matrix:LightGCN时间复杂度乘2是由于邻接矩阵是按照主对角线对称的,而 4ρ^|E|s 由于有构建2个子图,而且每个epoce都要重新构建, ρ^ 表示保留表的比例。
Graph Convoluntion: 乘以|E|B 的原因是每一步(step)都要重新计算图卷积。
BPR Loss:乘以2的原因是BPR损失要同时计算正样本对和负样本对的损失。
Self-supervised Loss: (2+|V|) 是将所有其他节点当作负样本时的复杂度, (2+2B) 是将批次内其他节点当作负样本时的复杂度。
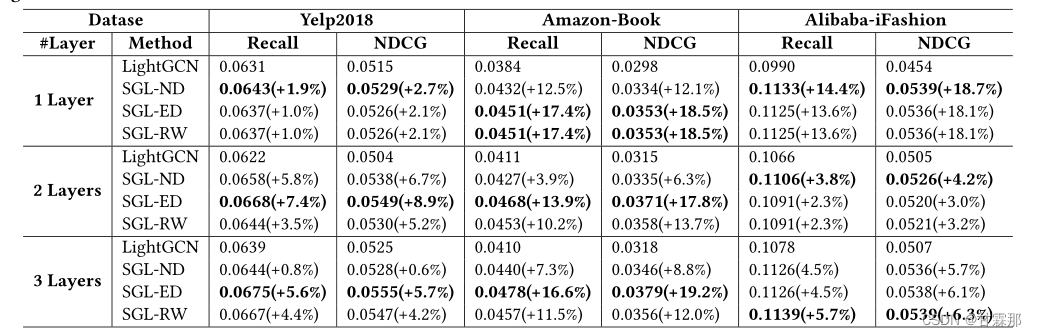
实验
下图中GroupID表示物品节点分组,GroupID越大表示节点度数越高,从图中可以看出SGL可以有效的提高长尾节点的表现。
从下图可以看出增加了自监督学习任务的SGL,无论是采用哪种数据增强操作符,其性能都强于未添加增强的模型。
总结
SGL 是模型不可知框架,采用用户项图上的自监督学习来弥补数据集稀疏和噪声影响的不足。论文中通过实验证明了SGL长尾推荐、训练收敛和抗噪声交互鲁棒性方面的优势。
总的来说,SGL修改了LightGCN的损失函数,增加了辅助任务,并且通过dropout来实现更加鲁棒的节点表示。其他的架构基本和LightGCN相同。