目录
Deep Reinforcement Learning, 深度强化学习的理论知识
Deep Reinforcement Learning, 深度强化学习的理论知识
强化学习系统的四要素:policy、reward、value、model。 主要是从一个强化学习的系统的角度去看。
1)policy指的是智能体在给定时间点的行为方式。policy定义了当前state与该state下可选action之间的映射。
(2)reward signal定义了强化学习的目标。
(3)reward定义了当前的动作选取的好坏,value function则定义了长期视角动作选取策略的好坏。
(4)model指的是对于环境的模拟。也就是构造一个模型来推断环境是如何变化的使用模型和规划来解决强化学习问题的方法被称为是基于模型的强化学习方法,与此相反的是较简单的无模型强化学习方法(通常是直接在环境试错学习的)。
什么是强化学习
强化学习是一种机器学习方法,能够使智能体通过与环境交互,学习如何做出最优决策以获取最大化的奖励。
有广泛的应用领域,包括机器人、游戏、自然语言处理等,具有很高的研究和商业价值。
基本组成部分包括智能体、环境、状态、动作、奖励和策略。
其基本原理是通过不断调整策略,最大化期望的长期累积奖励;另外强化学习相较于其他机器学习方法的优势在于其可以处理非固定环境下的复杂任务,并且能够学习到长期的行为模式。
为什么使用强化学习
不是所有需求都适合用DRL做,适合用DRL做的需求也未必能超越传统方法。
在我看来,算法工程师的核心能力可以总结成以下三点:
- 对各种算法本质及其能力边界的深刻理解
- 对问题内在逻辑的深入分析
- 对两者结合点的敏锐直觉
一个优秀算法工程师的高光时刻从拒绝不合理的需求开始,其他的都是后话。不经慎重评估而盲目上马的项目不仅是对资源的巨大浪费,更让每个参与者陷在深坑中痛不欲生。知道一种算法不能干什么与知道它能干什么同样重要,对DRL而言,即使在最理想的外部条件下,也有其绕不过去的七寸——泛化无能。这是DRL的基本原理决定的,任何在这一点上提出过高要求的应用都不适合用DRL解决。
DRL解决的是从过去经验中学习有用知识,并用于后续决策的问题。有别于纯视觉应用,DRL不仅仅满足于识别和定位,而是要根据这些信息采取针对性的行动以获取最大长期收益。从本质上说,DRL就是一种依赖过拟合的算法,说白了就是通过暴力搜索把其中的成功经验记下来,并用以指导后续决策。别嫌露骨,别怕尴尬,岂不闻学术界某大牛的辛辣讽刺仍余音绕梁——强化学习是唯一被允许在训练集上测试的算法。由于缺乏直接监督信号用于训练,DRL还特别“费数据”,以至于需要专门的模拟器源源不断地产生数据供其挥霍。好不容易训出来的policy在训练环境用得好好的,换个环境立马歇菜。
强化学习的基本要素
强化学习的核心组成要素包括状态、动作、奖励和价值等概念。
强化学习的流程通常包括环境建模、状态表示、策略生成、价值函数估计、动作选择等步骤。在环境建模中,需要将问题转化为马尔可夫决策过程(Markov Decision Process,MDP)或者其扩展形式。状态表示是将环境状态转化为智能体可理解的形式,策略生成是根据当前状态选择最优的行动,价值函数估计是评估策略的好坏,动作选择是根据策略生成和价值函数估计来确定下一步的行动。
On-policy和Off-policy
两者在学习方式上的区别:若agent与环境互动,则为On-policy(此时因为agent亲身参与,所以互动时的policy和目标的policy一致);若agent看别的agent与环境互动,自己不参与互动,则为Off-policy(此时因为互动的和目标优化的是两个agent,所以他们的policy不一致)。
两者在采样数据利用上的区别:On-policy:采样所用的policy和目标policy一致,采样后进行学习,学习后目标policy更新,此时需要把采样的policy同步更新以保持和目标policy一致,这也就导致了需要重新采样。Off-policy:采样的policy和目标的policy不一样,所以你目标的policy随便更新,采样后的数据可以用很多次也可以参考。
Online和Offline学习的本质
监督学习中通常利用已知(已标记)的数据进行学习,其本质是从数据中总结规律,这和人从学1+1=2基本原理一致,强化学习的过程也是如此,仍然是从数据中学习,只不过强化学习中学习的数据是一系列的轨迹。
所以重点来了,这里的数据才是最关键的一部分,这也强化学习中Online和offline学习中的关键, Online一方面是与环境有交互,通过采集数据学习、然后丢弃,而offline则是不用交互,直接通过采集到的轨迹数据学习,这也是off-policy到offline转换的重要原因。
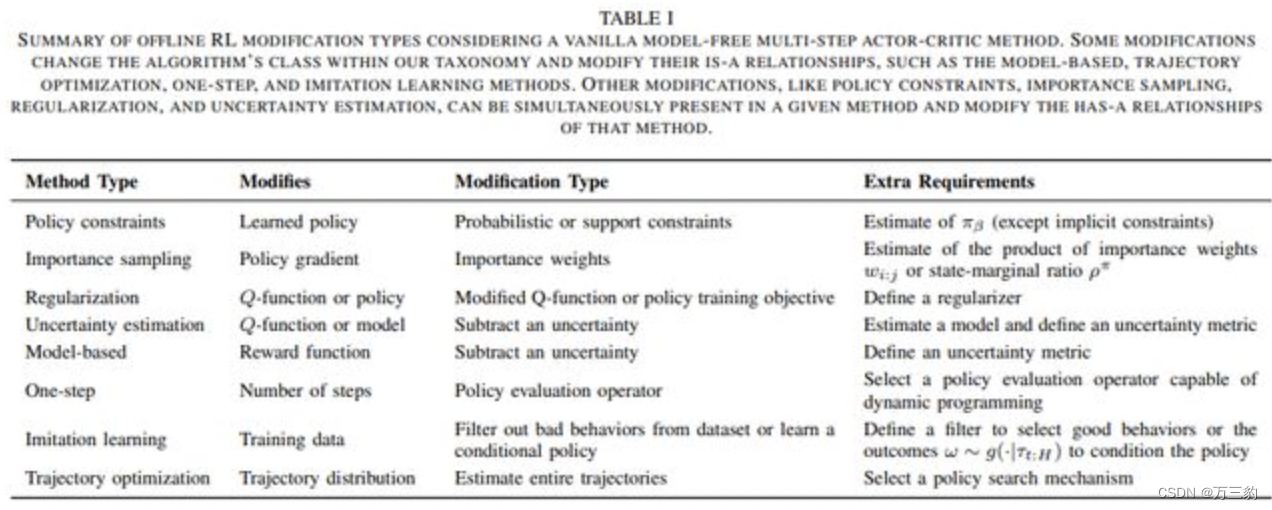
万字离线强化学习总结!(原理、数据集、算法、复杂性分析、超参数调优等)|轨迹|智能体_网易订阅
基本概念
链接:强化学习怎么入门好? - 知乎
1. 区分强化学习/有监督学习/无监督学习
- 这是三种不同的训练方式,核心区别在于loss的设计。
- 三者可用于同一 task,就像锤子和砍刀都可以用于砸钉子。
- task 选用哪一种工具,取决于获取 loss 所需数据的性价比。比如风格转移,使用Discriminator 判断 sample 是否属于目标域,显然优于一一标记数据集后进行有监督学习。
2. 区分 Return(s,a) 和 reward(s,a)
- reward(s,a) 是 environment 在状态s下,对行为a的单步奖励值。
- Return(s,a) 是 在状态s下,对往后n步的奖励值的组合。
-- n ∈\in {0, 1, .... ∞\infty }
-- 组合方式常用discounting, 详见 Sutton 书 3.3章。
3. 区分 Return,Q , V (value)和A(Advantage)
- Q(s,a) == Return(s,a)
- V(s)=Ea(Q(s,a))V(s)=E_a (Q(s,a))
- A(s,a)=Q(s,a)−V(s)A(s,a)=Q(s,a)-V(s)
-- 用A值更新policy会更稳定
4. 区分 policy 和 Q/V/A
- 在状态 s 下,policy 选出用于与环境交互的行为 a。
- policy 选择行为 a 的依据是 Q(s,a) / V(s') ( 在状态 s 下执行 a 后转移到状态 s')
--- policy 1: argmax(Q(s,a))
--- policy 2: sample from distribution
- Q(s,a) / A(s,a) / V(s') 的更新依赖于policy
5. 区分MC, DP, n-steps TD, GAE
-- DP 是已知 s,a->s'的状态转移概率,直接计算被估计值
-- MC 和 TD 都是通过采样估计值

-- MC 估计的样本全部来自采样,n-step TD 估计在第n步时使用估计值(有偏)
-- GAE 是对 n-steps TD 估计 Advantage值 的优化,将不同n值的TD 估计以decay的方式糅合在一起

6. 区分 policy-based 和 value-based
- 上述 policy 1 中的policy是固定的,因此为 value-based。
- 上述 policy 2 需要更新policy的分布,因此为 policy-based。
7. 区分离散和连续
- 理论上,在确定的 policy 下( eg, max ),可采样估计出所有的 Q/V, eg, Q-learning
--- 离散 environments: grid world (github上很多,后续我也会开源一个 : )
- 实际上,当状态空间连续(eg, Atari),或状态和行为空间均连续(eg, Mujoco)时,估计所有 Q/V成本过高,无法实现,因此引入DNN进行近似(DQN, DDPG)
--- 连续 environments: open AI gym
8. 区分online和offline
- online是线上训练,即便使用模型,边训练模型。
- offline是线下训练,即使用训练好的模型。
9. on-policy和off-police
- on-policy指,计算Return时所采用的sample,均由policy采样所得。
- off-police指,计算Return时所采用的sample,并非由policy采样所得。
- 对比Q-learning(off-police)和SARSA(on-policy)可以更直观地看出二者的差异。

左(q-learning), update Q时直接用的max Q(s’, a’),右(SARSA),使用采样的Q(s’, a’)
10. 区分 model-free 和 model-based
- 此处 model 指 environment。
- 显然,上述所有内容,均将environment视为黑盒,故为 model-free - 易得,学习 environment (比如 s,a 到 s' 的转移规则)的算法属于 model-based。
11. OpenAI baseline
- 掌握了1-9的基础知识后,就可以逐个学习baseline里的算法啦~
- RL的基础算法均有被baseline实现,可以边看paper边看code,有利于更快地掌握~
- 以后我会补充上baseline的代码解读~
12. 理解 exploration
重要,待补充
13. 理解 tradeoff variance and bias
重要,待补充
14. 理解 POMDP
见:花潇:POMDP 基础及其在 Crowd 场景中应用
15. 理解 multi-agents
重要,待补充
强化学习的分类
强化学习的模型和算法包括:基于价值函数的方法、基于策略的方法、基于模型的方法和深度强化学习等。其中,(1)基于价值函数的方法主要包括Q-learning和SARSA等,(2)基于策略的方法主要包括策略梯度算法和Actor-Critic算法等,(3)基于模型的方法主要包括模型预测控制和模型自适应控制等。深度强化学习是将深度学习与强化学习相结合的一种方法,包括Deep Q-Network(DQN)、Deep Deterministic Policy Gradient(DDPG)和Asynchronous Advantage Actor-Critic(A3C)等算法。
适用DRL的五大特征
场景固定,目标明确,数据廉价,过程复杂,自由度高。依次解读如下:
训练环境尽可能做到与工作(测试)环境相同。
工业界的需求一般都是优化某个指标(效率、能耗、胜算等),基本满足这个条件。目标越明确,设计优质的reward函数就越容易,从而训练得到更接近预期的policy。
所谓模拟器,就是将真实场景中的各种物理模型(即上文提到的model)在软件环境中仿真,从而生成无限量的高仿数据。这里有一个reality gap的问题,即这些仿真model与真实世界的误差,如果太大则训练出的policy无法直接应用。一个逼真的模拟器也是要花功夫(钱)的,像MuJoCo这样的优秀仿真平台收费也是合情合理的。
如果任务太简单,依靠规则和启发式就能解决问题了,相当于拿到了“解析解”,还用神经网络拟合个什么劲儿。
定用DRL之前,一定要认真评估任务场景是否有足够的优化空间,千万不要拎着锤子找钉子,否则即使训出了policy,性能也不如传统算法,白忙活一场。
强化学习的资料
公众号:深度强化学习实验室
书籍:
项目:
深度强化学习
万字离线强化学习总结!(原理、数据集、算法、复杂性分析、超参数调优等)|轨迹|智能体_网易订阅
策略
要素设计
在强化学习场景中,我们定义问题的数学框架被称之为马尔科夫决策过程。这可以被设计为:
- 状态集合:S
- 动作集合:A
- 奖励函数:R
- 策略:π
- 价值:V
数据
所以重点来了,这里的数据才是最关键的一部分,这也强化学习中Online和offline学习中的关键, Online一方面是与环境有交互,通过采集数据学习、然后丢弃,而offline则是不用交互,直接通过采集到的轨迹数据学习,这也是off-policy到offline转换的重要原因。
实践代码
工业界的应用

DQN
何公式化一个强化学习问题,然后进行推导呢?最常见的方法是通过马尔可夫决策过程。
在 Q-学习中,我们定义了一个函数 Q(s,a) 表示当我们在状态(state)s 中执行动作(action)a 时所获得的最大折扣未来奖励(maximum discounted future reward),并从该点进行继续优化。


深度 Q 网络(Deep Q Network)
DQN

DQN是借助AlphaGo最早成名的深度强化学习算法,其核心思想是利用Bellman公式的bootstrap特性,不断迭代优化一个Q(s,a)函数,并据此在各种状态下选择action。其中Q(s,a)函数拟合的是一对状态-动作的长期收益评估,该算法没有显式的policy。DQN探索和利用的平衡靠的是一种称为ε-greedy的策略,针对最新的Q(s,a)函数和当前的输入状态s,agent做决策时以概率ε随机选择action,而以1-ε的概率选择使Q(s,a)最大的action,随着ε从大到小变化,DQN也相应地从“强探索弱利用”过渡到“弱探索强利用”。
DQN的原理使其天然地适合离散动作空间,也就是action可以穷举,比如走迷宫的agent只允许前后左右4个动作,下围棋的AlphaGo只允许19*19=361个落子位置(实际还要排除已经落子的网格点)。这是一个重要的特征,如果你手上是一个连续控制任务,action在某区间内有无数种可能,那就不适合用DQN了。当然,你也可以选择把区间离散化,这样就可以应用DQN了,也曾有paper报告这样做在某些任务中可以比连续控制取得更好的性能。
DQN属于off-policy方法,所谓off-policy是指用于计算梯度的数据不一定是用当前policy采集的。DQN使用一个叫replay buffer的FIFO结构,用于存储transition:(s,a,s',r),每次随机从buffer中拿出一个batch用于梯度计算和参数更新。Replay buffer是稳定DQN训练的重要措施,对历史数据的重复使用也提高了其数据利用率,对于那些数据比较“贵”的任务,比如Google的抓取应用(见需求分析篇),这一点非常重要,事实上Google除了replay buffer,还专门搞了个数据库,把之前存储的另一个抓取应用采集的数据拿出来做预训练,精打细算到了极致,真是比你有钱,还比你节约~
DQN的缺点挺多,有些是RL的通病,比如对超参数敏感,我在训练篇会详细介绍;另外利用Bellman公式的bootstrap特性更新Q值的方式自带bias,外加计算目标Q值时使用同一个网络评估和选择动作(见下式),DQN容易被overestimation问题困扰,导致训练稳定性较差,近些年学术界有不少工作是围绕这一点做出改进(比如Double DQN)。此外,DQN还有off-policy方法的通病,对历史数据的重复利用虽然可以提高数据效率,但有个前提条件是环境model不能发生变化,single agent任务较易满足这个条件,但multiagent场景就未必了,对任意agent而言,其他agent也是环境的一部分,而他们的学习进化会改变这个环境,从而使历史数据失效,这就是MARL领域著名的环境不稳定问题,除非replay buffer内的数据更新足够快,否则off-policy方法的性能往往不如on-policy方法。

DQN的Q网络更新公式
DQN参数
DQN的特色超参数主要有:buffer size,起始训练时间,batchsize,探索时间占比,最终epsilon,目标网络更新频率等。
Buffer size指的是DQN中用来提高数据效率的replay buffer的大小。通常取1e6,但不绝对。Buffer size过小显然是不利于训练的,replay buffer设计的初衷就是为了保证正样本,尤其是稀有正样本能够被多次利用,从而加快模型收敛。对于复杂任务,适当增大buffer size往往能带来性能提升。反过来过大的buffer size也会产生负面作用,由于标准DQN算法是在buffer中均匀采集样本用于训练,新旧样本被采集的概率是相等的,如果旧样本或者无效样本在buffer中存留时间过长,就会阻碍模型的进一步优化。总之,合理的buffer size需要兼顾样本的稳定性和优胜劣汰。顺便说一句,针对“等概率采样”的弊端,学术界有人提出了prioritized replay buffer,通过刻意提高那些loss较大的transition被选中的概率,从而提升性能,这样又会引入新的超参数,这里就不做介绍了。
起始训练时间的设置仅仅是为了保证replay buffer里有足够的数据供二次采样,因此与batchsize有直接关系,没啥可说的。Batchsize指的是从replay buffer中二次采样并用于梯度计算的batch大小,和CV任务中的设定原则基本一致,即兼顾训练稳定性和训练速度,也没啥好说的。
探索时间占比和最终ε共同决定了DQN探索和利用的平衡。ε-greedy策略在训练开始的时候,随机选择action的概率ε=1,探索力度最大;随着训练进行ε逐渐线性下降直至达到最终epsilon保持恒定,之后DQN的训练将以利用为主而只保留少量探索。因此,最终ε取值在区间[0,1]内靠近0的一端。探索时间占比指的是ε从1下降到最终ε的时间占总训练时间的比例,在(0,1)内取值,用来调节以探索为主到以利用为主的过渡。通常来说,复杂任务的探索时间占比应设得大一些,以保证充分的探索;最终ε不宜过大,否则影响模型最终阶段“好上加好”的性能冲刺,因为最好的状态往往是在足够好的Q网络指导下才能探索到的,训练后期过强的探索干扰了习得知识的利用,也就阻碍了性能的进一步提升。
标准DQN引入了一个延迟更新的目标网络用来计算Q的目标值,避免Q网络误差的“自激效应”,并借此来提高训练稳定性。目标网络更新频率就是用来控制这个延迟程度的,时间到了就把Q网络的参数整个复制过来。通常情况下根据具体问题,参考Q网络的更新周期设定,比如Q网络每1个step更新一次,目标Q网络可以设定每500个step更新一次。

 梯度上升
梯度上升
整个过程的随机性,是期望


ppo
《深度强化学习落地指南》读书笔记1--什么情况下我们可以用强化学习?_第一剑柄的博客-CSDN博客
深度强化学习落地方法论(8)——新书推荐《深度强化学习落地指南》 - 知乎
强化学习(reinforcement learning)有什么好的开源项目、网站、文章推荐一下? - 知乎
DeepRL/A-Guide-Resource-For-DeepRL at master · NeuronDance/DeepRL · GitHub
【强化学习】重磅 | 详解深度强化学习,搭建DQN详细指南 - 专知
手把手教你强化学习 (一) 强化学习基本概要 (上) - 简书
深度强化学习(Deep Reinforcement Learning)入门 - 知乎