你说精通MySQL其实很菜jī(基础篇):你不一定会的基本技巧或知识点(值得一看)
-
- 《你说精通MySQL其实很菜jī》系列文章(持续更新)
- 一、前言
- 二、技巧或知识点汇总
-
- 1、MySQL客户端(Client)连接MySQL服务器(Server)的多种方式
- 2、MySQL两种方式断开连接
- 3、撤销命令
- 4、连接MySQL时指定要连接的数据库
- 5、查询当前的数据目录
- 6、Shell中检查数据目录(以查询出来的数据目录为准)内的文件
- 7、数据类型底层虐你千百遍
- 8、克隆表结构
- 9、ignore 在 insert 语句中的应用
- 10、 replace 语句应用和 insert 语句中 on duplicate key update 的应用
- 11、截断表(truncating table)
- 12、MySQL官方示例数据库(Employees)下载并安装
- 13、使用正则表达式查询数据
《你说精通MySQL其实很菜jī》系列文章(持续更新)
- 你说精通MySQL其实很菜jī(基础篇):你不一定会的基本技巧或知识点(值得一看)
- 你说精通MySQL其实很菜jī(性能调优篇):选择合适的数据类型
- 你说精通MySQL其实很菜jī(2):授予和撤销用户的访问权限
- 你说精通MySQL其实很菜jī(3):查询数据并保存到文件或表中
- 你说精通MySQL其实很菜jī(4):存储过程
- 你说精通MySQL其实很菜jī(5):函数
- 你说精通MySQL其实很菜jī(6):触发器
- 你说精通MySQL其实很菜jī(7):视图
- 你说精通MySQL其实很菜jī(8):事件
- 你说精通MySQL其实很菜jī(9):获取有关数据库和表的信息
- 你说精通MySQL其实很菜jī(10):JSON的使用【进阶】
- 你说精通MySQL其实很菜jī(11):公用表表达式【进阶】
- 你说精通MySQL其实很菜jī(12):生成列(generated column)【进阶】
- 你说精通MySQL其实很菜jī(13):窗口函数【进阶】
- 你说精通MySQL其实很菜jī(14):配置MySQL
- 你说精通MySQL其实很菜jī(15):事务
- 你说精通MySQL其实很菜jī(16):二进制日志
- 你说精通MySQL其实很菜jī(17):备份
- 你说精通MySQL其实很菜jī(18):恢复数据
- 你说精通MySQL其实很菜jī(19):复制
- 你说精通MySQL其实很菜jī(20):表维护
- 你说精通MySQL其实很菜jī(21):管理表空间
- 你说精通MySQL其实很菜jī(22):日志管理
一、前言
少数人是真的精通MySQL,但大多数人是假精通,或者说,精通背概念,其实属于 菜jī 一类。笔者也只是那大多数人中的一员,啃着《MySQL 8 Cookbook(中文版)》这本书来撰写该系列的文章,当然,有些内容也来自其它资料,希望带给大家精彩和高质量的博客。
《MySQL 8 Cookbook(中文版)》是一本不错的书籍,歪果仁撰写的,[美]Karthik Appigatla 著,周彦伟、孟治华、王学芳三位老师翻译,书籍内容基于MySQL8.0。你说一直使用MySQL5.7,这书适合看吗?那当然!虽然MySQL8相比MySQL5.7,有不少新功能的改进,但是底层的一些技术点却是相通的。
本文主要介绍MySQL中,大部分人不一定会但又很重要的一些基本技巧或知识点,简单的CURD操作不涉及,互联网上MySQL增删改查相关博文满天飞。因为笔者能力有限,所以不可能做到完全没错误和什么知识点都知道,日后再接触到新的知识点,再来补充,描述有问题的,也及时纠正。正如喜剧天才周星驰,当初入行也只是跑龙套,不经过熔炼和摩擦,金子是不会发光的。
与MySQL相关的安装部署博客如下:
最新MySQL-5.7.40在云服务器Centos7.9安装部署
写最好的Docker安装最新版MySQL8(mysql-8.0.31)教程(参考Docker Hub和MySQL官方文档)
本文由 @大白有点菜 原创,请勿盗用,转载请说明出处!如果觉得文章还不错,请点点赞,加关注,谢谢!
二、技巧或知识点汇总
由于笔者要写这个系列的博客,需要启动三个MySQL8 Server,所以采用Docker方式安装MySQL8,端口号分别设置为 3307、3308、3309 ,并没有采用默认的 3306 端口号。
1、MySQL客户端(Client)连接MySQL服务器(Server)的多种方式
-P参数(大写)用于指定端口。
-p参数(小写)用于指定密码。
-p参数(小写)后面没有空格。
对于密码,=后面没有空格。
【延伸阅读】
如果使用 -p 参数,后面直接显式暴露密码(如 123456 )的方式去连接MySQL Server,会报一条警告:
mysql: [Warning] Using a password on the command line interface can be insecure.
翻译过来就是:[警告] 在命令行界面上使用密码可能不安全。
(1)方式一(常见):使用 本地MySQL客户端 连接 本地MySQL服务器 。最常见的方式,缺省了 -h localhost 参数和 -P 端口号(默认是3306) 参数。【注意】:参数“-u”后面可以带空格或者无空格,然后接着用户名,例如 root 用户,但是参数“-p”后面不允许空格,如果输入了空格,会当做密码处理!最好不要在 -p 后面显式暴露密码(如123456),这样很不安全。
mysql -u root -p123456
或者
mysql -uroot -p123456
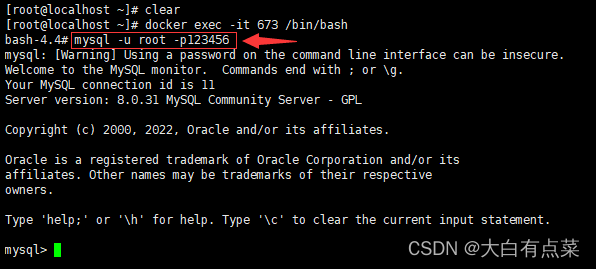
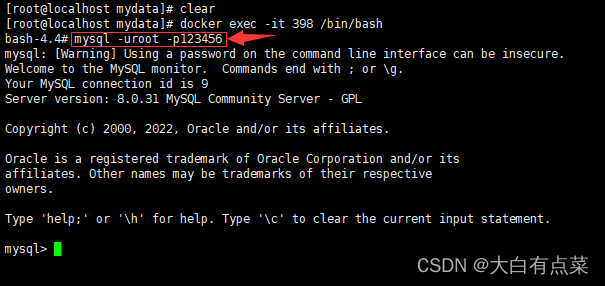
(2)方式二(常见):使用 本地MySQL客户端 连接 本地MySQL服务器 。也是最常见的方式,缺省了 -h localhost 参数和 -P 端口号(默认是3306) 参数。参数“-p”后面不带密码,手动输入密码,这样会更加安全。
mysql -u root -p
或者
mysql -uroot -p
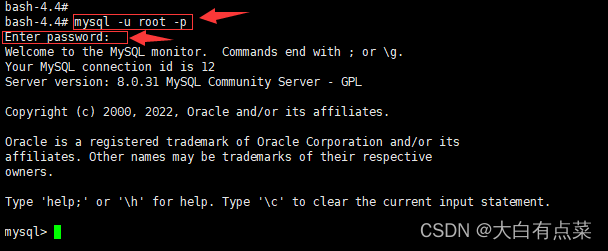
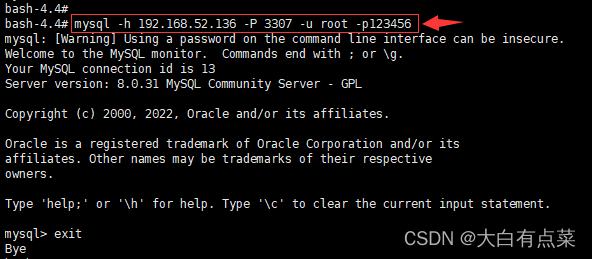
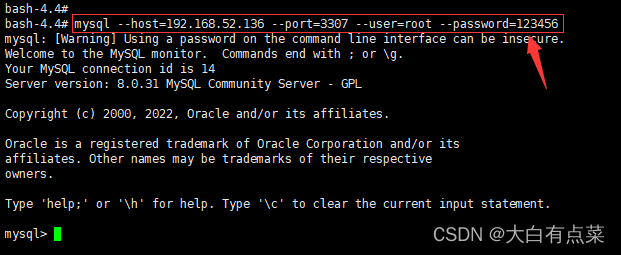
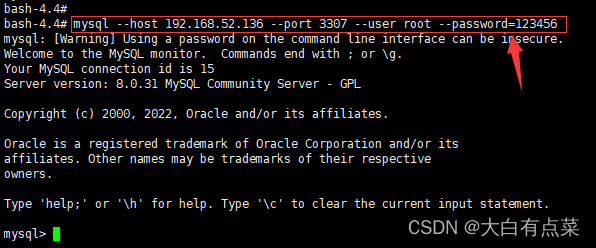
(3)方式三(有些写法很少见):使用 本地MySQL客户端 连接 远程MySQL服务器 ,就是说,可以连接远程任意MySQL服务器,只要参数配置好就行。需要添加 -h 服务器IP 参数和 -P 服务器端口号 参数。此处有3种写法,任意一个即可。
mysql -h 192.168.52.136 -P 3307 -u root -p123456
或者
mysql --host=192.168.52.136 --port=3307 --user=root --password=123456
又或者(注意,--password 后面一定要有“=”)
mysql --host 192.168.52.136 --port 3307 --user root --password=123456
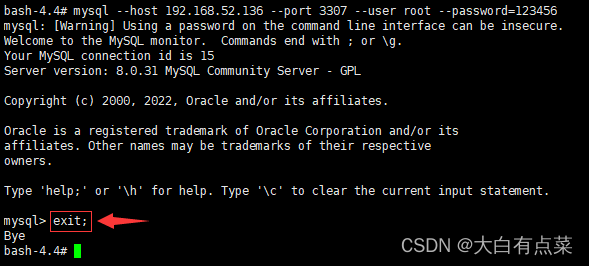
2、MySQL两种方式断开连接
(1)使用 exit; 命令。
exit;
(2)按 Ctrl + D 组合键。

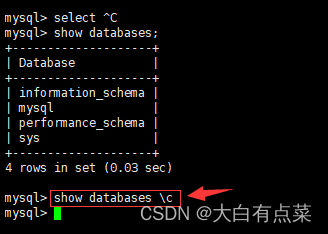
3、撤销命令
(1)按 Ctrl + C 组合键。

(2)使用 \c 命令。
\c
4、连接MySQL时指定要连接的数据库
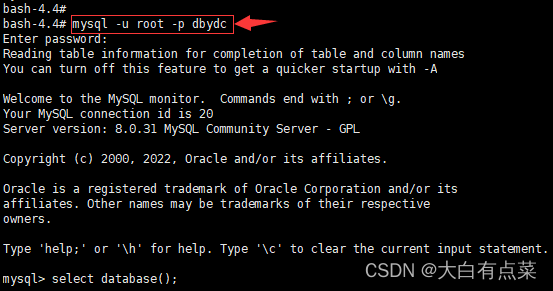
(1)指定数据库,如 dbydc 数据库。
mysql -u root -p dbydc
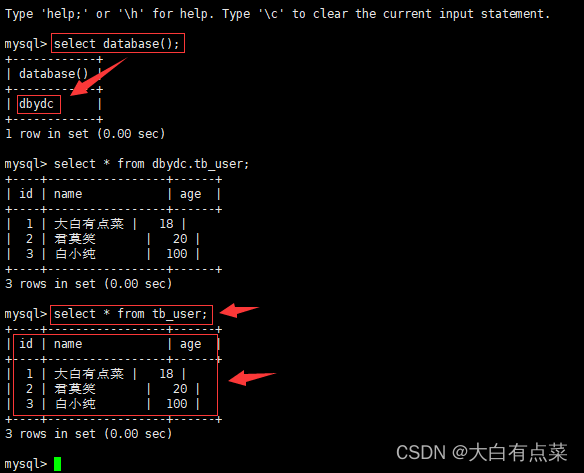
(2)查找连接到了哪个数据库。
select database();
或者
SELECT DATABASE();
5、查询当前的数据目录
show variables like 'datadir';
或者
SHOW VARIABLES LIKE 'datadir';
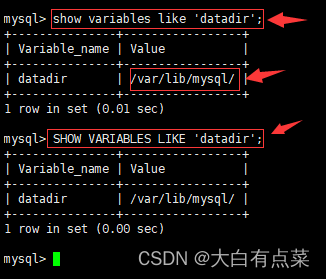
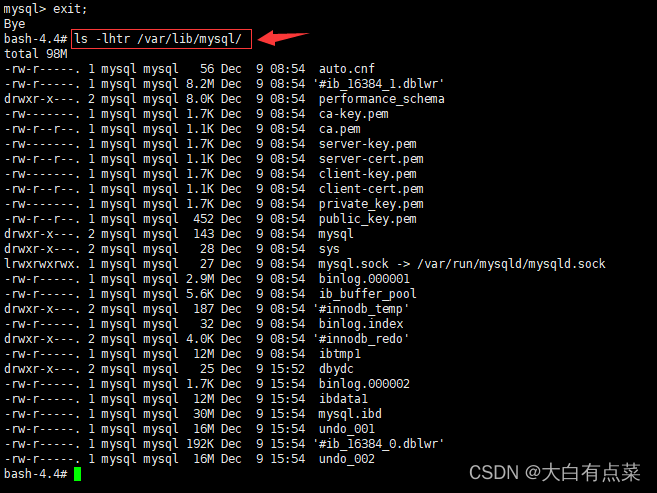
Docker中MySQL8容器的数据目录就是 /var/lib/mysql/ ,如果是在本机中安装MySQL8的,以查询出来的数据目录为准。
6、Shell中检查数据目录(以查询出来的数据目录为准)内的文件
ls -lhtr /var/lib/mysql/
7、数据类型底层虐你千百遍
MySQL官方有关数据类型介绍:https://dev.mysql.com/doc/refman/8.0/en/data-types.html
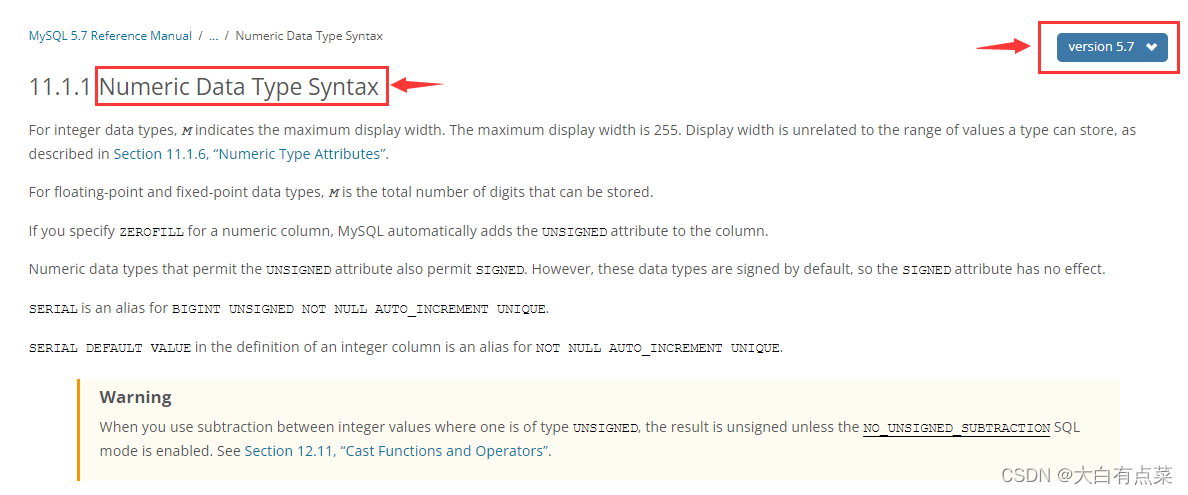
7.1 数字数据类型语法(Numeric Data Type Syntax)你可知道?
【MySQL5.7和MySQL8.0关于数字数据类型语法(Numeric Data Type Syntax)的文档介绍】
https://dev.mysql.com/doc/refman/5.7/en/numeric-type-syntax.html
https://dev.mysql.com/doc/refman/8.0/en/numeric-type-syntax.html
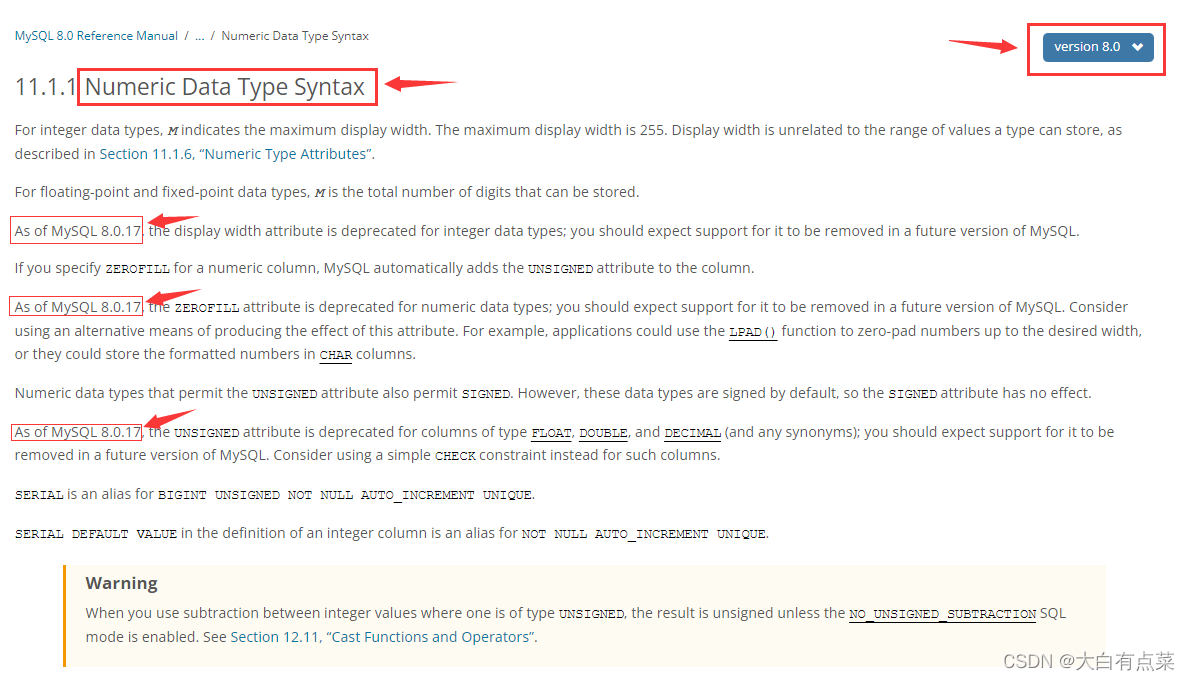
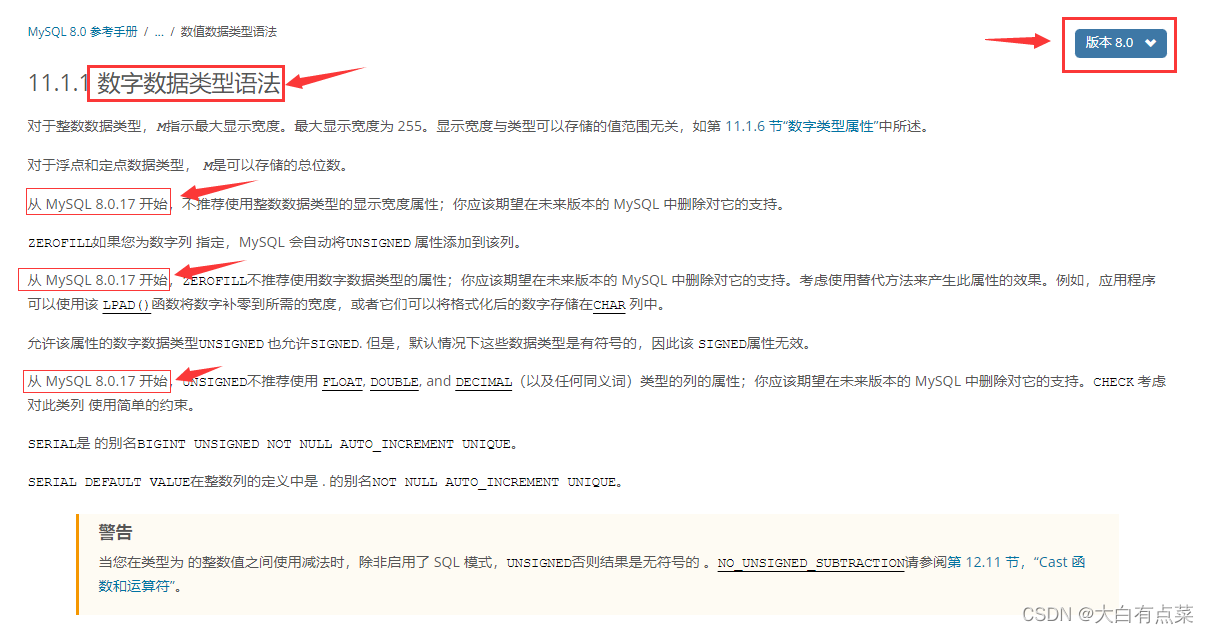
在MySQL8.0中,官方文档说到 数字数据类型语法(Numeric Data Type Syntax)有了一些新的改变,如下:
1、从 MySQL 8.0.17 开始,不推荐使用整数数据类型的显示宽度属性。
2、从 MySQL 8.0.17 开始,ZEROFILL不推荐使用数字数据类型的属性。例如,应用程序可以使用该 LPAD()函数将数字补零到所需的宽度,或者它们可以将格式化后的数字存储在CHAR 列中。
3、从 MySQL 8.0.17 开始,UNSIGNED不推荐使用 FLOAT、DOUBLE 和 DECIMAL(以及任何同义词)类型的列的属性。
(1)什么是显示宽度属性?
显示宽度属性也可以称为数字类型属性(Numeric Type Attributes),是MySQL支持一个扩展,可以在类型的基本关键字后面的括号中选择性地指定整数数据类型的显示宽度。例如 TINYINT(4)、SMALLINT(3)、INT(10) 等等。
【MySQL5.7和MySQL8.0关于数字类型属性(Numeric Type Attributes)的文档介绍】
https://dev.mysql.com/doc/refman/5.7/en/numeric-type-attributes.html
https://dev.mysql.com/doc/refman/8.0/en/numeric-type-attributes.html
(2)正确使用显示宽度属性
官方只是说从 MySQL 8.0.17 开始,不推荐使用整数数据类型的显示宽度属性而已,并不是不能使用,支持使用 ZEROFILL 来填充 0 。笔者认为这个功能很鸡肋,假如设定 tinyint 类型为两个宽度 tinyint(2),整数是 6,只有一个宽度,MySQL就可以使用 ZEROFILL 来填充 0 ,即处理为 06 。你们说,我只认识数值6,给我显示 06 是个啥意思呀,我得到的是个字符串吗?
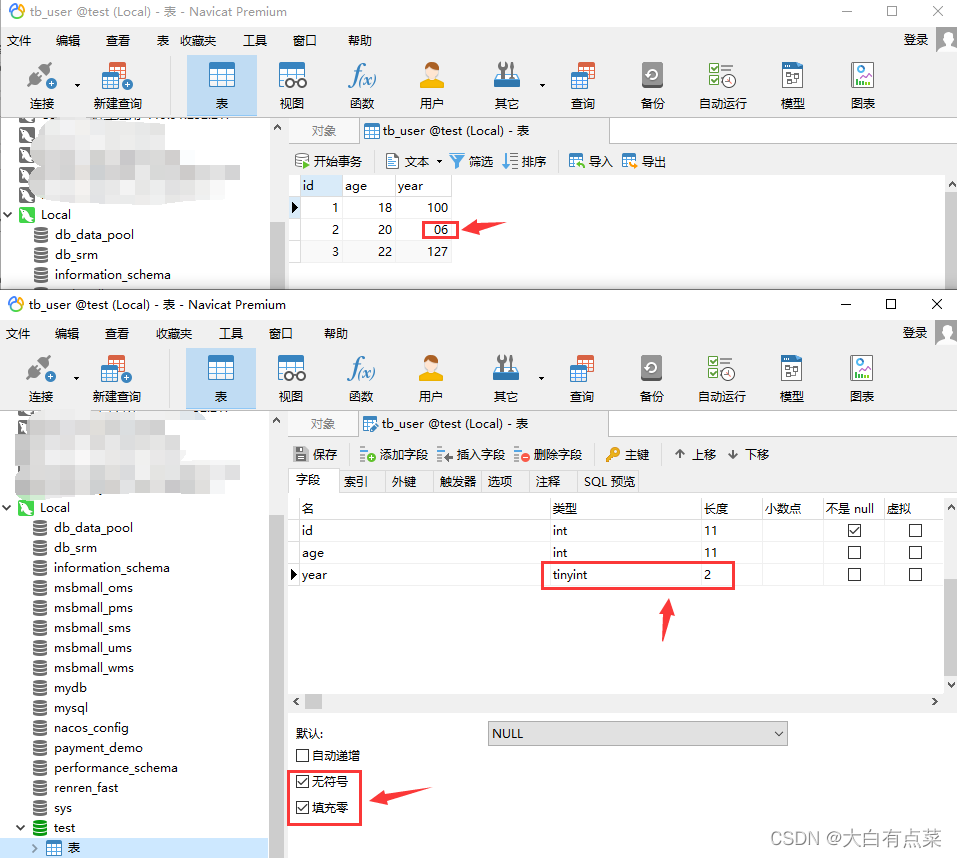
官方文档也说到,如果在指定列中指定 ZEROFILL 属性,那么 MySQL 会自动将 UNSIGNED 属性添加到该列。如图所示。但默认是使用空格填充的,只有指定 ZEROFILL 属性才会使用 0 去填充。

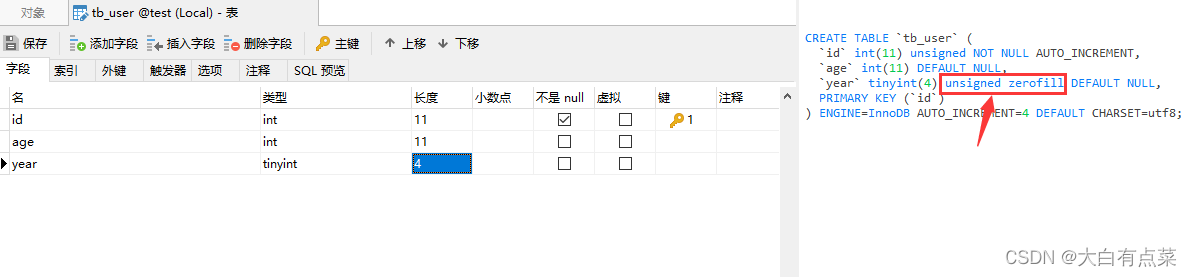
(3)不要乱设置显示宽度属性
显示宽度属性允许设置的最大值是 255 ,如果超过了,就会报错。即使支持设置这么大,也不要随便乱设置,来看个例子就知道了。这里设置 tinyint 显示宽度为 255 ,可以看到,字段 year 对应的数值显示100个0,没错,是100个0!你们说设置255有什么意义,图个好玩吗?
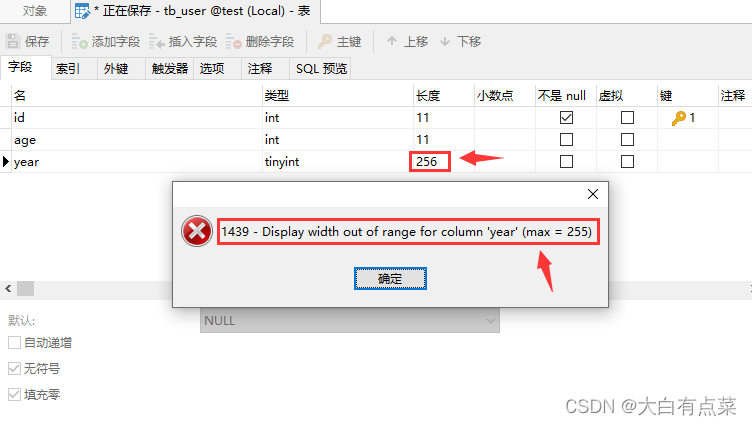
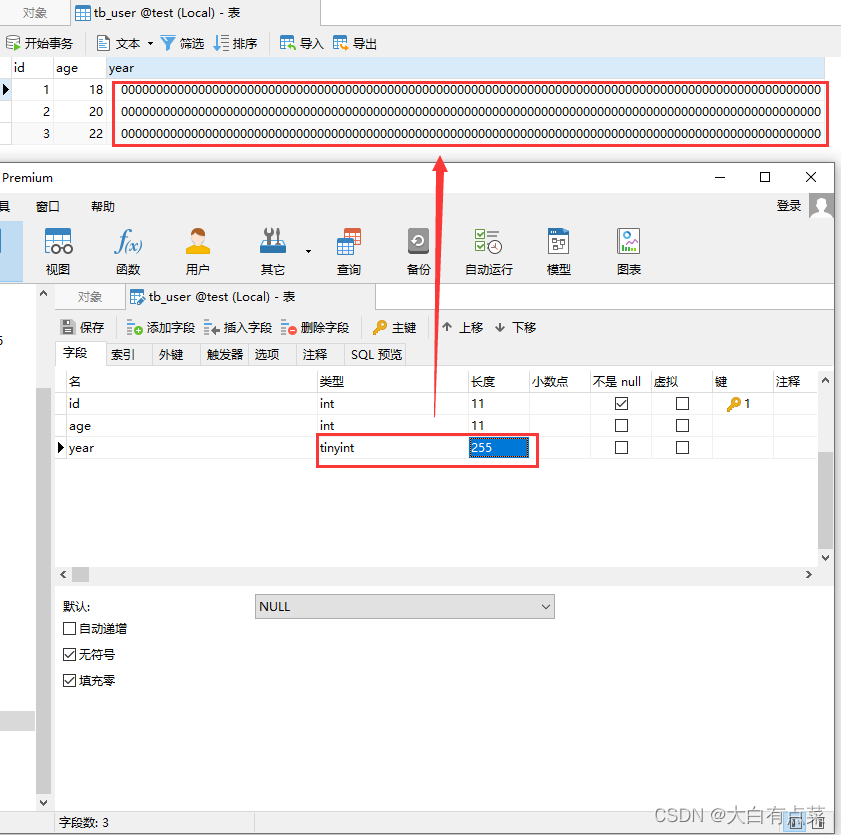
(4)千万不要认为整数类型的显示宽度和整数数据类型范围是一回事,一旦理解错误,很容易犯错导致数据超出值范围!
【整型类型(Integer Types)值范围对比官方文档】
https://dev.mysql.com/doc/refman/8.0/en/integer-types.html
| 数据类型 | 存储(字节) | 有符号最小值 | 无符号最小值 | 有符号最大值 | 无符号最大值 |
|---|---|---|---|---|---|
| TINYINT | 1 | -128 | 0 | 127 | 255 |
| SMALLINT | 2 | -32768 | 0 | 32767 | 65535 |
| MEDIUMINT | 3 | -8388608 | 0 | 8388607 | 16777215 |
| INT | 4 | -2147483648 | 0 | 2147483647 | 4294967295 |
| BIGINT | 8 | -263 | 0 | 263-1 | 264-1 |
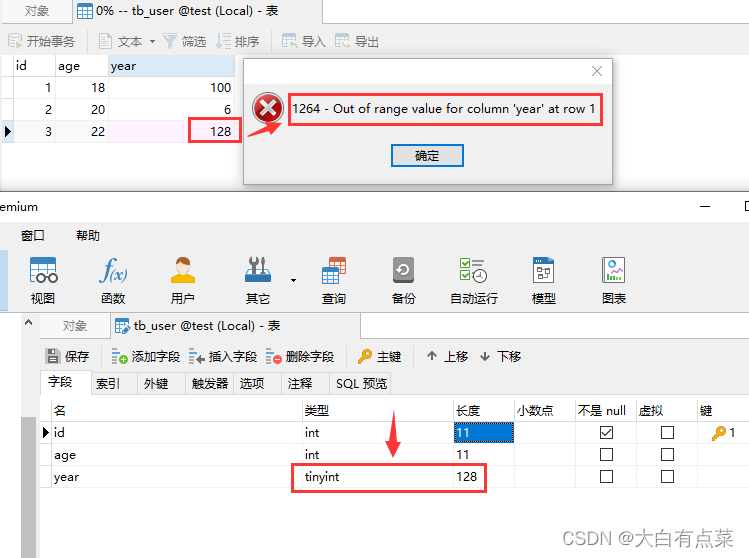
就是说,即使 tinyint 的显示宽度属性设置为 128 ,在有符号的值范围(-128到127)内,tinyint(128) 最大只能存储整数 127 ,如果存入 128 ,则会报超出值范围错误。如下图所示。
7.2 定点类型(Fixed-Point Types):NUMERIC,即 DECIMAL
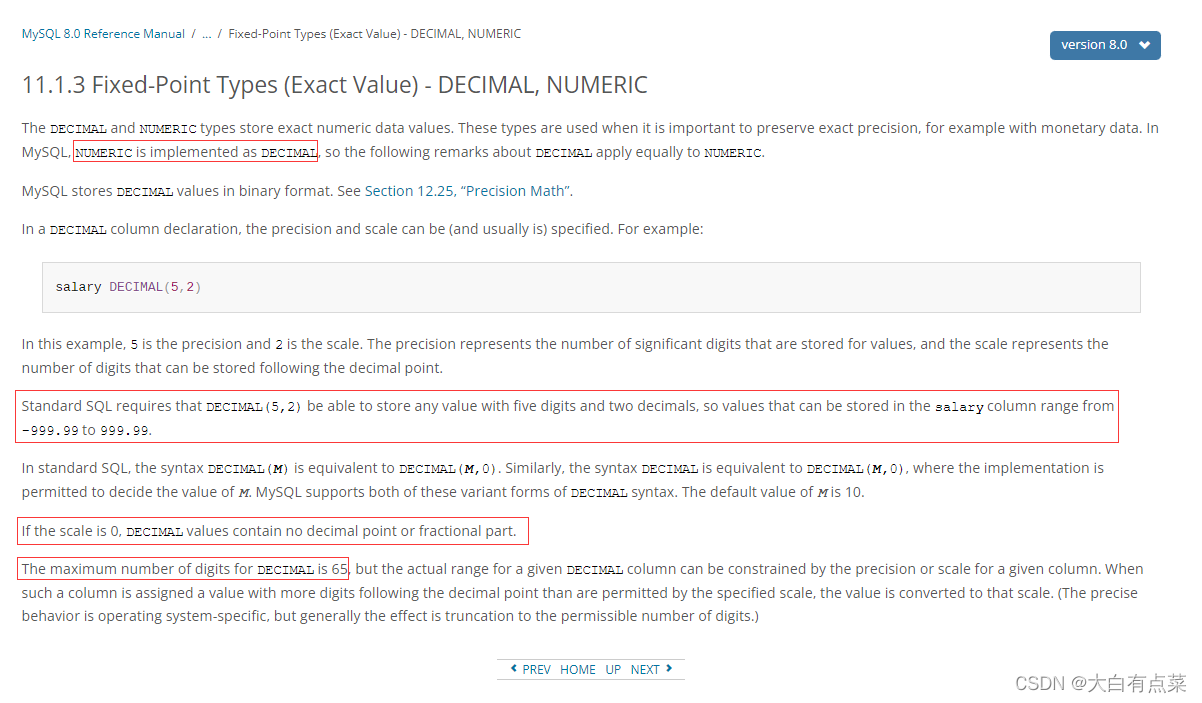
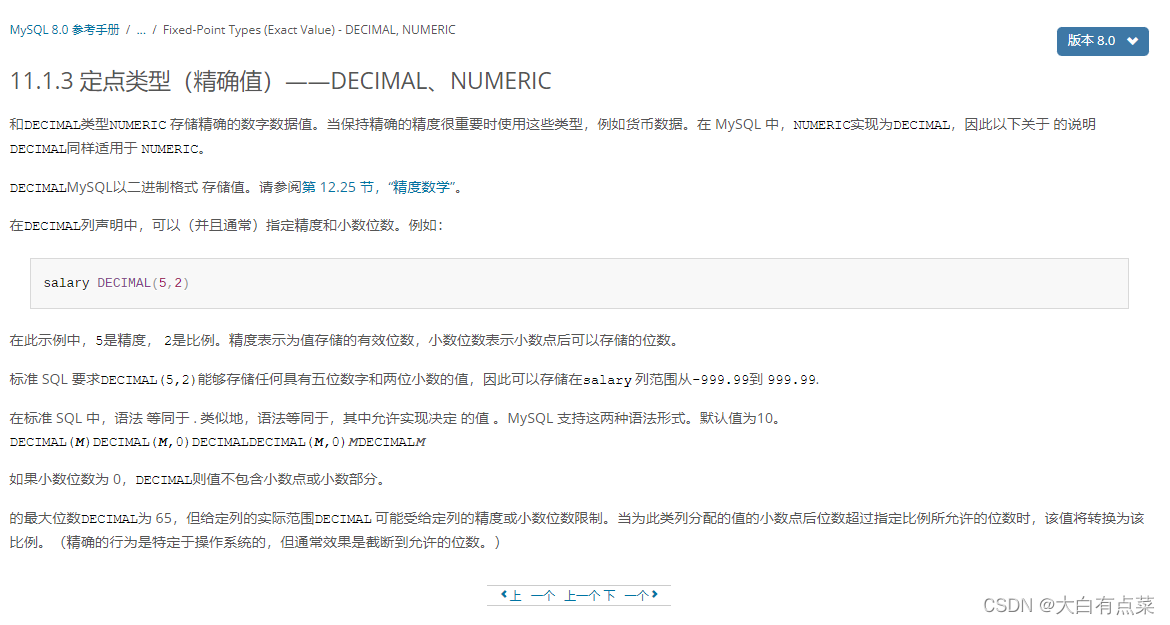
(1)定点类型(Fixed-Point Types):NUMERIC ,精确值。NUMERIC 等价于 DECIMAL,专业说法是 DECIMAL 是 NUMERIC 的实现。DECIMAL 默认最大位数(精度,precision)是 10 ,默认小数点位数(scale)是 0 。最大位数(精度,precision) M 范围为 1 到 65 ,小数点位数(scale) D 范围为 0 到 30 ,整数位数为(M - D),小数点位数为 D 。DECIMAL 使用 二进制格式存储。
DECIMAL(M,D)
例如 DECIMAL(5,2),精度是 5 ,小数位数是 2 ,整数位数是 5 - 2 = 3 ,是怎么在数据库中体现出来的呢?如果精度太小,是会报超出范围错误的。我们先来看看过程操作,那样能更好地理解 DECIMAL 的具体用法。
【附上官方定点类型(Fixed-Point Types)文档介绍链接,和蹩脚的谷歌翻译截图】
https://dev.mysql.com/doc/refman/8.0/en/fixed-point-types.html
笔者使用第三方可视化工具 Navicat 新建的 tb_user 表中有一个 money 字段,数据类型设置为 decimal ,“长度” 和 “小数点” 都不设置数值,保存后,自动默认赋值,“长度”赋值为 10 ,“小数点”赋值为 0 。同时 money 字段的数值显示是没有小数部分的。
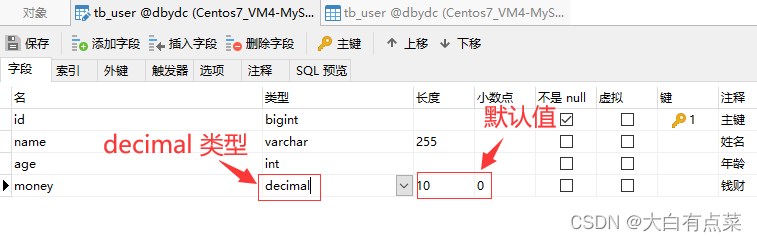
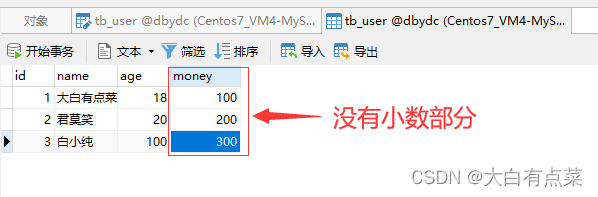
如果将“小数点”设置为 2 ,那么 money 字段的数值显示出现了小数点,并且全是 0。
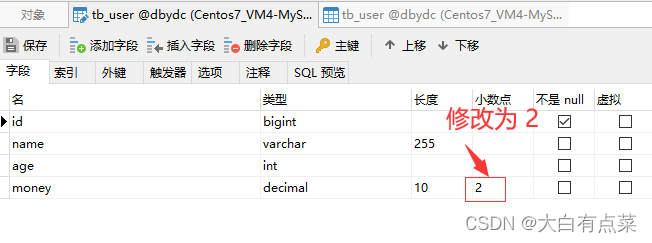
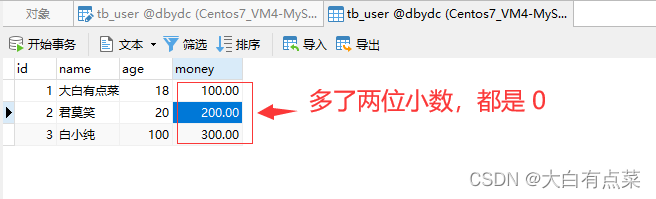
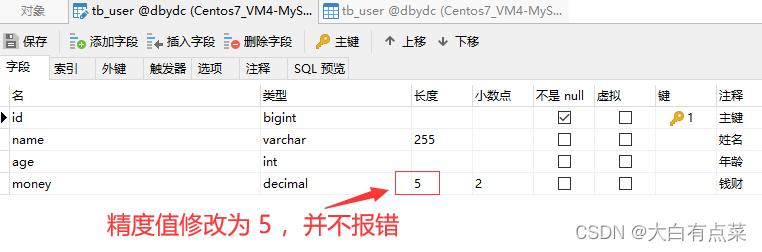
笔者将 money 字段的数值修改为具体的小数,同时将“长度”修改为 5 ,“小数点”修改为 2 ,保存是成功的,并不报错。此时数值的长度一共有5个,包括整数部分3个和小数部分2个,例如 200.02 。
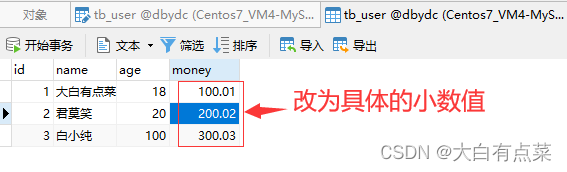
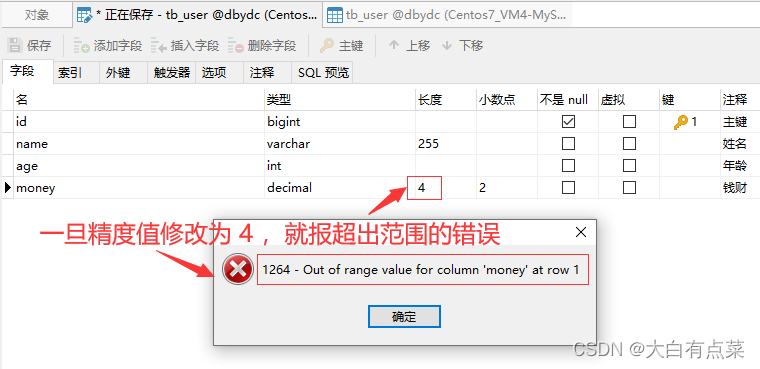
一旦将“长度”修改为 4 ,“小数点”保持 2 不变,再次保存时,立马报错:1264 - Out of range value for column 'money' at row 1 大概意思就是 money 列的值超出范围。这个报错也很容易找到原因,因为前面存储的数值(如200.02)是5位精度的,现在修改为4位精度,肯定会超出范围错误啦!
【定点类型(Fixed-Point Types)总结】
1、如果存储的数值要求精度(长度)特别大,默认值 10 是远远不够用的,不然会报超出值范围异常。不要遗漏设置小数点位数。
2、如果存储的数值要求准确的精度,千万不要使用浮点数(double 或 float)类型,一定要选择定点数(小数)类型(decimal),因为浮点数是近似值,小数才是精确值。有符号整数值不超过 127 ,无符号整数值不超过 255 的建议使用tinyint类型,那样占用空间更小。
3、一定要注意注意再注意,如果小数点位数从 2 设置到 0,再从 0 设置回 2 ,那是会导致具体的小数部分丢失的,即200.02 -> 200 -> 200.00,也就是最后不会变回 200.02 ,而是直接丢失了小数 0.02 那部分而变成了 200.00。
【延伸阅读】
官方文档关于 DECIMAL 数据类型特征介绍:
https://dev.mysql.com/doc/refman/8.0/en/precision-math-decimal-characteristics.html
笔者在查阅相关资料的时候,看到有些博文写到 decimal 的占用字节是如何算出来的,然后笔者也去MySQL官网查询,发现根本不是写的那么一回事?难道别人写的是错误的?现在就来分析一下,看看网上的博客写的有关 decimal 占用字节和官网介绍的有哪些出入。
先贴一部分网上博客的内容截图,如下所示:
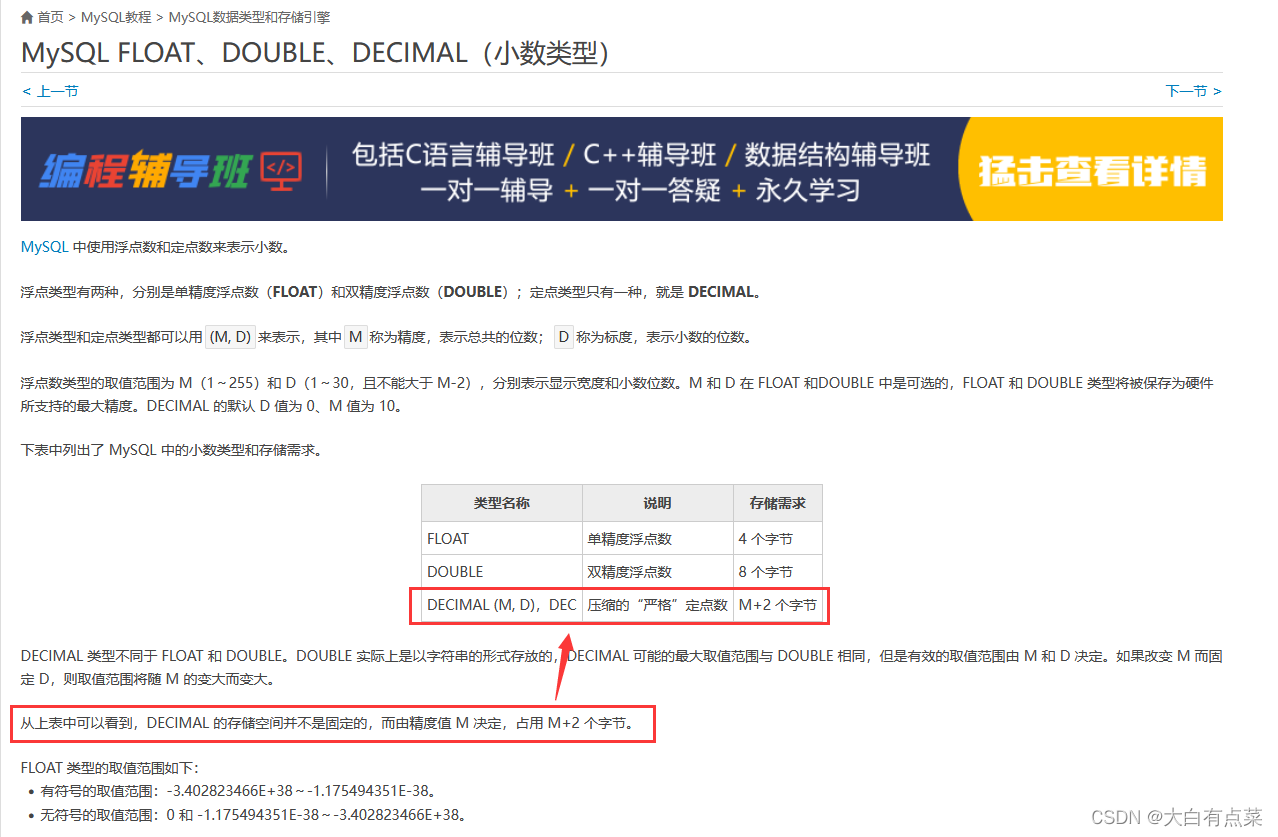
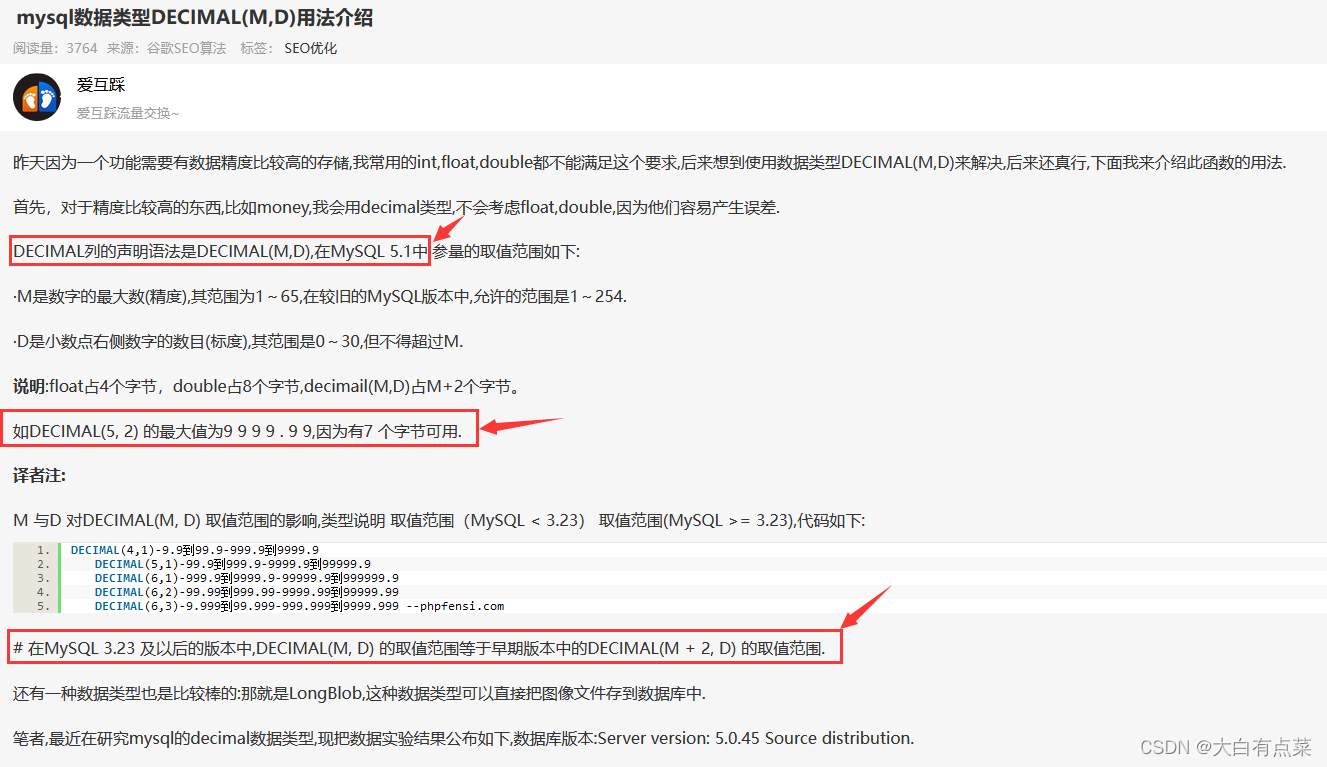

笔者从网上博客,总结出其他博主要表达的几点意思:
(1)
DECIMAL(M,D)是在MySQL 5.1引入的。
(2)DECIMAL(M,D)的占用字节数是M + 2。
真的是这样吗?其实啊,网上有太多太多这样的博客,人云亦云,别人说点东西,自己就把里面的内容当做权威,然后自己也写一篇这样类似的博客,却从来不去探究博客内容有没有问题,传递各种错误信息,这很害人啊!写技术类的文档,应该要以官网文档为根据,要做到博客内容有理有据,不睁眼说瞎话。好了,回归正题,笔者能力也有限,希望广大读者指出错误,一起学习一起进步。
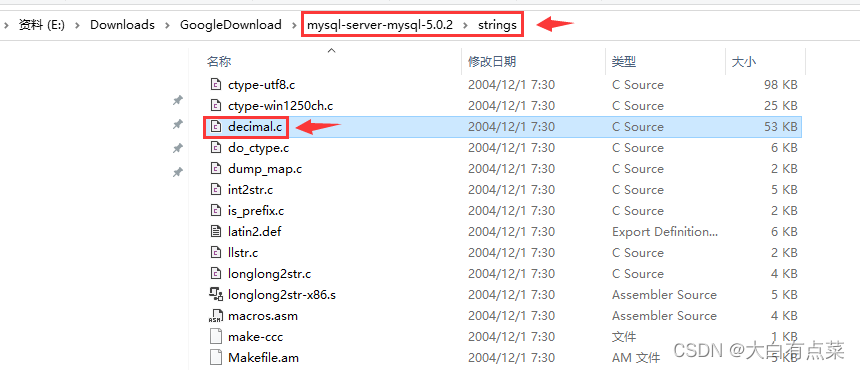
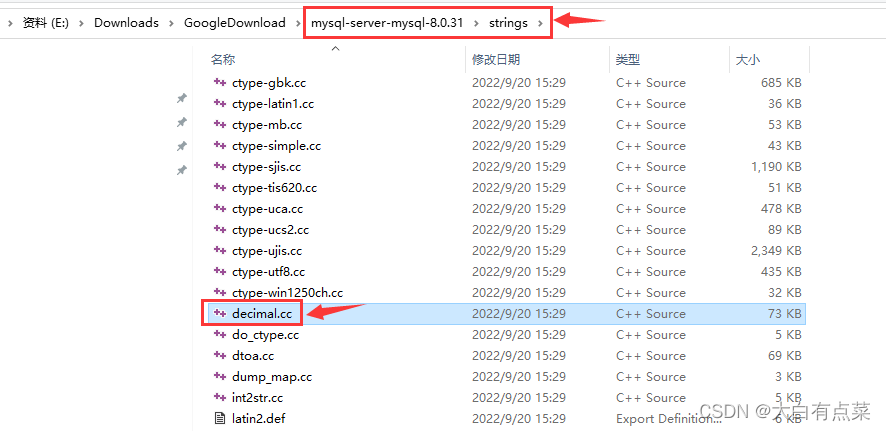
经过笔者研究,DECIMAL(M,D) 是在 MySQL 5 引入的,确切地说,是在 MySQL-5.0.2 版本引入的,一直到最新的 MySQL-8.0.31 ,源代码有经过不少修改,就是说 MySQL-5.0.1 和之前的版本都不存在 DECIMAL(M,D) 。有读者就不服了,你怎么知道的?当然是笔者下载N多版本的源码,一个个去找的呀,找出来 MySQL-5.0.1 并不存在 decimal.c 文件,而是在 MySQL-5.0.2 出现了!
DECIMAL(M,D) 是 decimal.c 或 decimal.cc 中定义的方法,这里需要注意,MySQL-5.0.2 源码包中 decimal.c 文件后缀是“.c”,但在最新的 MySQL-8.0.31 源码包中 decimal.cc 文件后缀却变为了“.cc”。无论是 decimal.c 或 decimal.cc 文件,都是在源码包的 strings 目录下。
github上MySQL各版本源码下载:
mysql-5.0.1源码:https://github.com/mysql/mysql-server/releases/tag/mysql-5.0.1
mysql-5.0.2源码:https://github.com/mysql/mysql-server/releases/tag/mysql-5.0.2
mysql-8.0.31源码:https://github.com/mysql/mysql-server/releases/tag/mysql-8.0.31

那么目前MySQL官网是如何介绍 DECIMAL 数据类型特征的呢?笔者也发现,官网只能查 5.6、5.7和8.0 三个版本的文档,前面低版本的文档查询不到了,不知是移除了还是放到别的位置。
【关于 DECIMAL 数据类型特征的官方文档介绍,从上到下是 8.0 、5.7、5.6】:
https://dev.mysql.com/doc/refman/8.0/en/precision-math-decimal-characteristics.html
https://dev.mysql.com/doc/refman/5.7/en/precision-math-decimal-characteristics.html
https://dev.mysql.com/doc/refman/5.6/en/precision-math-decimal-characteristics.html
官网都是英文,啊啊啊,对于英语差的人,简直是天书而不可窥也!这可难不倒笔者我,特意使用浏览器的谷歌翻译插件为大家友好地服务。谷歌翻译已经退出中国导致正常插件无法使用,但方法总比困难多是吧,只可意会不可言传哦。
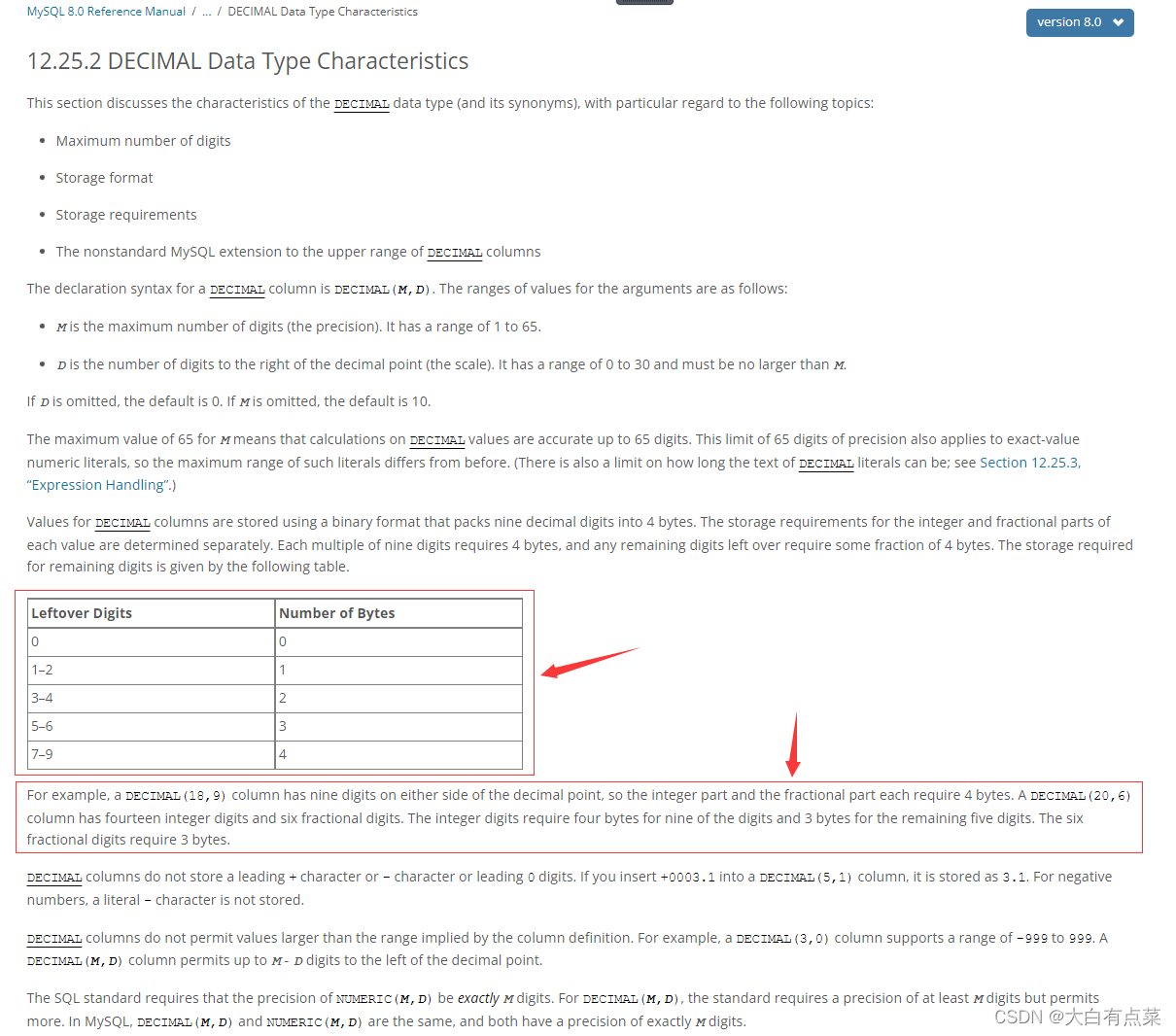
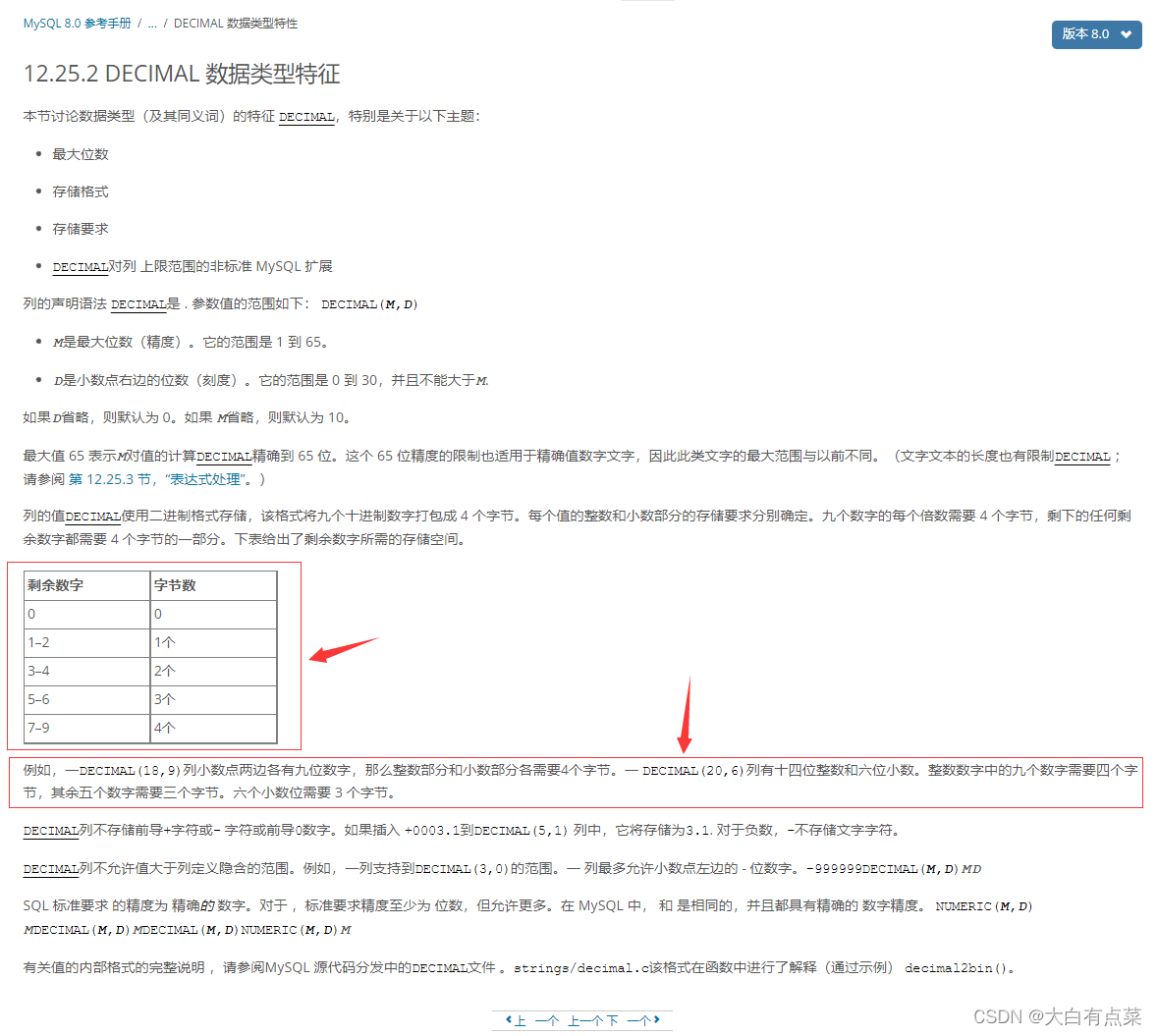
官网中提到,例子 DECIMAL(18,9) 中,整数部分有(18 - 9 = 9)个数字,小数部分有9个数字,那么9个数字占用4字节,两部分一共占用(4 + 4 = 8)字节。再来一个例子,DECIMAL(20,6) 中整数部分有14个数字,小数部分只有6个数字,14拆分为9和5,由于剩余数字个数是5到6之间,所以占用3字节,DECIMAL(20,6) 总的占用字节为(4 + 3 + 3 = 10)。
| 剩余数字 | 字节数 |
|---|---|
| 0 | 0 |
| 1-2 | 1个 |
| 3-4 | 2个 |
| 5-6 | 3个 |
| 7-9 | 4个 |
难道其它博客中写到的 DECIMAL(M,D) 占用字节为 M+2 是错误的吗?按那些博客的逻辑,DECIMAL(18,9)占用字节应该为20字节,DECIMAL(20,6)占用字节应该为22字节了,这和官方文档说的完全不一样啊!
其实,笔者认为,那些博客中写到的关于 DECIMAL 字节占用计算不一定就是错误的,应该旧版本就是这么处理的,不然总不能空穴来风,乱说一通吧?随着版本升级,有些数值逻辑处理可能导致各种问题,官方肯定是要优化算法的。笔者只能说,那些博客都是各种抄,有些东西过时了,也不自己去研究一下。学习就要紧跟时代步伐,多看看官方文档才能掌握更多新知识,不要随便将别人的文章当权威!
MySQL源码中,DECIMAL(M,D) 是怎么将 decimal 转换为 二进制 的呢?由于 decimal.c 或 decimal.cc 是用 c++ 去写的,这门编程语言笔者早就还给大一老师了,所以也看不懂,但是方法上面的注解中有个例子,可以拿出来讲解,相信读者们都能容易理解 decimal 转换为 二进制 的过程。
【MySQL-8.0.31源码中的 decimal.cc 文件中的 decimal2bin 方法核心代码】:
/*
Convert decimal to its binary fixed-length representation
two representations of the same length can be compared with memcmp
with the correct -1/0/+1 result
SYNOPSIS
decimal2bin()
from - value to convert
to - points to buffer where string representation should be stored
precision/scale - see decimal_bin_size() below
NOTE
the buffer is assumed to be of the size decimal_bin_size(precision, scale)
RETURN VALUE
E_DEC_OK/E_DEC_TRUNCATED/E_DEC_OVERFLOW
DESCRIPTION
for storage decimal numbers are converted to the "binary" format.
This format has the following properties:
1. length of the binary representation depends on the {precision, scale}
as provided by the caller and NOT on the intg/frac of the decimal to
convert.
2. binary representations of the same {precision, scale} can be compared
with memcmp - with the same result as decimal_cmp() of the original
decimals (not taking into account possible precision loss during
conversion).
This binary format is as follows:
1. First the number is converted to have a requested precision and scale.
2. Every full DIG_PER_DEC1 digits of intg part are stored in 4 bytes
as is
3. The first intg % DIG_PER_DEC1 digits are stored in the reduced
number of bytes (enough bytes to store this number of digits -
see dig2bytes)
4. same for frac - full decimal_digit_t's are stored as is,
the last frac % DIG_PER_DEC1 digits - in the reduced number of bytes.
5. If the number is negative - every byte is inversed.
5. The very first bit of the resulting byte array is inverted (because
memcmp compares unsigned bytes, see property 2 above)
Example:
1234567890.1234
internally is represented as 3 decimal_digit_t's
1 234567890 123400000
(assuming we want a binary representation with precision=14, scale=4)
in hex it's
00-00-00-01 0D-FB-38-D2 07-5A-EF-40
now, middle decimal_digit_t is full - it stores 9 decimal digits. It goes
into binary representation as is:
........... 0D-FB-38-D2 ............
First decimal_digit_t has only one decimal digit. We can store one digit in
one byte, no need to waste four:
01 0D-FB-38-D2 ............
now, last digit. It's 123400000. We can store 1234 in two bytes:
01 0D-FB-38-D2 04-D2
So, we've packed 12 bytes number in 7 bytes.
And now we invert the highest bit to get the final result:
81 0D FB 38 D2 04 D2
And for -1234567890.1234 it would be
7E F2 04 C7 2D FB 2D
*/
int decimal2bin(const decimal_t *from, uchar *to, int precision, int frac) {
dec1 mask = from->sign ? -1 : 0, *buf1 = from->buf, *stop1;
int error = E_DEC_OK, intg = precision - frac, isize1, intg1, intg1x,
from_intg, intg0 = intg / DIG_PER_DEC1, frac0 = frac / DIG_PER_DEC1,
intg0x = intg - intg0 * DIG_PER_DEC1,
frac0x = frac - frac0 * DIG_PER_DEC1, frac1 = from->frac / DIG_PER_DEC1,
frac1x = from->frac - frac1 * DIG_PER_DEC1,
isize0 = intg0 * sizeof(dec1) + dig2bytes[intg0x],
fsize0 = frac0 * sizeof(dec1) + dig2bytes[frac0x],
fsize1 = frac1 * sizeof(dec1) + dig2bytes[frac1x];
const int orig_isize0 = isize0;
const int orig_fsize0 = fsize0;
uchar *orig_to = to;
buf1 = remove_leading_zeroes(from, &from_intg);
if (unlikely(from_intg + fsize1 == 0)) {
mask = 0; /* just in case */
intg = 1;
buf1 = &mask;
}
intg1 = from_intg / DIG_PER_DEC1;
intg1x = from_intg - intg1 * DIG_PER_DEC1;
isize1 = intg1 * sizeof(dec1) + dig2bytes[intg1x];
if (intg < from_intg) {
buf1 += intg1 - intg0 + (intg1x > 0) - (intg0x > 0);
intg1 = intg0;
intg1x = intg0x;
error = E_DEC_OVERFLOW;
} else if (isize0 > isize1) {
while (isize0-- > isize1) *to++ = (char)mask;
}
if (fsize0 < fsize1) {
frac1 = frac0;
frac1x = frac0x;
error = E_DEC_TRUNCATED;
} else if (fsize0 > fsize1 && frac1x) {
if (frac0 == frac1) {
frac1x = frac0x;
fsize0 = fsize1;
} else {
frac1++;
frac1x = 0;
}
}
/* intg1x part */
if (intg1x) {
int i = dig2bytes[intg1x];
dec1 x = mod_by_pow10(*buf1++, intg1x) ^ mask;
switch (i) {
case 1:
mi_int1store(to, x);
break;
case 2:
mi_int2store(to, x);
break;
case 3:
mi_int3store(to, x);
break;
case 4:
mi_int4store(to, x);
break;
default:
assert(0);
}
to += i;
}
/* intg1+frac1 part */
for (stop1 = buf1 + intg1 + frac1; buf1 < stop1; to += sizeof(dec1)) {
dec1 x = *buf1++ ^ mask;
assert(sizeof(dec1) == 4);
mi_int4store(to, x);
}
/* frac1x part */
if (frac1x) {
dec1 x;
int i = dig2bytes[frac1x], lim = (frac1 < frac0 ? DIG_PER_DEC1 : frac0x);
while (frac1x < lim && dig2bytes[frac1x] == i) frac1x++;
x = div_by_pow10(*buf1, DIG_PER_DEC1 - frac1x) ^ mask;
switch (i) {
case 1:
mi_int1store(to, x);
break;
case 2:
mi_int2store(to, x);
break;
case 3:
mi_int3store(to, x);
break;
case 4:
mi_int4store(to, x);
break;
default:
assert(0);
}
to += i;
}
if (fsize0 > fsize1) {
uchar *to_end = orig_to + orig_fsize0 + orig_isize0;
while (fsize0-- > fsize1 && to < to_end) *to++ = (uchar)mask;
}
orig_to[0] ^= 0x80;
/* Check that we have written the whole decimal and nothing more */
assert(to == orig_to + orig_fsize0 + orig_isize0);
return error;
}
使用谷歌进行 decimal2bin 方法上标注的注解翻译,得到以下内容。
将十进制转换为其二进制固定长度表示相同长度的两个表示可以用 memcmp 进行比较正确的 -1/0/+1 结果
概要(SYNOPSIS)
decimal2bin()
from - 要转换的值
to - 指向应存储字符串表示的缓冲区
精度/比例 - 请参见下面的 decimal_bin_size()
笔记(NOTE)
假定缓冲区的大小为 decimal_bin_size(precision, scale)
返回值(RETURN VALUE)
E_DEC_OK/E_DEC_TRUNCATED/E_DEC_OVERFLOW
描述(DESCRIPTION)
用于存储的十进制数被转换为“二进制”格式。
此格式具有以下属性:
1.二进制表示的长度取决于{precision, scale}由调用者提供,而不是在小数点的 intg/frac 上转换。
2. 可以将相同 {precision, scale} 的二进制表示与 memcmp 进行比较 - 结果与原始小数的 decimal_cmp() 相同
(不考虑转换过程中可能出现的精度损失)。
这个二进制格式如下:
1.首先将数字转换为具有要求的精度和小数位数。
2.intg 部分的每个完整 DIG_PER_DEC1 数字都按原样存储在 4 个字节中。
3.第一个 intg % DIG_PER_DEC1 数字存储在减少的字节数中(足够的字节来存储这个数字(digits)数量——见 dig2bytes)
4.对于 frac 也是如此 - 完整的 decimal_digit_t 按原样存储,最后一个 frac % DIG_PER_DEC1 数字 - 在减少的字节数中。
5.如果数字是负数 - 每个字节都被反转。
5.结果字节数组的第一位被反转(因为 memcmp 比较无符号字节,参见上面的属性 2)。
笔者将注解中的例子抽出来,使用谷歌进行翻译,得到以下内容。
例子:
1234567890.1234
内部表示为 3 个 decimal_digit_t
1234567890123400000
(假设我们想要一个精度为 14,比例为 4 的二进制表示)
十六进制是
00-00-00-010D-FB-38-D207-5A-EF-40
现在,中间的 decimal_digit_t 已满 - 它存储 9 个十进制数字。 它去按原样转换为二进制表示形式:
…0D-FB-38-D2…
第一个 decimal_digit_t 只有一个十进制数字。 我们可以存储一个数字一个字节,不需要浪费四个:
010D-FB-38-D2…
现在,最后一位。 它是123400000。我们可以用两个字节存储1234:
010D-FB-38-D204-D2
所以,我们在 7 个字节中打包了 12 个字节的数字。
现在我们反转最高位以获得最终结果:
810DFB38D204D2
对于-1234567890.1234它将是
7EF204C72DFB2D
例子中,将 1234567890.1234 这个定点数分解为三部分:1、234567890、1234 ,每部分凑够9个数字,不够的就补0,最后得到以下新的三部分:1、234567890、123400000。我们可以使用第三方网站在线进制转换,如 oschina.net 中的在线进制转换:https://tool.oschina.net/hexconvert 。
将十进制的 1 转换为 十六进制 形式,得到结果为 1 ,可以写作:00-00-00-01 。
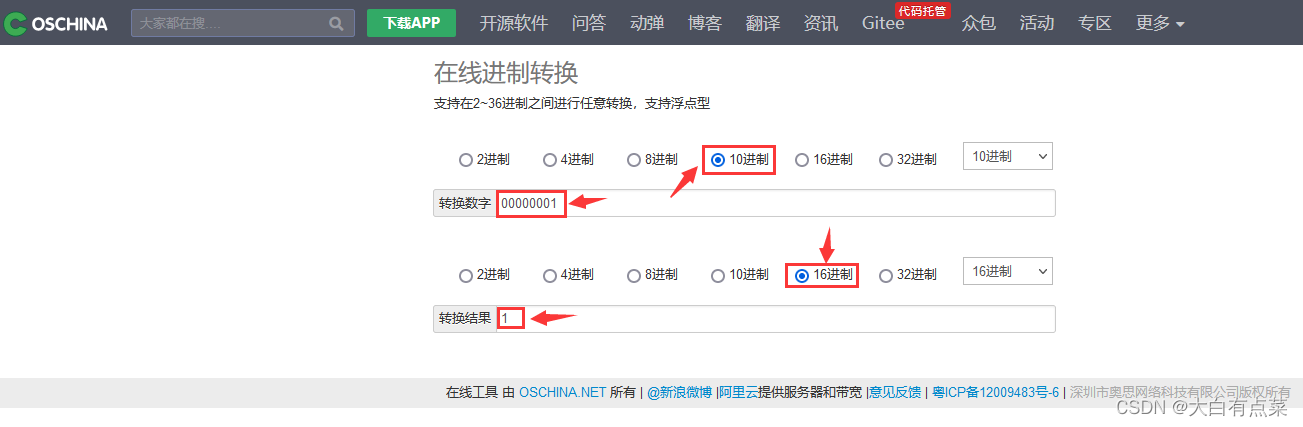
将十进制的 234567890 转换为 十六进制 形式,得到结果为 dfb38d2 ,可以写作:0D-FB-38-D2 。
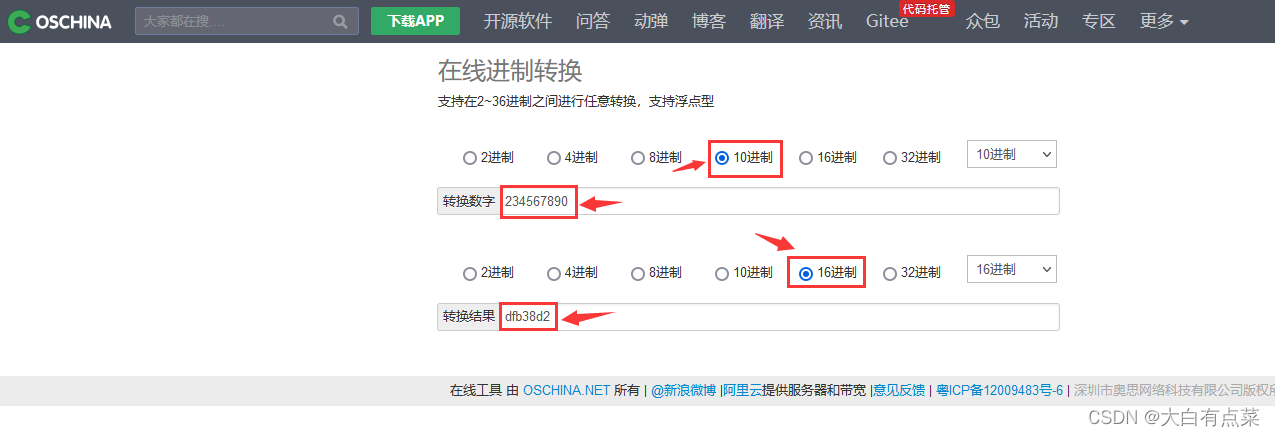
将十进制的 123400000 转换为 十六进制 形式,得到结果为 75aef40 ,可以写作:07-5A-EF-40 。
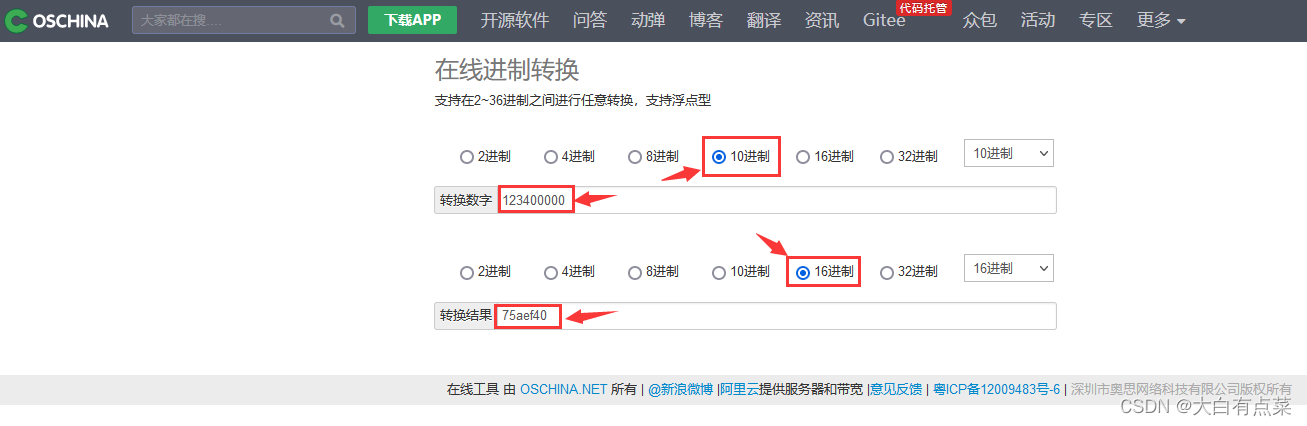
00-00-00-01 如果使用4个字节存储会很浪费,只有一个数字1,使用1个字节存储就可以了。
0D-FB-38-D2 使用4个字节存储。
1234 只有4个数字,如果使用4个字节存储也很浪费,所以直接对 1234 进行 十六进制转换,如下图所示,得到 4d2 ,写作:04-D2 。这样使用2个字节存储。
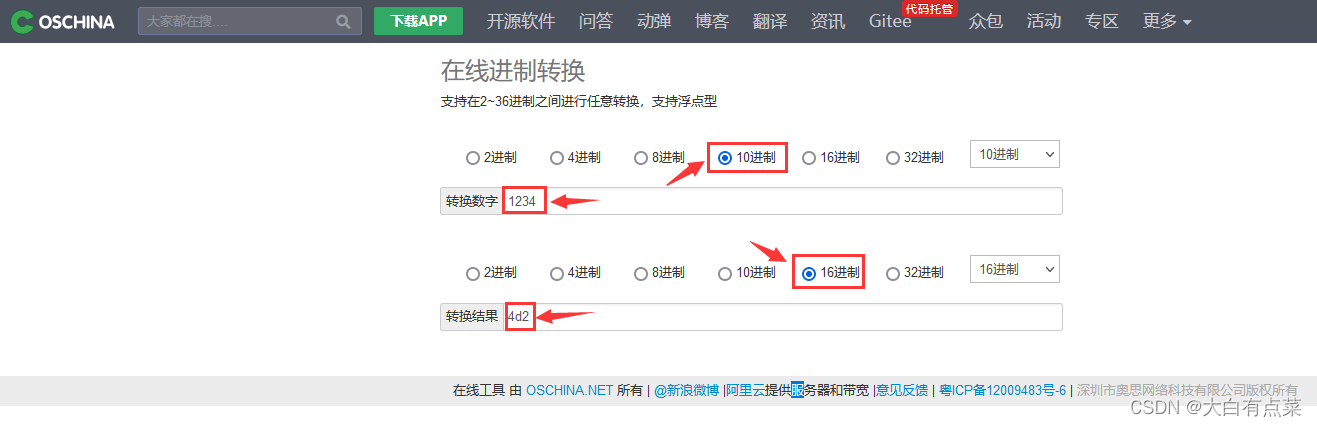
由上面的结果,得到:01 0D FB 38 D2 04 D2 ,这还不是最终的结果,还需要对最高位(01)进行反转。如何反转呢?使用(10000000)和 01 的二进制(00000001)进行异或运算,0 + 0 = 0,0 + 1 = 1,1 + 0 = 1,1 + 1 = 0,最终得到二进制数 10000001 ,转换为 十六进制 ,得到结果:81 。
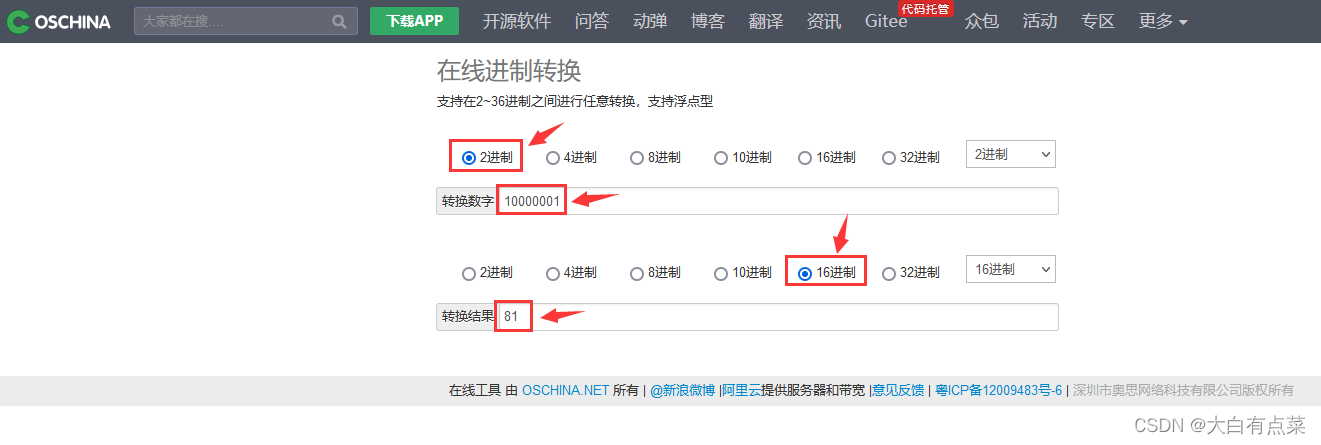
最终结果是:81 0D FB 38 D2 04 D2 。使用 1 + 4 + 2 = 7 个字节就实现了 1234567890.1234 的存储。
如果是负数 -1234567890.1234 呢?
同样将负数 -1234567890.1234 分解为三个部分,先忽略前面的负号。由正数的处理过程,同样得到 01 0D FB 38 D2 04 D2 7个十六进制数。负数的反转稍微复杂,如下表所示。
| 十六进制数 | 转换为二进制数 | 负数是所有二进制数最高位取反得到负数原码 |
负数反码是原码的最高位不变,其它位取反 |
反码对应的十六进制 | 最高位再取反(反转) | 最终结果(十六进制) |
|---|---|---|---|---|---|---|
| 01 | 00000001 | 10000001 | 11111110 | FE | 01111110,即 7E | 7E |
| 0D | 00001101 | 10001101 | 11110010 | F2 | F2 |
|
| FB | 11111011 | 01111011 | 00000100 | 04 | 04 |
|
| 38 | 00111000 | 10111000 | 11000111 | C7 | C7 |
|
| D2 | 11010010 | 01010010 | 00101101 | 2D | 2D |
|
| 04 | 00000100 | 10000100 | 11111011 | FB | FB |
|
| D2 | 11010010 | 01010010 | 00101101 | 2D | 2D |
负数 -1234567890.1234 的最终结果为:7E F2 04 C7 2D FB 2D 。
8、克隆表结构
克隆一个表的结构到新表中。
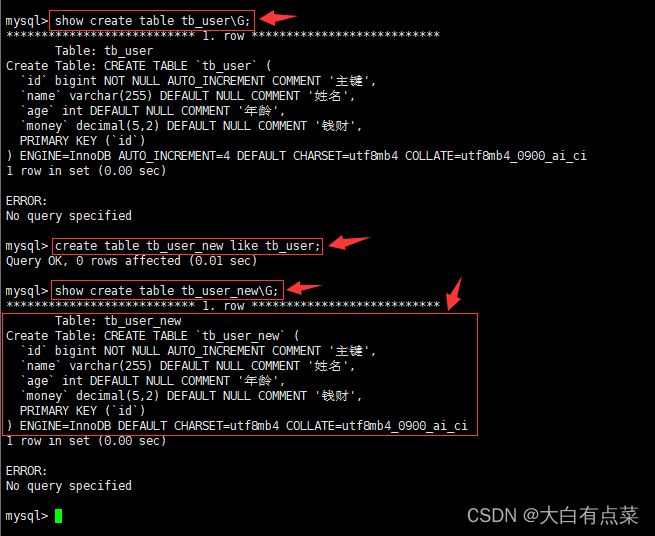
(1)从旧表 tb_user 克隆表结构到新表 tb_user_new 。
create table tb_user_new like tb_user;
(2)查看新建的表 tb_user_new 结构。
show create table tb_user_new\G;
9、ignore 在 insert 语句中的应用
大家对 insert 语句都很熟悉了,插入数据嘛,但是,有搭配关键字 ignore(忽略)使用过吗,有了解过不加 ignore 和加了 ignore 的区别吗?
(1)笔者在数据库 dbydc 中的 tb_user 表插入好了3条数据,第3条数据的主键 id 是 3 ,现在使用基本的 insert 语句插入一条新的数据,要插入的新数据中,字段 id 的值也为 3 ,不加 ignore 关键字,看看是否能正确插入。
insert into tb_user(id, name, age, money) values (3, 'helloworld', 26, 0);
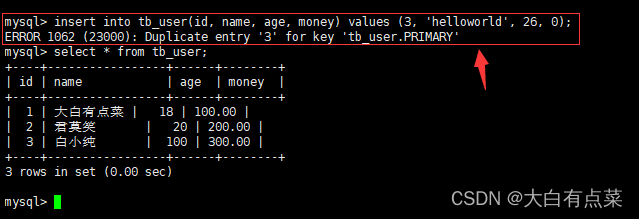
可以看到,普通的 insert into 语句会直接报主键重复的错误,数据不会被插入。
(2)在普通 insert 基础上加 ignore 关键字,再看看是否能正确插入,结果又是怎样。
insert ignore into tb_user(id, name, age, money) values (3, 'helloworld', 26, 0);
show warnings;
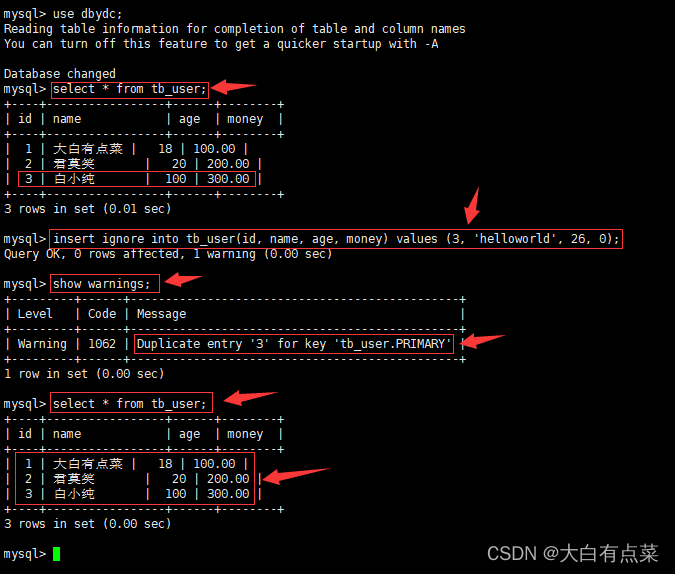
添加 ignore 关键字后,不报主键重复的错误了,但是会提示0行受影响(0 rows affected),1个警告(1 warning)。使用“show warnings;”语句查看警告内容,可以看到,信息(Message)中内容为:主键id为3的数据重复了。再去查看 tb_user 表数据,发现数据也是没有正确插入。
由此得出结论,如果该行已存在,关键字 ignore 会忽略新数据,insert 语句仍然会执行成功,同时生成一个警告和重复数据的数目。不使用 ignore 关键字,则 insert 语句会生成一条错误信息。
这只是插入一条数据的情况,那如果插入多条数据,普通方式 insert 和添加关键字 ignore 的 insert 又是怎样的效果呢?那就来验证吧!
(3)普通 insert 多条数据,看看若一条数据插入报错,其它数据会不会受影响。
insert into tb_user(id, name, age, money) values (3, 'hello', 26, 0),(4, 'world', 28, 66);
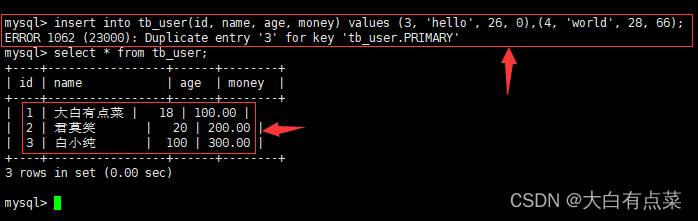
从结果看到,普通 insert 方式插入多条数据,报主键重复的错误了,要插入 id 为 4 的数据也未能正确插入。
(4)再来看看添加 ignore 关键字的 insert 语句执行插入多条数据,能正确插入吗?
insert ignore into tb_user(id, name, age, money) values (3, 'hello', 26, 0),(4, 'world', 28, 66);
show warnings;
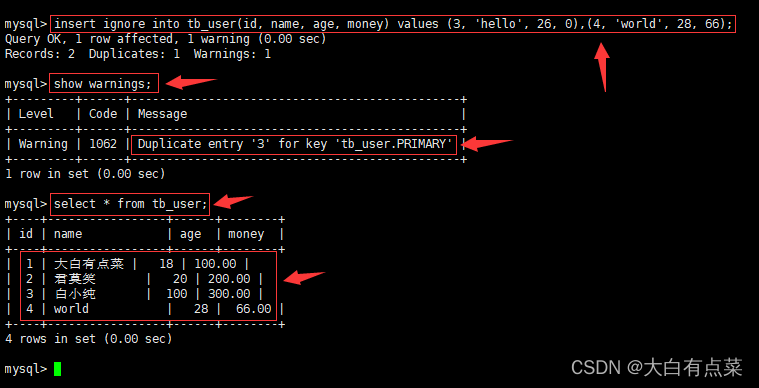
和普通 insert 方式插入多条数据的结果不同,我们清楚地看到,虽然新数据中 id 为 3 的那条数据插入是失败的,但是 id 为 4 的数据却能正确插入,说明 ignore 只忽略错误的数据,并不影响其它正常的数据。
(5)总结
1、普通 insert 方式一旦某条数据有错误,会导致其它数据插入失败,生成一条错误信息,这里指同一条 insert 语句。
2、添加关键字 ignore 的 insert 语句,只忽略错误的数据,并不影响其它正确数据的插入。如果该行已存在,关键字 ignore 会忽略新数据,insert 语句仍然会执行成功,同时生成一个警告和重复数据的数目。
10、 replace 语句应用和 insert 语句中 on duplicate key update 的应用
在某些情况下,我们要对表中重复数据进行处理,例如重复数据覆盖。很多人说了,这还不简单,使用 update 语句更新不就完了吗?这样做当然是可以的,但是,不仅仅 update 语句能做到,replace 和 insert 语句同样可以做到覆盖重复数据的效果,你,会用吗?replace 和 on duplicate key update 作为主角要登场了!
(1)replace 语句使用。
replace into tb_user values (4, 'java', 27, 90);
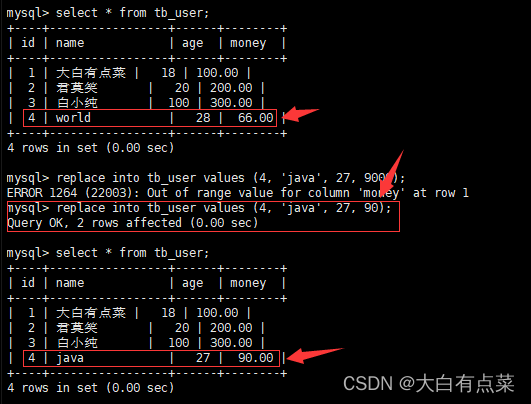
执行 replace 语句,发现有2行受影响(2 rows affected),明明只操作一条数据呀,应该是1行受影响,为什么会出现2行受影响的情况?因为,如果行已经存在,则 replace 语句先简单地删除该行,再插入新行,一共两个步骤,所以我们看到是2行受影响而不是1行受影响。
如果 replace 语句处理的是多条数据,结果又是怎样的呢?如下所示。
replace into tb_user values (4, 'java', 27, 100), (5, 'c', 32, 55);
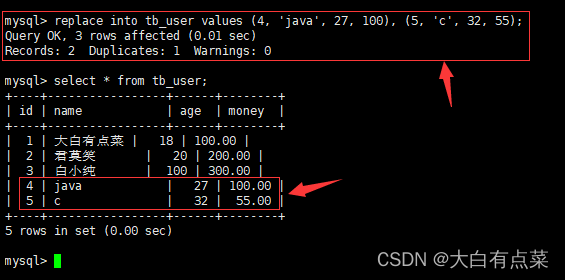
使用 replace 语句处理多条数据,发现 3 行受影响。主键 id 为 4 的数据依然是先简单删除重复行,再插入新行,一共 2 行受影响。主键 id 为 5 的数据是直接插入新行,1 行受影响,效果等同于 insert 语句。总共 3 行受影响。
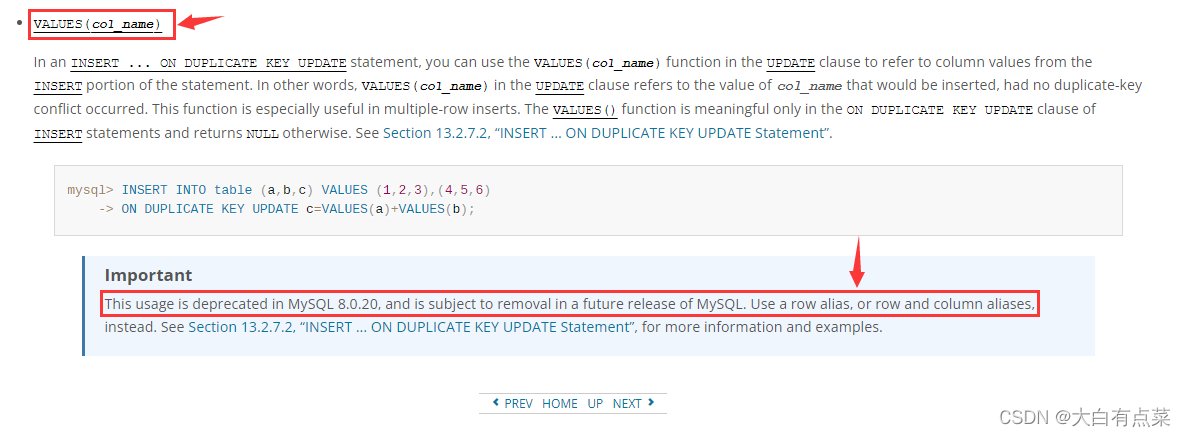
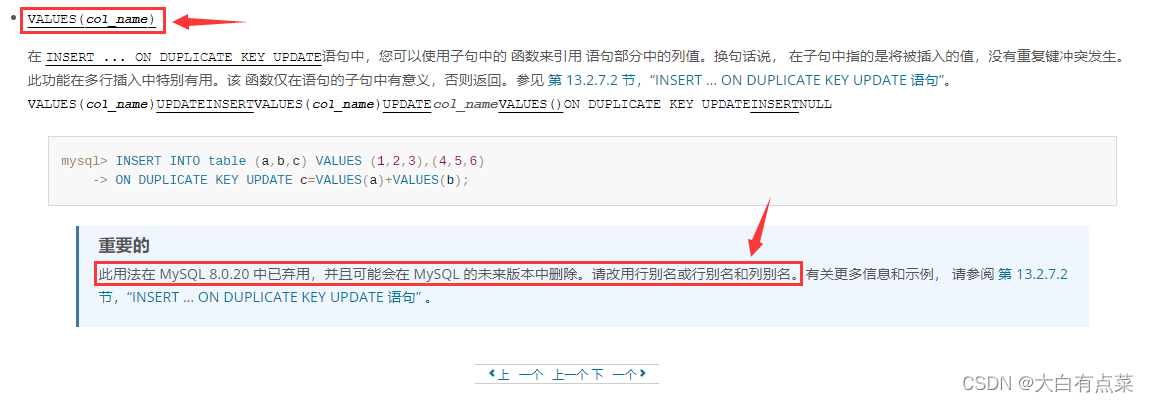
(2)on duplicate key update 在 insert 语句中的应用,但 values(col_name) 方法在MySQL8.0最新版过时了。
【INSERT … ON DUPLICATE KEY UPDATE 语句 - 官方文档】:
https://dev.mysql.com/doc/refman/8.0/en/insert-on-duplicate.html
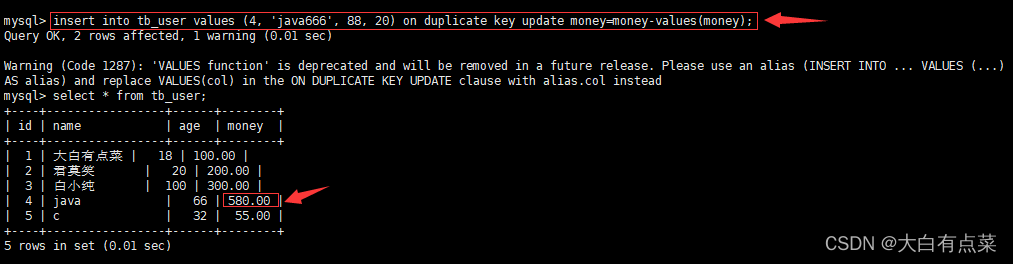
- 指定主键 id ,只更新其中一个字段的值,如下图,只有 money 字段的值被修改,其它字段的值保持不变。
insert into tb_user values (4, 'java666', 88, 20) on duplicate key update money=money-values(money);
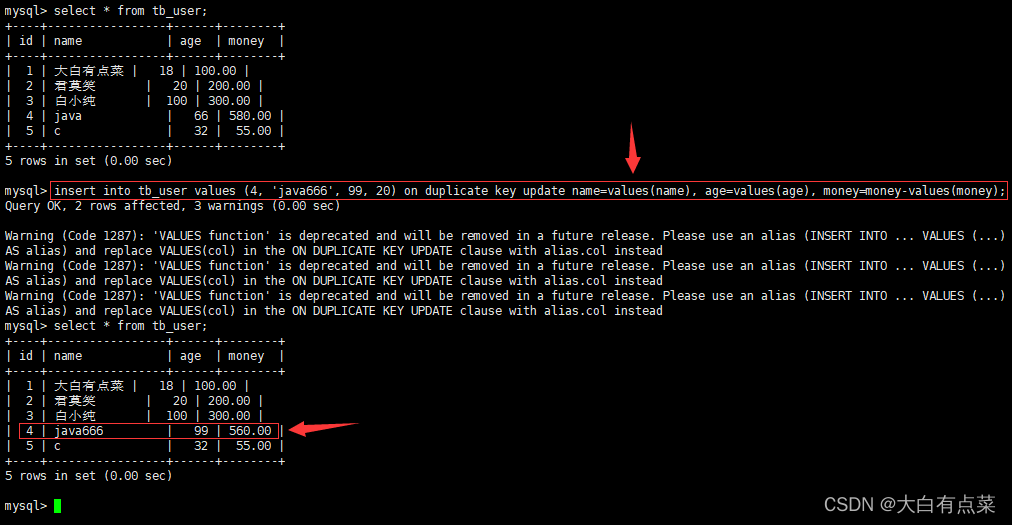
- 指定主键 id ,更新所有字段的值,如下图,所有字段的值都被修改了。
insert into tb_user values (4, 'java666', 99, 20) on duplicate key update name=values(name), age=values(age), money=money-values(money);
(3)过时的 values(col_name) 方法。
在前面只更新其中一个字段的值的 sql 语句中,on duplicate key update 后面写到 money=money-values(money) ,意思是使用 values(col_name) 方法获取 insert 语句中的值,col_name 变量指的是列名,如 values(money) 获取到的值是 20 ,原来 money 列对应的值是 600 ,计算后 money 的值为 600 - 20 = 580 。但是,却报了一个警告,默认警告内容是看不到的,需要使用命令“warnings;”开启警告内容显示。
warnings;
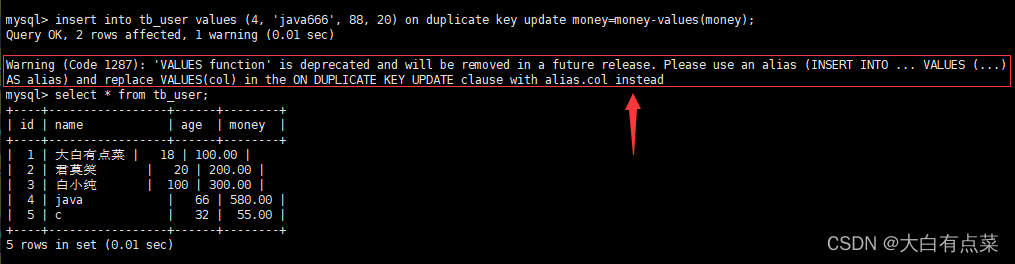
从警告内容看出,values(col_name) 函数(方法)已经过时了,官方建议使用别名(alias)的方式。笔者使用的是 MySQL-8.0.31 版本,这里的 values(col_name) 方法过时主要指的是 values(money) 这部分。其实呢,官方文档中说到,values(col_name) 方法在 MySQL-8.0.20 中已经弃用,并且可能会在 MySQL 的未来版本中删除。
【辅助功能中的VALUES(col_name)方法 - 官方文档】:
https://dev.mysql.com/doc/refman/8.0/en/miscellaneous-functions.html#function_values
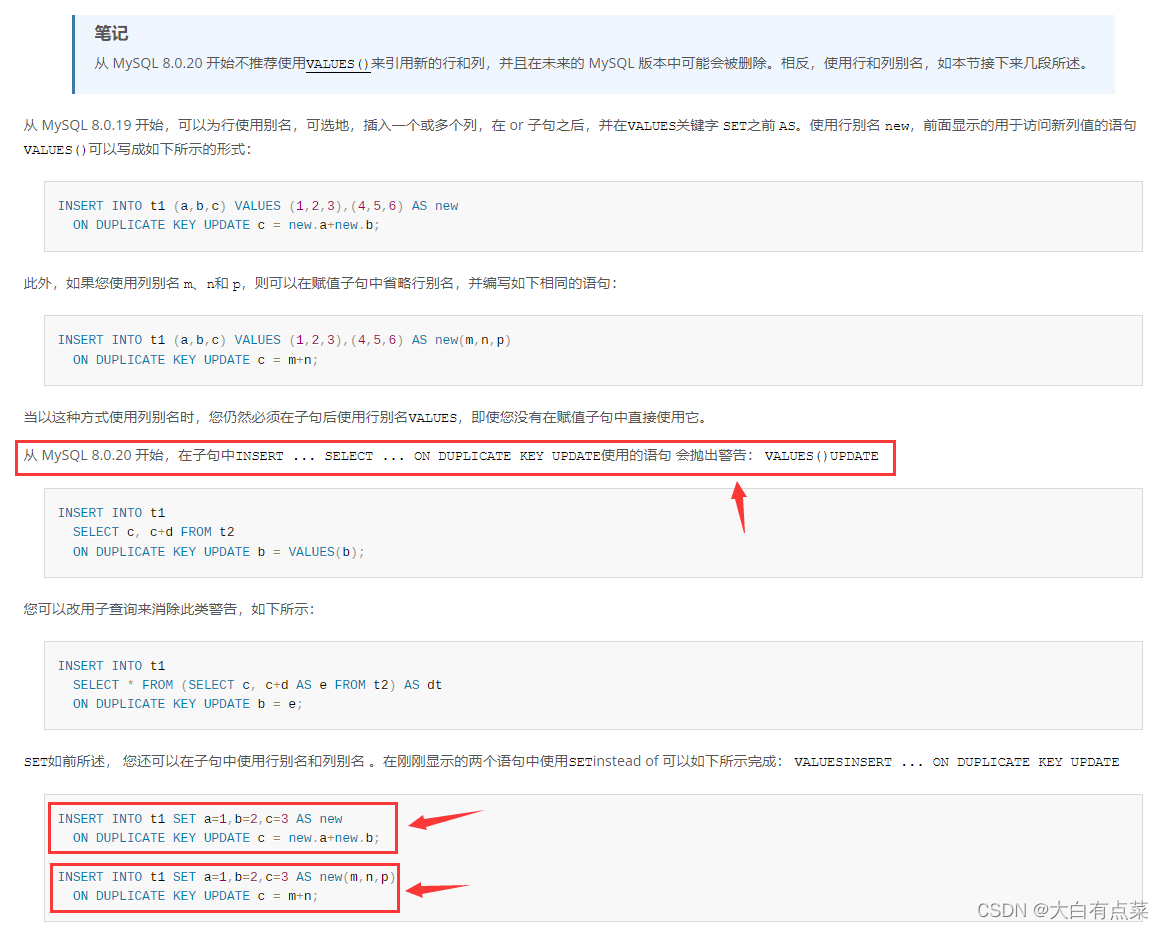
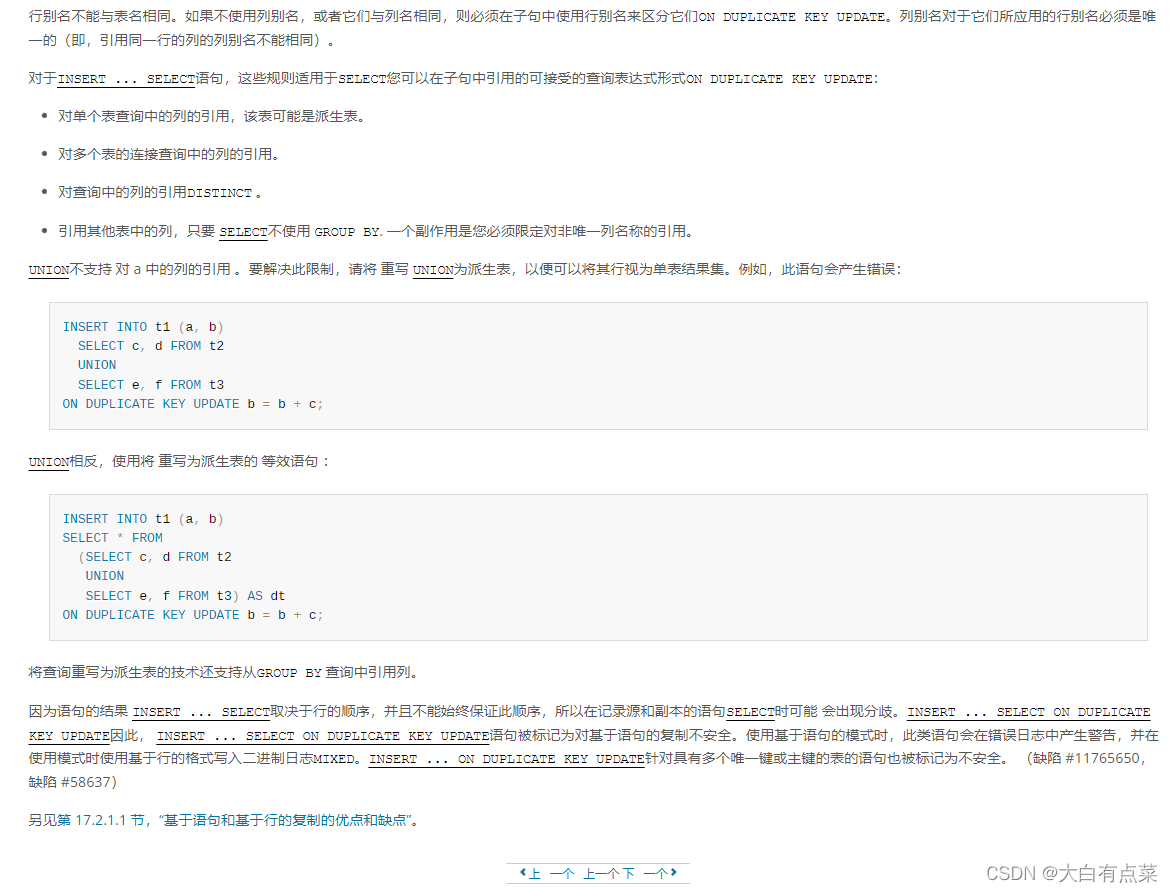
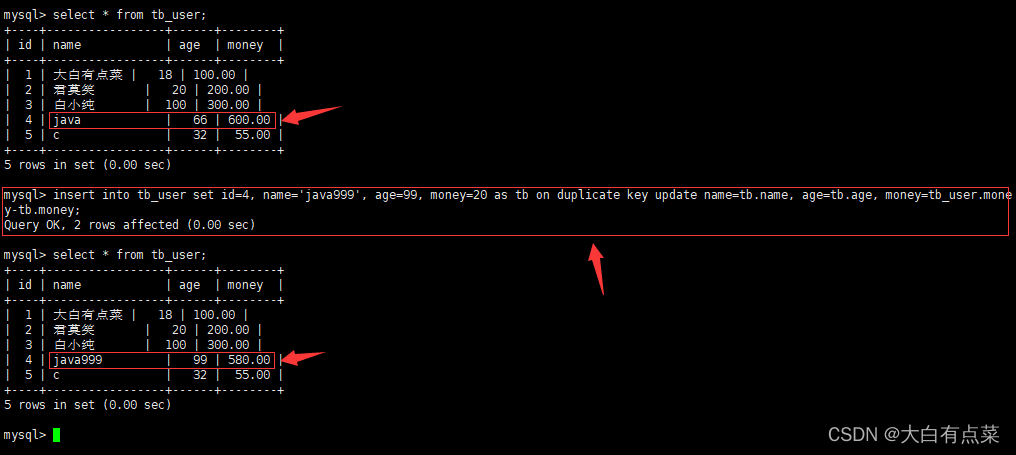
(3)正确姿势打开on duplicate key update 在 insert 语句中使用方式
【INSERT … ON DUPLICATE KEY UPDATE 语句 - 官方文档】:
https://dev.mysql.com/doc/refman/8.0/en/insert-on-duplicate.html
insert into tb_user set id=4, name='java999', age=99, money=20 as tb on duplicate key update name=tb.name, age=tb.age, money=tb_user.money-tb.money;
11、截断表(truncating table)
如果要删除整个表的数据(保留表结构)需要很长时间,因为MySQL是逐行执行操作的。最快的方式是使用“truncate table 表名”语句。截断表(truncating table)是MySQL的 DDL【数据库模式定义语言DDL(Data Definition Language),是用于描述数据库中要存储的现实世界实体的语言。】 操作,数据一旦被清空,就不能被回滚了,要谨慎使用。
truncate table tb_user;
12、MySQL官方示例数据库(Employees)下载并安装
MySQL官方提供一个示例数据库 Employees 以供大家测试。官网中是这么介绍 Employees 示例数据库的:
Employees 示例数据库由 Patrick Crews 和 Giuseppe Maxia 开发,提供了分布在六个单独表上的大量数据(大约 160MB)的组合,总共包含 400 万条记录。该结构与广泛的存储引擎类型兼容。通过包含的数据文件,还提供了对分区表的支持。
除了基础数据之外,Employees 数据库还包括一套可以跨测试数据执行的测试,以确保您加载的数据的完整性。这应该有助于确保初始加载期间的数据质量,并且可以在使用后使用以确保在测试期间没有对数据库进行任何更改。
【Employees 示例数据库简介 - 官方文档】:
https://dev.mysql.com/doc/employee/en/employees-introduction.html
【Employees 示例数据库安装 - 官方文档】:
https://dev.mysql.com/doc/employee/en/employees-installation.html

【Employees 示例数据库github下载地址,这里最新是 1.0.7 版】:
https://github.com/datacharmer/test_db/releases/tag/v1.0.7
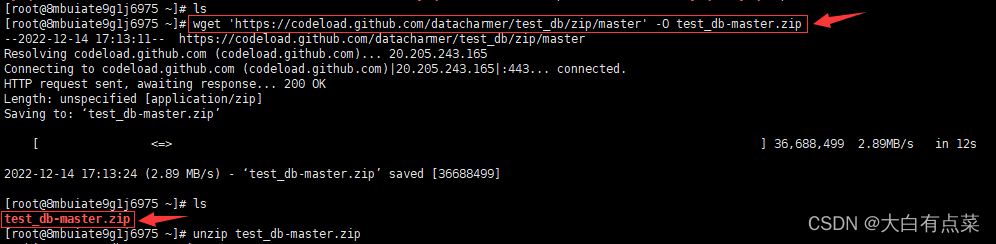
(1)github上下载Employees 示例数据库,如果下载不了,那就采用手动上传的方式。注意,可以下载到指定路径,笔者是直接下载到Centos最顶层的目录,使用命令 cd ~ 即可切换到那里。
wget 'https://codeload.github.com/datacharmer/test_db/zip/master' -O test_db-master.zip
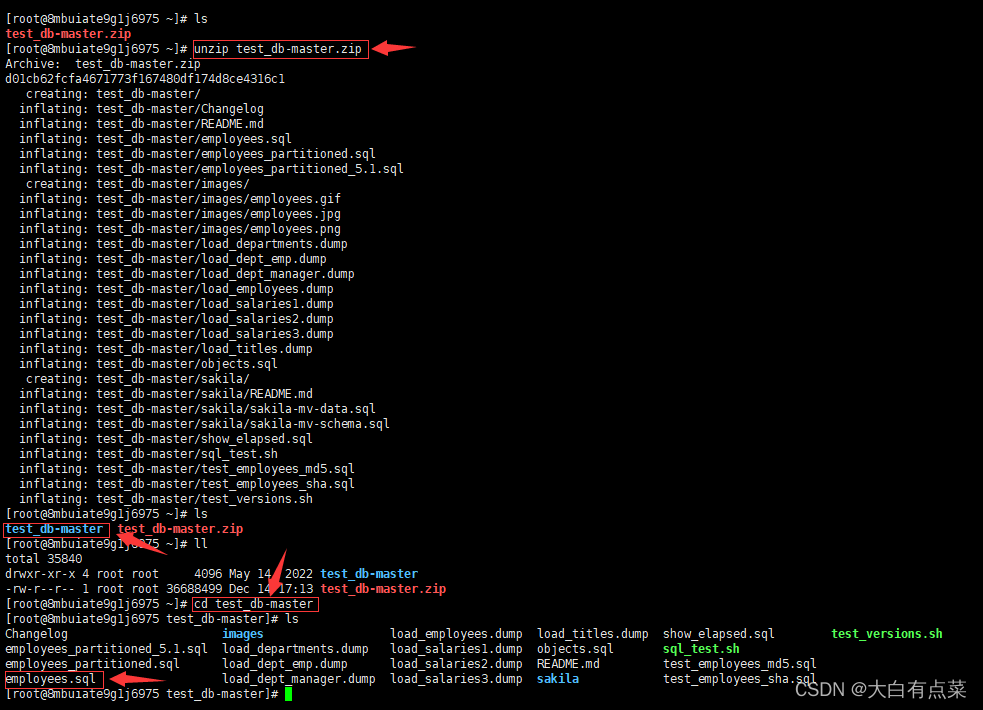
(2)解压 test_db-master.zip 压缩包,并切换到 test_db-master 目录下查看有哪些文件。我们要关注 employees.sql 脚本,里面有执行还原数据库的操作。
unzip test_db-master.zip
cd test_db-master
(3)安装 Employees 数据库:Centos上直接安装MySQL的。
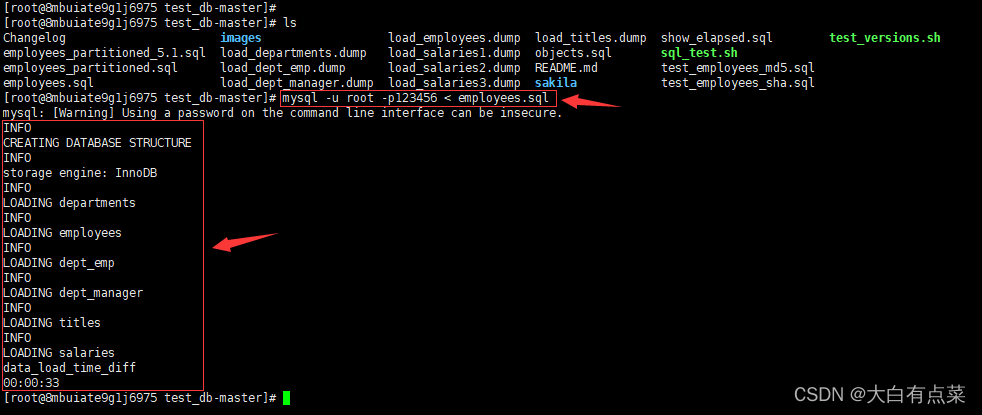
- 使用 mysql 命令执行 employees.sql 脚本还原 employees 数据库。
mysql -u root -p123456 < employees.sql
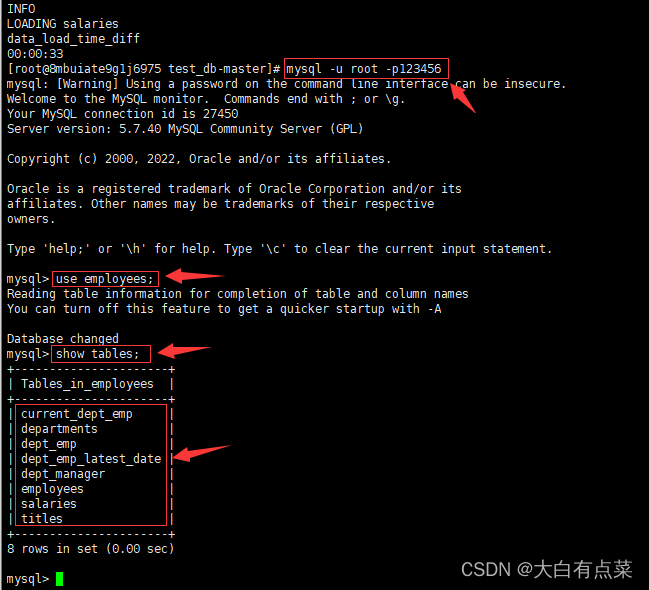
- 连接 mysql 数据库。
mysql -u root -p123456
- 切换到 employees 数据库。
use employees;
- 查看 employees 数据库所有表。
show tables;
(4)安装 Employees 数据库:Docker上启动MySQL容器的。
【Docker启动MySQL容器相关系列安装部署教程】
写最好的Docker安装最新版MySQL8(mysql-8.0.31)教程(参考Docker Hub和MySQL官方文档)
Docker安装最新版MySQL5.7(mysql-5.7.40)教程(参考Docker Hub)
1)此步很重要,一定要将 Employees 数据库有关的数据文件(employees.sql、show_elapsed.sql、load_departments.dump、load_employees.dump、load_dept_emp.dump、load_dept_manager.dump、load_titles.dump、load_salaries1.dump、load_salaries2.dump、load_salaries3.dump)复制到 MySQL 容器挂载的数据目录下,不然执行 employees.sql 脚本文件会报错!笔者运行MySQL容器挂载的数据目录是 /mydata/mysql1/data/ 。
cp ~/test_db-master/employees.sql show_elapsed.sql *.dump /mydata/mysql1/data/
2)方法一执行 employees.sql 脚本。这种方式虽然有点麻烦,但是不用进入到MySQL容器中去执行 employees.sql 脚本。需要修改复制到 /mydata/mysql1/data/ 目录下的 employees.sql 文件。修改有两种方式,建议使用第一种。
- (
方便)第一种方式修改 /mydata/mysql1/data/ 目录下的 employees.sql 文件,使用sed命令匹配每个数据文件名称,并在其前面添加/var/lib/mysql/路径,这路径是 mysql 的数据目录。“\”反斜杠代表转义符,主要转义“/”这个路径符号。
sed -i 's/load_departments.dump/\/var\/lib\/mysql\/load_departments.dump/' /mydata/mysql1/data/employees.sql
sed -i 's/load_employees.dump/\/var\/lib\/mysql\/load_employees.dump/' /mydata/mysql1/data/employees.sql
sed -i 's/load_dept_emp.dump/\/var\/lib\/mysql\/load_dept_emp.dump/' /mydata/mysql1/data/employees.sql
sed -i 's/load_dept_manager.dump/\/var\/lib\/mysql\/load_dept_manager.dump/' /mydata/mysql1/data/employees.sql
sed -i 's/load_titles.dump/\/var\/lib\/mysql\/load_titles.dump/' /mydata/mysql1/data/employees.sql
sed -i 's/load_salaries1.dump/\/var\/lib\/mysql\/load_salaries1.dump/' /mydata/mysql1/data/employees.sql
sed -i 's/load_salaries2.dump/\/var\/lib\/mysql\/load_salaries2.dump/' /mydata/mysql1/data/employees.sql
sed -i 's/load_salaries3.dump/\/var\/lib\/mysql\/load_salaries3.dump/' /mydata/mysql1/data/employees.sql
sed -i 's/show_elapsed.sql/\/var\/lib\/mysql\/show_elapsed.sql/' /mydata/mysql1/data/employees.sql
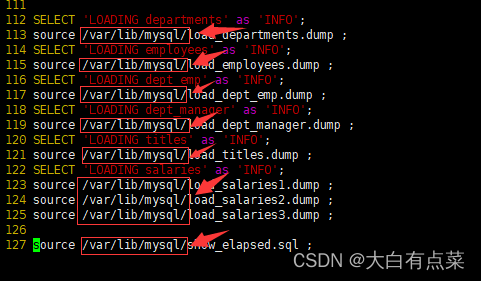
- (
麻烦)第二种方式修改 /mydata/mysql1/data/ 目录下的 employees.sql 文件,手动编辑 employees.sql 文件,并在每个数据文件名称前面添加/var/lib/mysql/路径。
vim /mydata/mysql1/data/employees.sql
/var/lib/mysql/
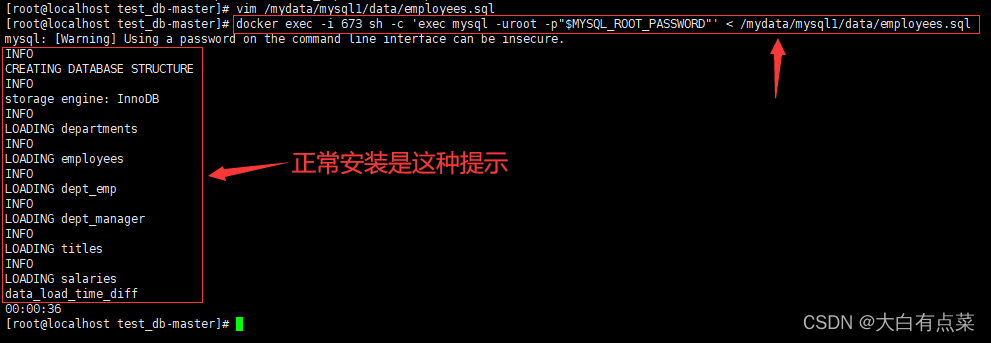
docker exec -i命令运行MySQL容器,并使用 mysql 命令执行 employees.sql 脚本还原 employees 数据库。参数-i后面可以是容器名称或者容器id(两种写法) 。
docker exec -i mysql sh -c 'exec mysql -uroot -p"$MYSQL_ROOT_PASSWORD"' < /mydata/mysql1/data/employees.sql
或者
docker exec -i 673 sh -c 'exec mysql -uroot -p"$MYSQL_ROOT_PASSWORD"' < /mydata/mysql1/data/employees.sql
- 测试 employees 数据库是否已经安装好,这里只查询 departments 表的数据(两种写法)。
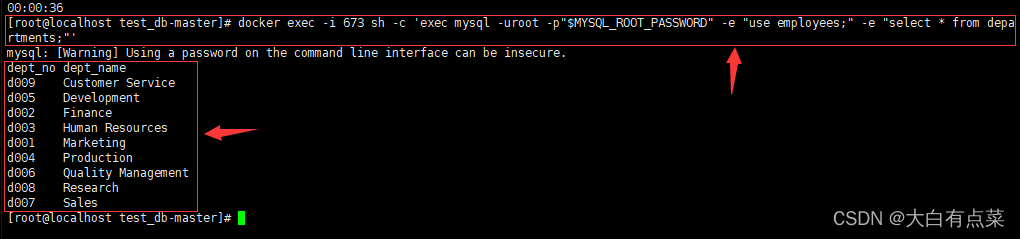
docker exec -i mysql sh -c 'exec mysql -uroot -p"$MYSQL_ROOT_PASSWORD" -e "use employees;" -e "select * from departments;"'
或者
docker exec -i 673 sh -c 'exec mysql -uroot -p"$MYSQL_ROOT_PASSWORD" -e "use employees;" -e "select * from departments;"'
3)方法二执行 employees.sql 脚本。这种方式需要进入到MySQL容器中去执行 employees.sql 脚本,不需要修改 employees.sql 文件。
- 进入到MySQL容器(两种写法)。
docker exec -it mysql /bin/bash
或者
docker exec -it 673 /bin/bash
- 切换到
/var/lib/mysql目录。
cd /var/lib/mysql
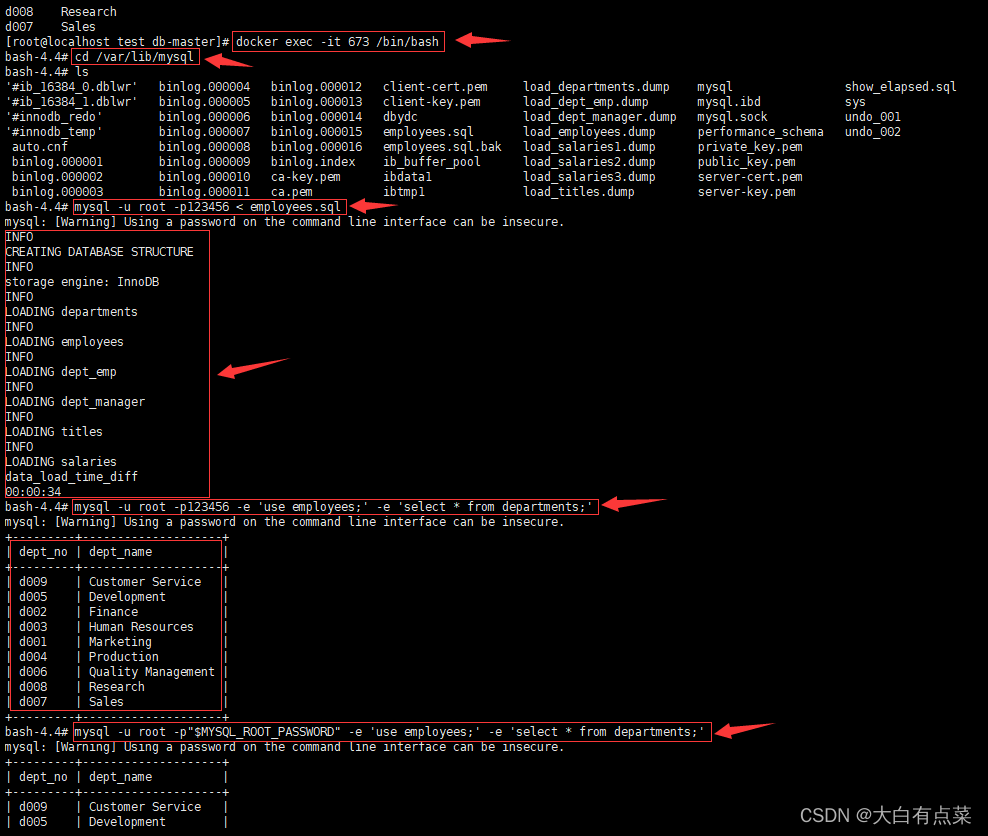
- 使用 mysql 命令执行 employees.sql 进行数据库还原(两种写法)。
mysql -u root -p"$MYSQL_ROOT_PASSWORD" < employees.sql
或者
mysql -u root -p123456 < employees.sql
- 测试 employees 数据库是否已经安装好,这里只查询 departments 表的数据(两种写法)。
mysql -u root -p"$MYSQL_ROOT_PASSWORD" -e 'use employees;' -e 'select * from departments;'
或者
mysql -u root -p123456 -e 'use employees;' -e 'select * from departments;'
13、使用正则表达式查询数据
MySQL提供正则表达式去查询数据,我们可以利用 rlike(RLIKE) 或 regexp(REGEXP)运算符在 where 子句中使用正则表达式。官方文档中也描述到,rlike(RLIKE)和 regexp(REGEXP)两者功能结合,等同于 regexp_like(REGEXP_LIKE),这是MySQL8.0出现的正则表达式函数。
【正则表达式(Regular Expressions)- 官方文档】
https://dev.mysql.com/doc/refman/8.0/en/regexp.html
| 表达式 | 描述 |
|---|---|
| * | 零次或多次重复 |
| + | 一个或多个重复 |
| ? | 可选字符 |
| ^ | 以…开头 |
| $ | 以…结尾 |
| . | 任何字符 (包括回车符和换行符,尽管要在字符串中间匹配这些字符,必须给出m(多行)匹配控制字符或(?m) 模式内修饰符) |
| \. | 区间 |
| [abc] | 只有a、b或c |
| [^abc] | 非a,非b,非c |
| [a-z] | 字符a到z |
| [0-9] | 数字0到9 |
| ^…$ | 开始和结束 |
| \d | 任何数字 |
| \D | 任何非数字字符 |
| \s | 任何空格 |
| \S | 任何非空白字符 |
| \w | 任何字母数字字符 |
| \W | 任何非字母数字字符 |
| {m} | m次重复 |
| {m,n} | m到n次重复 |
| a* | 匹配零个或多个a 字符的任意序列 |
| a+ | 匹配一个或多个a 字符的任意序列 |
| a? | 匹配零个或一个a字符 |
| de|abc | 交替; 匹配任一序列 de或abc |
| (abc)* | 匹配序列的零个或多个实例 abc |
【REGEXP_LIKE 说明】
格式:REGEXP_LIKE(expr, pat[, match_type])
如果字符串 expr 与模式 pat 指定的正则表达式匹配,则返回 1,否则返回 0。如果 expr 或 pat 为 NULL,则返回值为NULL。
可选 match_type 参数是一个字符串,可以包含以下任何或所有指定如何执行匹配的字符:
- c:区分大小写匹配。
- i:不区分大小写的匹配。
- m:多行模式。识别字符串中的行终止符。默认行为是仅在字符串表达式的开头和结尾匹配行终止符。
- n:“.”字符匹配行终止符。默认是“.”匹配停止在一行的末尾。
- u:Unix-only 行结尾。只有换行符被识别为以“.”、“^”和“$”匹配运算符结尾的行。
如果在 match_type 中指定了指定矛盾选项的字符,则最右边的优先。
默认情况下,正则表达式操作在确定字符类型和执行比较时使用 expr 和 pat 参数的字符集和排序规则。如果参数具有不同的字符集或归类,则适用强制性规则。
可以使用 c 或 i 字符指定 match_type 以覆盖默认的区分大小写。 例外:如果任一参数是二进制字符串,则这些参数将以区分大小写的方式作为二进制字符串处理,即使 match_type 包含 i 字符也是如此。
【REGEXP_LIKE 用法1 - 在MySQL8.0中运行】
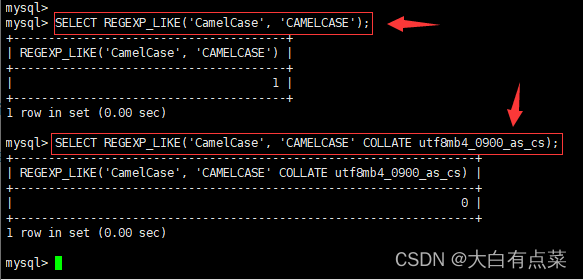
SELECT REGEXP_LIKE('CamelCase', 'CAMELCASE');
SELECT REGEXP_LIKE('CamelCase', 'CAMELCASE' COLLATE utf8mb4_0900_as_cs);
【REGEXP_LIKE 用法2 - 在MySQL8.0中运行】
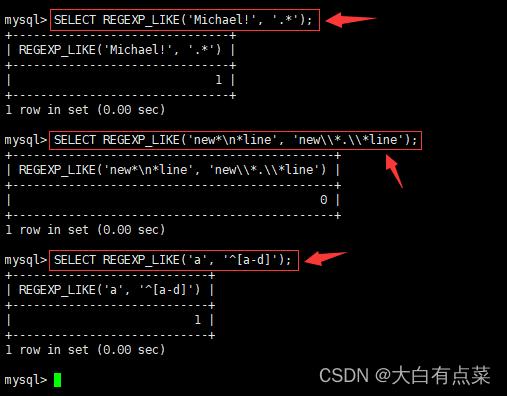
SELECT REGEXP_LIKE('Michael!', '.*');
SELECT REGEXP_LIKE('new*\n*line', 'new\\*.\\*line');
SELECT REGEXP_LIKE('a', '^[a-d]');
【REGEXP_LIKE 用法3 - 在MySQL8.0中运行】
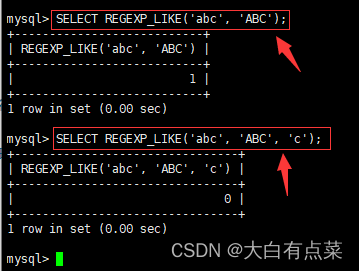
SELECT REGEXP_LIKE('abc', 'ABC');
SELECT REGEXP_LIKE('abc', 'ABC', 'c');
【RLIKE 用法 - 在MySQL8.0中运行】
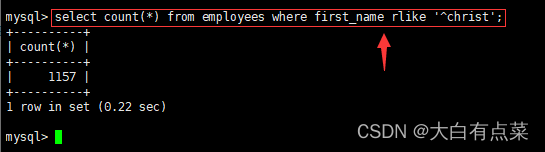
- 找出名字以 Christ 开头的所有员工的人数。
select count(*) from employees where first_name rlike '^christ';
【REGEXP 用法1 - 在MySQL8.0中运行】
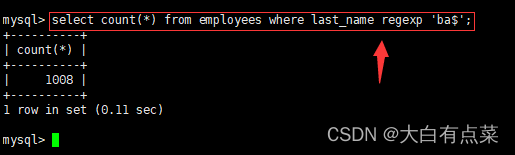
- 找出姓氏以 ba 结尾的所有员工的人数。
select count(*) from employees where last_name regexp 'ba$';
【REGEXP 用法2 - 在MySQL8.0中运行】
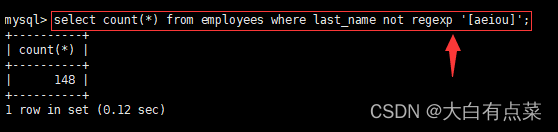
- 找出姓氏不包含元音(a、e、i、o、u)的所有员工的人数。
select count(*) from employees where last_name not regexp '[aeiou]';