前面学习了搭建网络模型的各个层级与结构,想要训练得到1个良好的网络模型,正确的权值初始化方法可以加快模型的收敛,相反,不恰当的权值初始化可能导致梯度爆炸或消失,最终导致模型无法训练。因此,本节主要从3方面来分析了解权值初始化:(1)分析不恰当的权值初始化是如何引发梯度消失与爆炸的?(2)学习常用的Xavier与Kaiming权值初始化方法;(3)学习Pytorch中10种权值初始化方法。
梯度爆炸和消失
一、理论

根据计算图,列写出计算图的前向传播计算公式,关注第2个隐藏层权值矩阵 W2 的梯度如何求取?

要求 W2 权值矩阵的梯度,从上述求解过程中可以看出, H1是上一层神经元的输出值, W2 的梯度依赖于上一层的输出:①如果 H1输出值非常小,趋近于0,那么 W2 的梯度也就趋于0,从而导致梯度消失;②同理,如果 H1输出值非常大,趋近于无穷大, W2 的梯度也就趋于无穷大,从而导致梯度爆炸。一旦发生梯度爆炸或消失,就会引发模型无法训练的问题。
结论:
从公式求导(求梯度)的角度,要避免梯度消失和爆炸的产生,就要严格控制网络输出层(输出值)的尺度范围,也就是要求每一层网络的输出值不能太大或者太小。
二、实验
(1)实验1——引发梯度爆炸,出现nan现象
代码分析:
这里采用layer_nums=100层全连接网络,每一层神经元个数为neural_num=256,输入数据batch_size=16,构建MLP模型。
(1)init 函数:采用Modulelist和列表生成式,通过for循环,循环构建网络层;又由于Modulelist不能自动前向传播,因此将构建好的Modulelist赋值给linear属性;
(2)forward函数:模型模块Modulelist构建好后,拼接子模块在forward中实现前向传播,只需要利用for循环依次从linear中获取每个全连接层,对全连接层实现前向传播,就可以返回输出值x。
(3)initialize初始化:对每一个模块进行for循环判断是否为线性层linear,如果是,采用标准正态分布(0均值、1标准差)对权值 W 进行初始化。
构建好全连接网络后,再构建1个0均值、1标准差的随机输入input,然后输入进net中观察其输出output。
class MLP(nn.Module):
def __init__(self, neural_num, layers):
super(MLP, self).__init__()
self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
self.neural_num = neural_num
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
return x
def initialize(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data) # normal: mean=0, std=1
flag = 1
if flag:
layer_nums = 100
neural_nums = 256
batch_size = 16
net = MLP(neural_nums, layer_nums)
net.initialize()
inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1
output = net(inputs)
print(output)
实验结果

结果表明:
Output的每一个值都为nan即数据非常大或者非常小,已经超出了当前精度可表示的范围。
结果分析:
到forward中观察,什么时候数据变化到了nan,这里采用标准差来衡量数据的尺度范围。
打印网络每一层的标准差std,设置判断if,判断x的标准差为nan时,模型停止向前传播。
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
x = torch.relu(x)
print("layer:{}, std:{}".format(i, x.std()))
if torch.isnan(x.std()):
print("output is nan in {} layers".format(i))
break
return x
实验结果


结果表明:
从实验结果可以看出,第31层数据的标准差出现了nan,std可能已经达到 1038 或 1039;就数据tensor而言,出现了非常大或者非常小的数据即正无穷inf或负无穷-inf,再向前传播,当前精度已经无法表示非常大或者非常小的数据。就标准差而言,std逐层变大,从15.95到256.623再到4107.245…
结果分析:
为什么出现了nan现象?以及如何抑制nan出现?
下面根据公式推导分析,为什么模型网络输出层的标准差会逐层变大?

抑制nan现象出现:**由图4所示,得到1个重要结论,想要控制网络层输出值尺度不变,始终为1,那么有:
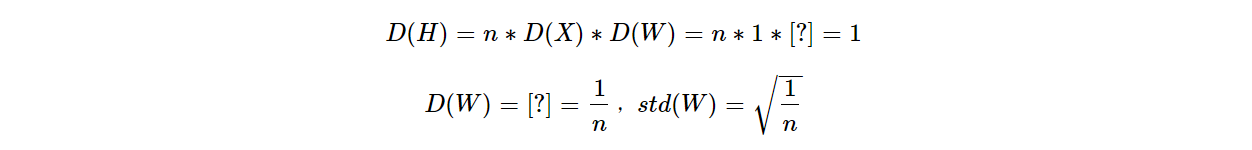
2)实验2:保持网络层输出值尺度不变的初始化
采用0均值,标准差为\sqrt{\frac{1}{n}}的分布初始化权值W,再观察网络层输出值标准差的特点。
def initialize(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data, std=np.sqrt(1/self.neural_num)) ## normal: mean=0, std=1/n
实验结果:

结果表明:
根据输出结果可以看出,每层数据标准差都能维持在1左右,采用恰当的权值初始化方法可以实现多层全连接网络输出值尺度维持在一定范围内。 通过以上实例,我们知道需要保持每个网络层输出数据的方差为1,但目前还未考虑激活函数的存在,下面学习具有激活函数的权值初始化。
Xavier和Kaiming方法
一、Xavier初始化
实验:具有激活函数的权值初始化—引发梯度消失
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
x = torch.tanh(x)
在forward中,每个linear后进行1个tanh()激活函数
print("layer:{}, std:{}".format(i, x.std()))
if torch.isnan(x.std()):
print("output is nan in {} layers".format(i))
break
return x
实验结果:

针对以上具有激活函数权值初始化的问题,2010年Xavier详细探讨了具有激活函数应该如何进行初始化。文献中,结合 “方差一致性原则:要求每个网络层输出值的方差为1”,同时针对饱和激活函数sigmoid、Tanh激活函数进行了分析。
Xavier初始化
1、理论
通过 《Understanding the diffculty of training deep feedforward nerual networks》 文章中的公式推导, 权值的方差D(W)满足如下公式:其中, ni为输入层神经元个数, ni+1为输出层神经元个数,下式是同时考虑了前向传播和反向传播的数据尺度问题得到的:
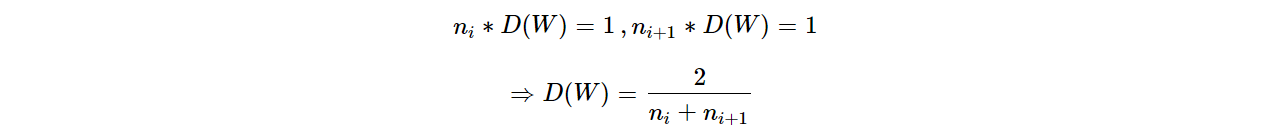
通常,Xavier采用均匀分布,下面推导均匀分布的上、下限。因为采用0均值,因此,分布的上下限是对称关系 W∼U[−a,a]:
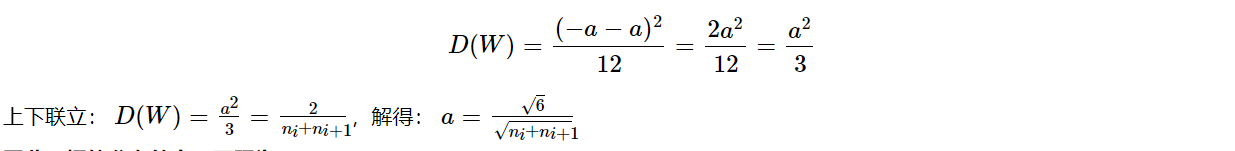
因此,权值分布的上、下限为:
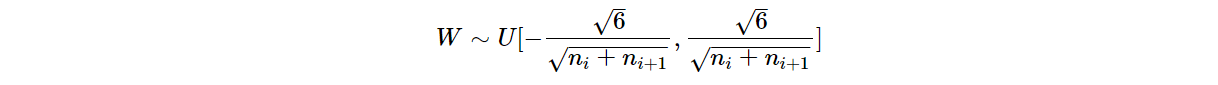
2、验证实验
①手动计算,采用Xavier对权值进行初始化再观察网络层的输出。
def initialize(self):
for m in self.modules():
if isinstance(m, nn.Linear):
#计算a的数值大小(由于本例中输入和输出神经元个数相同,所以同值)
a = np.sqrt(6 / (self.neural_num + self.neural_num))
#利用Pytorch的内置函数calculate_gain计算tanh增益
tanh_gain = nn.init.calculate_gain('tanh')
a *= tanh_gain
#利用上、下限对权值进行均匀分布初始化
nn.init.uniform_(m.weight.data, -a, a)
实验结果:

二、Kaiming初始化
1、理论
针对这一问题,2015年何恺明等人发表 《Delving deep into rectifiers:Surpassing human-level performance on ImageNet classification》 提出了解决方法,在文中同样遵循方差一致性原则:保持数据尺度维持在恰当范围,即让每个输出层方差为1,针对ReLU激活函数(及其变种)。
通过公式推导,权值的方差D(W)满足如下公式,其中, ni为输入层神经元个数:
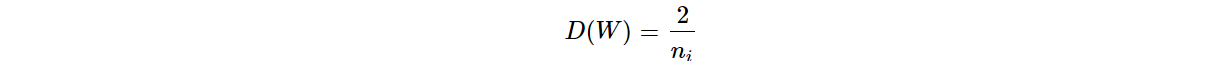
进一步,针对ReLU的变种(即负半轴存在斜率)权值的方差D(W)有,a为负半轴的斜率:
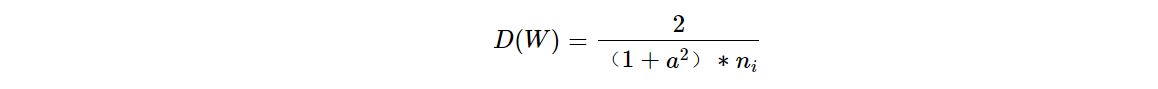
因此,权值矩阵std(W)有:

2、验证实验
下面通过上述公式对权值W进行初始化,观察网络层的输出。
①手动计算的Kaiming初始化方法
def initialize(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data, std=np.sqrt(2 / self.neural_num))
②Pytorch中提供的Kaiming初始化方法
def initialize(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight.data)
常用的初始化方法
不良的权值初始化会引起输出层输出值过大、过小从而引起梯度爆炸或消失,导致模型无法训练的问题。为避免这一问题,要控制网络层输出值的尺度范围,使每一个网络层输出值的方差尽量为1,不让方差过大或者过小。
Pytorch提供的10大初始化方法:
1、Xavier均匀分布
2、Xavier标准正态分布
3、Kaiming均匀分布
4、Kaiming标准正态分布
5、均匀分布
6、正态分布
7、常数分布
8、正交矩阵初始化
9、单位矩阵初始化
10、稀疏矩阵初始化
无论选择哪一种初始化方法都需要遵循方差一致性原则。
实验——函数 “calculate_gain方差变化尺度”
nn.init.calculate_gain
主要功能:计算激活函数的方差变化尺度
主要参数:nonlinearity-激活函数名称
param:激活函数的参数,如Leaky ReLU的negative_slop

① 手动计算输入输出增益gain
x = torch.randn(10000)
out = torch.tanh(x)
gain = x.std() / out.std()
print('gain:{}'.format(gain))
② Pytorch中提供求增益gain
x = torch.randn(10000)
out = torch.tanh(x)
tanh_gain = nn.init.calculate_gain('tanh')
print('tanh_gain in PyTorch:', tanh_gain)

对于0均值、1标准差的数据x经过tanh后,标准差会减小约1.6倍。