1. 基本符号含义
| 符号 | 含义 |
|---|---|
| TP | 将正类预测为正类 |
| FN | 将正类预测为负类 |
| FP | 将负类预测为正类 |
| TN | 将负类预测为负类 |
| 实际为正 | 实际为负 | |
|---|---|---|
| 预测为正 | TP真正例 | FP假正例 |
| 预测为负 | FN假负例 | TN真负例 |
P(positive) 和 N(negative) 表示样本被预测为“正”还是“负”,或者是1或0;
T(true) 和 F(false) 这一对符号代表预测正确or错误,也就是 “真”or"假" 。如果实际为正,预测也为正,或实际为负,预测也为负,即二者保持一致,则用 T ,否则是 F 。
这样就好记一些,比如TN,一看就是样本被预测为负类,但是预测结果是正确的,说明其实际也为负类的情况。
2. 查准率与查全率
| 指标 | 公式 | 含义 |
|---|---|---|
| 真正率TPR | T P R = T P T P + F N TPR=\dfrac{TP}{TP+FN} TPR=TP+FNTP | 实际为正的样本中,预测为正的比例(查全率) |
| 真负率TNR | T N R = T N T N + F P TNR=\dfrac{TN}{TN+FP} TNR=TN+FPTN | 实际为负的样本中,预测为负的比例 |
| 假正率FPR | F P R = F P T N + F P FPR=\dfrac{FP}{TN+FP} FPR=TN+FPFP | 实际为负的样本中,预测为正的比例 |
| 假负率FNR | F N R = F N F N + T P FNR=\dfrac{FN}{FN+TP} FNR=FN+TPFN | 实际为正的样本中,预测为负的比例 |
| 指标 | 公式 | 含义 |
|---|---|---|
| 精确率Precision | T P T P + F P \dfrac{TP}{TP+FP} TP+FPTP | 预测为正的样本中 实际也正的比例 |
| 召回率Recall | T P T P + F N \dfrac{TP}{TP+FN} TP+FNTP | 实际为正的样本中 预测也正的比例 |
| 准确率Accuracy | T P + T N T P + T N + F N + F P \dfrac{TP+TN}{TP+TN+FN+FP} TP+TN+FN+FPTP+TN | 所有样本中被预测正确的比例 |
精确率即查准率,表示预测为正的样本中,有多少实际也为正;
召回率即查全率,表示实际为正的样本中,有多少预测为正;
因为所谓“正类”,是我们自己定义的更加关注的类,我们在所有样本中扫描检查它们,所谓“准”和“全”都是针对正类而言的,以银行欺诈行为举例,定义欺诈用户为“正类”:
- 查准率即查得准不准,我们认为欺诈的人他就是真正欺诈了,没有冤枉一个好人;
- 查全率即查得全不全,我们是不是把欺诈用户都查出来了,没有放过一个坏人。
想要查得全,一般稍微有点可疑就要认为他欺诈;想要查得准,就不能草木皆兵,要欺诈嫌疑非常高材认定其欺诈,所以这两个指标一般不可兼得,即:一般查准率越高查全率越低。
不同的场景下对于查准率和查全率的要求也是不一样,比如推荐系统中比较倾向于高查准率低查全率,为了尽可能的不影响用户体验实现更精准推荐。而抓捕逃犯的系统中更需要高的查全率,误抓也不能漏抓。
3. P-R曲线与F1-score
如果没有那么明确的需求说P和R需要哪一个更高,可以通过P-R曲线来选取一个双高的点。
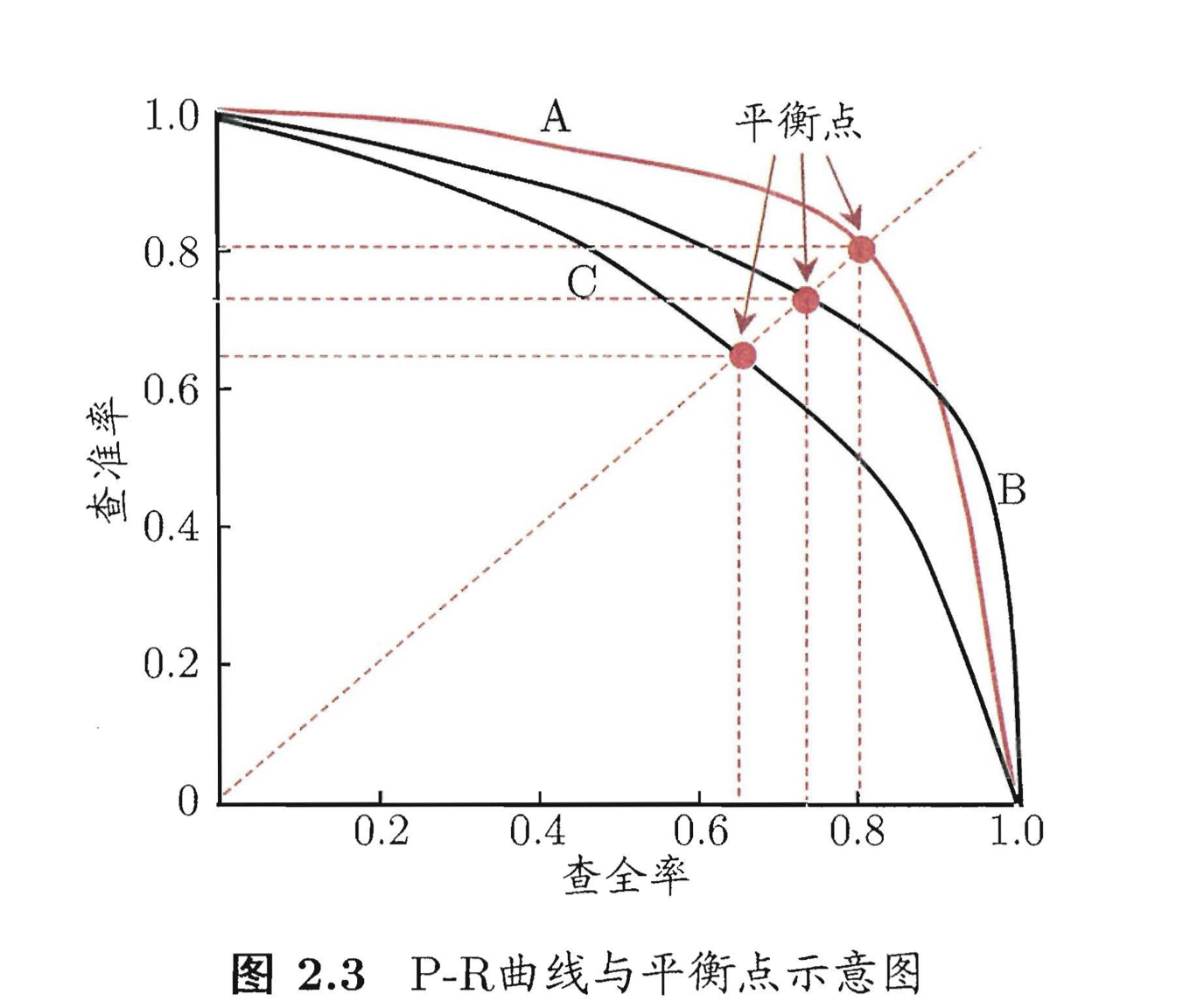
一般的判断方法是:
- 包围的面积越大越好(图中A的面积最大)
- 找P=R的的点,在该点处数值更大的模型比较好(A对应的平衡点也是最优的)
F1-Score指标综合了Precision与Recall的结果,认为二者同等重要,是二者的调和平均数。 F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。其中,F1的1就是Recall相对于Precision的重要程度,1代表相同,2代表Recall重要性是Precision的两倍。 F 1 s c o r e = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l = 2 × T P 样 例 总 数 + T P − T N F_1score=\dfrac{2×Precision×Recall}{Precision+Recall}=\dfrac{2×TP}{样例总数+TP-TN} F1score=Precision+Recall2×Precision×Recall=样例总数+TP−TN2×TP
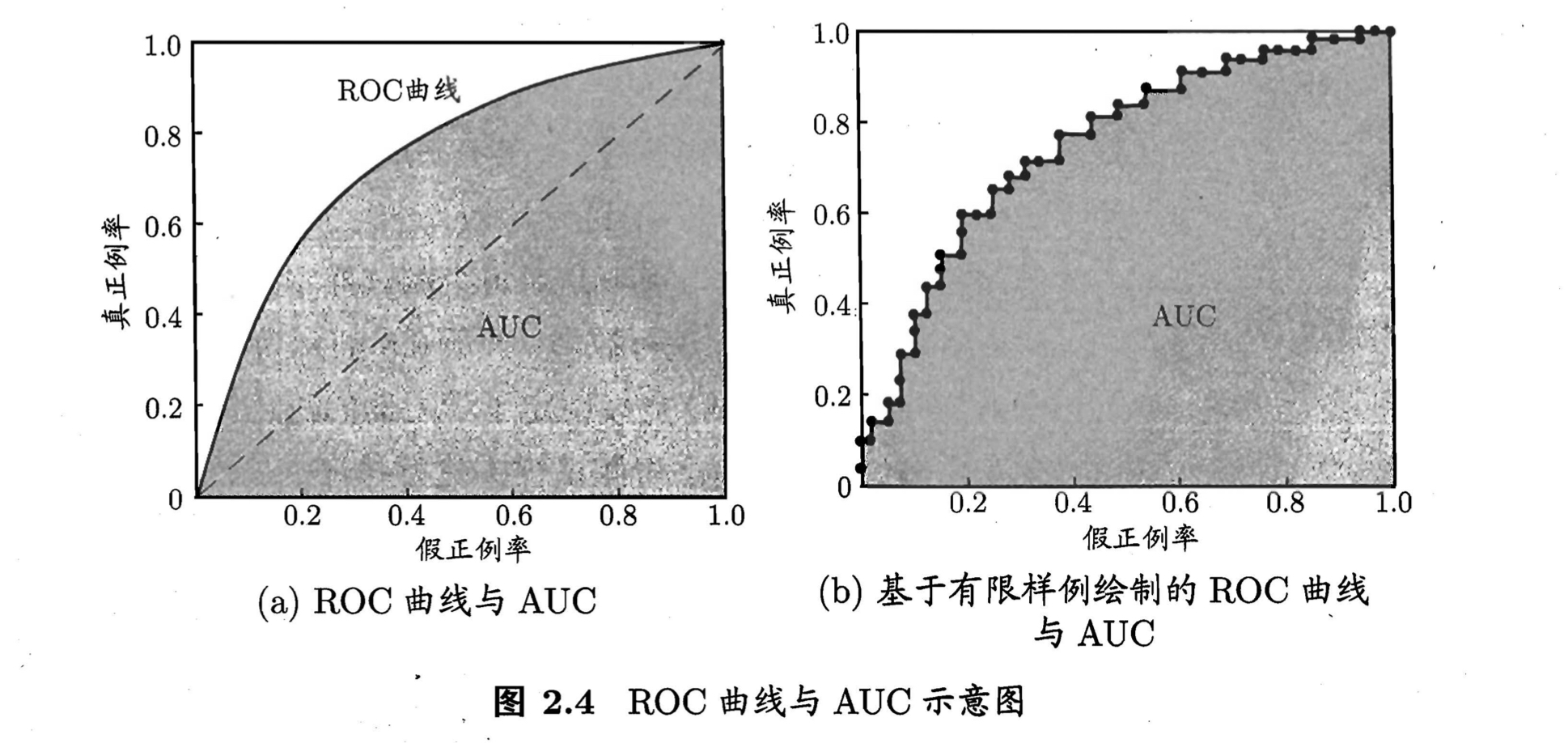
4. ROC与AUC
ROC全称是“受试者工作特征曲线”,ROC 曲线 x x x 轴表示的是假正率, y y y 轴表示的是真正率,ROC底部的面积被称为AUC。ROC曲线越是靠左上角,说明分类器越好;AUC对样本类别是否均衡并不敏感,这也是不均衡样本通常采用AUC评价分类性能的原因。