问题描述:
通过链路追踪trace发现,对kafka消息的异步处理出现耗时很大的情况,最大可达几秒,耗时主要在消息发出后到消息读出前,消息时延与应用无关。通过进一步打点测试,从消息发出到消费者读到消息的耗时p99很大,而p50以下则很小,只有几ms。
问题定位:
Kafka消息从生产者写入到消费者读出经过kafkaProxy、kafka两个组件,通过逐步深入、排除各种因素,最终定位问题。
一、 初步解决
1、 kafkaPrxoy
第一步排除kafkaProxy因素,kafkaProxy是应用将消息发送至kafka的代理,通过查看日志,发现无积压。另外,查看其使用的sarama包中的配置,producer未使用batch方式,所有消息都会及时发出。
2、 num.replica.fetchers
kafka收到一条消息,需要isr中所有broker全部同步成功之后,消息对consumer才可见。Kafka中num.replica.fetchers配置指定每个broker有多少fetcher threads负责同步消息,默认配置是1。猜测所有partition都通过这一个thread同步,可能造成同步时延,通过修改配置为2和4,对问题均没有缓解,排除。
3、 partition数量
线上partiton数量是100,通过修改测试环境partition数量,使得p99降低到ms级别,但不稳定,偶尔还会出现p99很高的情况。通过了解前人做过的kafka压测数据,kafka单个broker在超过64个partition时,性能会急剧下降,cpu使用率升高,消息时延也会增大。确定问题与partition数量有关,但具体原因待查。
partitons数量前后对比图:
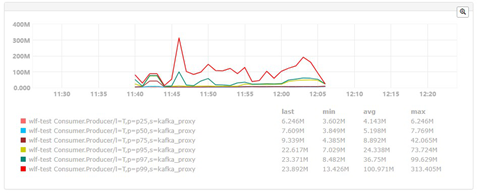
partition数量100
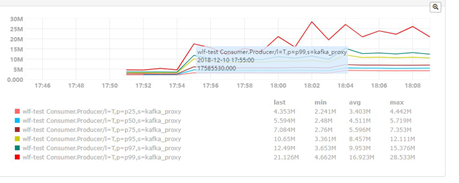
partitions数量30
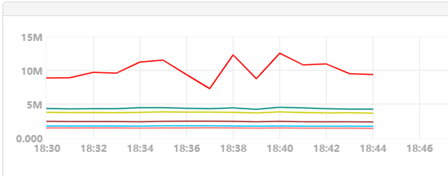
集群qps1000(3broker)
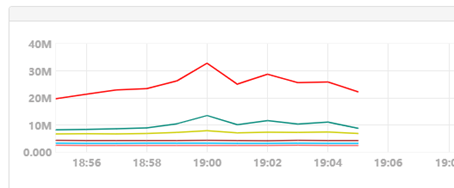
单broker 1000
二、 深入定位
通过对比rocketmq,kafka的partition过多影响性能,是由于每个partition都会打开一个文件,打开文件数过多影响性能。而rocketmq所有队列统一存储在一个文件中,每个broker只打开一个数据存储文件,性能与队列数量无关,最高可支持数万队列。
虽然通过减少partition数量可以降低p99时延,但在对kafka持续发送数据时,会出现偶尔p99时延达到s级的现象。每20-30分钟,会出现一次几秒的延迟,偶尔会在一段时间内,频繁出现几秒时间的超时,且发生时间比较随机。虽然大部分时间,消息的时延满足ms级的要求,但偶尔出现的s级时延,对于业务来说,同样不可容忍,继续研究这一问题,排除不同因素。
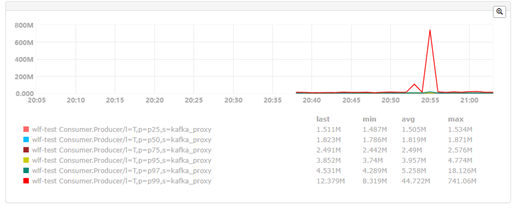
打开kafka的trace,发现broker在收到每条消息时,会首先写到本地页面缓存,写入时会偶尔出现几百ms,几s的情况,与现象一致,问题出现在写入文件缓存时。

1、 log.flush
《Apache Kafka实战》作者对这一现象给出的解决方案是“如果想要让生产的消息可以更快地被消费到,那么尝试设置"log.flush.interval.messages"和"log.flush.interval.ms"来手动设置flush频率。另外你可以尝试调整文件系统的commit interval (Ext4默认是5s)”。通过尝试修改log.flush.interval.messages"和"log.flush.interval.ms"参数,测试结果是问题仍没有解决,而且某些情况下,发生超时频率更高。排除因素
链接: https://www.zhihu.com/question/58491075
2、 脏页刷新策略
Kafka默认配置log.flush.interval.messages和log.flush.interval.ms都是maxint,也就是说kafka不会主动sync文件,全依靠linux系统本身的脏页刷盘策略。Linux刷盘有两个机制,一个是dirty_writeback_centisecs和dirty_expire_centisecs两项,dirty_writeback_centisecs是每隔多长时间刷新脏页超时时间大于dirty_expire_centisecs配置的脏页。另一个是dirty_ratio和dirty_background_ratio,每当脏页占用内存大于dirty_backgound_ratio就会启动pdflush进程,刷新脏页。而当脏页占用内存大于dirty_ratio时,则会阻塞其他的写页面缓存请求,这是个可能的原因。测试调整这几个参数,调大dirty_ratio,提高刷新频率,问题依然没有解决,在写入的同时,监控脏页数量,最大时不超过10MB,根本不会达到阻塞请求的比例。排除因素
3、 磁盘日志
ext4磁盘有三种磁盘日志策略,分别是journal、ordered、writeback,性能依次提高,默认采用ordered,Kafka给出对ext4磁盘给出的优化建议是可以采用writeback,因为kafka不要求日志的顺序,可以靠副本同步解决这一问题。采用writeback可以减小延迟,甚至可以完全禁用日志。通过两种方式测试,发现偶尔几秒的大延迟问题依然存在。排除因素
三、 问题解决
修改linux脏页刷新策略,ext4磁盘挂载配置等方案的被排除后,写入磁盘偶尔耗时高仍然未能定位。通过一个简单脚本,每秒写入磁盘文件一次,此时压力很小,还是会出现偶尔写入耗时超过1s。确定磁盘写入随机会出现超时,且与配置无关。通过搜索单纯的磁盘写入偶尔耗时大相关问题,linkedin大牛,kafka作者,Jay Kreps同样发现了这个问题,且进行了深入研究。
链接: https://blog.csdn.net/jus3ve/article/details/78336976
1、 delayed allocation和磁盘日志
通过对内核写入文件的监控,发现两项耗时巨大的操作,其一是之前提过的日志,第二种则是delayed allocation,delayed allocation是指在写入文件页缓存时,并不在磁盘实际申请空间,而由系统统一申请,这样不会频繁申请,而提高吞吐。缺点则是在某一次写入时的耗时会很大,具体原因见链接。测试关闭delayed allocation和磁盘日志,问题同样还是出现。
2、 xfs系统
Jay最终解决方式是通过更换文件系统,采用最新的xfs,xfs对文件锁的处理优于ext4,性能也更佳。通过挂载xfs磁盘,问题仍然存在,原因在于xfs磁盘和ext4磁盘在同一台机器,ext4磁盘偶尔使io使用率超过100%,影响xfs磁盘写入。最终,在windows的linux子系统与vmware虚拟机中的centos7中测试,不会在出现写入偶尔耗时大的问题,两个系统的文件系统分别为lxfs和xfs。
同时,第一个因素同样可能由于磁盘互相影响,暂未进行测试。
结论:
Kafka官方推荐文件系统使用xfs,centos7之后默认文件系统为xfs,为保证kafka消息时延稳定,kafka集群需优先使用xfs文件系统。上述其他因素,虽在此次问题中,被一一排除,但在消息量大,负载高时,触发了相关条件,也可能会造成消息时延,同样需要深入了解,以便后续问题解决。