基本创建
Session对象创建
//提供Session对象
val session = SparkSession
.builder() //构建器
.appName("sparkSQL") //序名称程
.master("local[*]") //执行方式:本地
.enableHiveSupport() //支持hive相关操作
.getOrCreate() //创建对象加载文件
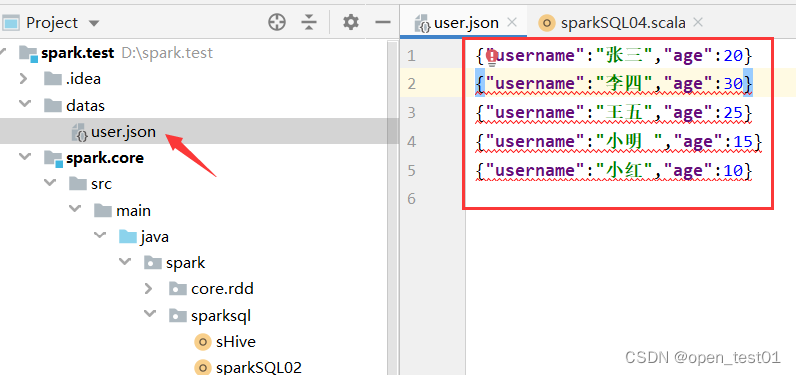
//加载数据文件
val df: DataFrame = session.read.json("datas\\user.json")sparkSQL编程时支持两套语法 :
- DSL语法:结合SQL中的关键字作为函数(算子)的名字传递参数进行编程的方式(接近RDD编程)
- SQL语法:直接写当前需求SQL或HQL语言运行当前编程(这种方式为sparkSQL编程的主流)
DSL语法
使用printSchema()打印表中结构
df.printSchema()打印的结果为二维表的结构

使用show()查看表中信息
该方法约等于 select * from user
df.show()
使用select()查询字段
针对查询某列的数据
df.select("age").show()
导入sparkSession隐式转换操作
增强sql的功能:涉及到列运算时 需要使用到$符号
import session.implicits._ //此处session为当前使用的对象
df.select($"username",$"age").show()
df.select('username,'age).show()
df.select($"username",$"age"+2).show()
使用创建Column方式进行列运算并使用as方法修改别名
df.select(new Column("age").+(2).as("年龄加2")).show()
分组聚合操作:统计不同年龄人数
df.select("age").groupBy("age").count().show()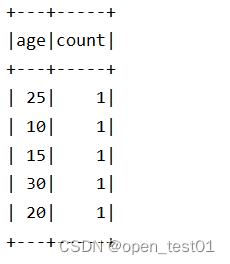
条件查询 :获取年龄大于20的数据
df.select("username","age").where("age > 20").show()
SQL语法
使用SQL的必要前提是要将当前的数据转换为表或视图的形式,SQL语法操作中提供两种表:
1、临时视图表,作用域只在Session应用范围内有效(常用)
没有Replace名称的表不会被覆盖
df.createOrReplaceTempView("user")2、 全局临时表,作用域在整个应用范围都内有效
使用全局临时表时需要全路径访问:如gloabl_temp.表名
global为当前sparkAPPlication中可以使用 非global只能在SparkSession中使用
df.createGlobalTempView("user")
session.sql(
"""
|select * from global_temp.user
|""".stripMargin).show()
}