文章目录
R的数据对象
R对象的类型划分
从存储角度划分R对象
(1)数值型
整数型和实数型;整数型(Integer)是整数的存储形式,通常需要2字节或4字节的存储空间。实数型用来存储包含小数位的数值型数据,通常需要4字节或8字节存储空间。R中的数值型数据均默认为双精度型数。
(2)字符型
诸如姓名、籍贯,是由英文双引号括起来的一个字符序列,简称字符串。
(3)逻辑型
TRUE;FALSE
从数据组织结构角度划分R对象
(1)向量
向量是R数据组织的基本单位。从统计角度看,一个向量对应一个变量,存储着多个具有相同存储类型的变量值。若无明确说明,向量均为列向量。
因子(Factor)是一种特殊的向量。
(2)矩阵
矩阵是一个二维表格形式,用于组织多个具有相同存储类型的变量。矩阵的列通常为变量,行为观测。
(3)数组
数组是多张二维表的集合,一般用于组织统计中的面板数据等
(4)数据框
数据框也是一张二维表格,与矩阵有类似之处,但用于组织存储类型不尽相同的多个变量。其中,数据框的列通常为变量,行为观测。
(5)列表
多个向量、矩阵、数组、数据框、列表的集合即为列表。多用于相关统计分析结果的“打包”集成。
创建和管理R对象
创建R对象
对象名<-R常量或R函数
访问R对象
print(对象名)
查看R对象的结构
str(对象名)
管理R对象
ls()当前工作空间中的对象名列表将显示在R的控制台窗口中
rm(对象名或对象名列表)对象名列表中包含多个对象名,各个对象之间用英文逗号分隔
remove(对象名)删除当前工作空间中的指定对象
R数据组织的基本方式
R向量及其创建与访问
is.vector(对象名)#判断对象是否为向量
最简单的R向量
> #创建包含一个元素的向量
> V1<-100 #创建整数形式的数值型向量V1,存储类型默认为双精度型
> V1 #显示V1的对象值
[1] 100
> V2<-123.5 #创建实数形式的数值型向量V2,存储类型为双精度型
> V2
[1] 123.5
> V3<-"abcd" #创建字符串型向量V3
> print(V3) #显示V3对象值
[1] "abcd"
> (V4<-TRUE) #创建逻辑型向量V4,并直接显示对象值
[1] TRUE
> is.vector(V1) #判断对象V1是否为向量
[1] TRUE
> is.logical(V4) #判断对象V4的存储类型是否为逻辑型
[1] TRUE
①若将赋值语句放入圆括号中,则表示创建对象,并直接显示对象值
②显示对象值时各行会自动以方括号开头,如[1],方括号中的数字表示对应行的第一个元素是R向量对象中的第几个元素。
利用R向量组织变量
SiteName<-c("东四","天坛","官园","万寿西宫","奥体中心","农展馆","万柳","北部新区","植物园","丰台花园",
"云岗","古城","房山","大兴","亦庄","通州","顺义","昌平","门头沟","平谷","怀柔","密云","延庆","定陵",
"八达岭","密云水库","东高村","永乐店","榆垡","琉璃河","前门","永定门内","西直门北","南三环","东四环")
SiteTypes<-c(rep("城区环境评价点",12),rep("郊区环境评价点",11),rep("对照点及区域点",7),rep("交通污染监控点",5))
> length(SiteName)
[1] 35
> length(SiteTypes)
[1] 35
rep("城区环境评价点",12)表示重复生成12个城区环境评价点
访问R向量中的元素
> a<-vector(length=10)#创建包含10个元素的向量a
> a#显示初始值
[1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
> a[1]<-1#访问第一个元素,并赋值为1
> a[2:4]<-c(2,3,4)#访问第2至第4个元素,并赋值为2,3,4
> a
[1] 1 2 3 4 0 0 0 0 0 0
> b<-seq(from=5,to=9,by=1)#生成一个取值5至9的序列给向量b
> b
[1] 5 6 7 8 9
> a[c(5:9,10)]<-c(b,10)
> a
[1] 1 2 3 4 5 6 7 8 9 10
> b<-(2:4)#创建数值型位置向量b,依次取值为2,3,4
> a[b]#访问a中位置向量b所指位置(即2,3,4)上的元素
[1] 2 3 4
> b<-c(TRUE,FALSE,FALSE,TRUE,FALSE,FALSE,FALSE,FALSE,FALSE,FALSE)#创建逻辑型向量b
> a[b]#访问a中位置向量b取值为TRUE位置(即1,4)上的元素
[1] 1 4
> a[-1]#访问除第一个元素以外的元素
[1] 2 3 4 5 6 7 8 9 10
> a[-(2:4)]#访问除第2至第4个元素以外的元素
[1] 1 5 6 7 8 9 10
> a[-c(5:9,10)]#访问除第5至第9以及第10个元素以外的元素
[1] 1 2 3 4
> b<-(2:4)
> a[-b]#访问除位置向量b以外的元素
[1] 1 5 6 7 8 9 10
> ls()#显示当前工作空间中的对象列表
[1] "a" "b"
> rm(a,b)#删除当前工作空间中的对象a和对象b
R的特殊向量:因子
> (a<-c("Poor","Improved","Excellent","Poor"))#创建包含4个元素的字符型向量a
[1] "Poor" "Improved" "Excellent" "Poor"
> is.vector(a)#判断a是否为向量
[1] TRUE
> (b<-as.factor(a))#将字符型向量a转换为因子b并显示b
[1] Poor Improved Excellent Poor
Levels: Excellent Improved Poor
> is.factor(b)#判断b是否为因子
[1] TRUE
> levels(b)#按因子水平值升序显示所对应的类别值
[1] "Excellent" "Improved" "Poor"
> typeof(b)#显示因子b的存储类型名
[1] "integer"
> (a<-c("Poor","Improved","Excellent","Poor"))#创建字符型向量a
[1] "Poor" "Improved" "Excellent" "Poor"
> (b<-factor(a,order=FALSE,levels=c("Poor","Improved","Excellent")))#指定类别值和水平值的对应关系
[1] Poor Improved Excellent Poor
Levels: Poor Improved Excellent
> (b<-factor(a,order=TRUE, levels=c("Poor","Improved","Excellent")))
[1] Poor Improved Excellent Poor
Levels: Poor < Improved < Excellent
> (a<-c("Poor","Improved","Excellent","Poor"))
[1] "Poor" "Improved" "Excellent" "Poor"
> (b<-factor(a,levels=c("Poor","Improved","Excellent")))
[1] Poor Improved Excellent Poor
Levels: Poor Improved Excellent
> (b<-factor(a,levels=c("Poor","Improved","Excellent"),labels=c("C","B","A")))
[1] C B A C
Levels: C B A
levels为原类别值;labels为新类别值
R矩阵和数组及其创建与访问
将多个向量合并成R矩阵
> Site<-cbind(SiteName,SiteTypes)
> is.matrix(Site)#判断对象是否为矩阵
[1] TRUE
> dim(Site)#获得矩阵的行数和列数
[1] 35 2

将向量转换成R矩阵
> (a<-c("Poor","Improved","Excellent","Poor"))
[1] "Poor" "Improved" "Excellent" "Poor"
> data<-(1:30)#生成一个名为data的数值型向量
> data<-matrix(data,nrow=5,ncol=6,byrow=FALSE)#将向量a按列排列放置到5行6列的矩阵中
> data
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 6 11 16 21 26
[2,] 2 7 12 17 22 27
[3,] 3 8 13 18 23 28
[4,] 4 9 14 19 24 29
[5,] 5 10 15 20 25 30
访问R矩阵中的元素
> data[2,3]#第2行第3列
[1] 12
> data[1:2,2:3]#访问第1行至第2行,第2列至第3列位置上的元素
[,1] [,2]
[1,] 6 11
[2,] 7 12
> data[1:2,c(1,3)]#访问第1行至第2行,第1,3列位置上的元素
[,1] [,2]
[1,] 1 11
[2,] 2 12
> data[2,]#访问第2行上的所有元素
[1] 2 7 12 17 22 27
> data[c(1,3),]#访问第1,3行上的所有元素
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 6 11 16 21 26
[2,] 3 8 13 18 23 28
> a<-c(TRUE,FALSE,TRUE,FALSE,FALSE)
> data[a,]
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 1 6 11 16 21 26
[2,] 3 8 13 18 23 28
> data[,1:3]#访问1-3列上的所有元素
[,1] [,2] [,3]
[1,] 1 6 11
[2,] 2 7 12
[3,] 3 8 13
[4,] 4 9 14
[5,] 5 10 15
> a<-matrix(nrow=5,ncol=2)#创建一个5x2的矩阵,初始值默认为缺失值
> a
[,1] [,2]
[1,] NA NA
[2,] NA NA
[3,] NA NA
[4,] NA NA
[5,] NA NA
> a[,1]<-seq(from=1,to=10,by=2)#给矩阵第1列赋值
> a[,2]<-seq(from=10,to=1,by=-2)#给矩阵第2列赋值
> a
[,1] [,2]
[1,] 1 10
[2,] 3 8
[3,] 5 6
[4,] 7 4
[5,] 9 2
创建和访问R数组
> a<-(1:60)
> dim1<-c("R1","R2","R3","R4")
> dim2<-c("C1","C2","C3","C4","C5")
> dim3<-c("T1","T2","T3")
> a<-array(a,c(4,5,3),dimnames = list(dim1,dim2,dim3))
> a#数组a由3张行数为4列数为5的二维表组成
> is.array(a)#判断a是否为数组
[1] TRUE
> a[1:3,c(1,3),2]#第2张表1-3行,1,3列
C1 C3
R1 21 29
R2 22 30
R3 23 31
R数据框及其创建与访问
创建R数据框
> #创建数据框
> SiteName<-c("东四","天坛","官园","万寿西宫","奥体中心","农展馆","万柳","北部新区","植物园","丰台花园",
+ "云岗","古城","房山","大兴","亦庄","通州","顺义","昌平","门头沟","平谷","怀柔","密云","延庆","定陵",
+ "八达岭","密云水库","东高村","永乐店","榆垡","琉璃河","前门","永定门内","西直门北","南三环","东四环")
> SiteTypes<-c(rep("城区环境评价点",12),rep("郊区环境评价点",11),rep("对照点及区域点",7),rep("交通污染监控点",5))
> SiteX<-c(116.417,116.407,116.339,116.352,116.397,116.461,116.287,116.174,116.207,116.279,116.146,116.184,
+ 116.136,116.404,116.506,116.663,116.655,116.23,116.106,117.1,116.628,116.832,115.972,
+ 116.22,115.988,116.911,117.12,116.783,116.30,116.00,
+ 116.395,116.394,116.349,116.368,116.483)
> SiteY<-c(39.929,39.886,39.929,39.878,39.982,39.937,39.987,40.09,40.002,39.863,39.824,39.914,
+ 39.742,39.718,39.795,39.886,40.127,40.217,39.937,40.143,40.328,40.37,40.453,
+ 40.292,40.365,40.499,40.10,39.712,39.52,39.58,
+ 39.899,39.876,39.954,39.856,39.939)
> Site<-data.frame(Sitename=SiteName,Sitetypes=SiteTypes,Sitex=SiteX,Sitey=SiteY)
> names(Site)#显示数据框的域名
[1] "Sitename" "Sitetypes" "Sitex" "Sitey"
> str(Site)#显示对象的结构信息
'data.frame': 35 obs. of 4 variables:
$ Sitename : chr "东四" "天坛" "官园" "万寿西宫" ...
$ Sitetypes: chr "城区环境评价点" "城区环境评价点" "城区环境评价点" "城区环境评价点" ...
$ Sitex : num 116 116 116 116 116 ...
$ Sitey : num 39.9 39.9 39.9 39.9 40 ...
> is.data.frame(Site)#判断Site是否为数据框
[1] TRUE
> fix(Site)#显示部分数据内容
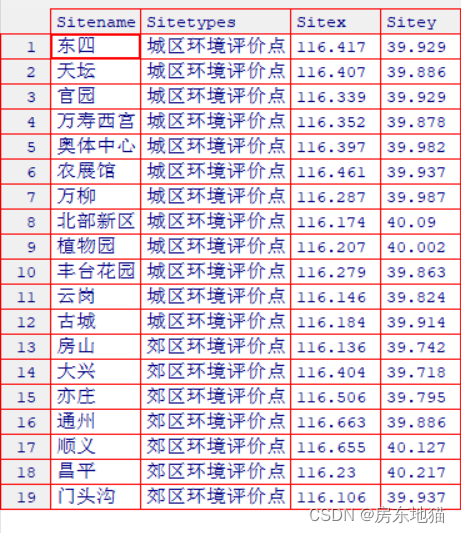
> head(Site)#仅显示数据框的前6行内容
Sitename Sitetypes Sitex Sitey
1 东四 城区环境评价点 116.417 39.929
2 天坛 城区环境评价点 116.407 39.886
3 官园 城区环境评价点 116.339 39.929
4 万寿西宫 城区环境评价点 116.352 39.878
5 奥体中心 城区环境评价点 116.397 39.982
6 农展馆 城区环境评价点 116.461 39.937
> head(Site$Sitename)#访问Sitename域且仅显示前6条内容
[1] "东四" "天坛" "官园" "万寿西宫" "奥体中心" "农展馆"
> tail(Site[["Sitename"]])#访问Sitename域且仅显示后6条内容
[1] "琉璃河" "前门" "永定门内" "西直门北" "南三环" "东四环"
> head(Site[1])#访问第一个域且仅显示前6条内容
Sitename
1 东四
2 天坛
3 官园
4 万寿西宫
5 奥体中心
6 农展馆
> tail(Site[c("Sitename","Sitetypes")])#访问Sitename和Sitetypes域且仅显示后6条内容
Sitename Sitetypes
30 琉璃河 对照点及区域点
31 前门 交通污染监控点
32 永定门内 交通污染监控点
33 西直门北 交通污染监控点
34 南三环 交通污染监控点
35 东四环 交通污染监控点
> attach(Site)#绑定Site数据框
> head(Sitename)
[1] "东四" "天坛" "官园" "万寿西宫" "奥体中心" "农展馆"
> detach(Site)#解除Site数据框的绑定
> head(Sitename)
Error in head(Sitename) : object 'Sitename' not found
R列表及其创建与访问
> a<-c(1,2,3)#创建向量a
> b<-matrix(nrow=5,ncol=2)#创建矩阵b
> b[,1]=seq(from=1,to=10,by=2)
> b[,2]=seq(from=10,to=1,by=-2)
> c<-array(1:60,c(4,5,3))#创建数组c
> d<-list(L1=a,L2=b,L3=c)#创建列表d
> names(d)#显示列表d各成分名
[1] "L1" "L2" "L3"
> str(d)#显示对象d的存储类型和结构信息
List of 3
$ L1: num [1:3] 1 2 3
$ L2: num [1:5, 1:2] 1 3 5 7 9 10 8 6 4 2
$ L3: int [1:4, 1:5, 1:3] 1 2 3 4 5 6 7 8 9 10 ...
> is.list(d)#判断d是否为列表
[1] TRUE
> d$L1#访问列表d中的成分L1
[1] 1 2 3
> d[[2]]#访问列表d中的第二个成分(L2)
[,1] [,2]
[1,] 1 10
[2,] 3 8
[3,] 5 6
[4,] 7 4
[5,] 9 2
R数据组织的其他问题
R对象数据的保存
write.table(Site,file="监测点信息.txt",row.names=FALSE,col.names=FALSE)
row.names=FALSE,col.names=FALSE
不将行编号和变量名写入文本文件
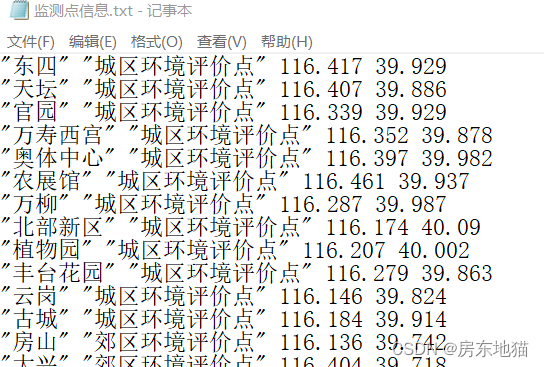
通过键盘读入数据
> a<-scan()#R将在控制台窗口等待用户输入数据,每个数据以回车键分隔
1: 10
2: 20
3: 30
4:
Read 3 items
> a
[1] 10 20 30
输入截止时,不输入内容直接回车键就行
共享R自带的数据包
data(),显示的数据集名和说明信息如下图
data("数据集名")#指定加载使用某个数据集
大数据案例的数据结构和R组织
读文本文件数据到R数据框
> getwd()#获取当前工作目录
[1] "D:/Program Files/RStudio/Projects"
> setwd("./课程数据集")#改变工作目录
> MyData<-read.table(file = "空气质量.txt",header = TRUE,sep=" ",stringsAsFactors = FALSE)
> str(MyData)
'data.frame': 12705 obs. of 11 variables:
$ SiteName : chr "奥体中心" "奥体中心" "奥体中心" "奥体中心" ...
$ date : int 20160101 20160626 20160505 20160307 20160907 20160314 20160717 20160122 20161119 20160526 ...
$ PM2.5 : num 165 39.9 48.7 50 40.2 ...
$ AQI : num 154.6 68.1 55.1 120.8 67.9 ...
$ CO : num 3.929 0.454 0.946 0.992 0.607 ...
$ NO2 : num 122.6 35.1 41 30.4 43.7 ...
$ O3 : num 10.7 119.2 82.1 53.3 106.9 ...
$ SO2 : num 45.67 4.88 14.83 14.83 4 ...
$ SiteTypes: chr "城区环境评价点" "城区环境评价点" "城区环境评价点" "城区环境评价点" ...
$ SiteX : num 116 116 116 116 116 ...
$ SiteY : num 40 40 40 40 40 ...