SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE
SqueezeNet:与AlexNet同等精度,参数量比AlexNet小50倍,模型尺寸< 0.5MB的网络;
发表时间:[Submitted on 24 Feb 2016 (v1), last revised 4 Nov 2016 (this version, v4)];
发表期刊/会议:Computer Vision and Pattern Recognition;
论文地址:https://arxiv.org/abs/1602.07360;
代码地址:https://github.com/DeepScale/SqueezeNet;
0 摘要
给定一个精度,能够达到这个精度的CNN模型有很多;
具有相同的精度,较小的CNN架构至少提供三个优势:
- 较小的CNN在分布式训练中需要较少的服务器之间的通信(易于训练);
- 较小的CNN需要更少的带宽来将新模型从云端导出到自动驾驶汽车(易于下载/传输);
- 较小的CNN更适合部署在FPGA和其他内存有限的硬件上(易于部署);
本文提出了一个名为SqueezeNet的小型CNN架构,包含以上所有优势;
SqueezeNet在ImageNet上达到AlexNet级别的精度,但参数少了50倍。
此外,通过模型压缩技术,能够将SqueezeNet压缩到小于0.5MB(比AlexNet小510倍)。
1 简介
小CNN的优势,如摘要所示;
本文提出模型,称之为SqueezeNet;
此外,本文提出了一种更有纪律的方法来搜索新的CNN架构的设计空间;
2 相关工作
2.1 模型压缩MODEL COMPRESSION
奇异值分解(singular value decomposition)【(Denton et al, 2014)】;
网络剪枝(Network Pruning) 【Han et al, 2015b】;
深度压缩(Deep Compression)【Han et al, 2015a】;
硬件加速器(hardware accelerator)【Han et al, 2016a】;
2.2 CNN微架构CNN MICRO ARCHITECTURE
NiN【Lin et al, 2013】;
VGG【Simonyan & Zisserman, 2014】;
GoogLeNet系列【zegedy et al, 2014; Ioffe & Szegedy, 2015; Szegedy et al, 2015; 2016】;
定义CNN微架构(CNN MICRO ARCHITECTURE):由不同模块堆叠的架构,模块由一些卷积组成;
2.3 CNN宏架构CNN MACRO ARCHITECTURE
定义CNN宏架构(CNN MACRO ARCHITECTURE):端到端CNN体系结构,层数/深度是重要的影响因素之一;
2.4 神经网络的设计空间NEURAL NETWORK DESIGN SPACE EXPLORATION
神经网络(Neural networks, NNs)有很大的设计空间,包括:微架构、宏架构、求解器(solver caffe)、超参数;人们想要知道这些因素如何影响NNs的精度;
一些工作:
- 贝叶斯优化(Snoek et al, 2012);
- 模拟退火(Ludermir et al, 2006);
- 随机搜索(Bergstra & Bengio, 2012);
- 遗传算法(Stanley & Miikkulainen, 2002);
在本文的后面部分,我们避免使用自动化方法——相反,我们以这样一种方式重构CNN,我们可以进行原则性的 A/B 比较,以调查CNN架构决策如何影响模型大小和准确性。
3 SqueezeNet:保留精度的同时参数更少
3.1 架构设计策略 ARCHITECTURAL DESIGN STRATEGIES
-
- 将3x3滤波器替换为1x1滤波器:给定一定数量的卷积滤波器的预算,我们将选择使这些滤波器中的大多数为1x1,因为1x1滤波器的参数比3x3滤波器少9倍。
-
- 减少输入到3×3滤波器的输入通道:一层的 参数总数 = ( i n p u t _ c h a n n e l ) ∗ ( f i l t e r s ) ∗ ( 3 × 3 ) 参数总数=(input\_channel) * (filters) * (3×3) 参数总数=(input_channel)∗(filters)∗(3×3),通过 squeeze 层来减少;
-
- 在网络的后期进行下采样,这样卷积层就有了大的激活映射:如果网络中的前3层具有降采样,那么大多数层将具有较小的激活映射;
1)和2) 在试图保持准确性的同时减少了CNN中的参数量,3)是在有限的参数预算下最大化精度;
3.2 FIRE模块
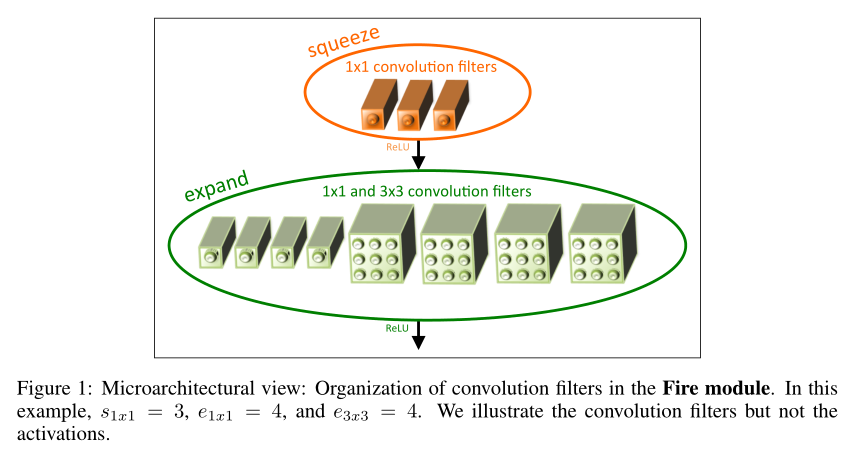
定义Fire模块如下,包含三个部分,如图1所示:
- squeeze卷积层,只包含1x1卷积;
- expand层,1×1卷积,
- expand层,3×3卷积;
对应3.1节策略1;
引入三个超参数:
- squeeze层, s 1 x 1 s_{1x1} s1x1:1×1卷积的数量;
- expand层, e 1 x 1 e_{1x1} e1x1:1×1卷积的数量;
- expand层, e 3 x 3 e_{3x3} e3x3:3×3卷积的数量;
当我们使用Fire模块时,我们将 s 1 x 1 s_{1x1} s1x1设置为小于( e 1 x 1 e_{1x1} e1x1 + e 3 x 3 e_{3x3} e3x3),因此squeeze层有助于限制输入通道的数量,如第3.1节中的策略2所示。
Pytorch实现:
class Fire(nn.Module):
def __init__(self, inplanes: int, squeeze_planes: int, expand1x1_planes: int, expand3x3_planes: int) -> None:
super().__init__()
self.inplanes = inplanes
# squeeze 1*1卷积
self.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1)
self.squeeze_activation = nn.ReLU(inplace=True)
# expand 1*1卷积
self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes, kernel_size=1)
self.expand1x1_activation = nn.ReLU(inplace=True)
# expand 3*3卷积
self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes, kernel_size=3, padding=1)
self.expand3x3_activation = nn.ReLU(inplace=True)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.squeeze_activation(self.squeeze(x))
return torch.cat(
[self.expand1x1_activation(self.expand1x1(x)), self.expand3x3_activation(self.expand3x3(x))], 1
3.3 SQUEEZENET架构
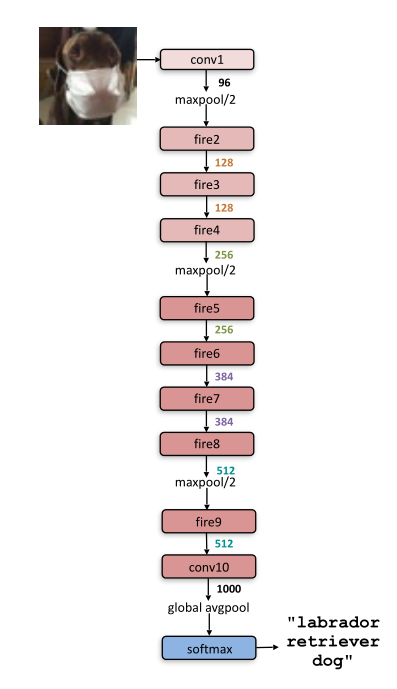
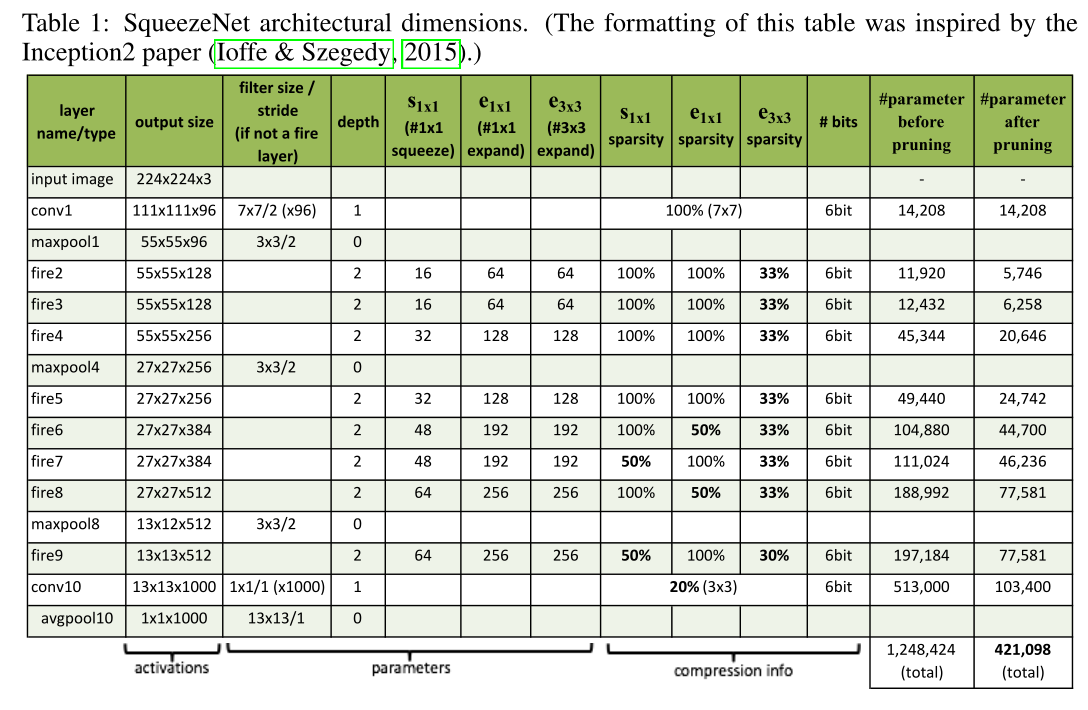
架构如下图所示,细节见表1:
SqueezeNet从一个独立的卷积层(conv1)开始,接着是8个Fire模块(fire2-9),以最终的conv层(conv10)结束;
Pytorch实现:
class SqueezeNet(nn.Module):
def __init__(self, version: str = "1_0", num_classes: int = 1000, dropout: float = 0.5) -> None:
super().__init__()
self.num_classes = num_classes
if version == "1_0":
self.features = nn.Sequential(
# conv1
nn.Conv2d(3, 96, kernel_size=7, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
# fire2
Fire(96, 16, 64, 64),
Fire(128, 16, 64, 64),
Fire(128, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 32, 128, 128),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
# fire9
Fire(512, 64, 256, 256),
)
# Final convolution is initialized differently from the rest
# conv10
final_conv = nn.Conv2d(512, self.num_classes, kernel_size=1)
self.classifier = nn.Sequential(
nn.Dropout(p=dropout), final_conv, nn.ReLU(inplace=True), nn.AdaptiveAvgPool2d((1, 1))
)
for m in self.modules():
if isinstance(m, nn.Conv2d):
if m is final_conv:
init.normal_(m.weight, mean=0.0, std=0.01)
else:
init.kaiming_uniform_(m.weight)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.classifier(x)
return torch.flatten(x, 1)
3.3.1 SqueezeNet其他细节
- 为了使1x1和3x3滤波器的输出激活具有相同的高度和宽度,我们在扩展模块的3x3滤波器的输入数据中添加了一个1像素的0 padding;
- 非线性激活使用ReLU;
- 在fire9模块之后应用50%比例的Dropout;
- SqueezeNet中没有全连接层;
- 0.04的学习率开始,在整个训练过程中我们线性地降低学习率;
4 SqueezeNet性能评估
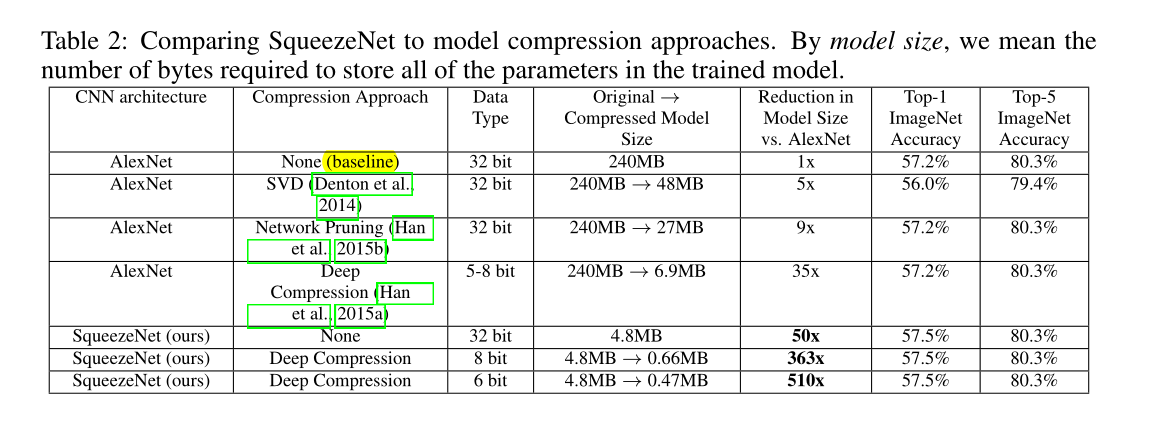
在评估SqueezeNet时,我们使用AlexNet和相关的模型压缩结果作为比较的基础。
与AlexNet相比,SqueezeNet的模型尺寸减少了50倍,同时达到或超过AlexNet的Top-1和Top-5的精度【表2倒数第3行所示】;
将深度压缩应用于SqueezeNet:
- 33%稀疏性和8位量化:得到0.66 MB的模型(比32位的AlexNet小363×),精度与AlexNet相当【表2倒数第2行所示】;
- 33%稀疏性和6位量化:得到0.47MB的模型(比32位AlexNet小510倍),具有相同的精度【表2倒数第1行所示】;
本文的小模型确实经得起压缩。
5 CNN微架构设计空间探索
请注意,在这里的目标不是最大化每个实验的准确性,而是理解CNN架构选择对模型大小和准确性的影响。
5.1 参数影响
3.2节中提出Fire模块的三个参数: s 1 x 1 s_{1x1} s1x1、 e 1 x 1 e_{1x1} e1x1 、 e 3 x 3 e_{3x3} e3x3;SqueezeNet共有8个Fire模块,共 3 × 8 = 24 3×8=24 3×8=24个参数;
定义:
- b a s e e base_e basee:CNN中第一个Fire模块中的扩展(expand)滤波器的数量;
- 在每个fire模块之后,增加的扩展滤波器的数量 i n c r e e incre_e incree;
- freq:fire module数量;
- e i e_i ei:每freq个fire模块中,expand滤波器的数量;
- p c t 3 x 3 pct_{3x3} pct3x3:expand层3∗3卷积占卷积总个数的比例,即 e i , 3 x 3 = e i ∗ p c t 3 x 3 e_{i,3x3} = e_i ∗ pct{3x3} ei,3x3=ei∗pct3x3, e i , 1 x 1 = e i ∗ ( 1 − p c t 3 x 3 ) e_{i,1x1} = e_i ∗ (1 − pct_{3x3}) ei,1x1=ei∗(1−pct3x3);
- SR(squeeze ratio):压缩比,squeeze layer中filter个数除以Fire module中filter总个数, s i , 1 x 1 = S R ∗ ( e i , 1 x 1 + e i , 3 x 3 ) ) s_{i,1x1} = SR ∗ (e_{i,1x1} + e_{i,3x3})) si,1x1=SR∗(ei,1x1+ei,3x3));
第3节中的SqueezeNet参数为: b a s e e = 128 , i n c r e = 128 , p c t 3 x 3 = 0.5 , f r e q = 2 , a n d S R = 0.125 base_e = 128, incr_e = 128, pct_{3x3} = 0.5, freq = 2, and SR = 0.125 basee=128,incre=128,pct3x3=0.5,freq=2,andSR=0.125;
每层滤波器数量:
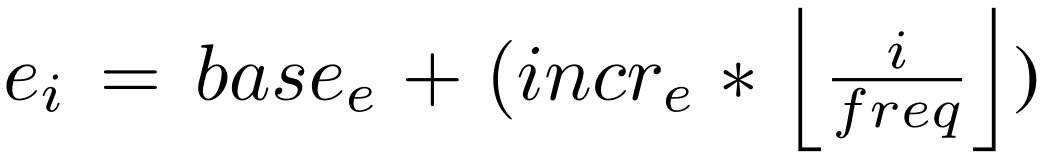
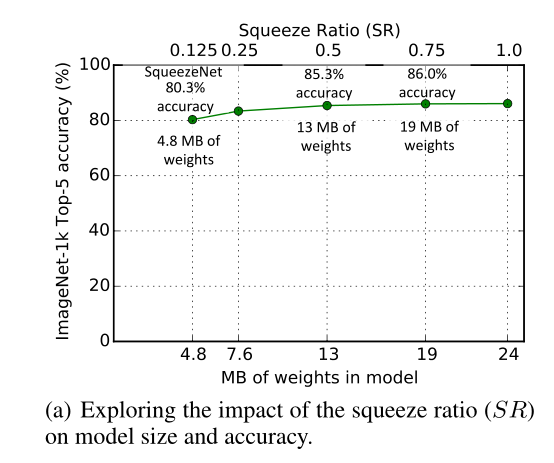
5.2 Squeeze Ratio压缩比
将SR增加到0.125以上可以进一步将ImageNet top-5的准确率从4.8MB模型的80.3%(即AlexNet水平)提高到19MB模型的86.0%;
SR=0.75(一个19MB的模型)时,精确度为86.0%,设置SR=1.0进一步增加了模型的大小,但没有提高精度;
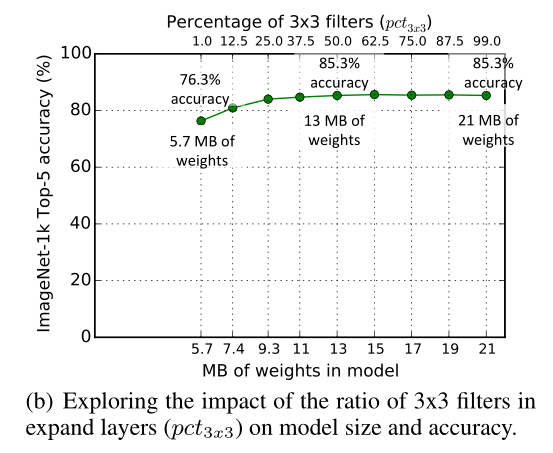
5.3 1×1滤波器和3×3滤波器之间的权衡
用1x1滤波器替换一些3x3滤波器来减少CNN中的参数数量,但是是否会影响CNN的空间分辨率/空间信息?
使用50%的3x3滤波器时,top-5为85.6%,进一步增加3x3滤波器的百分比会导致更大的模型尺寸,但在ImageNet上的精度没有提高。
6 CNN宏架构设计空间探索
受ResNet启发,探索以下三种架构:
- Vanilla SqueezeNet;
- SqueezeNet + Simple Bypass;
- SqueezeNet + Complex Bypass;
架构如图2所示:

结果如表3所示:
