NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING
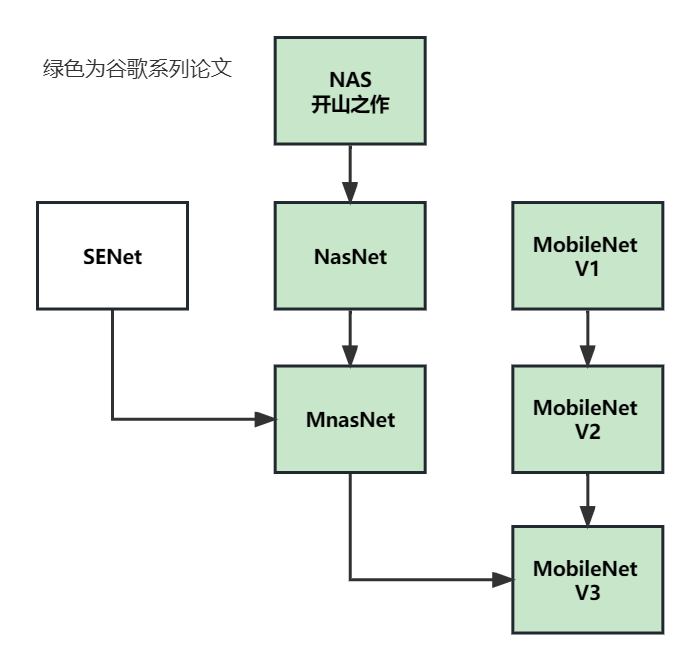
神经网络搜索与强化学习
NAS:Neural Architecture Search 神经网络搜索(不用人力来设计网络 用AI来搜索AI 炼丹 烧钱的魔法);
【搜索出的架构并不重要,重要的是搜索方法和思想】
发表时间:[Submitted on 5 Nov 2016 (v1), last revised 15 Feb 2017 (this version, v2)]
发表期刊/会议:ICLR 2017;
论文地址:https://arxiv.org/abs/1611.01578v2;
代码地址:https://github.com/tensorflow/models;
系列论文阅读顺序:
0 摘要
神经网络难以设计;
本文使用RNN作为controller来生成神经网络模型的描述,并用强化学习来训练RNN,以最大限度地提高在验证集上模型的准确性,从而生成高性能架构;
1 简介
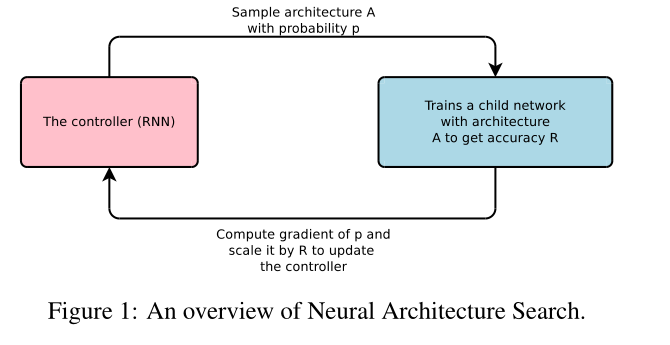
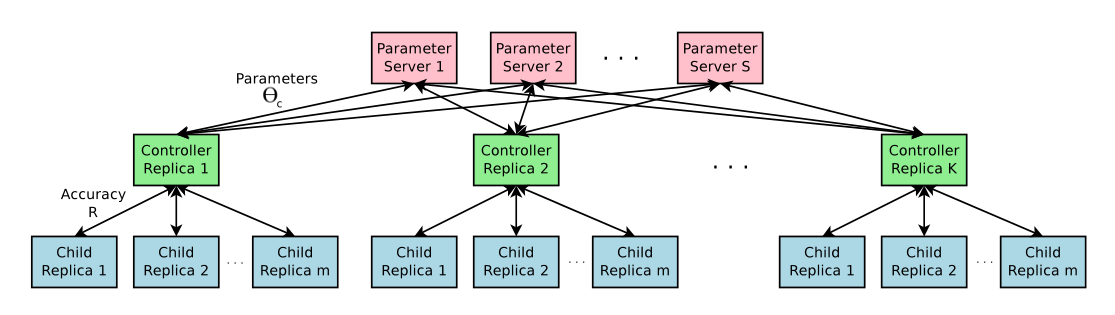
如下图1所示,RNN作为controller生成网络架构A,以此生成的网络作为基础训练子网络,在相应的数据集上进行训练,计算精度R,计算梯度并最大化R进行反向传播更新梯度,作为奖励(reward)返回给RNN,以此来迭代优化(详细内容见强化学习);
3 方法
3.1 用RNN生成模型描述(NAS for CNN)
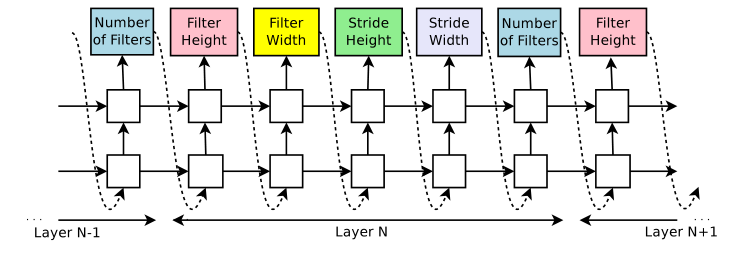
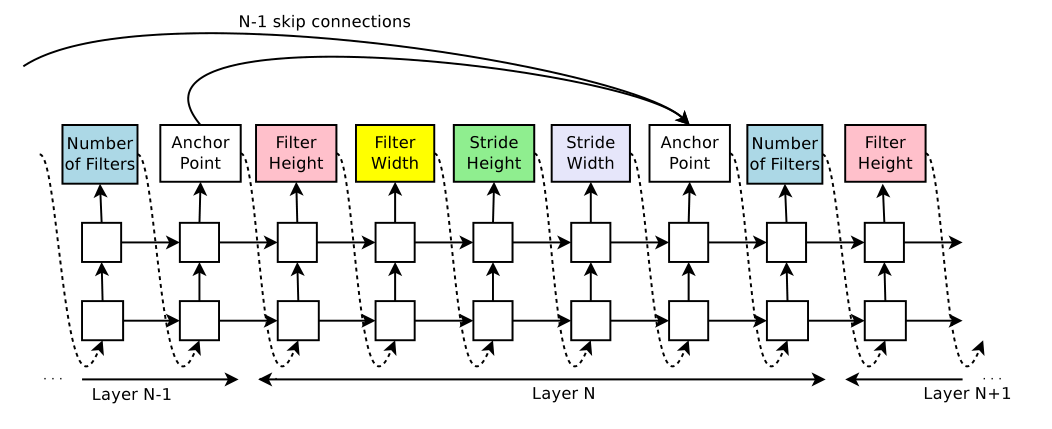
如图2所示,RNN生成tokens(就是一个向量)作为模型的超参数;
随便举个例子…
t o k e n = [ 3 , 3 , 1 , 1 , 5 ] token = [3,3,1,1,5] token=[3,3,1,1,5] 代表Layer N有,filter height = 3,filter width = 3,stride height = 1,stride width = 1,有5个filter;
生成的token对应唯一一个模型,建立这个模型并在数据集上进行训练;收敛后,记录验证集上的精度R,以此为奖励更新RNN的参数 θ c θ_c θc,在下一轮迭代中, θ c θ_c θc指导RNN生成更好的CNN;
3.2 强化学习训练
a 1 : T a_{1:T} a1:T代表RNN每部分的操作,比如1代表filter height,2代表filter width,…,T代表number of filters;
目标函数 J ( θ c ) J(θ_c) J(θc):
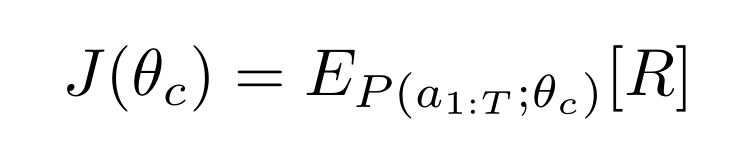
采用【Simple statistical gradient-following algorithms for connectionist reinforcement learning. 】一文的强化学习优化方法,将参数R设置为可求导的(不然无法更新);
目标函数求导:
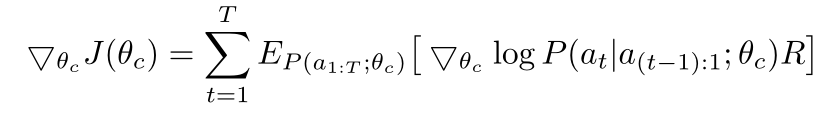
上式根据经验简化:
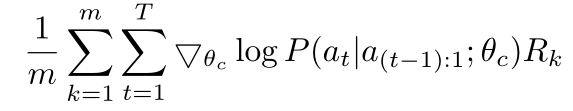
m:RNN(controller)在同一batch中采样的不同架构的数量;
T:生成不同网络架构所需的超参数数量;
R k R_k Rk:第k个网络架构的精度;
但是此式有很高的方差,为了减少估计的方差,采用了基线函数:
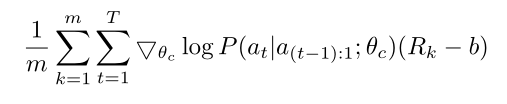
b:之前架构的指数移动平均值;
使用并行训练和异步更新加速训练
训练子网络所需的时间可能非常长,使用分布式训练和异步更新来控制controller的学习过程;
如图3所示;
3.3 使用残差连接和其他层类型增加体系结构的复杂性
本节将介绍一种方法,允许模型有残差连接,从而扩大搜索空间。
使用了一种集选择(set-selection)类型的注意力,在Layer N,添加一个锚点(anchor point),和前面的Layer N-1的内容连接;

h j h_j hj:第j层隐层的状态, j ∈ [ 0 , N − 1 ] j∈[0,N-1] j∈[0,N−1];
W p r e v W_{prev} Wprev, W c u r r W_{curr} Wcurr, v T v^T vT:可学习的参数;
通过一个sigmoid激活函数和tanh激活函数联系当前结点和之前结点的信息;
残差连接可能导致“编译失败”,因为其中一层与另一层不兼容,或者一层可能没有任何输入或输出。 为了避免这些问题,本文采用了三种简单的技术:
- 首先,如果一个层没有连接到任何输入层,那么图像将被用作输入层;
- 其次,在最后一层,将未连接的所有层输出连接起来,然后将最终隐藏状态发送给分类器;
- 最后,如果要连接的输入层具有不同的大小,我们用0填充小层,以便连接的层具有相同的大小;
3.1节中不预测学习率,其它类型的层,实际上还可以预测学习率、池化层、batch norm等等;
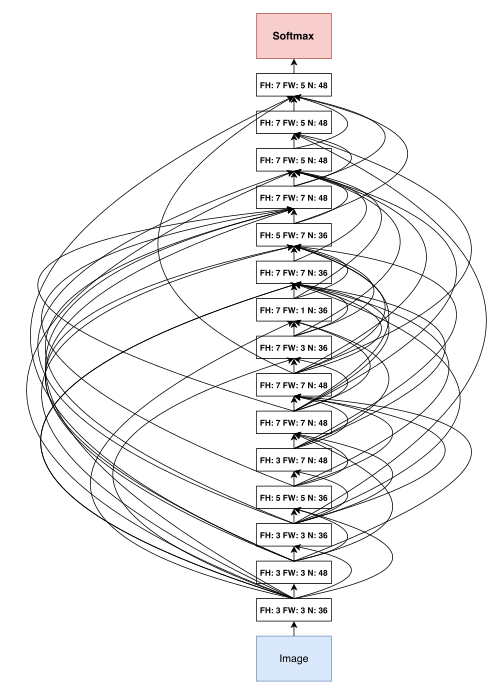
搜索出的架构见图7(附录);
3.4 生成循环单元结构(NAS for RNN)
上面提到的都是生成普通的CNN,本节将模型改造,使得可以生成类似LSTM的训练单元结构;
如图5左所示,树具有三个节点,两个叶子节点0和1,一个内部节点2,输入 h t − 1 h_{t-1} ht−1和 x t x_t xt:
- 需要预测三个block,每个block为每个树索引指定一个组合方法和激活函数(对应图5中间Tree Index 0、1、2);
- 最后两个block的预测:Cell Inject决定 c t − 1 c_{t-1} ct−1的连接方式(是add 还是relu),Cell Indices决定 c t c_t ct的连接方式;

计算过程,如下图所示:
- Tree Index 0: a 0 = t a n h ( W 1 ∗ x t + W 2 ∗ h t − 1 ) a_0 = tanh(W_1 * x_t + W_2 * h_{t-1}) a0=tanh(W1∗xt+W2∗ht−1);
- Tree Index 1: a 1 = R e L U ( ( W 3 ∗ x t ) ⊙ ( W 4 ∗ h t − 1 ) ) a_1 = ReLU((W_3 * x_t)⊙(W_4 * h_{t-1})) a1=ReLU((W3∗xt)⊙(W4∗ht−1));
- controller为Cell Indices的第二个元素的预测值为0,Cell Inject的预测值是add和ReLU,意味着 a 0 a_0 a0值需要更新为 a 0 n e w = R e L U ( a 0 + c t − 1 ) a_0^{new} = ReLU(a_0 + c_{t-1}) a0new=ReLU(a0+ct−1),这里不需要额外的参数;
- controller为Tree Index 2预测的操作包括ElemMul和Sigmoid, a 2 = s i g m o i d ( a 0 n e w ⊙ a 1 ) a_2 = sigmoid(a_0^{new}⊙a_1) a2=sigmoid(a0new⊙a1),因为 a 2 a_2 a2是最大的树的索引,所以 h t = a 2 h_t = a_2 ht=a2;
- controller为Cell Indices的第一个元素预测的值为1,意为 c t c_t ct要使用索引为1的树激活后的值, c t = ( W 3 ∗ x t ) ⊙ ( W 4 ∗ h t − 1 ) c_t = (W_3 * x_t)⊙(W_4 * h_{t-1}) ct=(W3∗xt)⊙(W4∗ht−1);
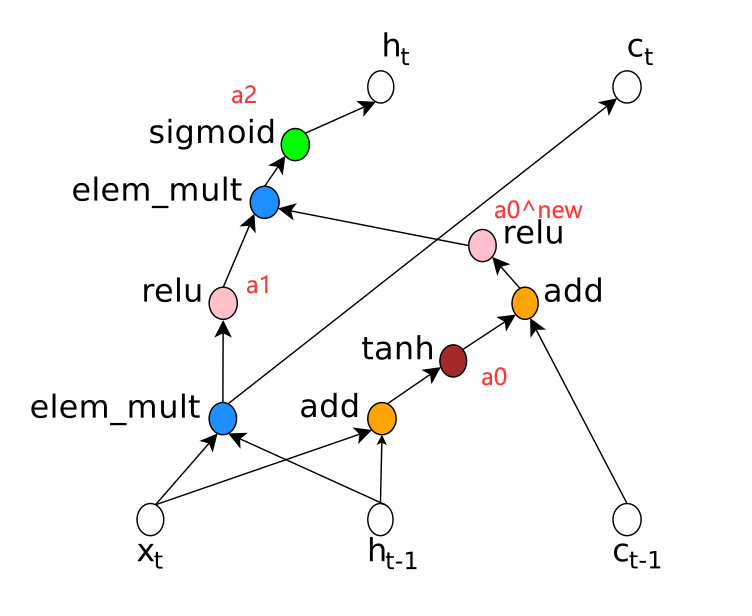
在图5的例子中只有两个叶子节点,称为"base 2"架构,实际试验中,用"base 8";
4 实验
- NAS for CNN:CIFAR-10的图像分类任务;
- NAS for RNN:Penn Treebank的语言建模任务;
4.1 NAS for CNN
数据集:带有预处理和数据增强的CIFAR-10数据集,图像大小,32 * 32;
搜索空间:卷积结构,激活函数,归一化,残差连接;
- filter height/width:[1, 3, 5, 7];
- filter number:[24, 36, 48, 64];
- stride:
- 一组固定为1;
- 另一组在[1, 2, 3]内搜索;
训练细节:使用adam优化器优化,学习率策略为0.0006。权重初始化符合[-0.08, 0.08]的均匀分布。在分布式训练部分,设置参数服务器的 S 为20,拷贝数量K 为100,每个部分子网络m的数量为8;
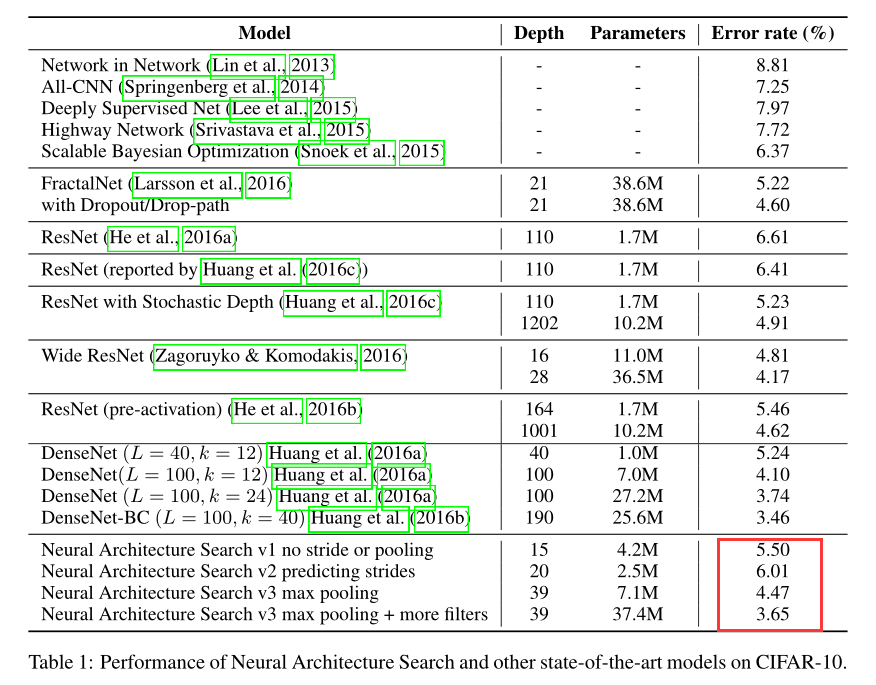
从12,800个架构中,选出最优的结果如下:
4.2 NAS for RNN
数据集:Penn Treebank数据集(著名的语言建模baseline);
搜索空间:如3.4节所述;
- 组合方法:[add, elem_mult];
- 激活方法:[identity, tanh, sigmoid, relu];
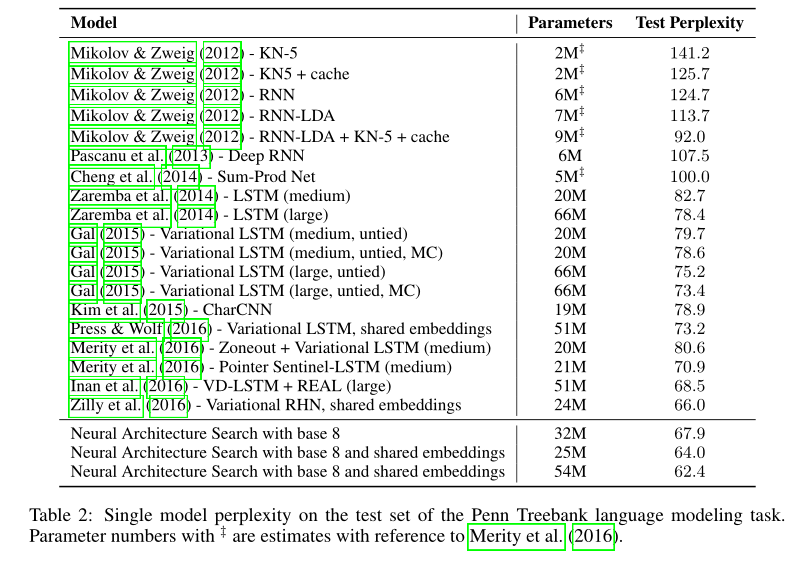
结果见表2:
迁移学习结果见表3: