小白学Pytorch系列-- torch.autograd API
torch.Autograd提供了实现任意标量值函数的自动微分的类和函数。它只需要对现有代码进行最小的更改-你只需要声明张量s,它的梯度应该用requires grad=True关键字计算。到目前为止,我们只支持浮点张量类型(half, float, double和bfloat 16)和复杂张量类型(cfloat, cdouble)的autograd。
基本概念
Variable,Parameter和torch.tensor()
torch.nn.Parameter(是Variable的子类)
如果在网络的训练过程中需要更新,就要定义为Parameter, 类似为W(权重)和b(偏置)也都是Parameter
Variable默认是不需要求梯度的,还需要手动设置参数 requires_grad=True。Variable因为要多次反向传播,那么在backward的时候还要手动注明参数(),就非常麻烦。
Pytorch主要通过引入nn.Parameter类型的变量和optimizer机制来解决了这个问题。Parameter是Variable的子类,本质上和后者一样,只不过parameter默认是求梯度的,同时一个网络中的parameter变量是可以通过 net.parameters() 来很方便地访问到的,只需将网络中所有需要训练更新的参数定义为Parameter类型,再用以optimizer,就能够完成所有参数的更新了,例如:optimizer = torch.optim.SGD(net.parameters(), lr=1e-1)
相同点
:torch.tensor()、torch.autograd.Variable和torch.nn.Parameter基本一样。
前两者都可以设置requires_grad参数,后者则直接默认requires_grad=True。
三者都拥有.data,.grad,.grad_fn等属性。
所以,只要requires_grad=True,都可以计算梯度以及backward()。
不同之处:
torch.nn.Parameter,直接默认requires_grad=True,在参数量大时更加方便。
反向传播
参考: https://blog.csdn.net/lj2048/article/details/113527400
实现autograd依赖于Variable和Function这两种数据类型。Variable是Tensor的外包装,Varibale和Tensor基本一致,区别在于多了下面几个属性。
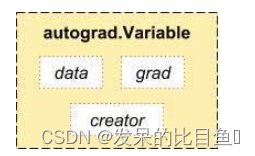
variable类型变量的data属性存储着Tensor数据,grad属性存储关于该变量的导数,creator是代表该变量的创造者。
Variable和Function它们是彼此不分开的,如下图所示,是数据向前传输和向后传输生成导数的过程。
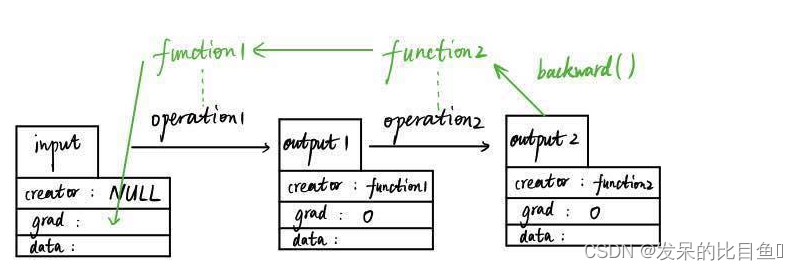
如图,假设我们有一个输入变量input(数据类型为Variable),input是用户输入的,所以其创造者creator为null值,input经过第一个数据操作operation1(比如加减乘除运算)得到output1变量(数据类型仍为Variable),这个过程中会自动生成一个function1的变量(数据类型为Function的一个实例),而output1的创造者就是这个function1。随后,output1再经过一个数据操作生成output2,这个过程也会生成另外一个实例function2,output2的创造者creator为function2。
示例可以参考该Blog: 参考PyTorch教程之Autograd
目标张量一般都是标量,如我们经常使用的损失值Loss,一般都是一个标量。但也有非标量的情况,后面将介绍的Deep Dream的目标值就是一个含多个元素的张量。那如何对非标量进行反向传播呢?
PyTorch有个简单的规定,不让张量(Tensor)对张量求导,只允许标量对张量求导,
因此,如果目标张量对一个非标量调用backward(),则需要传入一个gradient参数,该参数也是张量,而且需要与调用backward()的张量形状相同。
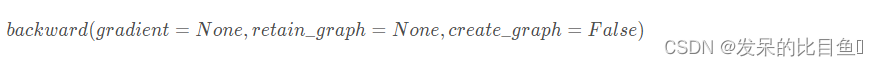
参考
https://zhuanlan.zhihu.com/p/321449610