好代码
什么是好的代码?
- 易于进行增加、删除、更新、修改(CURD)
- 易于移植和复用
- 易于测试
- 可读性好
易于 CURD
软件就是用来修改的。
需求不断变更、快速迭代的应用场景下,好的代码每一次进行 CURD,影响范围小,副作用下。不会因为一个简单的需求变动,而影响了整体。
易于移植和复用
易于移植,重要的是要
- 解耦
- 内聚
在移植代码到其他项目时,不会因为复用一个功能类,要同时拉上十几个的类,而这些把依赖的类我们根本不需要它的业务。
如果项目里依赖没有做好约束,整体成网状结构,要达到好移植可复用就很难了。
易于测试
什么样的代码更易于测试?
易于测试的方法,对外界环境的依赖小,基本靠输入的变量就可以在方法体内完成基本业务。
易于测试的类,对其他类的依赖小,或者基于接口编程,需要测试的时候,只要注入一个模拟的接口就可以,不用关联到真实的类。
可读性好
因为团队合作,经常要阅读和使用其他人的代码,所以团队合作下,可读性的要求还是非常高的。可读性好的具体表现有:
- 简单易用。简单地看下接口说明就能正确使用。如果是详细阅读源码才能正确使用的时候,是可以考虑一下调整设计了。
- 注释友好。在一些关键地方,或者容易引起理解困难的地方,会有友好的注释。
- 无冗余。这样就不会被一些冗余的无效的代码干扰思考。
- 高度复用。不会出现相似的代码在系统中出现多次(因为简单粗暴地复制粘贴)。阅读代码的时候,即使他们真的完全一样,换成其他人维护时,在不了解的情况下,还是得花时间和精力进行对比。如果只有细微的不同,也是容易产生造成忽略。谨记:代码是用来复用的,不是用来拷贝的。
- 有章可循。如果是应用了一些设计模式,可以简单地通过命名或者基本结构,就能感知到。可以加快理解。
熵减
先聊讲一下什么是熵增。
熵是物理学的概念,代表一个系统的混乱程度。一个孤立的系统,会从有序到无序发展。生命体也有这样的现象,从有序到无序,最终走向老化死亡。熵越高的系统就越难精确描述其微观状态。
软件世界的熵增,就是软件系统在没有进行维护、保养、整理的情况下,也会逐渐变得混乱、无序。最后维护不下去了,软件系统走向死亡。
这就要求我们平时的开发,需要主动去抵抗熵增,做到熵减,减速系统老化的过程,为软件系统续命。如果平时开发中,遇到某些软件模块有这样的问题,就可以考虑着手进行重构和优化:
- 是否已经越难越来理解代码,我只想了解一个功能的实现,却要学习整体的设计?
- 是否高度耦合,关联模块过多,修改几行代码,却引发和很多其他模块的异常?
- 是否想简单地删除一个功能,却动到了许多的类,每一处修改就意味着多一份可能产生 bug 的风险。
- 是否想增加一个需求,却要做大量的修改才能把需求加入,而不是通过扩展的方式。违背了软件开发中的开闭原则,即对扩展支持,对修改限制。
这就像在给一辆老旧的车更换零部件,上润滑油,可以让它多跑几年,做得好的话,整个项目可以在高强度的需求变动下,依然保持优雅。
所以,软件开发就是需要一个熵减的过程,帮助这些模块从混乱到有序。比较常见的处理方式有:
统一代码规范
统一的命名方式
命名首先要有意义,最好从命名就可以理解代码的作用。大家习惯不一,但在同一个项目需要统一风格。如果大家风格各异,那么每次在阅读代码的时候,都停顿个 0.5s 去理解对方的习惯,那么一个项目几十万行代码,积少成多,量变导致质变,会浪费掉很多时间。最好能够做到,就是项目看起来就像是一个人写的。
整齐的编码方式
这个从另一个维度对代码规范做出要求,那就是排版问题。希望能够有工整、对称的排版。放在类前面的字段功能内聚,或者按作用域内聚。类中的方法也按功能内聚,而不是散乱在各个类中,结果只有通过 IDE 能找到它们的相似方法。就把它当成自己居住的房间吧,是喜欢衣服乱扔的房间,还是干干净净整整齐齐的房间?
清晰的方法设计
各个方法单一职责,使用者只需要关心输入输出,而不用纠结内部实现。实例方法体减少对成员变量的依赖和外部环境的依赖,这样可以便于对方法单元进行测试。
清理冗余代码
需求变更,不再使用的代码及时清理
经常使用的代码和算法,抽取成业务工具类。
进行解耦和内聚
- 应用设计模式
- 应用分层架构
- 功能内聚
进行性能优化
要关注性能优化,这是因为软件运行的硬件环境资源有限。尤其是手机开发更要重视。而性能其实关注的就是一些硬件在现实中的瓶颈,比如
CPU 频率有限,核数有限。
硬盘的 IO 读写慢。
内存大小有限,不能挥霍。
……
针对这些,就有必要对项目进行优化,比如:
- IO优化
- 加快数据解析速度
- 检查发生在主线程的耗时操作
- 判断是否可以建立缓存减少IO操作,用空间换时间
- 线程优化
- 逮捕野线程。是否有野线程在跑,如果有的话,是执行频次高,执行速度快的野线程,还是频次短,耗时长的线程?如果收到线程池是否会提高效率?
- 对线程的复用,减少频繁创建线程带来的开销,线程池的设计
- 固定线程池
- 缓存线程池
- 单线程池
- 内存优化
- 是否有大对象放到了成员变量中?是否短时间内申请了大量的对象,造成了频繁 GC
- 应用的内存是否有做好及时回收
抽象
业务代码做多了,会发现可找到一定的模式和模型,梳理清楚后,对相应的模块进行调整,去满足开闭原则,让未来用更少的代码量,更小的修改影响范围来完成需求。
这时候我们需要对已有的或者即将开发的需求做抽象。
基本步骤有:
- 进行降维,排除一些业务实现的干扰。
单个单元找出变化的部分和不变的部分。
多个单元找出共同点和同点。
- 对整体的静态结构和动态行为总结出规律。
- 对以上流程得出的结论,建立模型,画个结构图或者流程图。
比如最近对应用分享模块的改造来举例。
分享弹窗中有分享到各个社交平台的,还有对视频或者用户数据一些功能的操作。比如分享到QQ,微信,新浪微博等。对视频的操作有删除操作,复制链接,举报等。我们想把这些功能抽象成一个个单元该怎么做?
首先降维,先排除所有外界干扰因素,还有某些具体的实现。可以看到一个单元需要完成的,其实就是:
- 执行分享任务
- 释放分享资源
于是有了接口 ICell:
public interface ICell {
void execute();
void release();
}因为要持有资源,而每个功能所需要的资源又是不一样的,我们先进行降维,无视掉不同地方的具体实现,创建了资源包接口 IResPacket。因为实现类只是对资源数据的打包,而资源我这边的定义是不可变类型的,所以就没有提供方法实现,提供了最大化的自由度。
public interface IResPacket {
}分析静态结构和动态行为,把资源包组合到单元中,有了抽象类 AbsCell 的诞生:
public abstract class AbsCell<T extends IResPacket> implements ICell {
public final T resPacket;
private final ShareLaunchParams mShareLaunchParams;
public AbsCell(@NonNull ShareLaunchParams params,
@NonNull T resPacket) {
this.mShareLaunchParams = params;
this.resPacket = resPacket;
}
public void execute() {
if (BaseUIOption.isProcessing(1000)) {
return;
}
executeImpl(mShareLaunchParams);
}
protected abstract void executeImpl(@NonNull ShareLaunchParams params);
public abstract void release();
}然后各个子类各自实现各自的业务逻辑,
- 社会化分享的,ShareCell
- 删除视频的,FuncMediaDeleteCell
- 复制链接的,FuncCopyUrlCell
…..
最后根据业务需求,在一个工厂组装这些单元,返回给整个分享页 ShareDialogFragment 使用。
public class CellListGenerator {
public static void generateVerticalCellList() {
...
}熟悉设计模式的话,可以看到我这边应用了设计模式中的桥接模式。而且用了三个维度的桥接。这个刚好匹配这样的业务场景。
经过了抽象然后建立模型后,就可以做到开闭原则了。三个维度就可以独立变化了,使用的时候再去组合。
新的分享功能过来,只需要再拓展一个 ShareCell。如果不需要举报了,直接删除 FuncMediaReportCell。界面改变了,就再实现 IShareView 接口取实现一个新的 View。
整体的类图如下:
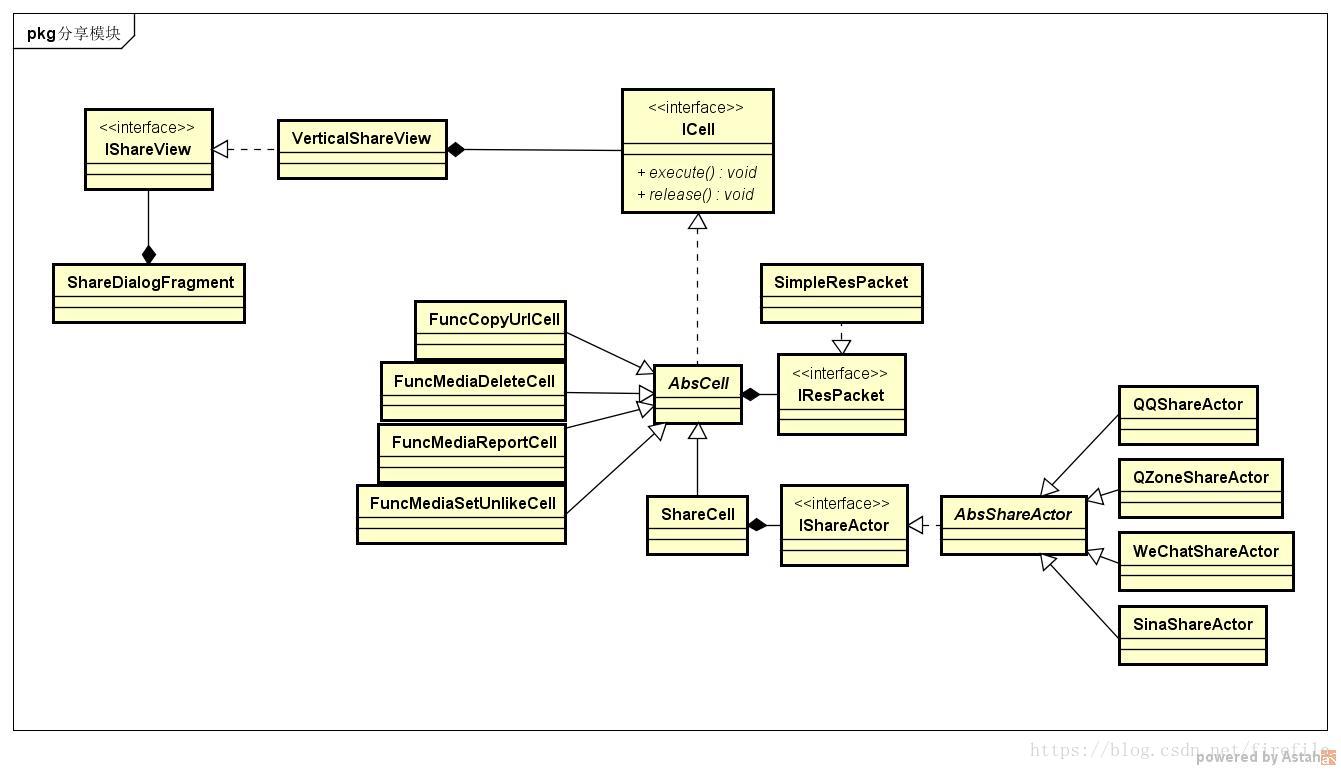
抽象的意义,整个分享模块隐藏了各个具体实现,找到了变与不变,同与不同,动与静,开发者可以对整体的模型一目了然,新的需求过来后可以轻松应对。
分与合
无论是解决问题或者软件开发,都需要有分与合的思想。
分,分而治之,大化小,小化无。把一个大的整体划分成几个相对单独的单元,每个单元相对独立,并且能完成特定功能,而且能够单独测试。
合,合而为一,把分离出来的单元再组成一个个小模块,小模块再组装成大模块。最后形成一个整体。
解决一个复杂的问题时,有时候我们需要把这个问题拆分成一个个小问题,然后各个击破。比如排序算法中比较快的快排、归并排序就应用了分而治之的方法。
分的一个方式是解构。比如我想造一辆车,就得去解构这个车,它应该有发动机,有变速器,有轮子,有方向盘,有悬挂系统等等。然后接着又可以分解,比如变速器可以是自动的、手动的、手自一体的等等,发动机可以是涡轮增压或者是自然吸气。解构完后,我们看到的不是一辆车,而是一个个相对独立的零部件。有了这样的基础,在去逐一去解决问题。
合的一个方式就是组装。上面的车子,我们零部件都准备好了,就可以把它们连接在一起。各个零部件组装起来,搭载在车子的骨架,通过电路系统进行通信,最后协同工作,把车子跑起来。
软件开发就是在模拟现实。我们从现实中的微观和宏观两个级别去寻找答案。
以下对微观和宏观两方面的描述并不严谨,也不完整,其实就是做了降维处理,为了得出基本模型。
微观世界
细胞 -> 组织 -> 器官 -> 人
每个细胞都是很相对单独的结构,他们有共性和差异性,一下就是对细胞基本结构的抽象:
形态各异的细胞,合成组织,组织合成器官,最后造了一个人

宏观宇宙
恒星系 -> 星系 ->星系群 -> 超星系团。
每个恒星系都自己成熟的系统,一个恒星,周围有几个行星。
我们住的太阳系是这样的
超星系团是这样的

软件世界
单元 -> 小组件 -> 大组件 -> 小模块 -> 大模块 -> 应用
软件用来模拟现实,要实现一个复杂的系统,也是需要拆分成各个不同的小单元,在组合成大模块。
比如拿我们工作的平台,Android 操作系统为例:
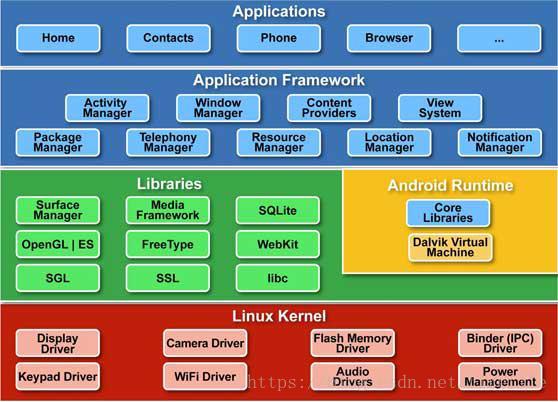
我们平时工作在应用层,但每次调用系统 API 实现一个功能的时候,是由多个层级地多个模块的多个单元配合完成,而这些单元都是相对独立的。
所以,无论是微观世界、宏观宇宙还是软件系统,都是有一个个单元不断地组合而成的。
我们平时的设计和编程,同样要注意做好分和合,控制好粒度:
水平划分,把系统割成一个个子模块,相互独立。
垂直划分,对模块进行分层,各层独立。
拥抱变化
不过度设计,简单最美。我们设计的时候,经常会忧虑,万一以后增加什么需求该怎么办,那我就先加了某种设计。如果这个增加并不会带来太大影响,没有问题。如果这个增加,大大提高了整个设计的复杂度,甚至可读性和可维护性都大幅度下降,则要再三思而行。
不存在完美的设计,因为世界是动态的,业务在变,软件技术在革新,开发者的能力和视野也提高。所以,我们需要对现实做一些妥协,避免出现为了追求极致完美,而大大提供项目交付风险。甚至在代码已经稳定时,因为对设计不满意推翻重建更要慎重。
微小重构,在风险可控的情况下,及时调整。因为系统处于熵增的状态,看到代码维护性开始下降,我们又拼命堆需求,而不打算做点小重构来优化的话,系统寿命会大大下降。做重构不仅仅是前人栽树,后人乘凉的事情,只要还在这个项目,自己总会有可能再次维护到这块代码,这也是给自己栽树。
业务决定了架构。比如最新流行的模块化,如果不是因为业务量和业务复杂度达到了一定程度,分模块独立开发其实并不需要。
灵活运用,摆脱教条主义
Effective Java 里的有一句话,“同大多数学科一样,学习编程艺术首先要学会基本的规则,然后才能知道什么时候去打破规则”。
在学习或者接受了某些新的软件开发思想、设计模式或者架构,非常想要推翻所有代码进行重建。但现实情况是很复杂的,教科书上的模型不一定匹配。
比如如果拿 MVC 模型来说,在一些没有数据输入或者读取的应用场景中,是不需要 Model 的。这时候强行设计一个 Model 就有些画蛇添足了。
这样的例子还有很多。所以通用并不一定适用,要根据业务情况做适当更改,同时还要评估风险和收益。收集各方面信息然后做出决策。
在现实应用的开发,如果应用设计模式解决问题,经常也是多种设计模式来协同合作,才能完成某项具体的业务的。而且应用这些模式的时候,往往也会根据对现实做一些调整,没有和教科书描述的完全一致。
比如应用职责链模式解决一个请求需要在不同的业务节点上传递的问题。严格责任链要求每个节点只干两件事情,一个是承担请求的责任并做相应处理,一个是不处理传给下一个节点。所以请求一定要被处理掉。但很多场景下,其实我们的节点每个节点可以处理请求,并且可以决定请求往下传递或者就此结束,所以每个节点都有可能处理请求,而且请求有可能不被处理。所以设计模式要怎么用,要按照业务的设计来。
但万变不离其宗,在我们的面向对象编程(OOP)中,我们用了这么多的编程技巧、编程方法,
,其实就是为了要努力做到几个基本原则:
- 开闭原则,对扩展良好支持,对修改严格限制。
- 里式替换,子类能够代替基类。
- 依赖倒转,设计依赖于抽象而不是具体。
- 接口隔离,对接口进行归类聚合,各种不同类型方法堆到接口会使接口变得臃肿庞大。
- 单一职责,一个类职责要少并且要专。不是说每个类只能有一个职责,而是说职责要尽可能地少。避免各种复杂的业务都汇集到一个类中,网状结构的依赖导致随便改个需求就牵一发而动全身。
- 迪米特法则,一个对象尽可能地少了解其他对象。也是最少知识法则。这就要求我们对类的封装性要做好,作用域要管好,同时提供给外部的接口要简单好用。
这就有些目标导向型的特点在里面。为了实现这些目标,可以八仙过海,各显神通,前人确实总结了不少的编程技巧、编程范式、设计模式给我们使用
比如初代软件从业者总结了几十年的软件开发经验,又参考了建筑学的一些原理,有了 24 种设计模式。
比如代码分层架构的演变,从最开始一个类完成所有工作到 MVC、MVP、MVVM 等。
比如现在在前端很流行的函数响应式编程方式,可以很有效地解决实际开发中多层嵌套回调的问题。
我们平时开发,就可以根据业务情况,自己去思考还是多思考和实现新的方案,而不是简单地搬运。去实现这些原则是我们要的结果。