利用tensorflow的Keras模块我们可以建立我们自己定义的卷积神经网络模型,但是一般不会触碰到学习率这个问题,一般默认的学习率都是0.001
激活层
dropout 是神经网络用来防止过拟合的一种方法,很简单,但是很实用。
基本思想是以一定概率放弃被激活的神经元,使得模型更健壮,相当于放弃一些特征,这使得模型不过分依赖于某些特征,即使这些特征是真实的,当然也可能是假的。
# 我们的模型使用categorical_crossentropy作为损失函数,因此需要根据类别数量nb_classes将 # 类别标签进行one-hot编码使其向量化,在这里我们的类别只有两种,经过转化后标签数据变为二维
简单的交叉熵损失函数,你真的懂了吗?
从上面两种图,可以帮助我们对交叉熵损失函数有更直观的理解。无论真实样本标签 y 是 0 还是 1,L 都表征了预测输出与 y 的差距。
另外,重点提一点的是,从图形中我们可以发现:预测输出与 y 差得越多,L 的值越大,也就是说对当前模型的 “ 惩罚 ” 越大,而且是非线性增大,是一种类似指数增长的级别。这是由 log 函数本身的特性所决定的。这样的好处是模型会倾向于让预测输出更接近真实样本标签 y。
因为我的项目是二分类问题,由于交叉熵损失函数的log特性,损失函数越大,惩罚越严重
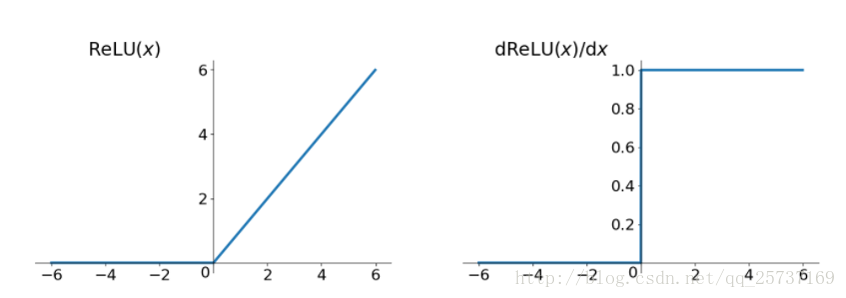
relu函数的k值为1,所以不会出现梯度爆炸或者梯度消失
反向传播——通俗易懂
关于ssm

分类层(回归函数)
用的是softmax,
卷积神经网络的分类层-softmax和sigmoid
关于sgd和momentum 优化器
介绍概念:为什么说随机最速下降法(SGD)是一个很好的方法?
仔细看的话,其实SGD需要更多步才能够收敛的,毕竟它喝醉了.可是,由于它对导数的要求非常低,可以包含大量的噪声,只要期望正确就行(有时候期望不对都是可以的..),所以导数算起来非常快.就我刚才说的机器学习的例子,比如神经网络吧,训练的时候都是每次只从百万数据点里面拿128或者256个数据点,算一个不那么准的导数,然后用SGD走一步的.想想看,这样每次算的时间就快了10000倍,就算是多走几倍的路,算算也是挺值的了.