上一篇我们已经配置好了文件,接下来就是制作训练标签。我这次想做的是检测六个不同物体,是去年也就是2019年浙江的工程训练比赛的题目,因为我之前有拍过一大堆的数据。
检测物体分别为圆柱、N形方块、三角柱体、正方体、五角星柱体、六边形柱体。为了偷懒我把他们标注为123456,差不多对应他们的名字。之所以想到用深度学习的方法去检测,是因为传统的图像霍夫检测与机器学习无法完美适应环境,他们是有可能成功,但其中的不确定性太大了,准确率也低 。你无法避免环境因素、噪音干扰。
我之前也用过百度的easy dl做过,他们的算法很强大,做出来既快捷方便准确率又高。唯一的问题是他们好像只是针对企业,对学生群体不是很友好,而且我提交发布模型申请后,也根本没有人在几个工作日内鸟我。本着掌握关键技术的思想,我才决定自己学习定制模型的方法,这样以后要用上的时候就不会求人了。
1.准备工作
1.1在桌面上创建一个文件夹,例如命名’xx_object’,并在’xx_object’下创建四个文件夹分别命名为’train’,‘test’,‘training’,‘data’
1.2 将图片放入train文件夹中,实际上我们需要将图片分成train和test甚至val,但先为了方便操作,我们都放入train里。
一般建议100张吧,80%train,20%test。这里给大家一些代码用来批量处理图片:
import os.path
import glob
import cv2
import numpy as np
#全局统一大小处理
def convertjpg(jpgfile,outdir,width=600,height=800):
src = cv2.imread(jpgfile, cv2.IMREAD_ANYCOLOR)
try:
dst = cv2.resize(src, (width,height), interpolation=cv2.INTER_CUBIC)
cv2.imwrite(os.path.join(outdir,os.path.basename(jpgfile)), dst)
except Exception as e:
print(e)
for jpgfile in glob.glob(r'C:\Users\kangaroo\Desktop\111\*.jpg'):# 修改为自己的路径
convertjpg(jpgfile,r'C:\Users\kangaroo\Desktop\train')# 修改为自己的路径
#批量修改图片名字
import os
def rename():
#原始图片路径
path = r'C:\Users\kangaroo\测试代码\视觉处理\11.21'# 修改为自己的路径
#获取该路径下所有图片
filelist = os.listdir(path)
a = 42
for files in filelist:
#原始路径
Olddir = os.path.join(path,files)
#if os.path.isdir(Olddir):
# continue
#将图片名切片,比如 xxx.bmp 切成xxx和.bmp
filename = os.path.splitext(files)[0]
#.bmp
filetype = os.path.splitext(files)[1]
#需要存储的路径 a 是需要定义修改的文件名
Newdir=os.path.join(path,str(a)+filetype)
os.rename(Olddir,Newdir)
a += 1
rename()
#统一灰度图与大小 处理
for j in range(1,20):
img_gray = cv2.imread('11.20/%d.jpg'%j,cv2.IMREAD_GRAYSCALE) # 修改为自己的路径
cropImg = cv2.resize(img_gray,(300,300))
cv2.imwrite('chuli/%d.jpg'%j,cropImg)
准备结束,开始标注。
以上步骤只是为了方便我讲解步骤,也方便大家理解,大家理解后不一定要按我的方式来创建文件,我就按我所创建的文件名来说明
2.labelImg
2.1下载labelImg
我给出百度云:
链接:https://pan.baidu.com/s/1Uyt9_pVxhZDoQikXj2wMng
提取码:vk66
2.2标注信息
解压后打开,在文件夹下直接双击labelImg.exe。

出现此界面后,点击open dir,选择你要标注图片列表,也就是train文件夹
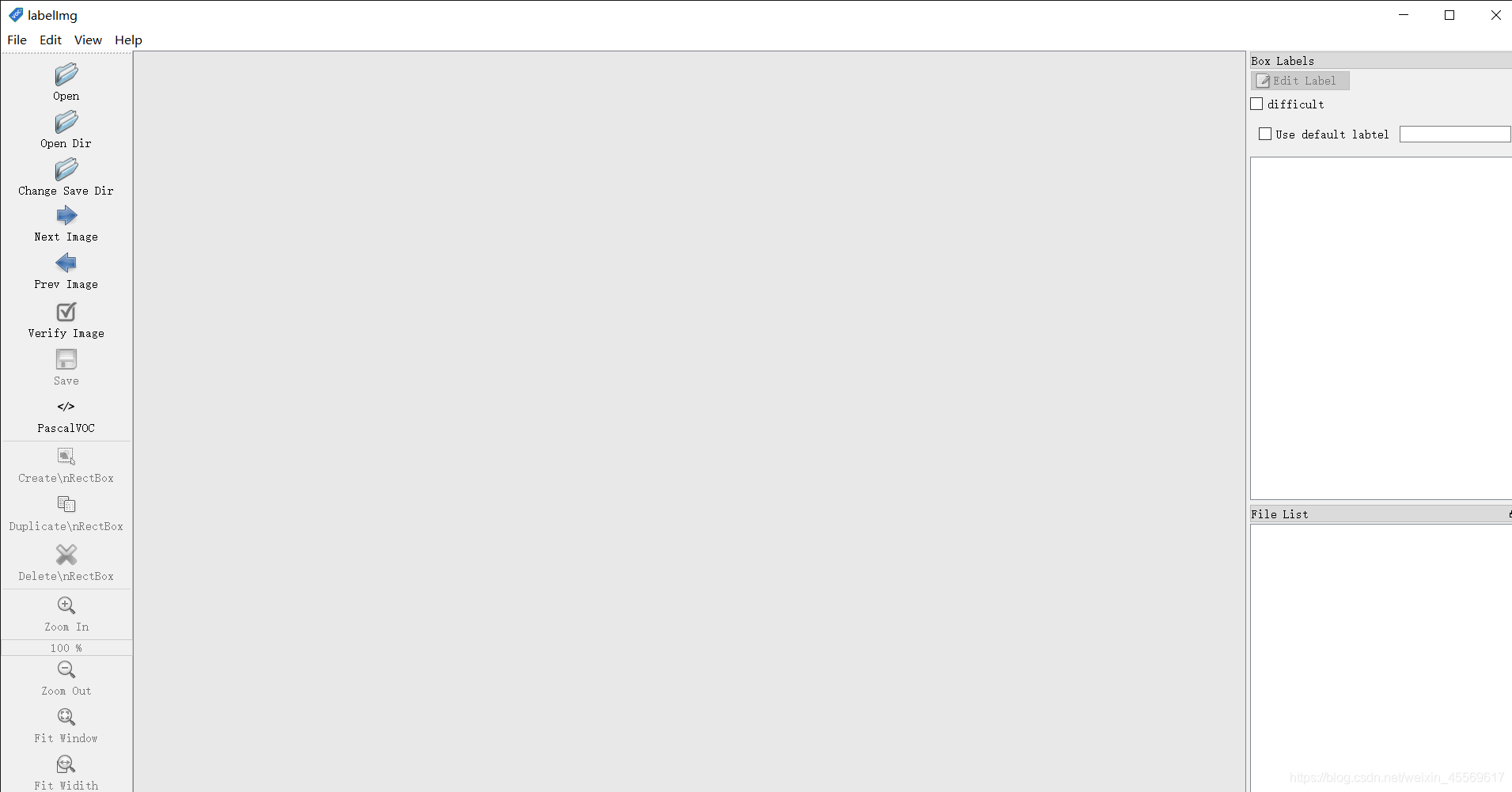
快捷键:
- w: 画框
- d:下一张
- a:上一张
- ctrl+s:保存
2.3分类照片
慢慢地把所有的图片标注好,会生成对应的xml文件,然后选取20%地图片放入test文件夹里
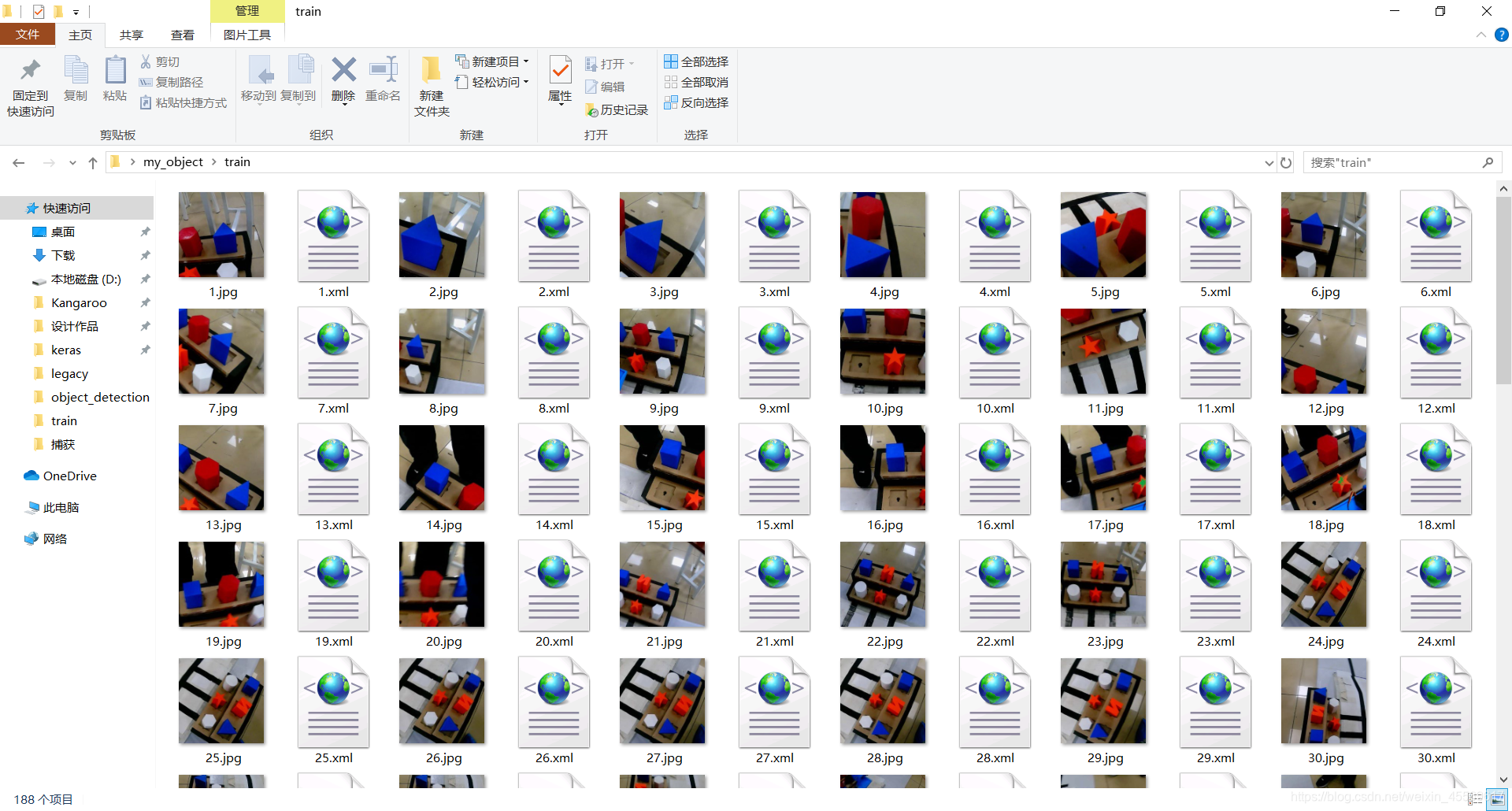
3.xml to csv
现在我们把整个’my_object’文件夹放到models/research/object_detection/ 这个目录下并运行下面的代码,将train和test下的xml文件分别合成csv文件,注意自己的路径 。
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def main():
image_path = path
xml_df = xml_to_csv(image_path)
xml_df.to_csv(target, index=None)
print('Successfully converted xml to csv.')
#生成test的csv文件,根据自己情况修改路径
path = 'models/research/object_detection/my_object/test'
target = 'test.csv'
os.chdir(path)
main()
#生成train的csv文件,根据自己情况修改路径
path = 'models/research/object_detection/my_object/train'
target = 'train.csv'
os.chdir(path)
main()
这时,在train和test的文件夹下分别出现train.csv 和test.csv。
4.csv to record
由于tensorflow无法识别csv文件,我们需要将csv转成record格式。
import os
import io
import pandas as pd
import tensorflow as tf
from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
os.chdir('C:\\Users\\Kangaroo\\models\\research\\object_detection') # 修改为object文件夹相对于此代码文件的路径
flags = tf.compat.v1.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS
# 改为自己的分类个数
def class_text_to_int(row_label):
if row_label == '1':
return 1
elif row_label == '2':
return 2
elif row_label == '3':
return 3
elif row_label == '4':
return 4
elif row_label == '5':
return 5
elif row_label == '6':
return 6
else:
return 0
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.io.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(str(row['class']).encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.io.TFRecordWriter(FLAGS.output_path)
# path = os.path.join(os.getcwd(), 'my_object/train')# 转换train写这句,代表train的图片集
path = os.path.join(os.getcwd(), 'my_object/test') # 转换test写这句,代表test的图片集
examples = pd.read_csv(FLAGS.csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
tf.compat.v1.app.run()
注意:
- 修改为object文件夹相对于此代码文件的路径 ,就是让此代码运行时能找到xx_object文件夹,建议用绝对路径直接锁定object文件夹的位置
- 修改成自己的分类,我的是6类
- 修改对应的转换代码,具体我代码里有注明
- 转换test时,路径给到object文件夹下test的图片集所在的位置
- 转换train时,路径给到object文件夹下train的图片集所在的位置
- 将此代码文件放在与xx_object文件夹同级别的目录下
这里,我把这个代码重命名为’ctt.py’,启动命令行,来到ctt所在的文件夹下输入
#转换test文件夹下使用
python ctt.py --csv_input=my_object/test/test.csv --output_path=my_object/test/test.record
#转换train文件夹下使用
python ctt.py --csv_input=my_object/train/train.csv --output_path=my_object/train/train.record
这时,在train和test的文件夹下分别出现train.record 和test.record。
小结
labelImg的操作是定制模型里最重复无聊但量大的工作。但这一步也直接关系到你生成模型的好坏,我们在选取训练照片时,尽量覆盖面广,比如亮光暗光下。你想想你如果遇上从没遇到过的题目是不是就无从下手了?计算机也是一样,况且计算机还不会像人一样思考,你没给他训练过这种情况,他在此情况下的识别率就会大大降低。
接下来就是配置训练文件,开始训练了。
2020年tensorflow定制训练模型笔记(1)——object detection的安装
2020年tensorflow定制训练模型笔记(2)——制作标签
2020年tensorflow定制训练模型笔记(3)——开始训练