目录
1、数据预处理
1.1、计算用户点击rank和点击次数
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rc('font', family='SimHei', size=13)
import os,gc,re,warnings,sys
warnings.filterwarnings("ignore")
path = '新建文件夹/推荐系统/零基础入门推荐系统 - 新闻推荐/'
# trn_click = pd.read_csv(path + 'train_click_log.csv')
trn_click = pd.read_csv(path+'train_click_log.csv',encoding= 'utf-8-sig',sep = r'\s*,\s*',header = 0)
trn_click.head()
item_df = trn_click = pd.read_csv(path + 'articles.csv',encoding= 'utf-8-sig',sep = r'\s*,\s*',header = 0)
item_df = item_df.rename(columns={'article_id': 'click_article_id'}) #重命名,方便后续match
item_df.head()
item_emb_df = pd.read_csv(path+'articles_emb.csv',encoding= 'utf-8-sig',sep = r'\s*,\s*',header = 0)
item_emb_df.head()
print(trn_click.columns.tolist())
# 对每个用户的点击时间戳进行排序
trn_click['rank'] = trn_click.groupby(['user_id'])['click_timestamp'].rank(ascending=False).astype(int)
tst_click['rank'] = tst_click.groupby(['user_id'])['click_timestamp'].rank(ascending=False).astype(int)
#计算用户点击文章的次数,并添加新的一列count
trn_click['click_cnts'] = trn_click.groupby(['user_id'])['click_timestamp'].transform('count')
tst_click['click_cnts'] = tst_click.groupby(['user_id'])['click_timestamp'].transform('count')2、数据查看
2.1、训练集用户点击日志
将trn_click 和item_df合并为用户点击日志-训练集
#用户点击日志-训练集
trn_click = trn_click.merge(item_df, how='left', on=['click_article_id'])
trn_click.head()
trn_click.describe().T
trn_click.info()<class 'pandas.core.frame.DataFrame'> Int64Index: 1112623 entries, 0 to 1112622 Data columns (total 14 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 user_id 1112623 non-null int64 1 click_article_id 1112623 non-null int64 2 click_timestamp 1112623 non-null int64 3 click_environment 1112623 non-null int64 4 click_deviceGroup 1112623 non-null int64 5 click_os 1112623 non-null int64 6 click_country 1112623 non-null int64 7 click_region 1112623 non-null int64 8 click_referrer_type 1112623 non-null int64 9 rank 1112623 non-null int32 10 click_cnts 1112623 non-null int64 11 category_id 1112623 non-null int64 12 created_at_ts 1112623 non-null int64 13 words_count 1112623 non-null int64 dtypes: int32(1), int64(13) memory usage: 123.1 MB
- 共有20000个用户
trn_click.user_id.nunique()#200000- 训练集里面每个用户至少点击了两篇文章
trn_click.groupby('user_id')['click_article_id'].count().min() # 训练集里面每个用户至少点击了两篇文章- 点击环境click_environment变化很稳定,仅有2102次(占0.19%)点击环境为1;仅有25894次(占2.3%)点击环境为2;剩余(占97.6%)点击环境为4。
trn_click['click_environment'].value_counts()4 1084627 2 25894 1 2102 Name: click_environment, dtype: int64
- 击设备组click_deviceGroup,设备1占大部分(61%),设备3占36%。
trn_click['click_deviceGroup'].value_counts()1 678187 3 395558 4 38731 5 141 2 6 Name: click_deviceGroup, dtype: int64
2.2、测试集用户点击日志
#测试集用户点击日志
tst_click = tst_click.merge(item_df, how='left', on=['click_article_id'])
tst_click.head()
tst_click.describe()
tst_click.user_id.nunique()#50000
tst_click.groupby('user_id')['click_article_id'].count().min() # 注意测试集里面有只点击过一次文章的用户训练集的用户ID由0 ~ 199999,而测试集A的用户ID由200000 ~ 249999。
在训练时,需要把测试集的数据也包括在内,称为全量数据。
2.3、新闻文章信息数据表
item_df.head().append(item_df.tail())
item_df.shape # 364047篇文章- 新闻字数统计
#新闻字数统计
item_df['words_count'].value_counts()- 新闻类别
#新闻类别
item_df['category_id'].nunique()#461
item_df['category_id'].hist()2.4、新闻文章embedding向量表示
item_emb_df.head()
item_emb_df.shape3、数据分析
合并训练集和测试集的用户日志
user_click_merge = trn_click.append(tst_click)
3.1、用户重复点击新闻的次数
#reset_index()重置索引。
user_click_count = user_click_merge.groupby(['user_id', 'click_article_id'])['click_timestamp'].agg({'count'}).reset_index()
user_click_count[:10]
| user_id | click_article_id | count | |
|---|---|---|---|
| 0 | 0 | 30760 | 1 |
| 1 | 0 | 157507 | 1 |
| 2 | 1 | 63746 | 1 |
| 3 | 1 | 289197 | 1 |
| 4 | 2 | 36162 | 1 |
| 5 | 2 | 168401 | 1 |
| 6 | 3 | 36162 | 1 |
| 7 | 3 | 50644 | 1 |
| 8 | 4 | 39894 | 1 |
| 9 | 4 | 42567 | 1 |
user_click_count[user_click_count['count']>7]
user_click_count['count'].unique()
#array([ 1, 2, 4, 3, 6, 5, 10, 7, 13], dtype=int64)| user_id | click_article_id | count | |
|---|---|---|---|
| 311242 | 86295 | 74254 | 10 |
| 311243 | 86295 | 76268 | 10 |
| 393761 | 103237 | 205948 | 10 |
| 393763 | 103237 | 235689 | 10 |
| 576902 | 134850 | 69463 | 13 |
#用户重复点击新闻次数
user_click_count.loc[:,'count'].value_counts() #取count列所有行,统计不同的count出现的次数
#可以看出:有1605541(约占99.2%)的用户未重复阅读过文章,仅有极少数用户重复点击过某篇文章。 这个也可以单独制作成特征1 1605541 2 11621 3 422 4 77 5 26 6 12 10 4 7 3 13 1 Name: count, dtype: int64
3.2、新闻不同点击数量的用户分布
3.2.1、活跃用户
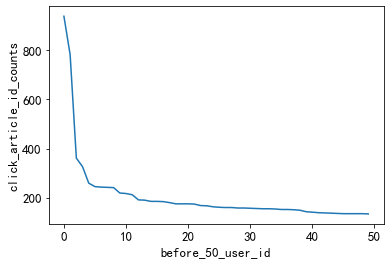
点击次数排前50的用户的点击次数都在100次以上。可以定义点击次数大于等于100次的用户为活跃用户,
这是一种简单的处理思路, 判断用户活跃度,更加全面的是再结合上点击时间,
后面我们会基于点击次数和点击时间两个方面来判断用户活跃度。
#用户点击次数分析
user_click_item_count = sorted(user_click_merge.groupby('user_id')['click_article_id'].count(), reverse=True)
plt.plot(user_click_item_count)
plt.xlabel('user_id')
plt.ylabel('click_article_id_counts')
#点击次数在前50的用户
plt.plot(user_click_item_count[:50])
plt.xlabel('before_50_user_id')
plt.ylabel('click_article_id_counts')
3.2.2、非活跃用户
点击次数小于等于两次的用户非常的多,这些用户可以认为是非活跃用户
#点击次数排名在[25000:50000]之间
plt.plot(user_click_item_count[25000:50000]) 
3.3、新闻被点击次数
3.3.1、热门新闻
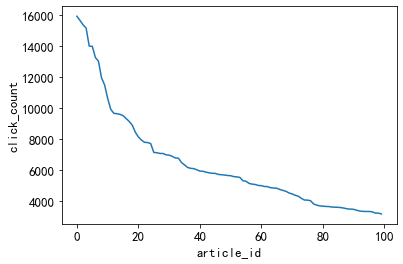
'''点击次数最多的前20篇新闻,点击次数大于2500。
思路:可以定义这些新闻为热门新闻, 这个也是简单的处理方式,
后面我们也是根据点击次数和时间进行文章热度的一个划分。'''
item_click_count = sorted(user_click_merge.groupby('click_article_id')['user_id'].count(), reverse=True)
plt.plot(item_click_count)
plt.xlabel('article_id')
plt.ylabel('click_count')
plt.plot(item_click_count[:100])
plt.xlabel('article_id')
plt.ylabel('click_count')
#点击率排名前100的新闻点击量都超过1000次
plt.plot(item_click_count[:20])
plt.xlabel('article_id')
plt.ylabel('click_count')
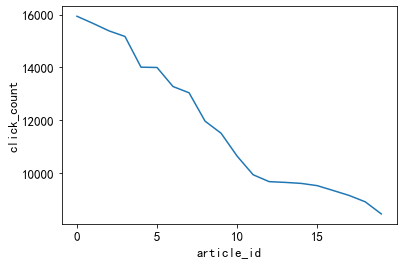
3.3.2、 冷门新闻
很多新闻只被点击过一两次。思路:可以定义这些新闻是冷门新闻
plt.plot(item_click_count[3500:])3.4、 新闻共现频次:两篇新闻连续出现的次数
tmp = user_click_merge.sort_values('click_timestamp')
tmp['next_item'] = tmp.groupby(['user_id'])['click_article_id'].transform(lambda x:x.shift(-1))
union_item = tmp.groupby(['click_article_id','next_item'])['click_timestamp'].agg({'count'}).reset_index().sort_values('count', ascending=False)
union_item[['count']].describe()
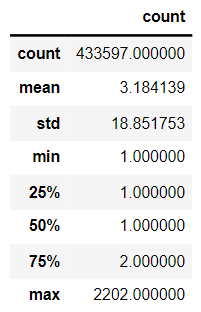
平均共现次数3.18,最高为2202,两篇新闻连续出现的概率算高,说明用户看的新闻上下相关性较强。
x = union_item['click_article_id']
y = union_item['count']
plt.scatter(x, y)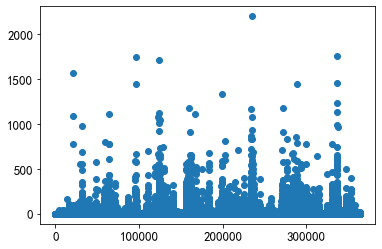
大概有75000个pair至少共现一次
plt.plot(union_item['count'].values[40000:])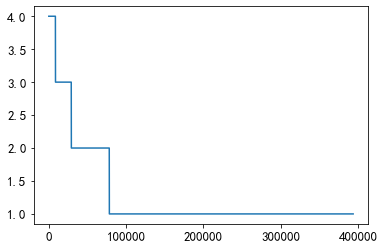
3.5、新闻文章信息
3.5.1、不同类型的新闻出现的次数
小于50个不同类型的新闻出现次数较高
#不同类型的新闻出现的次数
plt.plot(user_click_merge['category_id'].value_counts().values)
plt.xlabel('article_id')
plt.ylabel('appear_counts')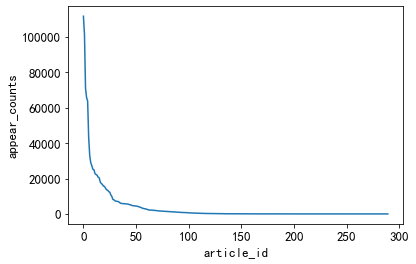
出现次数较少的新闻
#出现次数比较少的新闻类型, 有些新闻类型,基本上就出现过几次
plt.plot(user_click_merge['category_id'].value_counts().values[150:])
plt.xlabel('article_id')
plt.ylabel('appear_counts')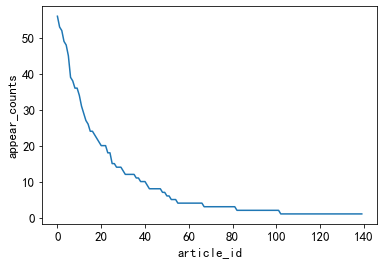
3.5.2、新闻字数
#新闻字数的描述性统计
user_click_merge['words_count'].describe()
plt.plot(user_click_merge['words_count'].values)
3.5.3、用户点击的新闻类型的偏好
此特征可以用于度量用户的兴趣是否广泛。
#用户偏好的新闻广泛程度
plt.plot(sorted(user_click_merge.groupby('user_id')['category_id'].nunique(), reverse=True))
plt.xlabel('user_id')
plt.ylabel('category_id')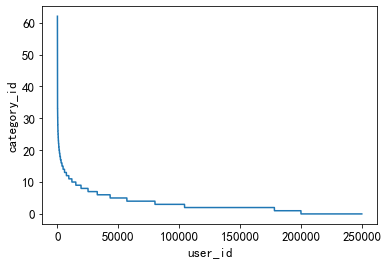
由图知,偏好类型广泛的用户较少,大多数用户的偏好类型较少,在20个类型以下。
3.5.4、用户查看文章的长度的分布
通过统计不同用户点击新闻的平均字数,这个可以反映用户是对长文更感兴趣还是对短文更感兴趣。
plt.plot(sorted(user_click_merge.groupby('user_id')['words_count'].mean(),reverse = True))
plt.xlabel('user_id')
plt.ylabel('avg_words_count')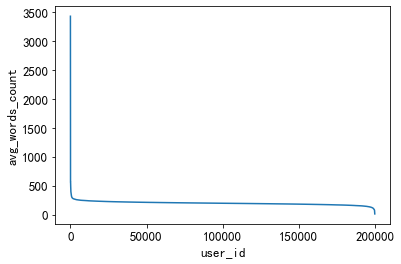
一小部分人看的文章平均词数非常高,也有一小部分人看的平均文章次数非常低。
大多数人偏好于阅读字数在200-400字之间的新闻。
plt.plot(sorted(user_click_merge.groupby('user_id')['words_count'].mean(),reverse = True)[1000:45000])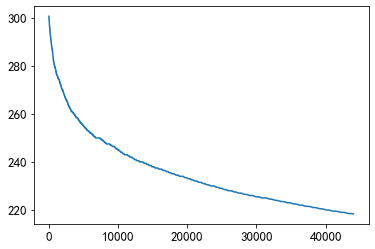
在大多数人的区间中,人们更偏好读220~250字数的新闻。
3.6、用户点击新闻的时间分析
#为了更好的可视化,这里把时间进行归一化操作
from sklearn.preprocessing import MinMaxScaler
mm = MinMaxScaler()
user_click_merge['click_timestamp'] = mm.fit_transform(user_click_merge[['click_timestamp']])
user_click_merge['created_at_ts'] = mm.fit_transform(user_click_merge[['created_at_ts']])
user_click_merge = user_click_merge.sort_values('click_timestamp')3.6.1、点击时间差的平均值
def mean_diff_time_func(df, col):
df = pd.DataFrame(df, columns={col})
df['time_shift1'] = df[col].shift(1).fillna(0)#shift(1)是把数据向下移动1位
df['diff_time'] = abs(df[col] - df['time_shift1'])
return df['diff_time'].mean()
# 点击时间差的平均值
mean_diff_click_time = user_click_merge.groupby('user_id')['click_timestamp',
'created_at_ts'].apply(lambda x: mean_diff_time_func(x, 'click_timestamp'))
plt.plot(sorted(mean_diff_click_time.values, reverse=True))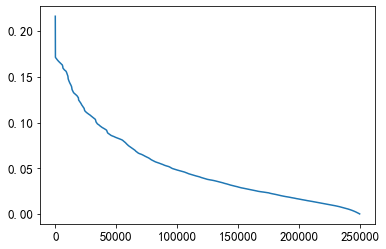
3.6.2、 前后点击的文章的创建时间差的平均值
# 前后点击的文章的创建时间差的平均值
mean_diff_created_time = user_click_merge.groupby('user_id')['click_timestamp',
'created_at_ts'].apply(lambda x: mean_diff_time_func(x, 'created_at_ts'))
plt.plot(sorted(mean_diff_created_time.values, reverse=True))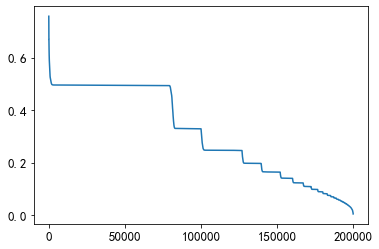
从上图可以发现不同用户点击文章的时间差是有差异的,用户先后点击文章,文章的创建时间也是有差异的
4、得到用户前,后查看文章的相似度列表
4.1、训练新闻的词向量
from gensim.models import Word2Vec
import logging, pickle
# 需要注意这里模型只迭代了一次
def trian_item_word2vec(click_df, embed_size=16, save_name='item_w2v_emb.pkl', split_char=' '):
#按click_timestamp排序
click_df = click_df.sort_values('click_timestamp')
# 将click_article_id转换成字符串才可以进行训练
click_df['click_article_id'] = click_df['click_article_id'].astype(str)
# 将click_article_id转换成句子的形式
docs = click_df.groupby(['user_id'])['click_article_id'].apply(lambda x: list(x)).reset_index()
docs = docs['click_article_id'].values.tolist()
# 为了方便查看训练的进度,这里设定一个log信息
logging.basicConfig(format='%(asctime)s:%(levelname)s:%(message)s', level=logging.INFO)
# 这里的参数对训练得到的向量影响也很大,默认负采样为5
w2v = Word2Vec(docs, vector_size=16, sg=1, window=5, seed=2020, workers=24, min_count=1, epochs=10)
# 保存成字典的形式
item_w2v_emb_dict = {k: w2v.wv[k] for k in click_df['click_article_id']}
return item_w2v_emb_dictitem_w2v_emb_dict = trian_item_word2vec(user_click_merge)4.2、查看用户前后查看文章的相似性
# 随机选择5个用户,查看这些用户前后查看文章的相似性
sub_user_ids = np.random.choice(user_click_merge.user_id.unique(), size=15, replace=False)
sub_user_info = user_click_merge[user_click_merge['user_id'].isin(sub_user_ids)]# .isin()筛选行
sub_user_info.head()4.3、得到用户前,后查看文章的相似度列表
# 得到用户前,后查看文章的相似度列表
def get_item_sim_list(df):
sim_list = []
item_list = df['click_article_id'].values
for i in range(0, len(item_list)-1):
emb1 = item_w2v_emb_dict[str(item_list[i])] # 需要注意的是word2vec训练时候使用的是str类型的数据
emb2 = item_w2v_emb_dict[str(item_list[i+1])]
sim_list.append(np.dot(emb1,emb2)/(np.linalg.norm(emb1)*(np.linalg.norm(emb2))))
sim_list.append(0)
return sim_list4.4、可视化用户前,后查看文章的相似度列表
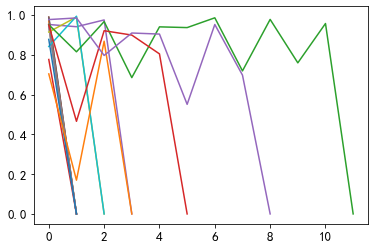
for _, user_df in sub_user_info.groupby('user_id'):
item_sim_list = get_item_sim_list(user_df)
plt.plot(item_sim_list)