上一篇介绍了RepVGG,RepVGG存在量化问题,Repopt通过将先验融入优化器中,统一训练与测试模型解决了其量化不友好的问题。
论文链接: Re-parameterizing Your Optimizers rather than Architectures
Introduction
Repopt提出将模型结构的先验信息直接用于修改梯度数值,其称为梯度重参数化,对应的优化器称为RepOptimizer。Repopt着重关注VGG式的直筒模型,训练得到RepOptVGG模型与VGG结构一致,有着高训练效率,简单直接的结构和极快的推理速度。
与RepVGG的不同:
1)RepVGG在训练过程中加入了结构先验(shortcut,1x1 branch),在推理时,将多支路融合成单路3x3卷积。而RepOptVGG将结构先验转移至梯度中,通过设计的RepOpt优化器实现。
2)在结构上,RepOptVGG是真-直筒结构,模型在训练与测试时保持一致。RepVGG训练时存在多支路需要更多的显存与训练时间。
3)RepOptVGG通过定制优化器,实现了结构重参与梯度重参的等效变化。
Idea
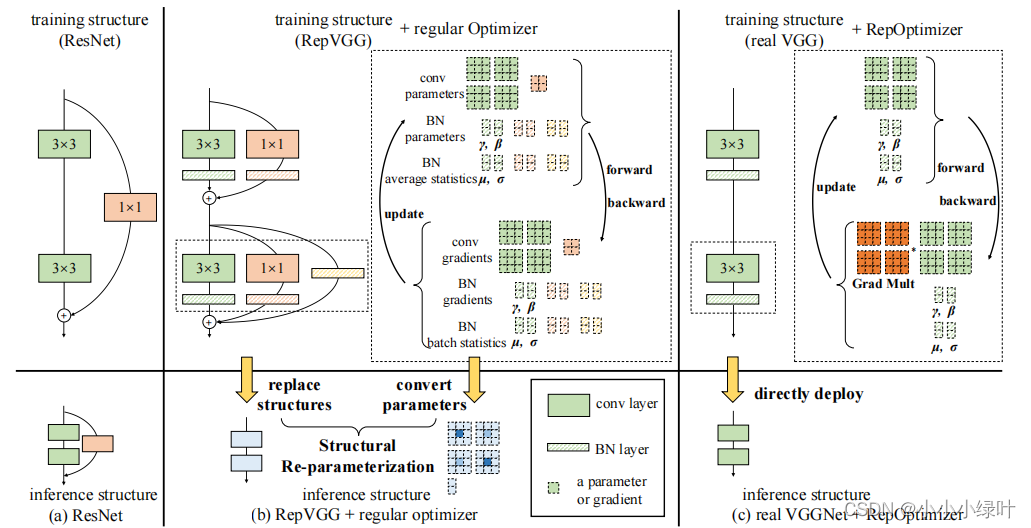
Repopt发现结构先验的一个有趣现象:当每个分支只包含一个线性可训练算子,如果正确设置常尺度值,模型的性能会提高。我们将这种线性块称为Constant Scale Linear Addition(CSLA)。我们可以用单个算子替换一个CSLA块,并通过设计优化器改变梯度实现等价的训练动态。Repopt将这种乘数称为Grad Mult,如上图所示。
证明:用常规的SGD训练一个CSLA块相当于用修改的梯度训练一个简单的卷积
CSLA块中每个分支只包含一个可训练线性算子,并且结构中不存在BN或者dropout等非线性操作。Repopt发现用常规的SGD训练一个CSLA块相当于用修改的梯度训练一个简单的卷积。下面用一个简单的例子证明这个结论。
假设CSLA由两个相同形状的卷积组成,其中每个核包含一个可训练线性算子。如下面公式所示,其中 α A , α B \alpha_A,\alpha_B αA,αB为可训练线性算子,W为卷积的参数,X是输入,Y为CSLA的输出,*表示卷积操作。
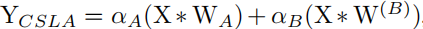
对应的梯度重参公式 Y G R = X ∗ W ′ Y_{GR}=X*W^{\prime} YGR=X∗W′,其中 W ′ W^{\prime} W′表示梯度重参后的卷积,假设损失函数为L,训练迭代数为i,卷积参数W的梯度表示为 ∂ L ∂ W \frac{\partial L}{\partial W} ∂W∂L, F ( ∂ L ∂ W ′ ) F(\frac{\partial L}{\partial W^{\prime}}) F(∂W′∂L)表示对应梯度重参上的任意变化,我们希望通过数次训练后CSLA的输出与梯度重参后的输出一致,即

通过卷积的线性可加性,我们需要保证公式6
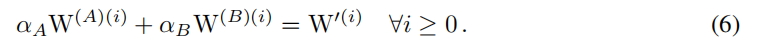
在i=0迭代开始前,正确的初始化确保了公式6的等价性,初始化如公式7所示
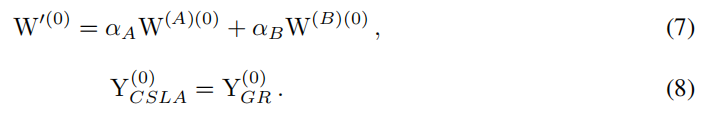
下面,我们用数学归纳法证明在 W ′ W^{\prime} W′的梯度上进行适当的变换后,公式6的等价性始终成立,W梯度更新的公式如下
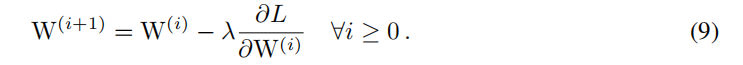
更新相应的CSLA块,我们获得公式10
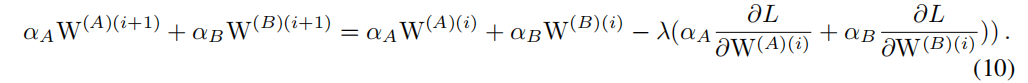
我们使用 F ( ∂ L ∂ W ′ ) F(\frac{\partial L}{\partial W^{\prime}}) F(∂W′∂L)来更新 W ′ W^{\prime} W′,这就意味着
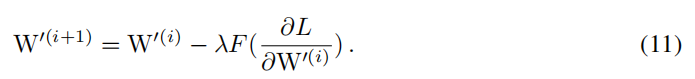
假设在迭代第i次时,公式6,10,11成立,那么可以获得公式12
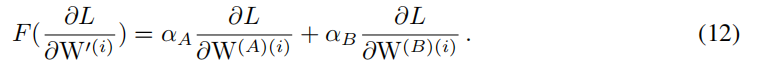
对公式6取偏导数,有公式13
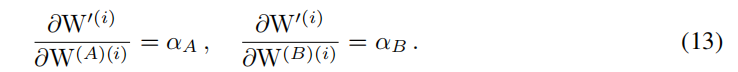
我们获得等式14,即 F ( ∂ L ∂ W ′ ) F(\frac{\partial L}{\partial W^{\prime}}) F(∂W′∂L)的准确形式
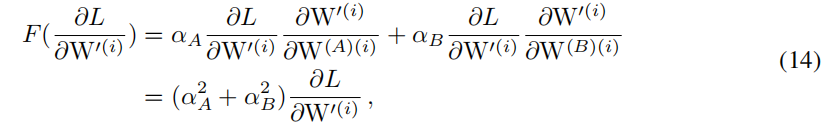
由公式11,14,我们可以推到出,当迭代到i+1次时,下面等式成立
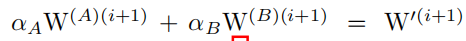
由于假设公式6成立
通过初始条件公式7,8,以及数学归纳法我们可以证明当i>=0时,公式6成立。同时,我们知道 F ( ∂ L ∂ W ′ ) F(\frac{\partial L}{\partial W^{\prime}}) F(∂W′∂L)的准确形式,如公式14所示。
Method
上文,已经介绍了Repopt找到一个合适的结构先验CSLA块,并通过数学归纳证明可以通过梯度重参将CSLA等效为简单的卷积操作,下面,我们使用RepOpt-VGG作为展示例,具体介绍Repopt如何设计和描述梯度重参的行为。
在RepOptVGG中,对应的CSLA块则是将RepVGG块中的3x3卷积,1x1卷积,bn层替换为带可学习缩放参数的3x3卷积,1x1卷积。进一步拓展到多分支中,假设s,t分别是3x3卷积,1x1卷积的缩放系数,那么对应的更新规则为:
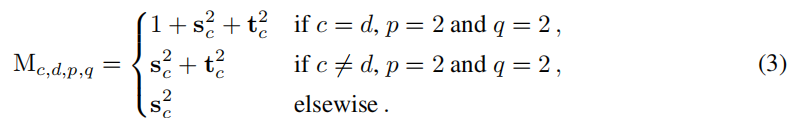
对公式3的理解需要结合RepVGG,当输入与输出通道不等时,只存在conv3x3, conv1x1两个分支,其中conv1x1可以等效为特殊的conv3x3,因此梯度可以重参为 s c 2 + t c 2 s_c^2+t_c^2 sc2+tc2,如上文所证明一样。而当输入与输出通道相等时,此时一共有3个分支,分别是identity,conv3x3, conv1x1,Identity也可以等效为特殊的conv3x3,其卷积核由0,1组成,所以梯度重参为 1 + s c 2 + t c 2 1+s_c^2+t_c^2 1+sc2+tc2。
需要注意的是CSLA没有BN这种训练期间非线性算子(training-time nonlinearity),也没有非顺序性(non sequential)可训练参数,CSLA在这里只是一个描述RepOptimizer的间接工具。
那么剩下一个问题,即如何确定这个缩放系数
HyperSearch
受DARTS启发,我们将CSLA中的常数缩放系数,替换成可训练参数。在一个小数据集(如CIFAR100)上进行训练,在小数据上训练完毕后,我们将这些可训练参数固定为常数。
Code
LinearAddBlock定义的是CSLA块,该模块只在确定HyperSearch的时候被训练。
class LinearAddBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1,
dilation=1, groups=1, padding_mode='zeros', use_se=False, is_csla=False, conv_scale_init=1.0):
super(LinearAddBlock, self).__init__()
self.in_channels = in_channels
self.relu = nn.ReLU()
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=False)
self.scale_conv = ScaleLayer(num_features=out_channels, use_bias=False, scale_init=conv_scale_init)
self.conv_1x1 = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=0, bias=False)
self.scale_1x1 = ScaleLayer(num_features=out_channels, use_bias=False, scale_init=conv_scale_init)
if in_channels == out_channels and stride == 1:
self.scale_identity = ScaleLayer(num_features=out_channels, use_bias=False, scale_init=1.0)
self.bn = nn.BatchNorm2d(out_channels)
if is_csla: # Make them constant
self.scale_1x1.requires_grad_(False)
self.scale_conv.requires_grad_(False)
if use_se:
raise NotImplementedError("se block not supported yet")
else:
self.se = nn.Identity()
def forward(self, inputs):
out = self.scale_conv(self.conv(inputs)) + self.scale_1x1(self.conv_1x1(inputs))
if hasattr(self, 'scale_identity'):
out += self.scale_identity(inputs)
out = self.relu(self.se(self.bn(out)))
return out
class ScaleLayer(torch.nn.Module):
def __init__(self, num_features, use_bias=True, scale_init=1.0):
super(ScaleLayer, self).__init__()
self.weight = Parameter(torch.Tensor(num_features))
init.constant_(self.weight, scale_init)
self.num_features = num_features
if use_bias:
self.bias = Parameter(torch.Tensor(num_features))
init.zeros_(self.bias)
else:
self.bias = None
def forward(self, inputs):
if self.bias is None:
return inputs * self.weight.view(1, self.num_features, 1, 1)
else:
return inputs * self.weight.view(1, self.num_features, 1, 1) + self.bias.view(1, self.num_features, 1, 1)
RealVGGBlock是RepOptVGG的真实模块,结构简单如下所示。
class RealVGGBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1,
dilation=1, groups=1, padding_mode='zeros', use_se=False,
):
super(RealVGGBlock, self).__init__()
self.relu = nn.ReLU()
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
if use_se:
raise NotImplementedError("se block not supported yet")
else:
self.se = nn.Identity()
def forward(self, inputs):
out = self.relu(self.se(self.bn(self.conv(inputs))))
return out
假设我们已经通过小数据训练获得了HyperSearch需要的scales,那么在训练RepOptVGG时,RepVGGOptimizer需要在初始化时候将CSLA块的scales赋值给RealVGGBlock,赋值的过程如reinitialize所示,对应了Method中的公式3。
def reinitialize(self, scales_by_idx, conv3x3_by_idx, use_identity_scales):
for scales, conv3x3 in zip(scales_by_idx, conv3x3_by_idx):
in_channels = conv3x3.in_channels
out_channels = conv3x3.out_channels
kernel_1x1 = nn.Conv2d(in_channels, out_channels, 1, device=conv3x3.weight.device)
if len(scales) == 2:
conv3x3.weight.data = conv3x3.weight * scales[1].view(-1, 1, 1, 1) \
+ F.pad(kernel_1x1.weight, [1, 1, 1, 1]) * scales[0].view(-1, 1, 1, 1)
else:
assert len(scales) == 3
assert in_channels == out_channels
identity = torch.from_numpy(np.eye(out_channels, dtype=np.float32).reshape(out_channels, out_channels, 1, 1)).to(conv3x3.weight.device)
conv3x3.weight.data = conv3x3.weight * scales[2].view(-1, 1, 1, 1) + F.pad(kernel_1x1.weight, [1, 1, 1, 1]) * scales[1].view(-1, 1, 1, 1)
if use_identity_scales: # You may initialize the imaginary CSLA block with the trained identity_scale values. Makes almost no difference.
identity_scale_weight = scales[0]
conv3x3.weight.data += F.pad(identity * identity_scale_weight.view(-1, 1, 1, 1), [1, 1, 1, 1])
else:
conv3x3.weight.data += F.pad(identity, [1, 1, 1, 1])
我们在梯度重参过程中需要获取梯度Mask,与reinitialize过程相似分为3种情况,具体实现如下所示。
def generate_gradient_masks(self, scales_by_idx, conv3x3_by_idx, cpu_mode=False):
self.grad_mask_map = {
}
for scales, conv3x3 in zip(scales_by_idx, conv3x3_by_idx):
para = conv3x3.weight
if len(scales) == 2:
mask = torch.ones_like(para, device=scales[0].device) * (scales[1] ** 2).view(-1, 1, 1, 1)
mask[:, :, 1:2, 1:2] += torch.ones(para.shape[0], para.shape[1], 1, 1, device=scales[0].device) * (scales[0] ** 2).view(-1, 1, 1, 1)
else:
mask = torch.ones_like(para, device=scales[0].device) * (scales[2] ** 2).view(-1, 1, 1, 1)
mask[:, :, 1:2, 1:2] += torch.ones(para.shape[0], para.shape[1], 1, 1, device=scales[0].device) * (scales[1] ** 2).view(-1, 1, 1, 1)
ids = np.arange(para.shape[1])
assert para.shape[1] == para.shape[0]
mask[ids, ids, 1:2, 1:2] += 1.0
if cpu_mode:
self.grad_mask_map[para] = mask
else:
self.grad_mask_map[para] = mask.cuda()
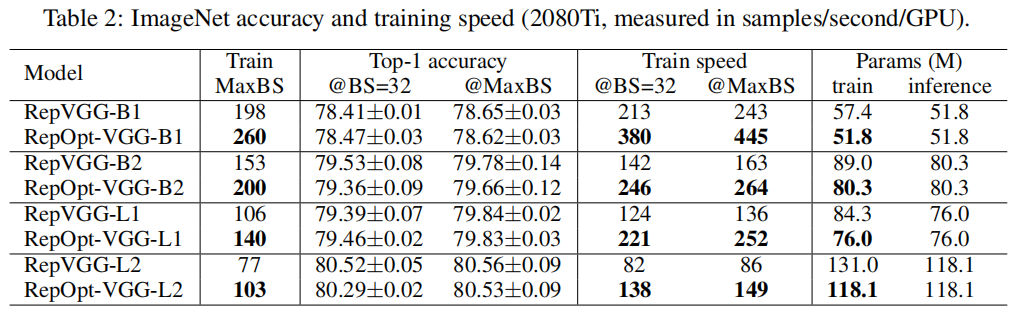
通过Repopt梯度重参的方式将结构先验转化为梯度先验,可以统一训练与测试模型结构,有效解决RepVGG量化不友好问题,其结构在YOLOV6中被使用,并表现出极佳的性能。