MLOps Engineering at Scale
目录
第 1 章
介绍了机器学习系统工程领域的广泛观点,以及将系统投入生产所需的条件。
- 没有MLOPS平台,机器学习从业者和容易瞎忙(“yak shaving” ),人们没有把注意力放在使产品获得巨大成功所需的功能上,而是把太多的工程时间花在明显不相关的活动上,如重新安装Linux设备驱动程序或在网上搜索正确的集群设置来配置数据处理中间件。
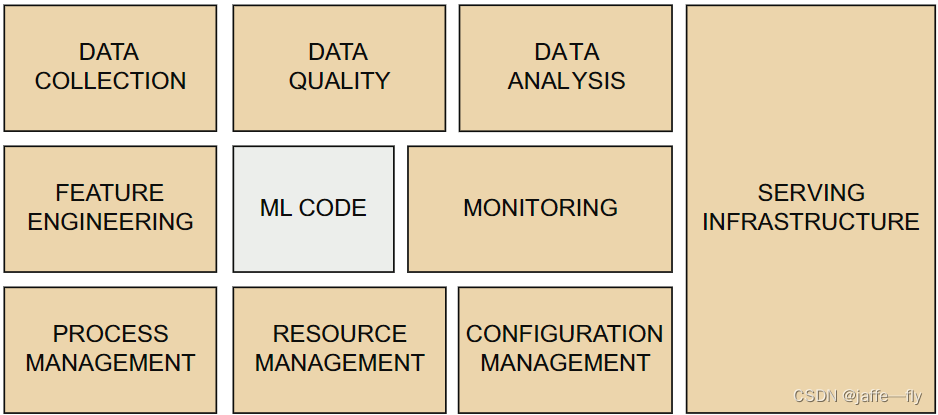
- 成熟的机器学习系统 “最终(最多)只有**5%**的机器学习代码”
-
https://academictorrents.com/致力于帮助机器学习从业者获得适合机器学习的公共数据集。有大量 1–5 TB 的数据集
-
云计算基础设置(Amazon Web Services, Microsoft Azure, or Google Cloud )可以帮助解决:
- 安全隔离:平台的多个用户可以在不同的机器学习项目和代码中并行工作
- 根据项目需要可以很方便的操作数据存储、计算和网络等
- 基于消耗量的计费,因此你的机器学习项目只需为你使用的资源计费。
-
Serverless machine learning:一种机器学习代码的软件开发模式,该代码写在云计算基础设施中托管的机器学习平台上运行,按量计费。Serverless并不意味着没有服务器,而是开发人员可以忽略云厂商服务器的存在而专注于编写代码。
-
https://www.deeplearningai.net/ 可以学习吴恩达的机器学习课程
第 2 章
向您介绍了华盛顿特区的出租车行程数据集,并教您如何开始在 Amazon Web Services (AWS) 公共云中使用该数据集进行机器学习。
- OpenStreetMap交互式地图上画图的网站
- flesystems 和 object storage 的区别:

- flesystems 文件系统将可变数据存储在指定位置。可以打开文件,导航到文件中的任何行或字节位置,根据需要更改内容,然后将更改保存回文件系统。由于文件系统中的文件是可变的,因此在您进行更改后,原始数据将在存储介质(例如,固态驱动器上)上被更改替换。
- object storage 对象存储中的对象是不可变的。在对象存储中创建对象后,它会保存创建对象时放置在对象中的数据。您可以根据更改创建对象的新版本,但就对象存储服务而言,新版本是占用额外存储空间的。当然,您也可以删除整个对象,释放存储空间。
- CSV 文件和传统关系数据库使用的行存储-专为事务处理而设计,可以一次更改一行数据。 Apache Parquet 和许多数据仓库使用的列存储适用于对不可变数据集的分析查询。
第 3 章
应用 AWS Athena 交互式查询服务深入挖掘数据集,发现数据质量问题,然后通过严格和有原则的数据质量保证流程解决这些问题。
- AWS Athena是一种交互式查询服务,让您能够轻松使用标准 SQL 分析 Amazon S3 中的数据。Athena 没有服务器,因此您无需管理任何基础设施,且只需为您运行的查询付费。
- Athena 使用开源的PrestoDB 分布式查询引擎开发而来,支持PB级别的数据
- Athena 使用 schema-on-read,schema-on-read 和 schema-on-write 的区别
- 数据质量的原则 VACUUM:
- VALID:数据类型是否正确,数据是否可以为null,数据值是否在范围内(0-100),数据是否在枚举的有效值之内,数据是否满足某些规则比如信用卡的校验规则
- ACCURATE:如果作为记录一部分的所有数据值都有效并且记录中的值组合与参考数据源一致,则数据记录是准确的。
- CONSISTENT:虽然每个单独的数仓都可以根据数仓的定义而有效和准确,consistent 的实现意味着在整合来自跨越不同技术和组织边界的数仓系统的数据之前,要确保一套共同的有效和准确数据的标准。
- UNIFORM:对于数据集中的每一列,所有记录都应使用使用相同(统一)测量系统记录的数据。
- UNIFIED:您还可以通过发现和定位训练数据集中不明显的系统性偏差数据,统一和协调项目运营环境的文化价值和项目内容,帮助最大限度地降低机器学习项目成功的风险。(一些违反常理的因果可以提前排除)
第 4 章
演示了如何使用统计方法来总结数据集样本并证明它们与整个数据集的相似性。本章还介绍了如何设置test、train和val数据集的大小,并使用云的分布式处理为机器学习准备数据集样本。
- 这一节没太懂
第 5 章
介绍 PyTorch tensor API的基础知识,并帮助您一定程度的熟练使用 API 。
第 6 章
重点介绍 PyTorch 的深度学习方面,包括对自动微分的支持、其他梯度下降算法和支持工具。
第 7 章
通过了解 GPU 特性以及如何利用它们来加速深度学习代码,如何扩展 PyTorch 程序。
第 8 章
介绍了分布式 PyTorch 并行训练方法,并深入介绍了传统的、基于参数的、基于服务器的方法和基于环的分布式训练(例如 Horovod)之间的区别
第 9 章
探讨了围绕特征选择和特征工程的用例,使用案例研究来建立关于可以为 DC 出租车数据集选择或设计的特征的直觉。
第 10 章
介绍了如何采用 PyTorch Lightning 的模板代码实现 DC 出租车 PyTorch 模型。此外,本章还介绍了PyTorch Lightning 训练、验证和测试的步骤。
第 11 章
将您的深度学习模型与 Optuna 的开源超参数优化框架集成,帮助您根据替代超参数值训练多个模型,然后根据 loss 和 metric 对训练后的模型进行排名。
第 12 章
将深度学习模型实现打包到 Docker 容器中,以便在整个机器学习管道的各个阶段运行它,从开发数据集一直到准备好用于生产部署的训练模型。
- Machine learning 的pipline 必须足够灵活使 hyper-parameter optimization (HPO) 管理
- pipline 的实现依靠下面的技术
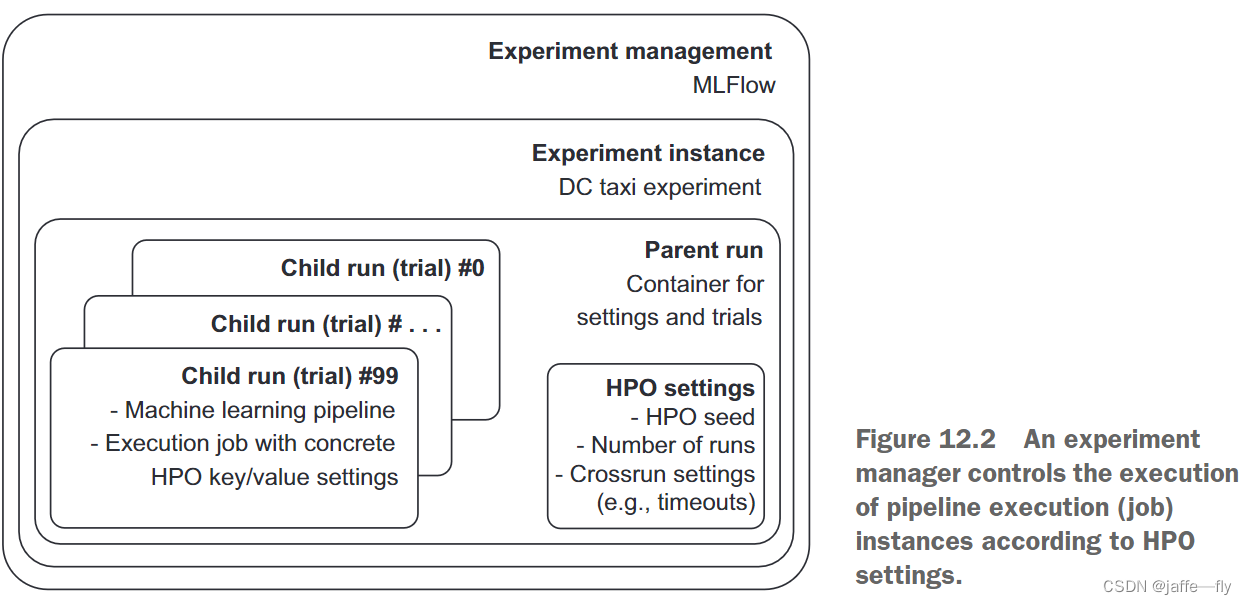
- MLFlow —For open source experiment management,类似还有Weights & Biases,Comet.ML,和 Neptune.AI
- Optuna —For hyperparameter optimization
- Docker —For pipeline component packaging and reproducible execution
- PyTorch Lighting —For PyTorch machine learning model training and validation
- Kaen —For provisioning and management of the pipeline across AWS and other
public cloud providers
- 通过云厂商的虚拟私有云 (VPC) 网络互连的 Docker 容器部署机器学习的pipline。
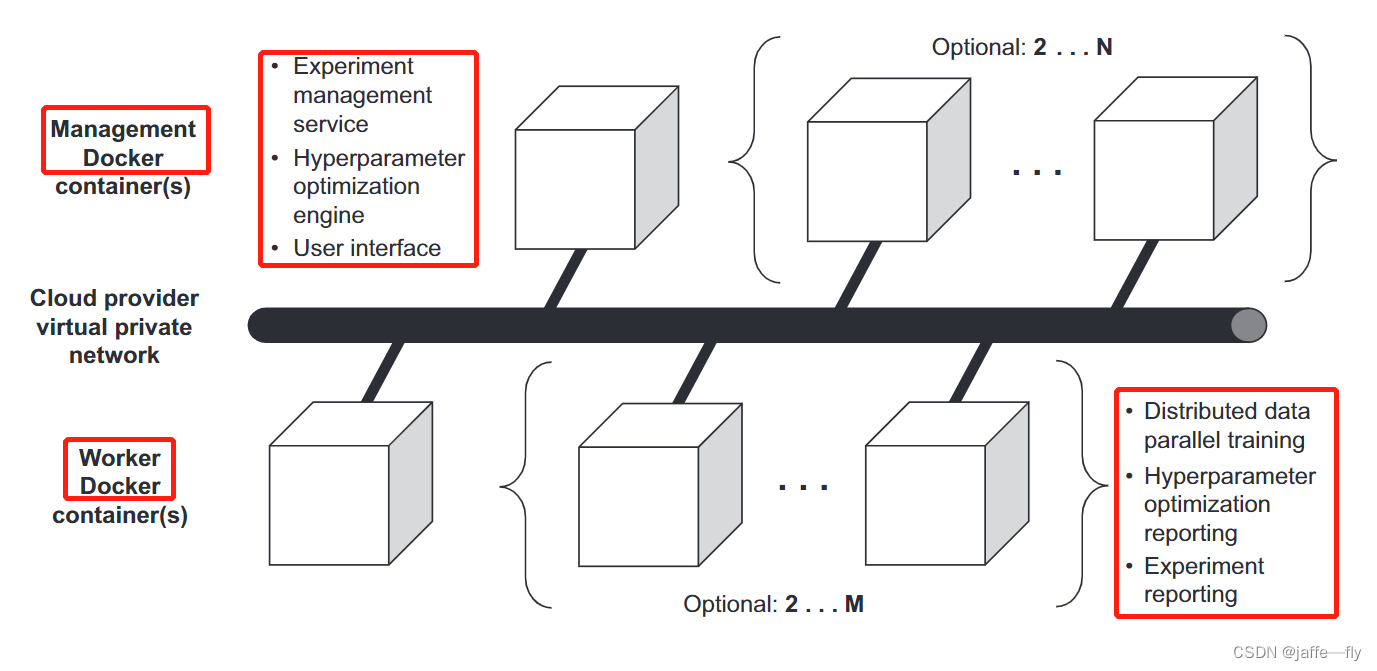
- 尽管原生 PyTorch 不提供与 AWS、Azure 或 GCP 等云提供商的集成,但Kaen framework 将 PyTorch 和 PyTorch Lightning 与云提供商的分布式训练联系起来。
pip install kaen[cli,docker]
kaen --help
资源
代码:https://github.com/osipov/smlbook
在线论坛:https://livebook.manning.com/book/mlops-engineering-at-scale/discussion