一、RNN是什么?
RNN全名循环神经网络,主要用于时间序列数据分析预测。与传统的ANN区别在于其将前一网络输出的部分信息保存并传递给后面的一层参与计算,使前后两个RNN模块建立关联。
| 传统ANN结构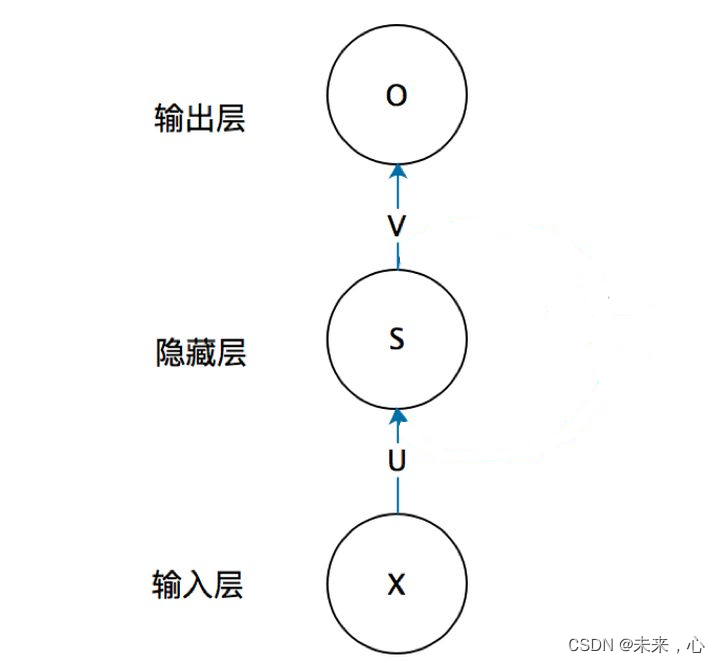
| RNN节后结构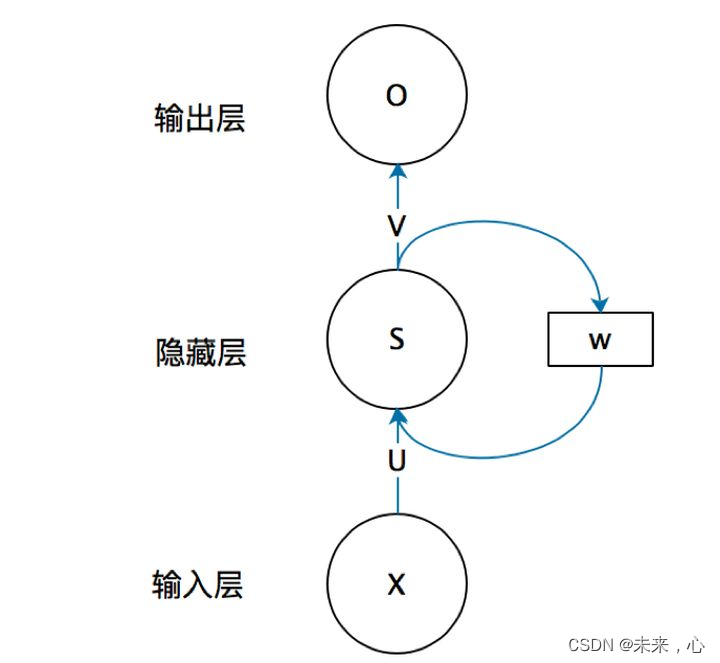
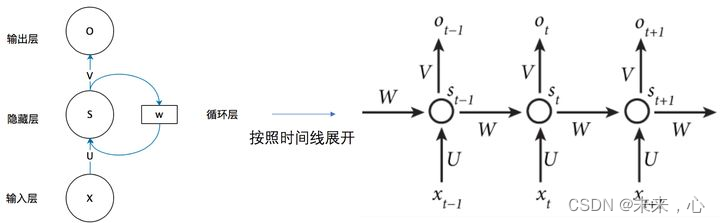
从上图我们可以看出RNN较ANN增加了一个权重W,现在我们来看看W是什么。循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
这里借用一张图表示其W的运作过程
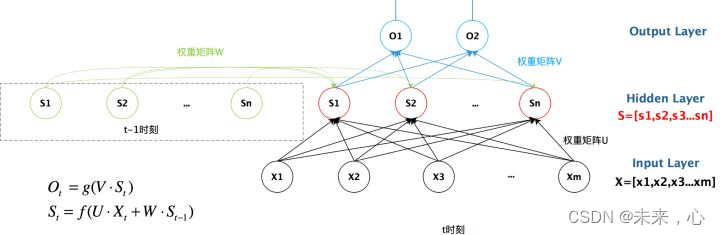
我们从上图就能够很清楚的看到,上一时刻的隐藏层是如何影响当前时刻的隐藏层的。
如果我们把上面的图展开,循环神经网络也可以画成下面这个样子
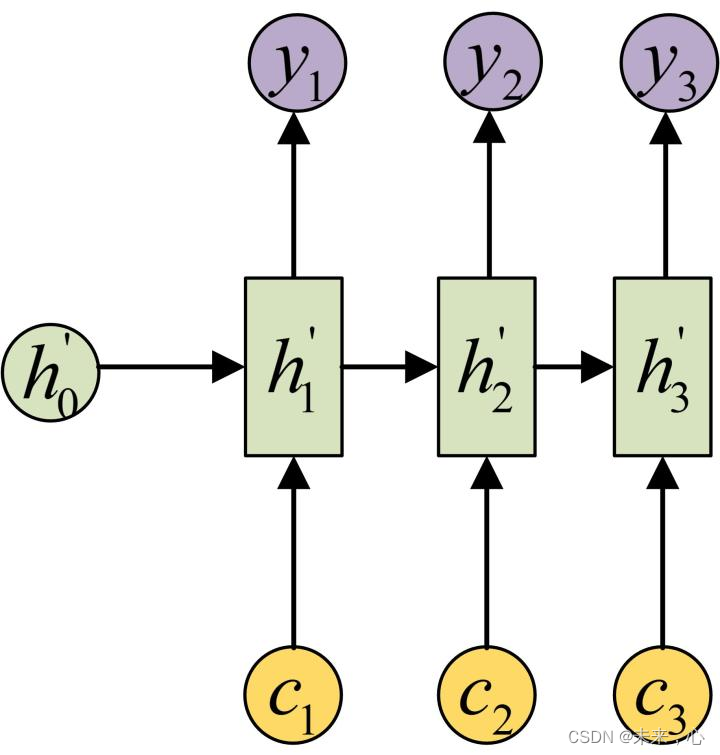
以上是三个RNN结构,其用公式为下图结果,每一层的均会传递权重矩阵W到下一层参与计算。
二、用途
那RNN到底用来做什么呢,首先RNN是对数据分析,其主要用于时间序列数据预测,即按照时间顺序输入已知的数据,来推断未来时间对应的数据值,应用领域比较多
应用场景如下:
文本生成:类似上面的填空题,给出前后文,然后预测空格中的词是什么。
机器翻译:翻译工作也是典型的序列问题,词的顺序直接影响了翻译的结果。
语音识别:根据输入音频判断对应的文字是什么。
生成图像描述:类似看图说话,给一张图,能够描述出图片中的内容。这个往往是 RNN 和 CNN 的结合。
这里引用文本识别的动图简单介绍下本文预测的过程
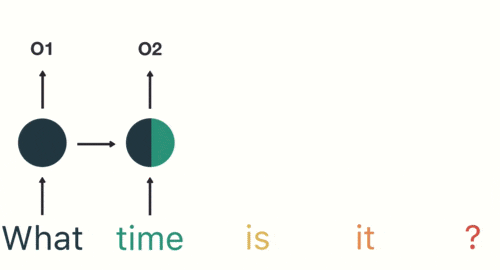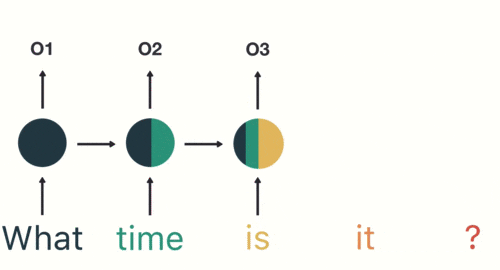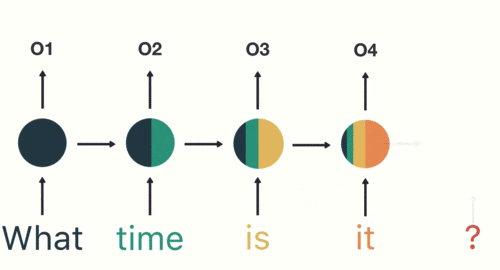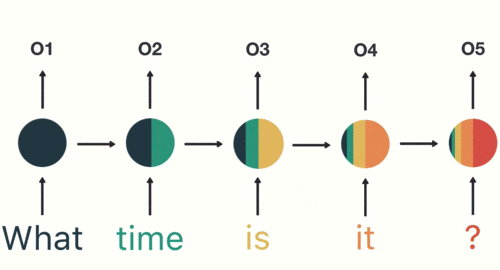
如上图所示,我们属于的文本是:What time,想预测后续单词,后续输出结果是:is it ?
案例就简单介绍到这里。
三、实战分享
股票数据预测
直接上代码。
运行环境:pycharm,python3.6,tensorflow=2.4
import os,math
from tensorflow.keras.layers import Dropout, Dense, SimpleRNN
from sklearn.preprocessing import MinMaxScaler
from sklearn import metrics
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
data = pd.read_csv('./data/SH600519.csv') # 读取股票文件
"""
前(2426-300=2126)天的开盘价作为训练集,表格从0开始计数,2:3 是提取[2:3)列,前闭后开,故提取出C列开盘价
后300天的开盘价作为测试集
"""
training_set = data.iloc[0:2426 - 300, 2:3].values
test_set = data.iloc[2426 - 300:, 2:3].values
sc = MinMaxScaler(feature_range=(0, 1))
training_set = sc.fit_transform(training_set)
test_set = sc.transform(test_set)
x_train = []
y_train = []
x_test = []
y_test = []
"""
使用前60天的开盘价作为输入特征x_train
第61天的开盘价作为输入标签y_train
for循环共构建2426-300-60=2066组训练数据。
共构建300-60=260组测试数据
"""
for i in range(60, len(training_set)):
x_train.append(training_set[i - 60:i, 0])
y_train.append(training_set[i, 0])
for i in range(60, len(test_set)):
x_test.append(test_set[i - 60:i, 0])
y_test.append(test_set[i, 0])
# 对训练集进行打乱
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
"""
将训练数据调整为数组(array)
调整后的形状:
x_train:(2066, 60, 1)
y_train:(2066,)
x_test :(240, 60, 1)
y_test :(240,)
"""
x_train, y_train = np.array(x_train), np.array(y_train) # x_train形状为:(2066, 60, 1)
x_test, y_test = np.array(x_test), np.array(y_test)
"""
输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]
"""
x_train = np.reshape(x_train, (x_train.shape[0], 60, 1))
x_test = np.reshape(x_test, (x_test.shape[0], 60, 1))
model = tf.keras.Sequential([
SimpleRNN(100, return_sequences=True), #布尔值。是返回输出序列中的最后一个输出,还是全部序列。
Dropout(0.1), #防止过拟合
SimpleRNN(100),
Dropout(0.1),
Dense(1)
])
# 该应用只观测loss数值,不观测准确率,所以删去metrics选项,一会在每个epoch迭代显示时只显示loss值
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='mean_squared_error') # 损失函数用均方误差
history = model.fit(x_train, y_train,
batch_size=64,
epochs=20,
validation_data=(x_test, y_test),
validation_freq=1) #测试的epoch间隔数
model.summary()
plt.plot(history.history['loss'] , label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.legend()
plt.show()
#预测
predicted_stock_price = model.predict(x_test) # 测试集输入模型进行预测
predicted_stock_price = sc.inverse_transform(predicted_stock_price) # 对预测数据还原---从(0,1)反归一化到原始范围
real_stock_price = sc.inverse_transform(test_set[60:]) # 对真实数据还原---从(0,1)反归一化到原始范围
# 画出真实数据和预测数据的对比曲线
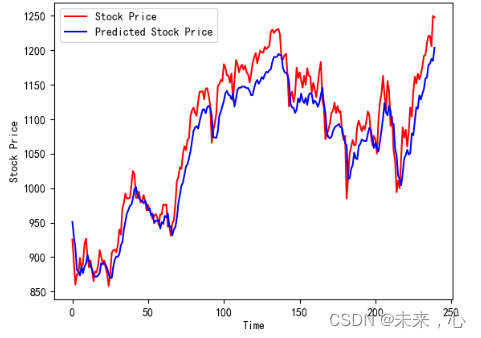
plt.plot(real_stock_price, color='red', label='Stock Price')
plt.plot(predicted_stock_price, color='blue', label='Predicted Stock Price')
plt.xlabel('Time')
plt.ylabel('Stock Price')
plt.legend()
plt.show()
"""
MSE :均方误差 -----> 预测值减真实值求平方后求均值
RMSE :均方根误差 -----> 对均方误差开方
MAE :平均绝对误差-----> 预测值减真实值求绝对值后求均值
R2 :决定系数,可以简单理解为反映模型拟合优度的重要的统计量
详细介绍可以参考文章:https://blog.csdn.net/qq_38251616/article/details/107997435
"""
MSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)
RMSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)**0.5
MAE = metrics.mean_absolute_error(predicted_stock_price, real_stock_price)
R2 = metrics.r2_score(predicted_stock_price, real_stock_price)
print('均方误差: %.5f' % MSE)
print('均方根误差: %.5f' % RMSE)
print('平均绝对误差: %.5f' % MAE)
print('R2: %.5f' % R2)
上述运算结果不是很理想
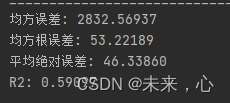
现调整网络结构,对其重新计算
本次修改主要是对网络参数进行调整,调整结果如下:
model = tf.keras.Sequential([
SimpleRNN(200, return_sequences=True), #布尔值。是返回输出序列中的最后一个输出,还是全部序列。
Dropout(0.5), #防止过拟合
SimpleRNN(300),
Dropout(0.5),
Dense(1)
])
调整后发现误差明显降低,因此后续可以按照此方向进行调整,不断缩小误差。
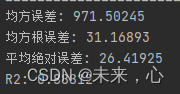
下面是训练验证过程曲线:
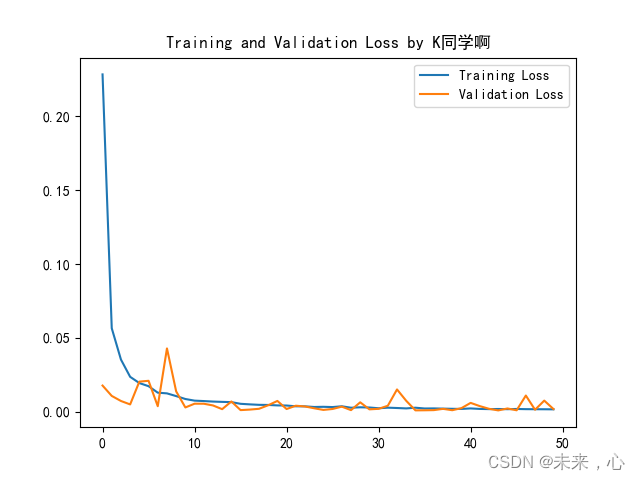
真实曲线与预测对比虚线
补充:
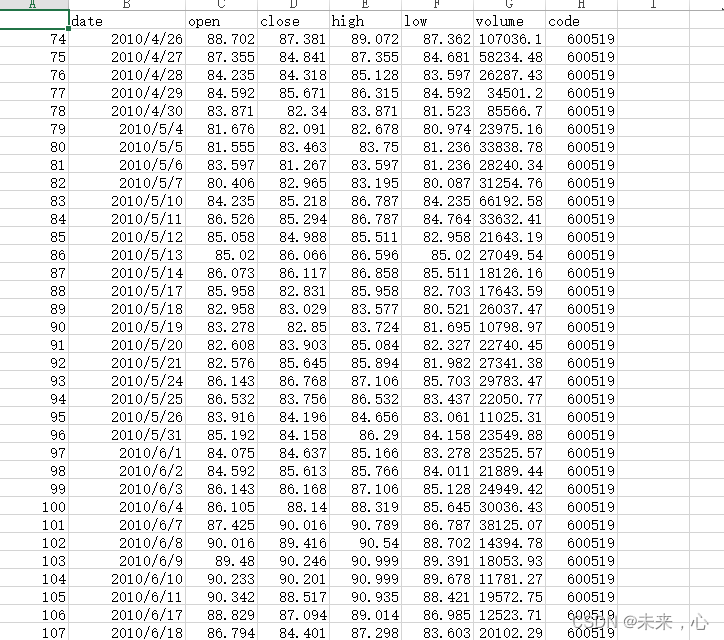
如果大家想根据自己的实际情况进行预测,数据格式可以参考下图
最后这里将使用数据分享给大家。
链接:https://pan.baidu.com/s/13N7U9x2SLL7gRcRfucSpJg
提取码:qoj5
致谢:K同学啊,参考:深度学习100例-循环神经网络(RNN)实现股票预测 | 第9天