提升模型精度
- 数据增强(也就是pytorch里面的图像预处理)
- 学习率衰减
- 更好的优化方法(Adam\lookhead)
- dropout(防止过拟合)正则化
- BN层(是数据分布相同)
- 迁移学习+微调
- +增加数据集
以上几种方法 往往能够提升模型精度
在训练数据集时,怎么保存预测精度最高的参数(第几个epoch对应的精度)
保存模型(字典形式的保存)
state_dict就是一个简单的Python字典,它将模型中的可训练参数(比如weights和biases,batchnorm的running_mean、torch.optim参数等)通过将模型每层与层的参数张量之间一一映射,实现保存、更新、变化和再存储。
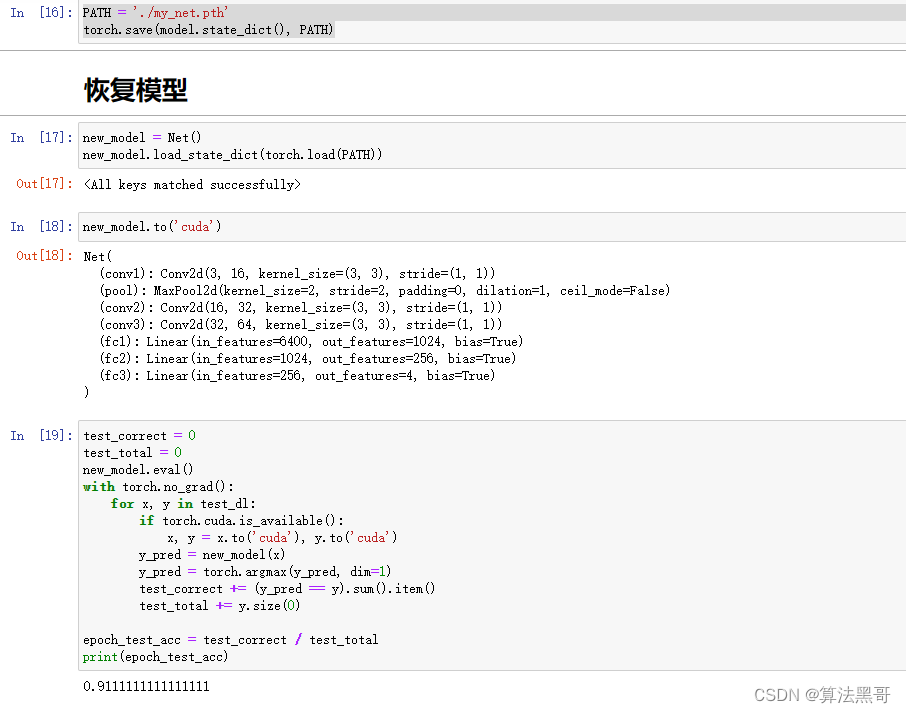
- 恢复模型前,需要先把模型的网络结果写出来
完整模型的保存与加载
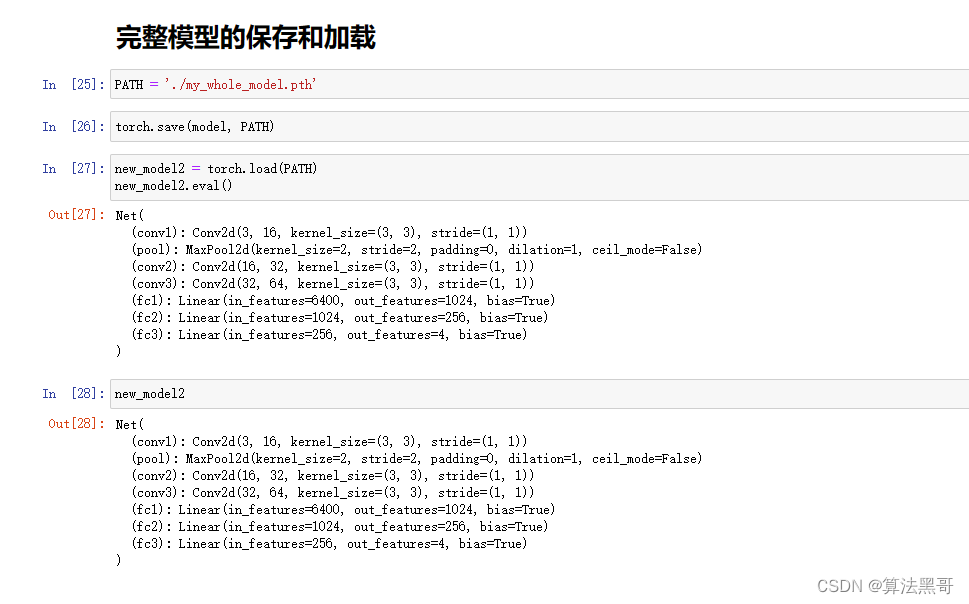
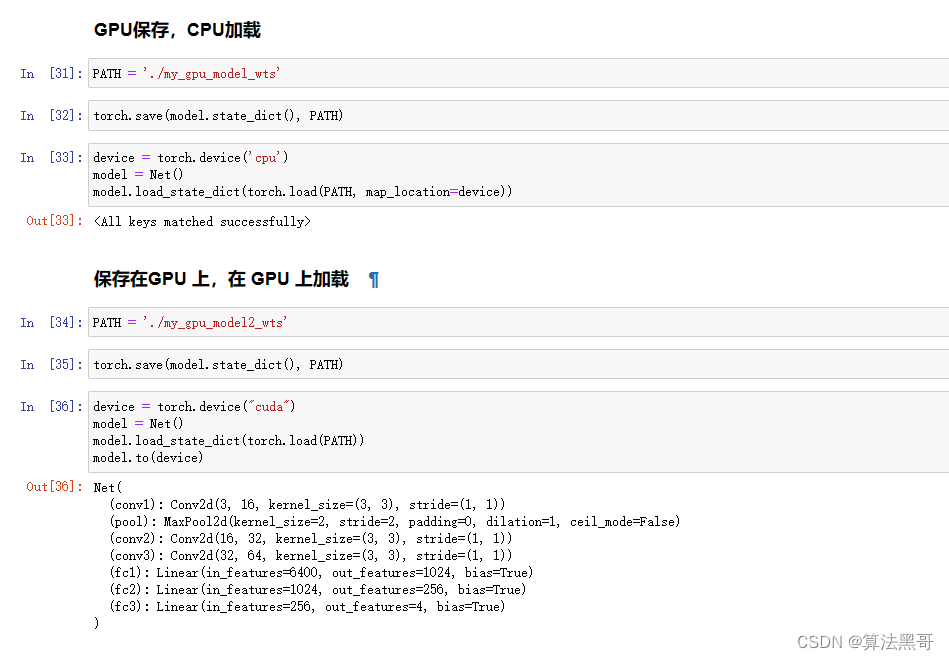

训练函数保存最优参数
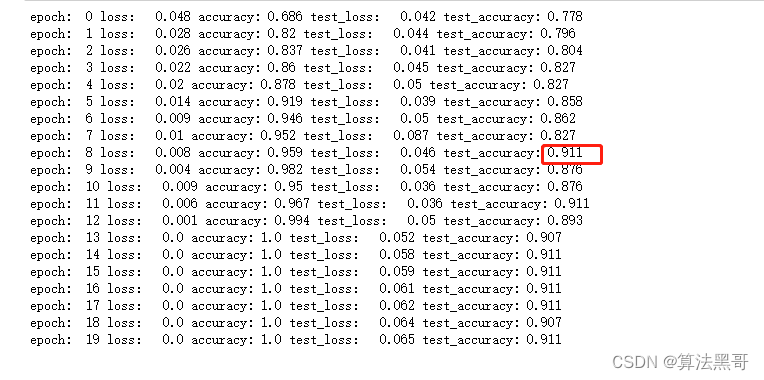
在训练过程中把预测效果最优的参数保存下来,然后再加载预测。其代码如下:
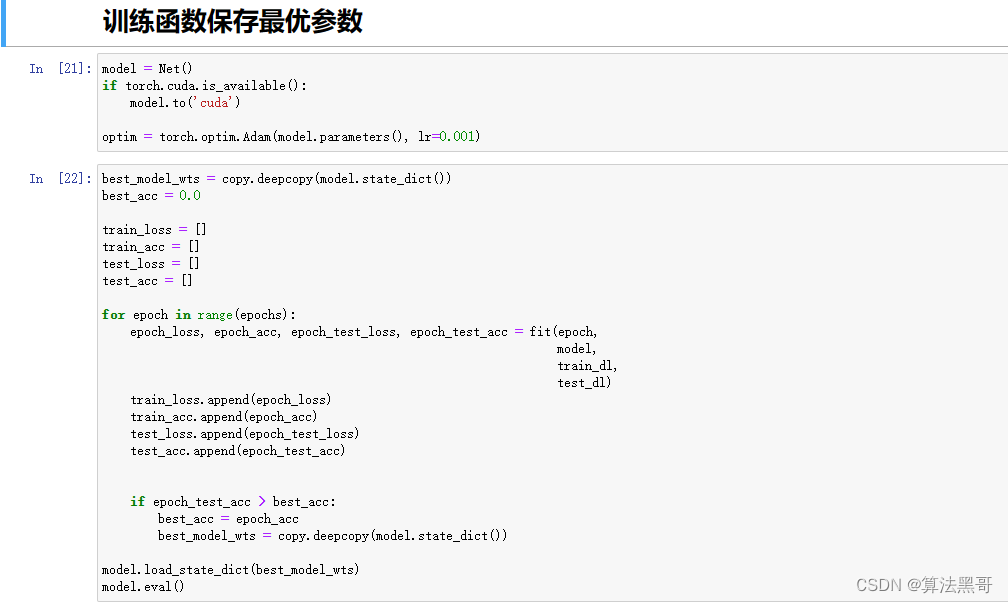
model = Net()
if torch.cuda.is_available():
model.to('cuda')
optim = torch.optim.Adam(model.parameters(), lr=0.001)
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch,
model,
train_dl,
test_dl)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
if epoch_test_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
model.load_state_dict(best_model_wts)
model.eval()