1.caffe的求解器(solver)是对模型的优化,使损失函数达到全局最小,即最优化的求解过程。
2.caffe官网上介绍了6种求解器的方法,denny的solver优化方法已经做过介绍,在solver.prototxt输入损失函数的类型type,Message type "caffe.SolverParameter"has no field named "type"报错。
3.看一下根目录/caffe/src/caffe/proto/caffe.proto
// Solver type
enum SolverType {
SGD = 0;
NESTEROV = 1;
ADAGRAD = 2;
}
optional SolverType solver_type = 30 [default = SGD];
// numerical stability for AdaGrad
optional float delta = 31 [default = 1e-8];
枚举了3种求解器类型,默认的SGD,还有Nesterov 的加速梯度法(Nesterov’s accelerated gradient),自适应梯度ADAGRAD(adaptive gradient),参数是solver_type。
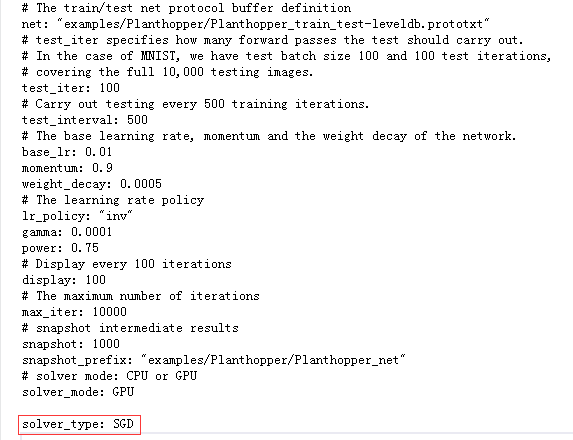
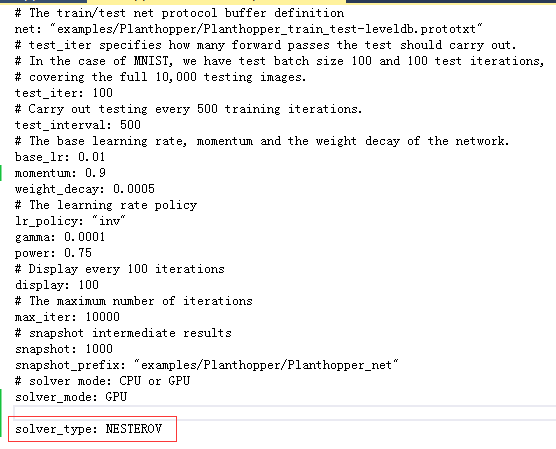
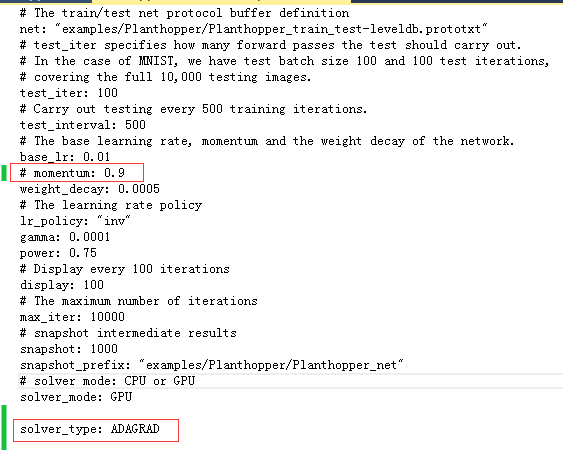
4.求解器的其他参数
主要的超参数
net:网络模型
test_iter:测试迭代次数,注意与batch_size区别,batch_size每次迭代训练图片的数量,一个epoch是将所以训练图像全部通过网络训练一次
test_interval:测试间隔
base_lr: 学习速率,最终速率为lr_mult*base_lr,网络结构中的两个lr_mult,第一个是权值学习率,第二个是偏置项学习率
lr_policy(gamma、power、step):学习速率衰减策略,可以设置为下面这些值,相应的学习率的计算为:
- fixed: 保持base_lr不变.
- step: 如果设置为step,则还需要设置一个stepsize, 返回 base_lr * gamma ^ (floor(iter / stepsize)),其中iter表示当前的迭代次数
- exp: 返回base_lr * gamma ^ iter, iter为当前迭代次数
- inv: 如果设置为inv,还需要设置一个power, 返回base_lr * (1 + gamma * iter) ^ (- power)
- multistep: 如果设置为multistep,则还需要设置一个stepvalue。这个参数和step很相似,step是均匀等间隔变化,而multistep则是根据stepvalue值变化
- poly: 学习率进行多项式误差, 返回 base_lr (1 - iter/max_iter) ^ (power)
- sigmoid: 学习率进行sigmod衰减,返回 base_lr ( 1/(1 + exp(-gamma * (iter - stepsize))))
gamma: 衰减系数
momentum:遗忘因子
weight_decay:权重衰减项,防止过拟合的一个参数
display:每训练多少次,在屏幕上显示一次
max_iter:最大迭代次数。这个数设置太小,会导致没有收敛,精确度很低。设置太大,会导致震荡,浪费时间。
snapshot: 打快照间隔
snapshot_prefix: 保存的文件路径
solver_mode:设置运行模式CPU或者GPU
solver_type:求解器类型,SGD,Nesterov,AdaGrad