1. 什么是有状态的应用
有了持久化存储 PersistentVolume,应用就可以把一些运行时的关键数据落盘,相当于有了一份“保险”,如果 Pod 发生意外崩溃,也只不过像是按下了暂停键,等重启后挂载 Volume,再加载原数据就能够满血复活,恢复之前的“状态”继续运行。
所以从这个角度来说,理论上任何应用都是有状态的。
只是有的应用的状态信息不是很重要,即使不恢复状态也能够正常运行,这就是我们常说的“无状态应用”。“无状态应用”典型的例子就是 Nginx 这样的 Web 服务器,它只是处理 HTTP 请求,本身不生产数据(日志除外),不需要特意保存状态,无论以什么状态重启都能很好地对外提供服务。
还有一些应用,运行状态信息就很重要了,如果因为重启而丢失了状态是绝对无法接受的,这样的应用就是“有状态应用”。
“有状态应用”的例子也有很多,比如 Redis、MySQL 这样的数据库,它们的“状态”就是在内存或者磁盘上产生的数据,是应用的核心价值所在,如果不能够把这些数据及时保存再恢复,那绝对会是灾难性的后果。
理解了这一点,我们结合目前学到的知识思考一下:Deployment 加上 PersistentVolume,在 Kubernetes 里是不是可以轻松管理有状态的应用了呢?
的确,用 Deployment 来保证高可用,用 PersistentVolume 来存储数据,确实可以部分达到管理“有状态应用”的目的。
但是 Kubernetes 的眼光则更加全面和长远,它认为“状态”不仅仅是数据持久化,在集群化、分布式的场景里,还有多实例的依赖关系、启动顺序和网络标识等问题需要解决,而这些问题恰恰是 Deployment 力所不及的。
因为只使用 Deployment,多个实例之间是无关的,启动的顺序不固定,Pod 的名字、IP 地址、域名也都是完全随机的,这正是“无状态应用”的特点。
但对于“有状态应用”,多个实例之间可能存在依赖关系,比如 master/slave、active/passive,需要依次启动才能保证应用正常运行,外界的客户端也可能要使用固定的网络标识来访问实例,而且这些信息还必须要保证在 Pod 重启后不变。
所以,Kubernetes 就在 Deployment 的基础之上定义了一个新的 API 对象,名字也很好理解,就叫 StatefulSet,专门用来管理有状态的应用。

2. 使用 YAML 描述 StatefulSet
首先我们还是用命令 kubectl api-resources 来查看 StatefulSet 的基本信息,可以知道它的简称是 sts,YAML 文件头信息是:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: xxx-sts
和 DaemonSet 类似,StatefulSet 也可以看做是 Deployment 的一个特例,它也不能直接用 kubectl create 创建样板文件,但它的对象描述和 Deployment 差不多,你同样可以把 Deployment 适当修改一下,就变成了 StatefulSet 对象。
这里我给出了一个使用 Redis 的 StatefulSet,你来看看它与 Deployment 有什么差异:
# redis-sts.yml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-sts
spec:
serviceName: redis-svc
replicas: 2
selector:
matchLabels:
app: redis-sts
template:
metadata:
labels:
app: redis-sts
spec:
containers:
- image: redis:5-alpine
name: redis
ports:
- containerPort: 6379
我们会发现,YAML 文件里除了 kind 必须是 StatefulSet ,在 spec 里还多出了一个 serviceName 字段,其余的部分和 Deployment 是一模一样的,比如 replicas、selector、template 等等。
这两个不同之处其实就是 StatefulSet 与 Deployment 的关键区别。想要真正理解这一点,我们得结合 StatefulSet 在 Kubernetes 里的使用方法来分析。
3. 在 Kubernetes 里使用 StatefulSet
让我们用 kubectl apply 创建 StatefulSet 对象,用 kubectl get 先看看它是什么样的:
kubectl apply -f redis-sts.yml
kubectl get sts
kubectl get pod
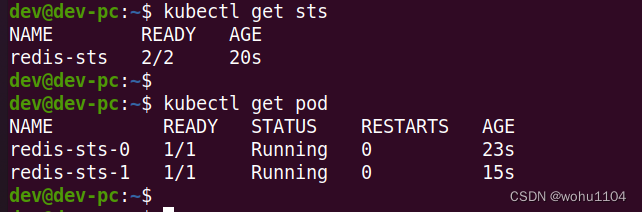
从截图里,你应该能够看到,StatefulSet 所管理的 Pod 不再是随机的名字了,而是有了顺序编号,从 0 开始分别被命名为 redis-sts-0、redis-sts-1,Kubernetes 也会按照这个顺序依次创建(0 号比 1 号的 AGE 要长一点),这就解决了“有状态应用”的第一个问题:启动顺序。
有了启动的先后顺序,应用该怎么知道自己的身份,进而确定互相之间的依赖关系呢?
Kubernetes 给出的方法是使用 hostname,也就是每个 Pod 里的主机名,让我们再用 kubectl exec 登录 Pod 内部看看:
kubectl exec -it redis-sts-0 -- sh

在 Pod 里查看环境变量 $HOSTNAME 或者是执行命令 hostname,都可以得到这个 Pod 的名字 redis-sts-0。
有了这个唯一的名字,应用就可以自行决定依赖关系了,比如在这个 Redis 例子里,就可以让先启动的 0 号 Pod 是主实例,后启动的 1 号 Pod 是从实例。
解决了启动顺序和依赖关系,还剩下第三个问题:网络标识,这就需要用到 Service 对象。
不过这里又有一点奇怪的地方,我们不能用命令 kubectl expose 直接为 StatefulSet 生成 Service,只能手动编写 YAML。
因为不能自动生成,你在写 Service 对象的时候要小心一些,metadata.name 必须和 StatefulSet 里的 serviceName 相同,selector 里的标签也必须和 StatefulSet 里的一致:
# redis-svc.yml
apiVersion: v1
kind: Service
metadata:
name: redis-svc
spec:
selector:
app: redis-sts
ports:
- port: 6379
protocol: TCP
targetPort: 6379
写好 Service 之后,还是用 kubectl apply 创建这个对象:
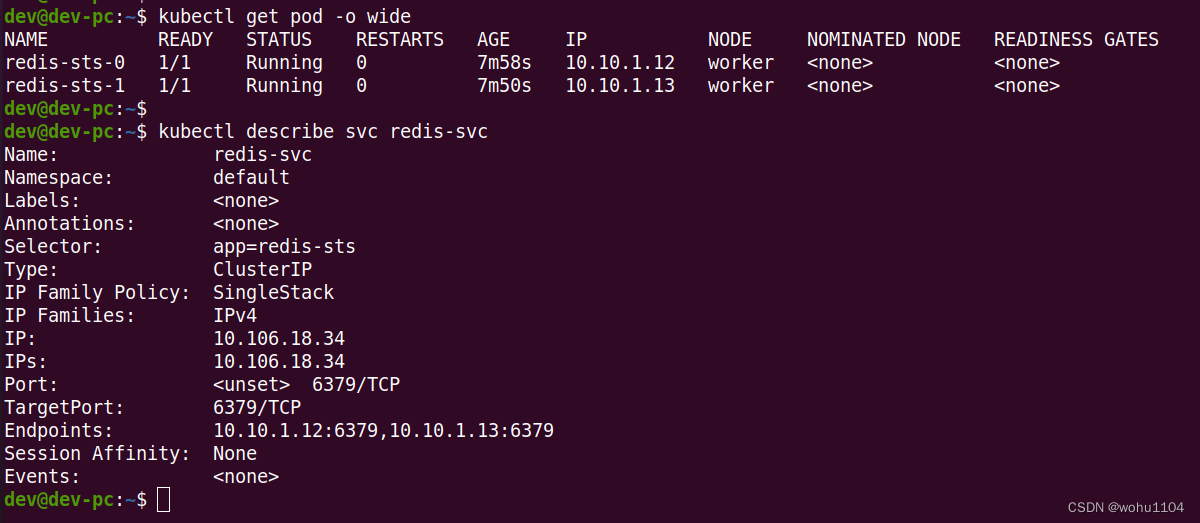
可以看到这个 Service 并没有什么特殊的地方,也是用标签选择器找到 StatefulSet 管理的两个 Pod,然后找到它们的 IP 地址。
不过,StatefulSet 的奥秘就在它的域名上。
Service 自己会有一个域名,格式是“对象名. 名字空间”,每个 Pod 也会有一个域名,形式是“IP 地址. 名字空间”。但因为 IP 地址不稳定,所以 Pod 的域名并不实用,一般我们会使用稳定的 Service 域名。
当我们把 Service 对象应用于 StatefulSet 的时候,情况就不一样了。
Service 发现这些 Pod 不是一般的应用,而是有状态应用,需要有稳定的网络标识,所以就会为 Pod 再多创建出一个新的域名,格式是 Pod 名. 服务名. 名字空间.svc.cluster.local 。当然,这个域名也可以简写成 Pod 名. 服务名。
我们还是用 kubectl exec 进入 Pod 内部,用 ping 命令来验证一下:
kubectl exec -it redis-sts-0 -- sh
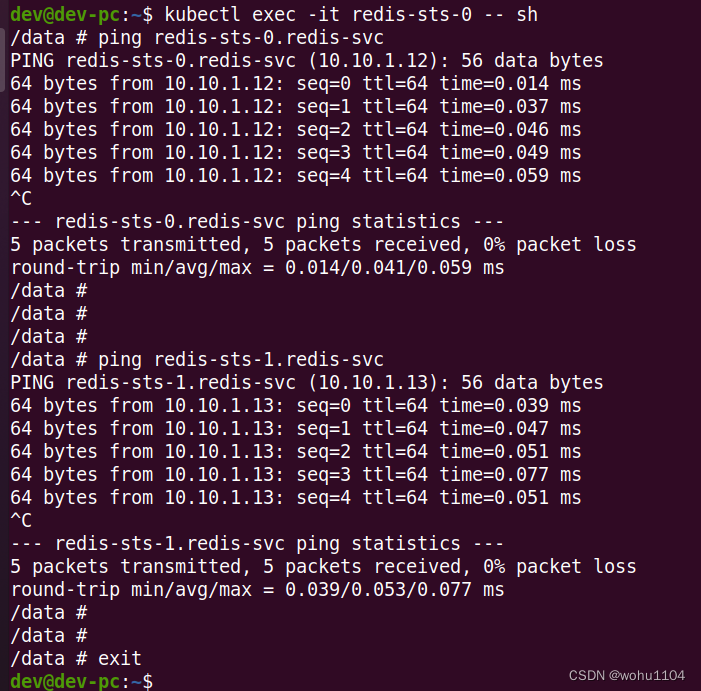
显然,在 StatefulSet 里的这两个 Pod 都有了各自的域名,也就是稳定的网络标识。那么接下来,外部的客户端只要知道了 StatefulSet 对象,就可以用固定的编号去访问某个具体的实例了,虽然 Pod 的 IP 地址可能会变,但这个有编号的域名由 Service 对象维护,是稳定不变的。
到这里,通过 StatefulSet 和 Service 的联合使用,Kubernetes 就解决了“有状态应用”的依赖关系、启动顺序和网络标识这三个问题,剩下的多实例之间内部沟通协调等事情就需要应用自己去想办法处理了。
关于 Service,有一点值得再多提一下。
Service 原本的目的是负载均衡,应该由它在 Pod 前面来转发流量,但是对 StatefulSet 来说,这项功能反而是不必要的,因为 Pod 已经有了稳定的域名,外界访问服务就不应该再通过 Service 这一层了。所以,从安全和节约系统资源的角度考虑,我们可以在 Service 里添加一个字段 clusterIP: None ,告诉 Kubernetes 不必再为这个对象分配 IP 地址。
我画了一张图展示 StatefulSet 与 Service 对象的关系,你可以参考一下它们字段之间的互相引用:

4. 实现 StatefulSet 的数据持久化
现在 StatefulSet 已经有了固定的名字、启动顺序和网络标识,只要再给它加上数据持久化功能,我们就可以实现对“有状态应用”的管理了。
这里就能用到上一节课里学的 PersistentVolume 和 NFS 的知识,我们可以很容易地定义 StorageClass,然后编写 PVC,再给 Pod 挂载 Volume。
不过,为了强调持久化存储与 StatefulSet 的一对一绑定关系,Kubernetes 为 StatefulSet 专门定义了一个字段 volumeClaimTemplates,直接把 PVC 定义嵌入 StatefulSet 的 YAML 文件里。这样能保证创建 StatefulSet 的同时,就会为每个 Pod 自动创建 PVC,让 StatefulSet 的可用性更高。
volumeClaimTemplates 这个字段好像有点难以理解,你可以把它和 Pod 的 template、Job 的 jobTemplate 对比起来学习,它其实也是一个“套娃”的对象组合结构,里面就是应用了 StorageClass 的普通 PVC 而已。
让我们把刚才的 Redis StatefulSet 对象稍微改造一下,加上持久化存储功能:
# redis-pv-sts.yml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-pv-sts
spec:
serviceName: redis-pv-svc
volumeClaimTemplates:
- metadata:
name: redis-100m-pvc
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Mi
replicas: 2
selector:
matchLabels:
app: redis-pv-sts
template:
metadata:
labels:
app: redis-pv-sts
spec:
containers:
- image: redis:5-alpine
name: redis
ports:
- containerPort: 6379
volumeMounts:
- name: redis-100m-pvc
mountPath: /data
首先 StatefulSet 对象的名字是 redis-pv-sts,表示它使用了 PV 存储。然后 volumeClaimTemplates 里定义了一个 PVC,名字是 redis-100m-pvc,申请了 100MB 的 NFS 存储。在 Pod 模板里用 volumeMounts 引用了这个 PVC,把网盘挂载到了 /data 目录,也就是 Redis 的数据目录。
下面的这张图就是这个 StatefulSet 对象完整的关系图:
 先执行上节里面的
先执行上节里面的
kubectl apply -f rbac.yml
kubectl apply -f class.yml
kubectl apply -f deployment.yml
然后执行
kubectl apply -f redis-pv-svc.yml
最后使用 kubectl apply 创建这些对象,一个带持久化功能的“有状态应用”就算是运行起来了:
kubectl apply -f redis-pv-sts.yml
可以使用命令 kubectl get pvc 来查看 StatefulSet 关联的存储卷状态:

看这两个 PVC 的命名,不是随机的,是有规律的,用的是 PVC 名字加上 StatefulSet 的名字组合而成,所以即使 Pod 被销毁,因为它的名字不变,还能够找到这个 PVC,再次绑定使用之前存储的数据。
那我们就来实地验证一下吧,用 kubectl exec 运行 Redis 的客户端,在里面添加一些 KV 数据:
kubectl exec -it redis-pv-sts-0 -- redis-cli
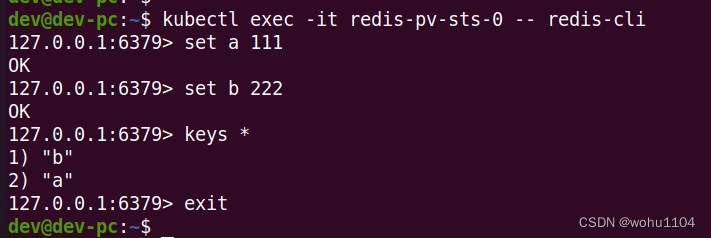
这里我设置了两个值,分别是 a=111 和 b=222。
现在我们模拟意外事故,删除这个 Pod:
kubectl delete pod redis-pv-sts-0
由于 StatefulSet 和 Deployment 一样会监控 Pod 的实例,发现 Pod 数量少了就会很快创建出新的 Pod,并且名字、网络标识也都会和之前的 Pod 一模一样:
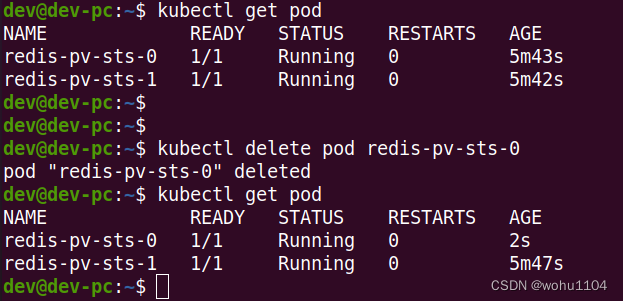
那 Redis 里存储的数据怎么样了呢?是不是真的用到了持久化存储,也完全恢复了呢?
可以再用 Redis 客户端登录去检查一下:
kubectl exec -it redis-pv-sts-0 -- redis-cli
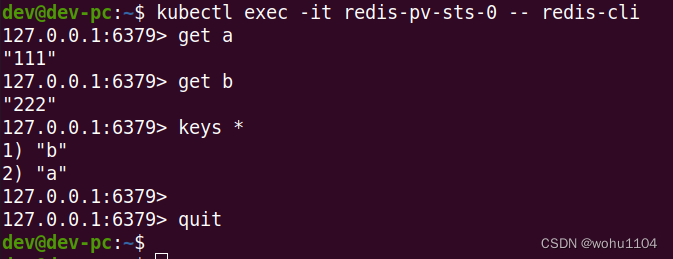
因为我们把 NFS 网络存储挂载到了 Pod 的 /data 目录,Redis 就会定期把数据落盘保存,所以新创建的 Pod 再次挂载目录的时候会从备份文件里恢复数据,内存里的数据就恢复原状了。
5. 总结
这节我们学习了专门部署“有状态应用”的 API 对象 StatefulSet,它与 Deployment 非常相似,区别是由它管理的 Pod 会有固定的名字、启动顺序和网络标识,这些特性对于在集群里实施有主从、主备等关系的应用非常重要。
StatefulSet的YAML描述和Deployment几乎完全相同,只是多了一个关键字段serviceName。- 要为
StatefulSet里的Pod生成稳定的域名,需要定义Service对象,它的名字必须和StatefulSet里的serviceName一致。 - 访问
StatefulSet应该使用每个Pod的单独域名,形式是Pod 名. 服务名,不应该使用Service的负载均衡功能。 - 在
StatefulSet里可以用字段volumeClaimTemplates直接定义PVC,让Pod实现数据持久化存储。
若不使用 volumeClaimTemplates 内嵌定义 PVC ,那么可能的后果就是,多个副本挂载同一个网络存储设备,这可能会导致数据丢失。
Pod 负责服务,Job 负责调度,
Daemon/Deployment 负责无状态部署,StatefulSet 负责状态部署,
Service 负责四层访问(负载均衡、IP分配、域名访问),Ingress 负责应用层(7层)访问(路由规则),
PVC/PV 负责可靠性存储。