- SQL和NOSQL的区别?
SQL |
NOSQL |
|
数据结构 |
结构化 |
非结构化 |
数据关联 |
关联的 |
非关联的 |
查询方式 |
SQL查询 |
非SQL查询 |
事物特性 |
ACID(事务) |
BASE |
存储方式 |
磁盘 |
内存 |
扩展性 |
垂直 |
水平 |
使用场景 |
|
|
2.Redis特征:
键值型 Value支持多种不同数据结构,功能丰富。
单线程 每个命令具有原子性。
低延迟、速度快(基于内存,10多路复用,良好的编码)。
支持数据持久化。
支持主从集群、分布集群。
支持多语言客户端。
3.基本类型:
String(字符串)
set key value //设置指定key的value值
get key //获取指定key的vaule值
getset key value //为key设置新的value,并返回key的旧值value
mget key1 key2 key3... //获取一个或多个key值value
setnx key //自动判断key值是否存在,key值不存在时自动添加,存在时无操作
strlen key //返回key所存储的字符串的长度
mset key1 value1 key2 value2 ... //同时添加元素
incr key //将key值存储的数字进行自增1
decr key //将key值存储的数字进行自减1
incrby num //将key所存储的值上给定的增量值num
append key value //如果key值所处的是字符串,将value值自动添加到原值的后面Hash(哈希)
hset key field value [filed value] //存放指定key的filed和value值
hdel key filed1 filed2 //删除一个或多个哈希表字段
hexists key filed //查看哈希表key中,指定的字段是否存在
hget key filed //获取存储在哈希表中指定key中的字段
hgetall key //获取在哈希表中指定key的所有字段和值
hincrby key filed num //为哈希表key中指定的字段的整数值加上增量num
hkeys key //获取所有哈希表中的字段
hlen key //获取哈希表中的字段的数量
hmset key filed1 filed2 //获取所有给定字段的值
hmset key filed1 value1 filed2 value2 //同时将多个filed-value设置到哈希表key中
hvals key //获取哈希表中的所有值List(列表)
特征:1.有序 2.元素可以重复 3.插入和删除快 4.查询速度一般
llen key //获取列表长度
lpop key //移出并获取列表中的第一个元素
lpush key value1 value2... //将一个值插入到已存在的列表的头部
lrange key num1 num2 //获取到num1,num2范围内的元素
lrem key count value //移出列表中的元素
lset key index value //通过索引(下表)设置列表元素的值
ltrim key num1 num2 //对一个列表进行修剪,在num1,num2中的元素进行保留,不在指定范围内的元素进行删除
rpop key //移出并获取列表中的最后一个元素
rpoplpush 列表 列表 //移出列表的最后一个元素,并将该元素添加到另一个列表进行返回
rpush key value1 value2 //在列表中红添加一个或者多个值
rpushx key value //为已存在的列表添加值Set(集合)
特征:1.无序 2.元素不可重复 3.查找快 4.支持交集、并集、差集
sadd key member1... //向集合中添加一个或多个成员
scard key //获取集合的成员数
sdiff key1 key2 //返回第一个集合和第二个集合的差异
sinter key1 key2 //返回给定所有集合的交集
sismember key member //判断member元素是否是集合key的成员
smembers key //返回集合中的所有成员
smove source destination member /将membe元素从source集合移动到destination集合
spop key //移除并返回该元素
srandmember key 数字 //返回集合中一个或多个元素
srem key member1... //移除集合中一个或多个元素
sunion key1 key2 //返回所有给定集合的并集SortedSet(有序集合 按分数进行排序 score)
特征:1.可排序 2.元素不重复 3.查询速度快
zadd key score1 member1 [score2 member2] //向有序集合添加一个或者多个成员或者更新已经存在的分数
zcard key //获取有序集合的成员数
zcount key min max //计算在有序集合中指定区间分数的成员数
zrange key start stop withscores //通过索引区间返回有序集合指定区间内的成员
zrevrangbyscore key max min withscores //返回有序集合中指定分数区间内的成员
zscore key member //返回有序集合,成员的分数值4.SpringDataRedis
提供了对不同Redis客户端的整合(Lettuce 和 Jedis)
提供了RedisTemplate 统一API来操作Redis
支持Redis的发布订阅模型
支持Redis哨兵和Redis集群
支持基于Lettuce的响应式编程
支持基于JDK、JSON、字符串、Spring对象的数据库序列化以及反序列化
支持基于Redis的JDKCollection实现
5.缓存
缓存定义:缓存就是数据交换的缓存区,是存储数据的临时地方,一般读写性能较高
缓存作用:1.降低后端负载 2.提高读写效率,降低响应时间
缓存的成本:1.数据一致性成本 2.代码维护成本 3.运维成本
缓存更新策略:
内存淘汰 |
超时剔除 |
主动更新 |
|
说明 |
不同自己维护,利用Redis的内存淘汰机制,当内存不足时自动淘汰部分数据,下次查询时更新缓存。 |
给缓存添加TTL时间,到期后自动删除缓存,下次查询时更新缓存 |
编写业务逻辑时,在修改数据库的同时,更新数据缓存 |
6.最佳实践方案
低一致性需求:使用Redis自带的内存淘汰机制
高一致性需求:主动更新,并以超时剔除,作为兜底方案
读操作
缓存命中直接返回
缓存未命中则查询数据库,并写入缓存,设置超时实践
写操作
先写数据库,然后再删除缓存
确保数据库与缓存操作的原子性
7.缓存穿透
缓存穿透:客户端请求的数据在缓存中和数据库中都不存在,这样缓存都不会生效,都会打在数据库中,解决方案:1.缓存空对象 2.布隆过滤 3.增强id的复用性 4.做好数据校验 5.做好热点参数的限流
缓存空对象的流程:
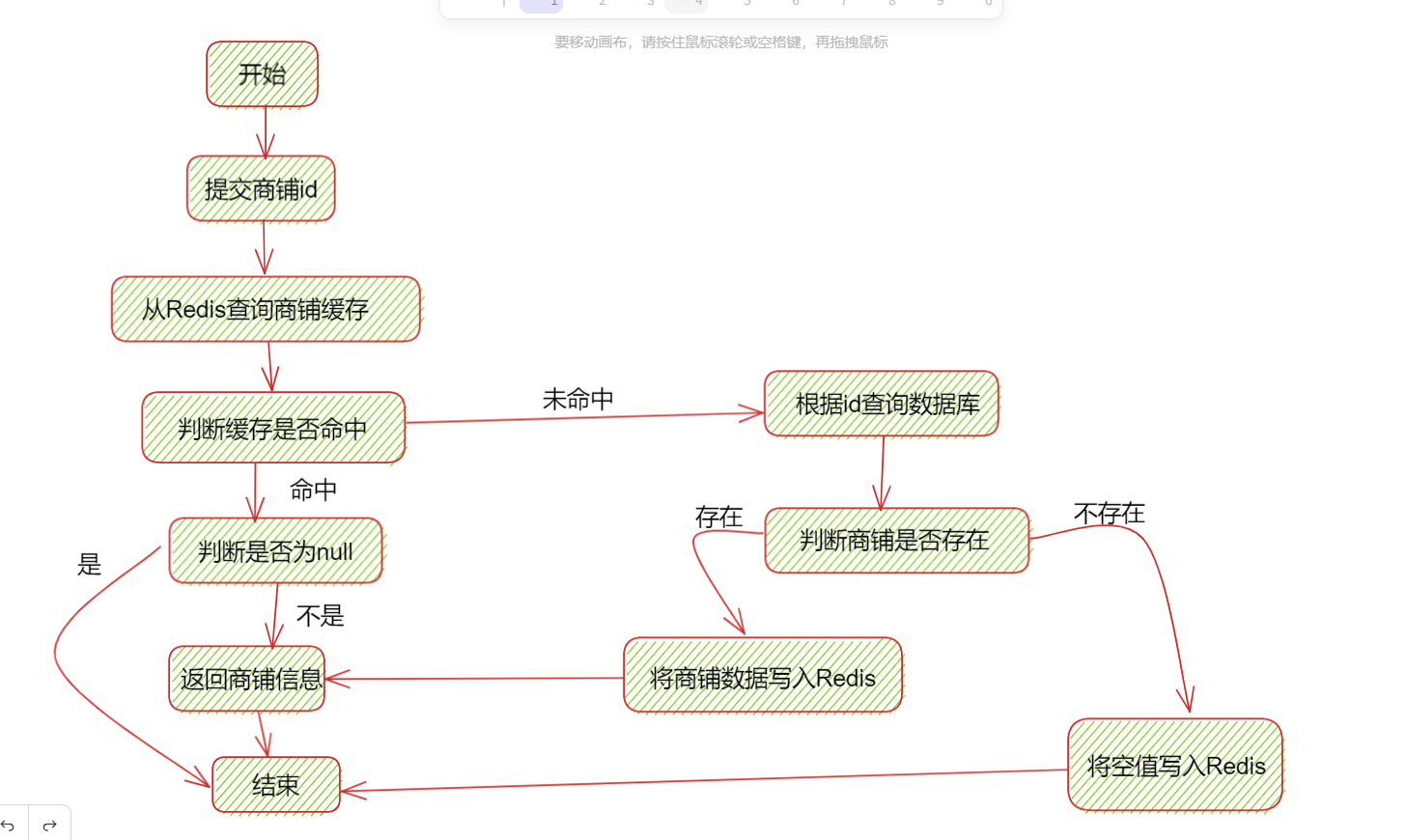
8.缓存雪崩
缓存雪崩:同一时段大量缓存key同时失效或者Redis服务宕机
解决方案:
给不同的key的TTL添加随机值
利用Redis集群提高服务的可用性
给缓存业务添加降级限流策略
给业务添加多级缓存
9.缓存击穿
缓存击穿:高并发访问并且缓存重建业务较为复杂的key突然失效,会给数据库带来巨大的冲击
解决方案:
互斥锁
优点:1.没有额外的内存消耗 2.保证一致性 3.实现简单
缺点:1.线程需要等待,性能受影响 2.可能有死锁的危险
实现流程:

逻辑过期
优点:1.线程无需等待,性能较好
缺点:1.不保证一致性 2.有额外内存消耗 3.实现复杂
实现流程:

10.缓存工具封装
基于StringRedisTemplate封装一个缓存工具类,满足下列需求:
将任意Java对象序列化为Json并存储在String类型的key中,并且设置TTL过期时间
将任意Java对象序列化为Json并存储在String类型的key中,并且设置逻辑过期时间,用于处理缓存击穿问题
根据指定的key查询缓存,并反序列化为指定类型,利用缓存空值的方式解决缓存穿透问题
根据指定的key值查询,并反序列化为指定类型,需要利用逻辑过期解决缓存击穿问题