清华技术成果转化的公司智谱 AI 开源了 GLM 系列模型 ChatGLM-6B,这是一个支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
ChatGLM-6B 是智谱 AI 在开源社区贡献的重要成果之一,也是清华大学在自然语言处理领域的创新突破之一。智谱 AI 希望通过开源 ChatGLM-6B 模型,促进对话系统的发展和应用,并与广大开发者和研究者共同探索更高效、更智能、更人性化的对话交互方式。
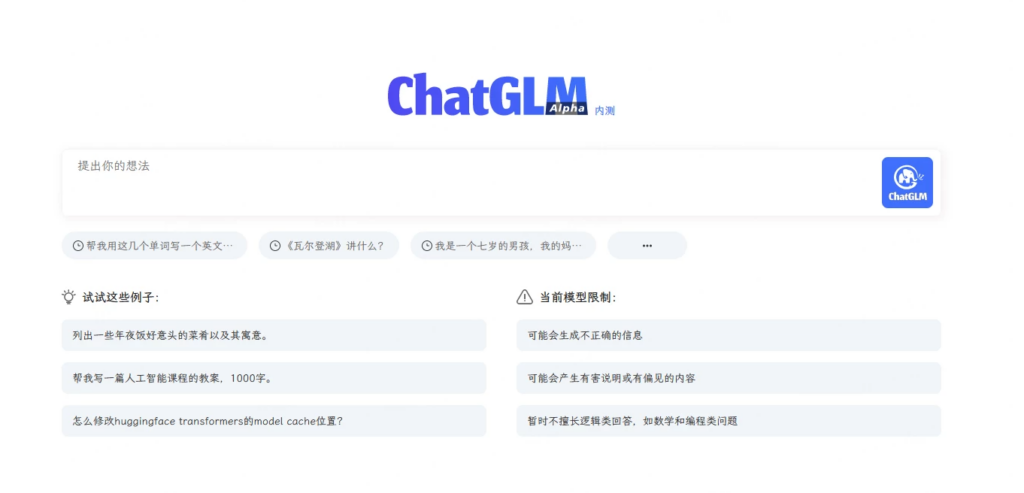
目前ChatGLM-6B 的不足可能包括以下几点:
它需要遵守特定的许可协议,不能用于商业目的或者侵犯他人权利。
它可能存在一些生成质量不高或者不符合人类偏好的回答,需要进一步改进模型或者引入人类反馈。
它可能没有覆盖到所有的中英文自然语言处理任务,需要根据不同的场景进行适当的微调或者适配。

ChatGLM 基于智谱 AI GLM-130B
GLM-130B 是一个开源的、支持中英双语的双向密集模型,具有 1300 亿参数,使用 General Language Model (GLM) 算法进行预训练。它可以在单个 A100 (40G * 8) 或 V100 (32G * 8) 服务器上支持带有 1300 亿参数的推理任务。结合 INT4 量化技术,可以降低硬件要求。
GLM-130B 是目前最大规模的开源双语预训练模型之一,也是 GPT-3 级别的模型之一。它在多个中英文自然语言处理任务上都取得了优异的表现。
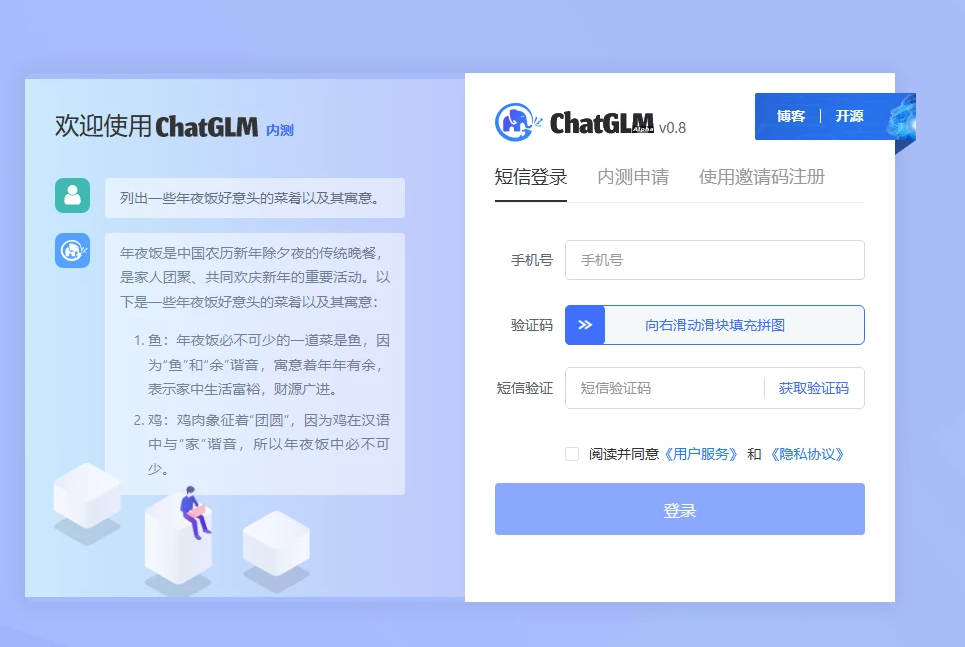
在线版的chaglm 目前还在内测阶段。 根据测试大模型的各项能力都已经接近chatgpt。