一、案例分析
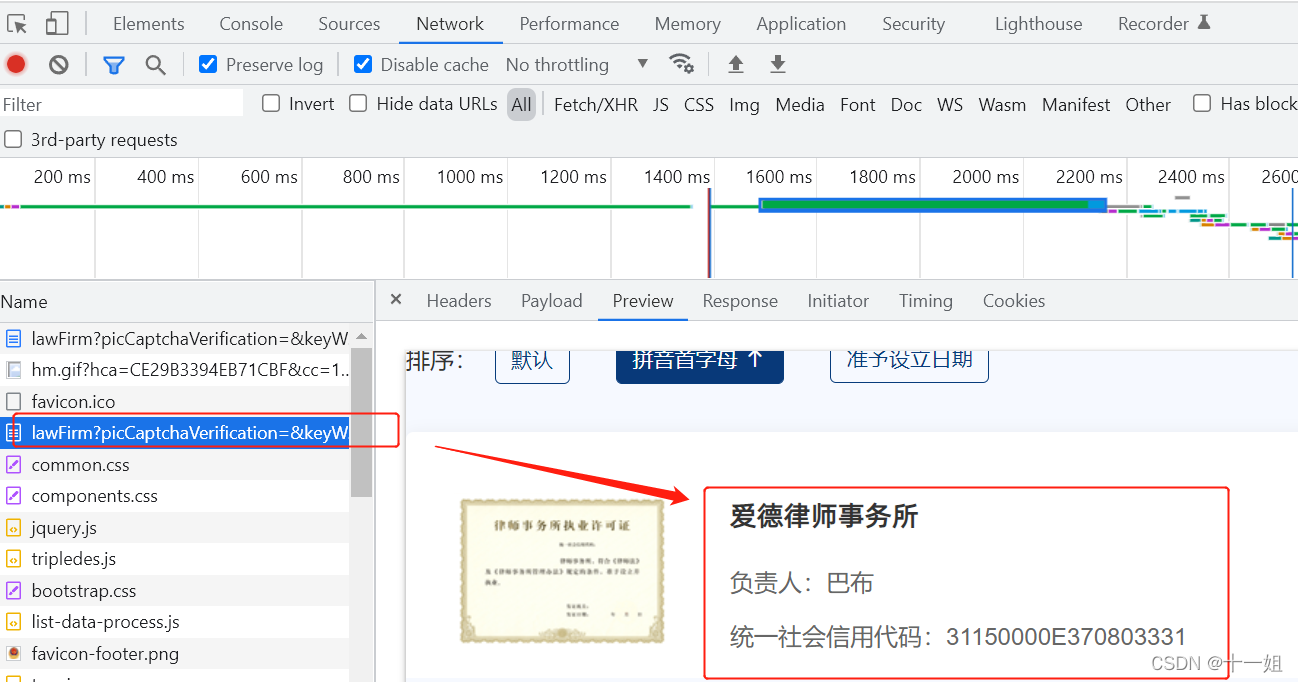
- 如图研究的是这个请求对应的数据,以及点击进入详情页后的过程, 案例网址:aHR0cHM6Ly9jcmVkaXQuYWNsYS5vcmcuY24vY3JlZGl0L2xhd0Zpcm0/cGljQ2FwdGNoYVZlcmlmaWNhdGlvbj0ma2V5V29yZHM9
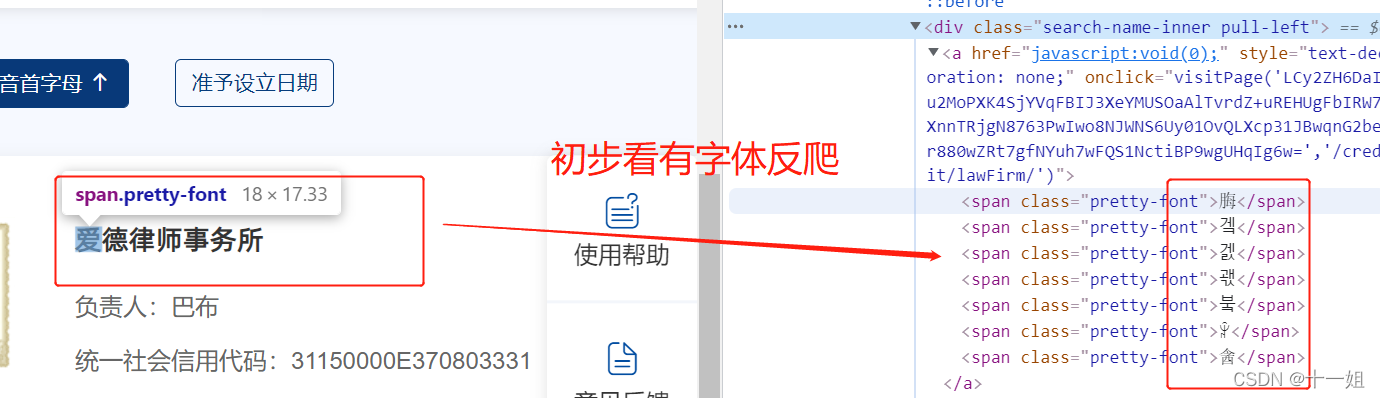
- 初步看有字体反爬,实际上通过一系列分析后会发现还有cookie反爬、des解密这两种,接下来看下面分析
二、反调试无限debugger与console
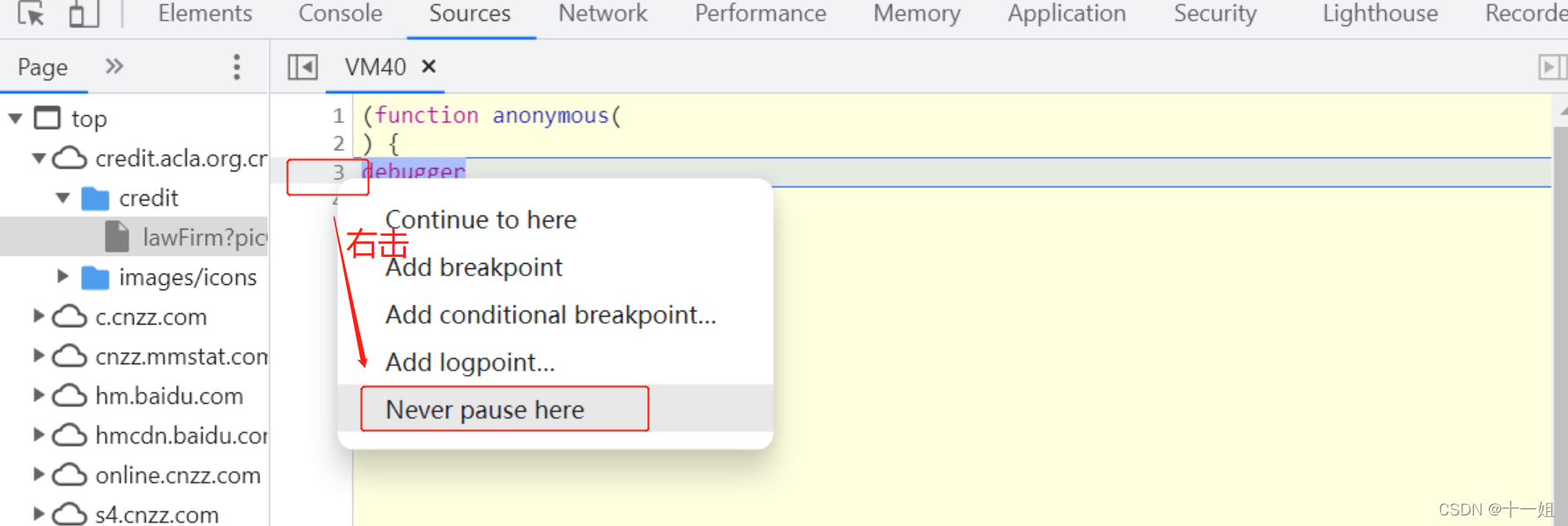
- 反爬1:无限debugger,打开谷歌开发者工具,按如图过无限debugger
- 反爬2:控制台console.clear / console.log 反调试,注入hook代码直接置空返回,或者新开一个标签页打开也可
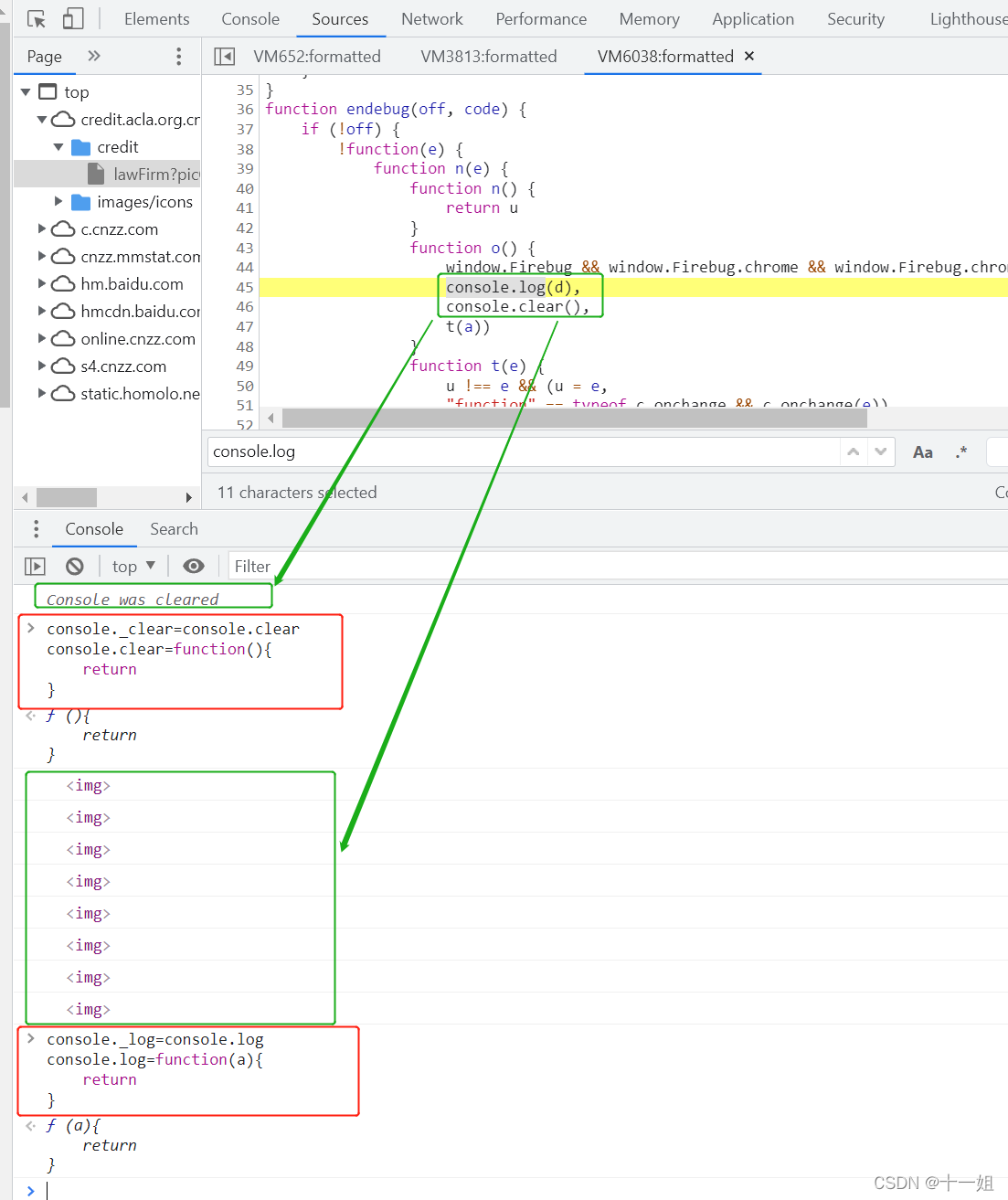
console._clear=console.clear console.clear=function(){ return } console._log=console.log console.log=function(a){ return }
三、jsfuck生成cookie
- 反爬3:cookie反爬,网页第一次响应返回jsfunck的代码用来生成cookie,第二次请求携带cookie才能获得正常数据

- 第一次响应请求的网页html源码如下,如图是jsfuck代码

- 去掉
()到控制台输出反混淆的真实代码如图,此时生成的是一个函数可自执行代码
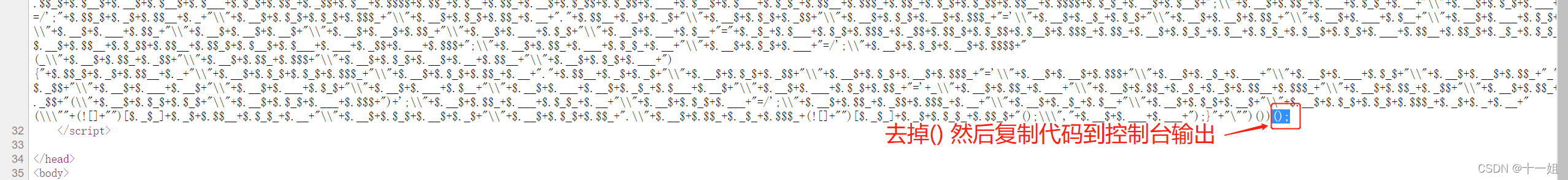
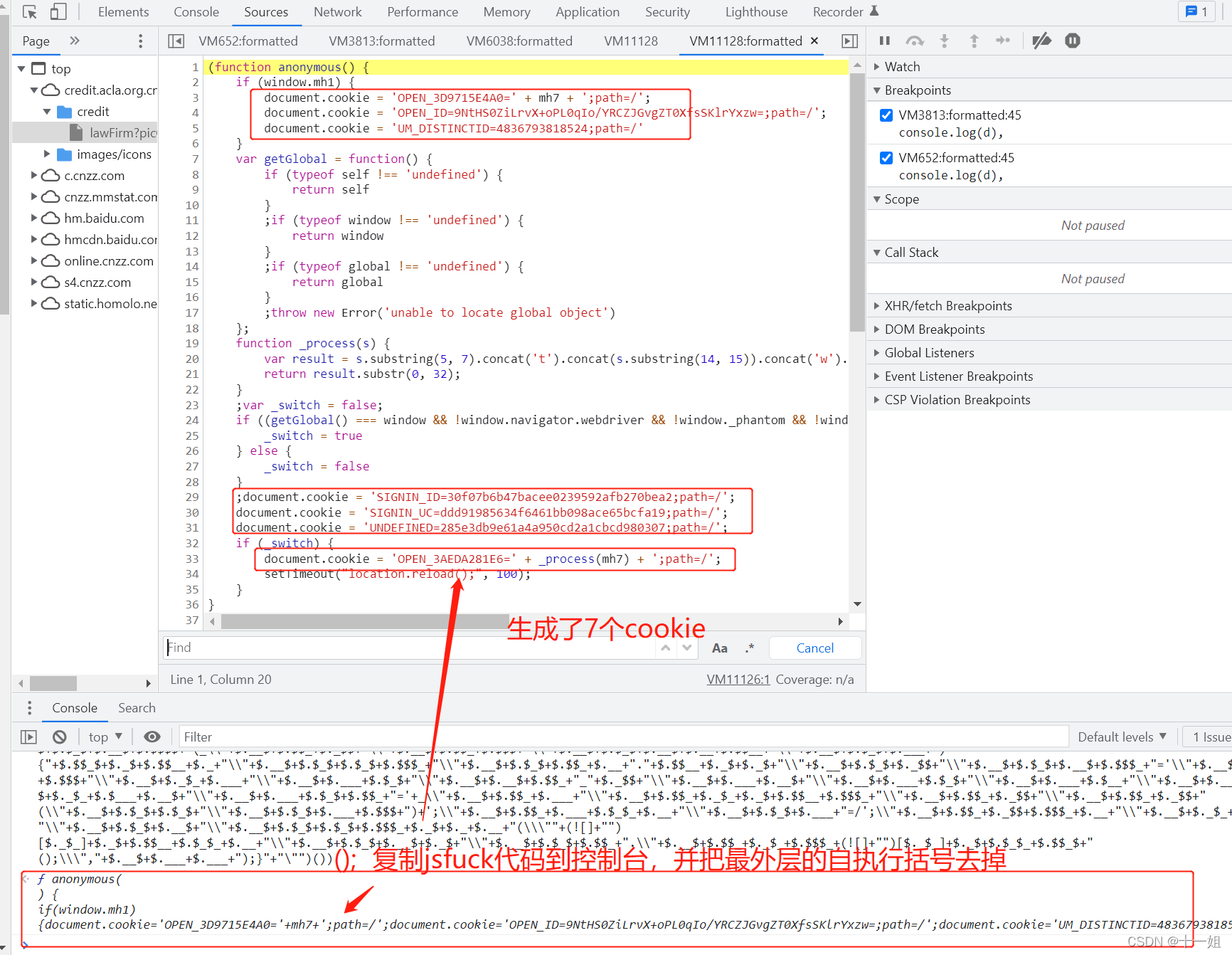
- 分析如上图片js代码生成cookie的逻辑,编写如下代码, 其中jsfuck代码除了要去掉最后一个自执行的括号外

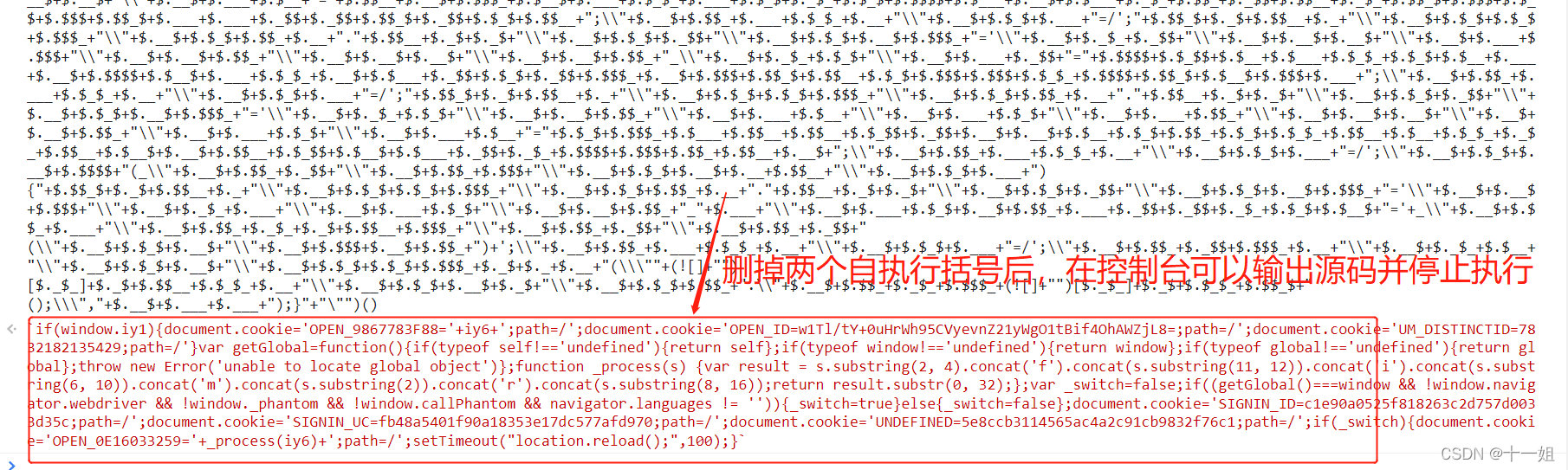
- 还需要去掉一个自执行的括号变得不可自执行,才能用
ctx.eval(new_js)的方式去输出获得源码,否则会报错缺少window/document等对象 更多jsfuck的代码介绍

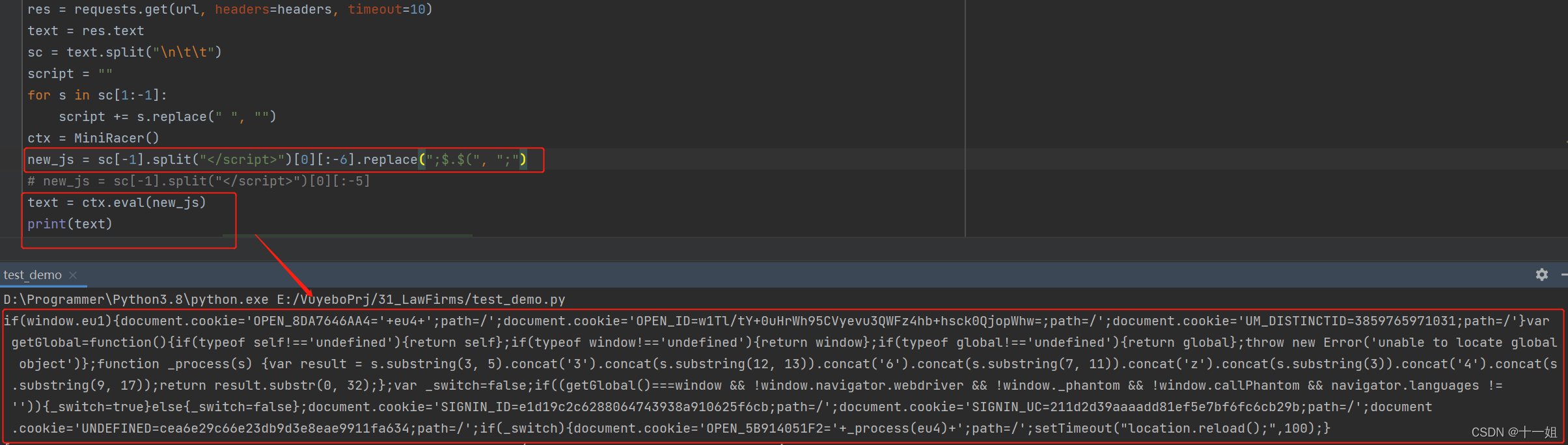
- 梳理流程,编写如下解析jsfuck的代码获取cookie逻辑如下
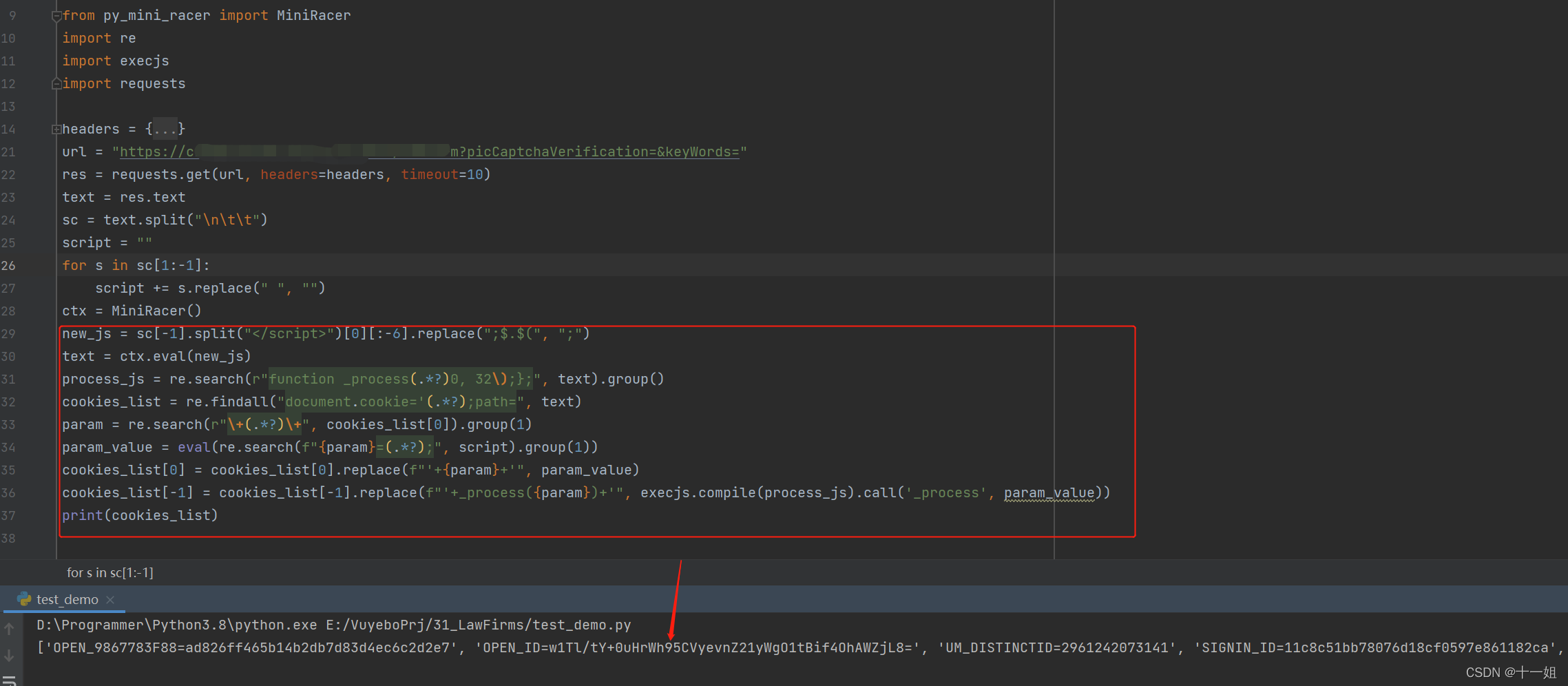
四、des解密详情url后缀
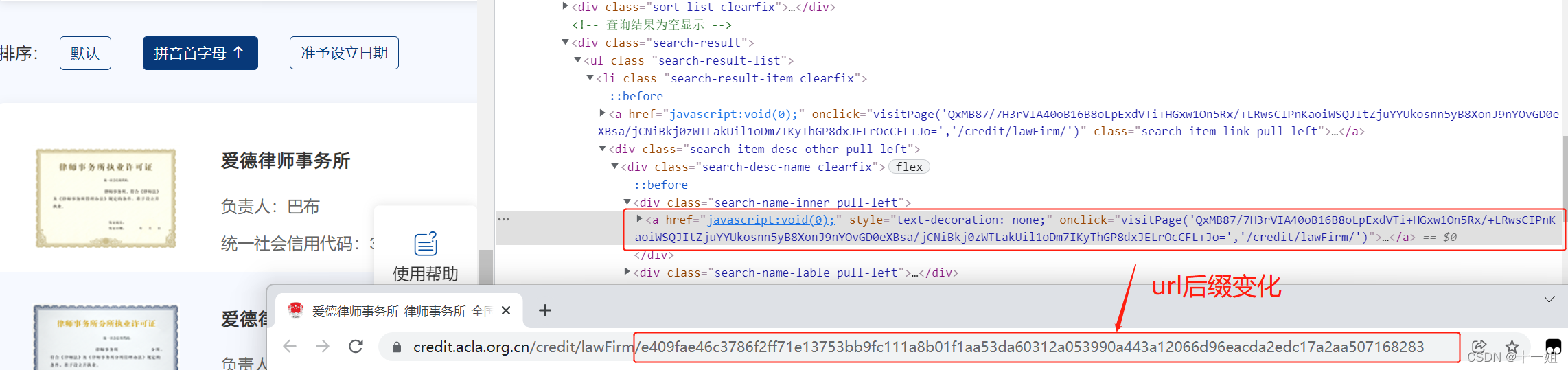
- 反爬4:url后缀变化
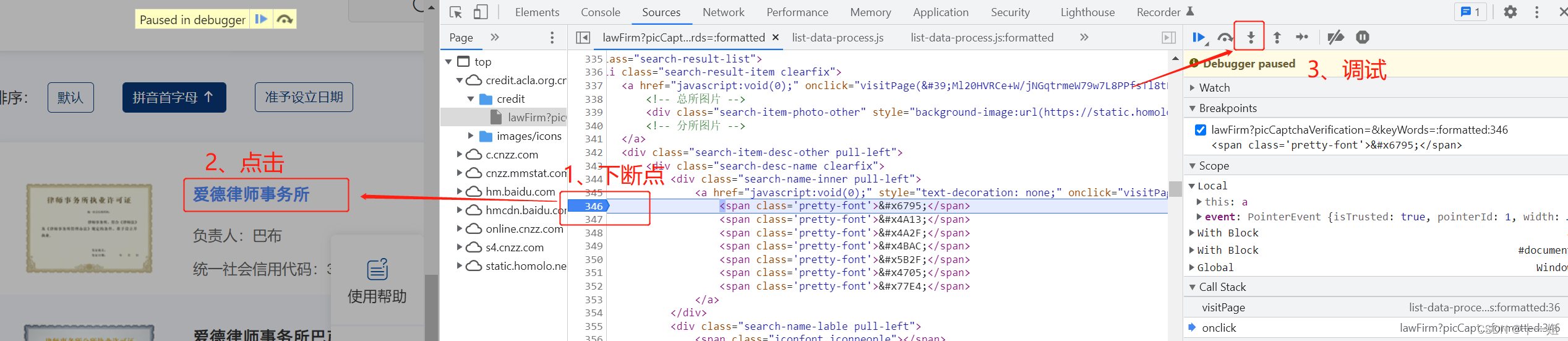
- 点击事件位置处下断点,然后调试

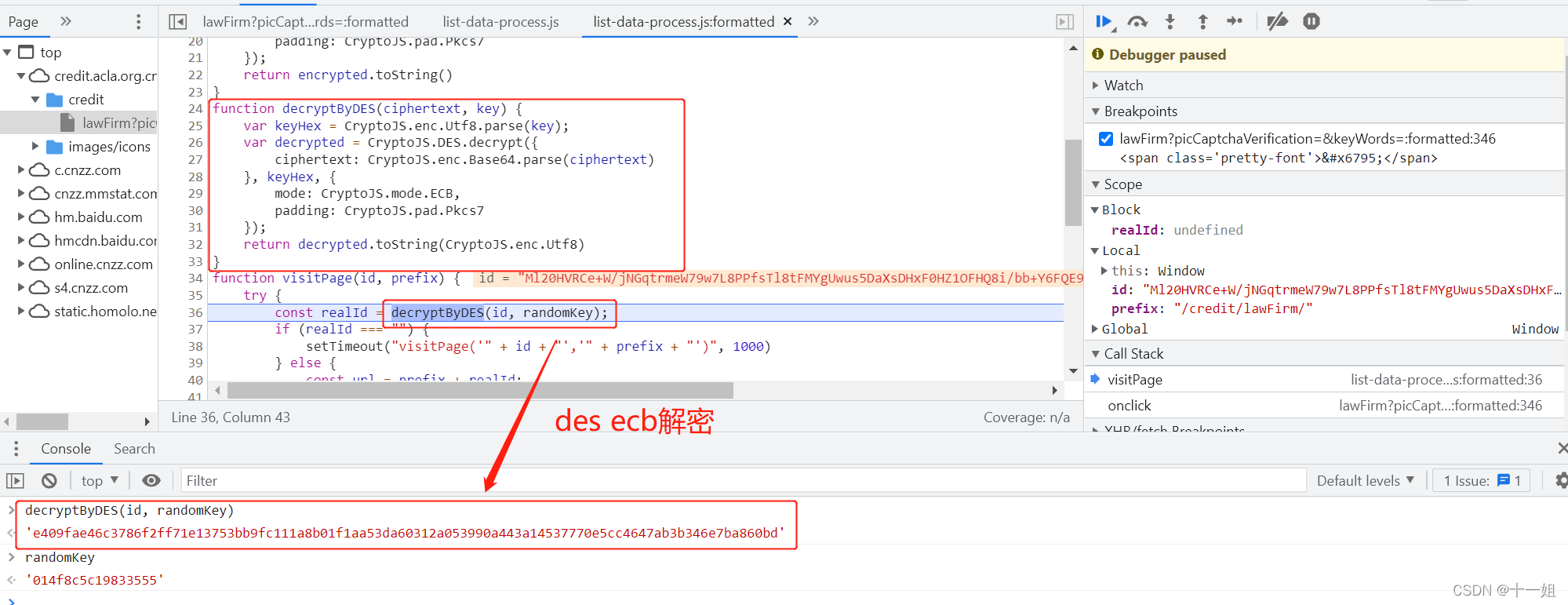
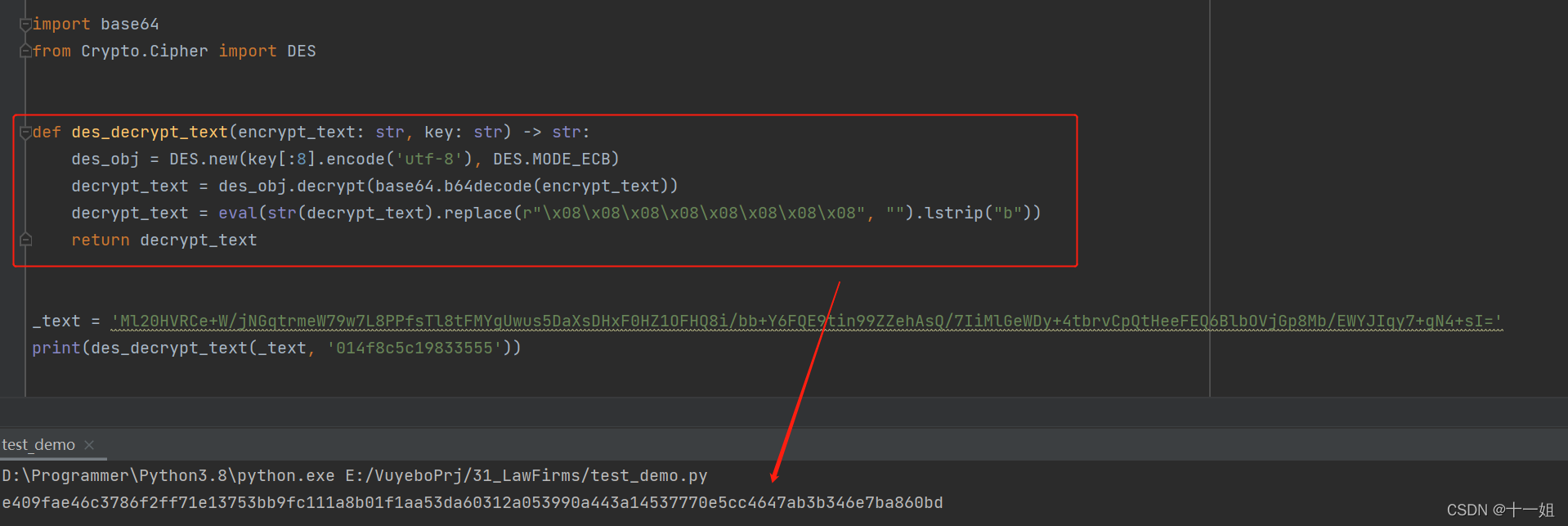
- 如图调试到如下位置,标准的des ecb解密,直接用python的
from Crypto.Cipher import DES进行解密,其中密钥是动态的,在响应里面可以拿到
五、woff动态字体反爬
-
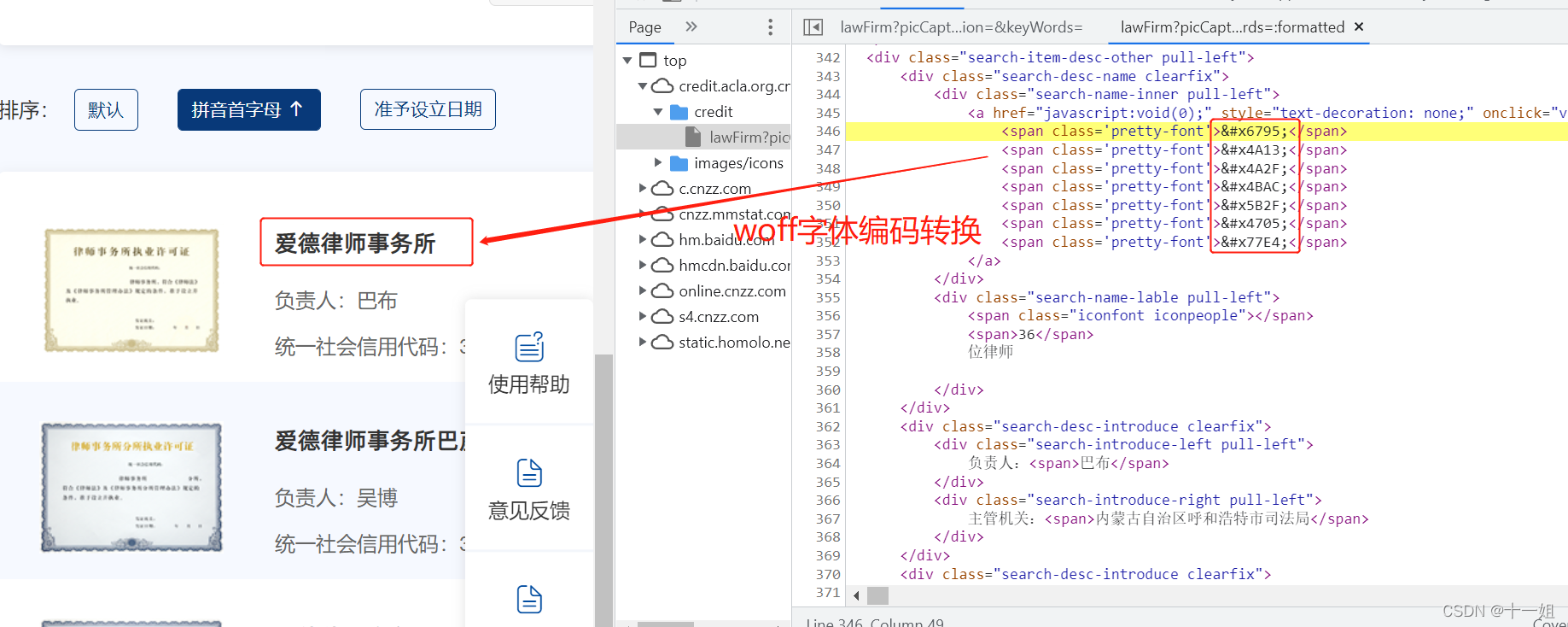
反爬5:woff字体编码转换,关于fontTools的使用 , 关于字体反爬介绍
-
每次刷新网页都会有一套新的ttf字体文件,也就是
动态文件,动态编码,有规律的坐标,属于中级难度css字体反爬
-
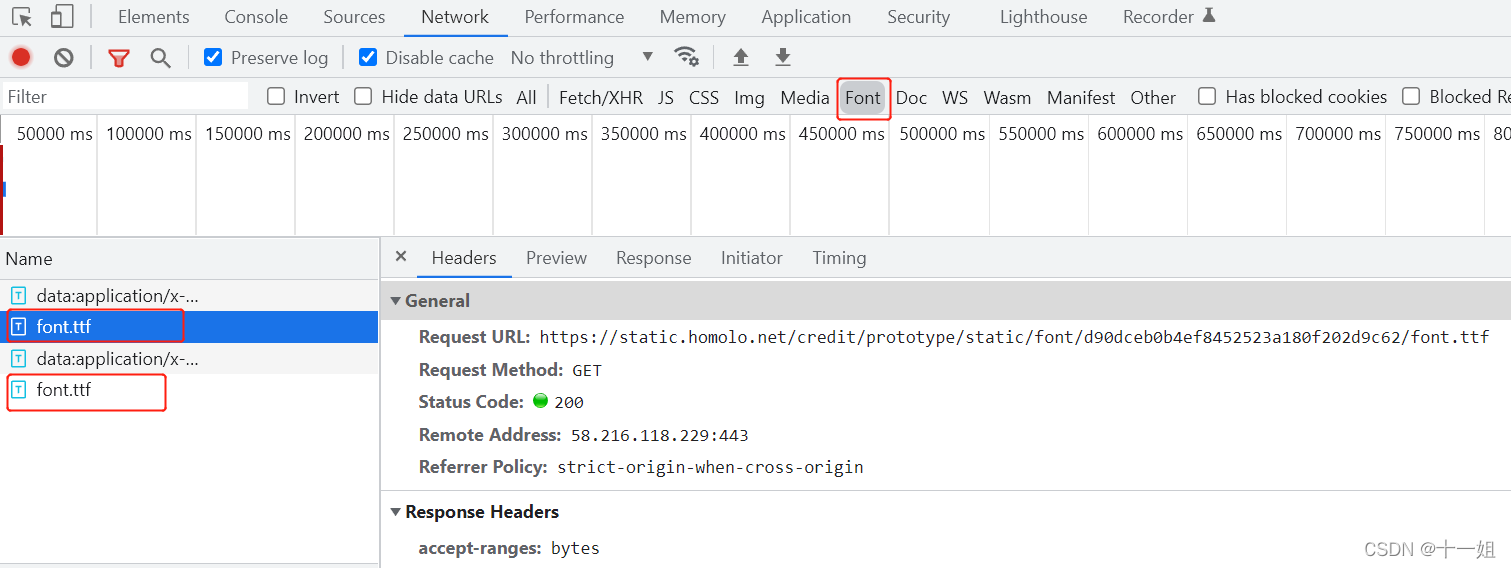
复制ttf链接到浏览器打开,下载ttf文件, 然后到https://font.qqe2.com/打开ttf文件,如图显示

-
同一个汉字
律,我们对比下两个ttf文件,分别对应的不同编码,也就是说明编码是动态变化的(因为字体文件ttf也是动态变化的)

-
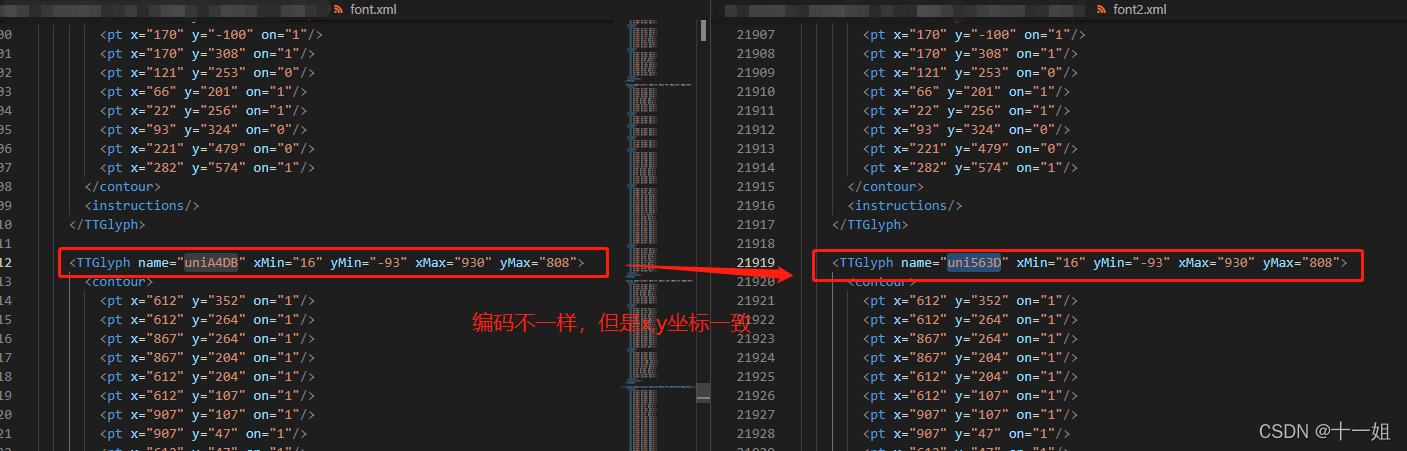
按如下代码将ttf文件保存成xml文件,并打开xml文件进行同一个汉字对比,
pip install fontTools,然后进行对比分析,发现虽然编码不一样,但是x,y坐标是一样的from fontTools.ttLib import TTFont font = TTFont("./font.ttf") font.saveXML('./font.xml') font = TTFont("./font2.ttf") font.saveXML('./font2.xml')

-
也就是说我们只要获得x/y坐标与字体映射关系就可以了,比如
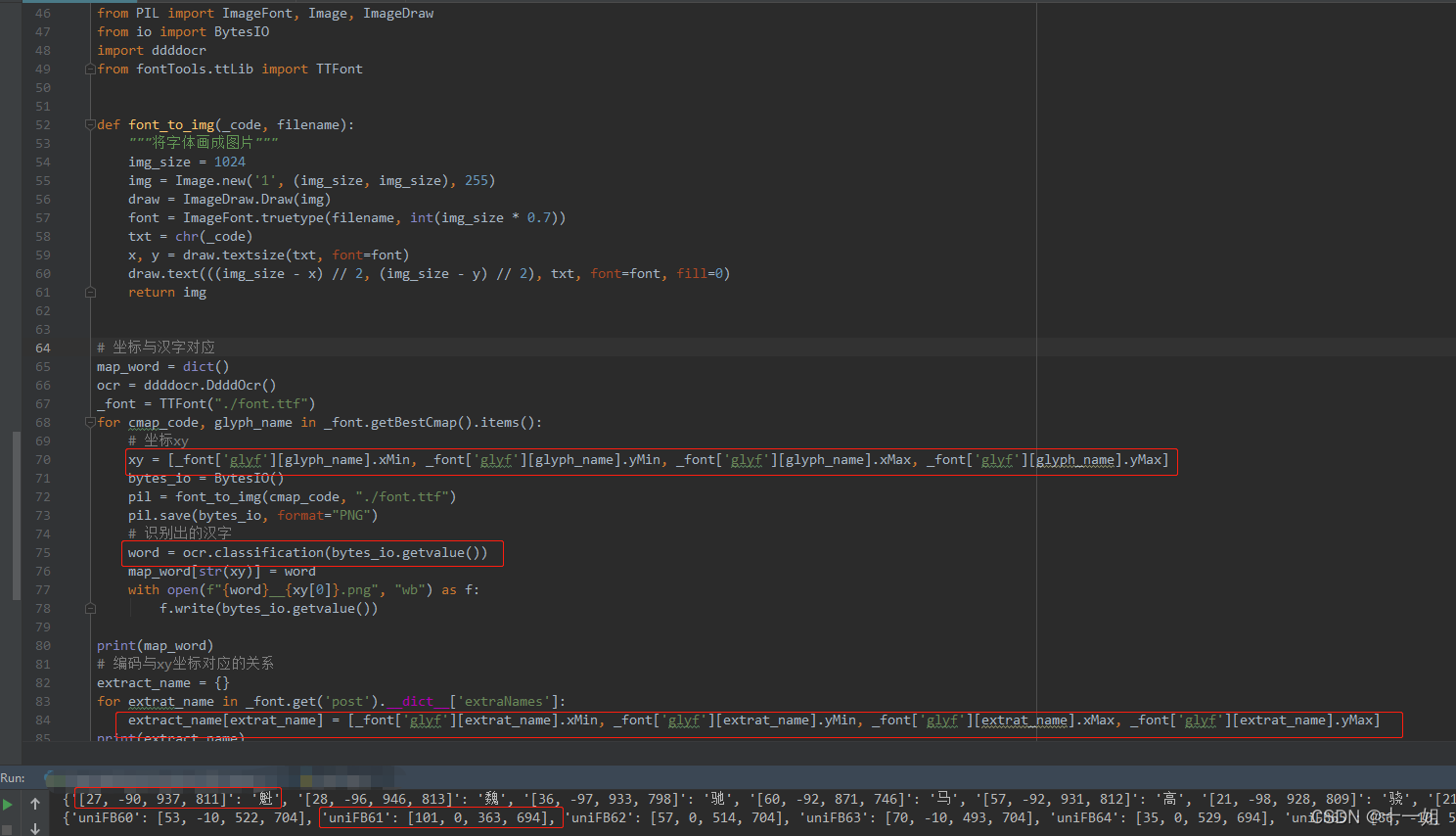
[{'[16, -93, 930, 808]': '律'}],而接下来每个ttf字体文件只需要获得x/y坐标,就可以得到相应的汉字了,先存一份xy坐标与字体映射关系,这里我们借助哲哥的ddddocr识别汉字,代码如下
from PIL import ImageFont, Image, ImageDraw from io import BytesIO import ddddocr from fontTools.ttLib import TTFont def font_to_img(_code, filename): """将字体画成图片""" img_size = 1024 img = Image.new('1', (img_size, img_size), 255) draw = ImageDraw.Draw(img) font = ImageFont.truetype(filename, int(img_size * 0.7)) txt = chr(_code) x, y = draw.textsize(txt, font=font) draw.text(((img_size - x) // 2, (img_size - y) // 2), txt, font=font, fill=0) return img # 坐标与汉字对应 map_word = dict() ocr = ddddocr.DdddOcr() _font = TTFont("./font.ttf") for cmap_code, glyph_name in _font.getBestCmap().items(): # 坐标xy xy = [_font['glyf'][glyph_name].xMin, _font['glyf'][glyph_name].yMin, _font['glyf'][glyph_name].xMax, _font['glyf'][glyph_name].yMax] bytes_io = BytesIO() pil = font_to_img(cmap_code, "./font.ttf") pil.save(bytes_io, format="PNG") # 识别出的汉字 word = ocr.classification(bytes_io.getvalue()) map_word[str(xy)] = word with open(f"{ word}__{ xy[0]}.png", "wb") as f: f.write(bytes_io.getvalue()) print(map_word) # 编码与xy坐标对应的关系 extract_name = { } for extrat_name in _font.get('post').__dict__['extraNames']: extract_name[extrat_name] = [_font['glyf'][extrat_name].xMin, _font['glyf'][extrat_name].yMin, _font['glyf'][extrat_name].xMax, _font['glyf'][extrat_name].yMax] print(extract_name)