在历经了前两part的了解和熟悉后,对于SRAM的了解基本已经了然如心了。
小伙伴们在这里就可以使用自己学习的知识,就可以对SRAM的生成和遴选可以建立一套自身的方法学和流程。在这一章节,笔者分享一些浅见,对这个自动化的流程进项一些头脑风暴和讨论。

SRAM 生成方法
基于不同工艺和FAB,都会有相应的memory team对指定工艺进行memory array和peripheral进行构建。这里的构建是指的是构建一些基础组件,然后通过打包的方式进行封装,以自动化命令的方式交付给用户,方便用户进行不同的配置和选型。
不同的SRAM vendor提供的套件往往不尽相同,有的可以支持GUI和batch,有的支持batch。相较而言,batch是一定要支持的,否则在大型项目下这类工作没法批量开展。这里以T家为例,使用batch mode进行SRAM的生成
> tsn7_1prf.exe -NonTsmcName -file $CFG_FILE
各家的SRAM都有自己默认名称,但是用户为了自身数据管理便利,通常需要使用自己的名称来进行规划,所以在T家的mem-gen的时候,建议大家使用自己的$CFG_FILE 进行名称定义,当然,这里的$CFG_FILE需要指定出SRAM具体的位宽、位深以及column MUX的信息。简单示例如下
 )
)
T家的command line还支持其他的一些选项,包括并不限于
- SRAM datasheet:包含SRAM的各种时序、功耗和物理信息
- 各种view的生成选择
- verilog仿真模型
- DFT view
- timing view
- Masis view
- SPICE view
- GDS view
- LEF view
- VOLTUS view
- 不同配置的选择(鉴于memory类型的不同,并非每种配置都可生成出来对应的memory,用户需要检查memgen 日志)
- DualRail:VDD/VDDM 时候使用不同的rail
- ULVT/SVT:对peripheral 的std-cell VT的选择,
- BIST: 控制是否支持MBIST模式
- bit-wise:是否支持bit 写操作
- etc…
所有的可配置接口都可以通过batch 模式下进行配置。这样的好处是可以支持用户在大面积SRAM遴选生成的时候实现自动化。
类似的SNPS在mem-gen里,会提供batch以及GUI接口,GUI操作相对方便一些,但是在批量生产的时候,还是需要使用batch提高生产效率
 )
)
实际项目中SRAM 遴选维度
有了上述的讲解以及工具的支撑,用户基本已经可以开始进行SRAM的生成了。上述的信息和资源最终都是支持实际项目的工具,项目对于不同SRAM的比较、匹配和选型等操作,才是可以真正作用的实际项目上来的。
现在的大型芯片,SRAM的用量面积有甚者可以占到整个项目将近一半的面积,所以对于SRAM的选型需要从以下几个方面进行考量
-
基于工艺的SRAM vendor的选择
- 渠道1:通常FAB在提供工艺的时候,也会提供SRAM vendor的推荐,常规的讲,FAB自己的SRAM一般都是免费的(应该搜是被TO费用所涵盖),譬如T家或者S家都会提供自己对应工艺的SRAM产品
- 渠道2:一些第三方的SRAM vendor , 他们已经和FAB之间建立了坚实的商业合同,FAB也会分享给用户,让用户自己去选择,用户在流片的时候只需要少量的royalty费用即可。
- 渠道3:对于某个工艺,有一些商业客户专门去研发了SRAM,并且可以做到比原厂FAB更好的PPA,譬如S家,A家等等,这个时候用户在使用的时候,需要像采购IP一样去额外付费,如果用户对某项PPA确实倚重,可以考量花这笔钱。
-
Rail的考虑:这个由于牵扯整个芯片的rail设计,必须在初期考虑清楚,项目通常采用统一的策略。现在的SRAM都支持SD/DSLP设计,没有外围isolate逻辑的损耗,但是SRAM内部的处理一定是有isolate的代价的。基于项目对于功耗和性能的平衡,在初期选定rail模式是非常必要的。
-
STAM的DFT相关:
- BIST: 由于SRAM里边有peripheral std-cell,这个MBIST的DFT功能可以支持对这类std-cell的fault定位。代价是由于输入pin脚的急剧增多,可能对于APR是个新的挑战,通常为了节省绕线资源,会跳过这些peripheral std-cell的MBIST 测试,直接对整块memory (包含memory array)进行MBIST测试

- BISR:为了实现良率,BISR有时也是需要,尤其是column redundancy bit,通过FAB给的数据,1bit的redundancy通常可进行修一检二的操作,性价比还是很高的。
- 所有的SRAM DFT相关部分,都需要额外的STD-cell支持,此类面积通常是memory 面积的5%~10%上下,对于大型芯片,在架构设计和面积评估的时候,此部分的影响需要全盘考量
- BIST: 由于SRAM里边有peripheral std-cell,这个MBIST的DFT功能可以支持对这类std-cell的fault定位。代价是由于输入pin脚的急剧增多,可能对于APR是个新的挑战,通常为了节省绕线资源,会跳过这些peripheral std-cell的MBIST 测试,直接对整块memory (包含memory array)进行MBIST测试
-
形状:由于过多memory (或者memory array)的存在,memory形状对于APR的floorplan和pin access有比较大的影响。具体示例可见:来做一次装修 之版图实现第二步 – Floorplan 。 这里有几点需要注意:
- 不要因为速度原因将column mux设置过大。导致memory 过度扁平
- 不要创建过小size的memory,有可能会导致常规的pg strap不能直接落在memory上,降低电源连接性能等等。
-
时序:这里重点说一下时序。由于memory的分布很广,项目很大的时候,memory的时序问题会成为某些核心组件的性能瓶颈,譬如:L1/L2 etc. 所以在对memory选型的时候,这里需要特注意一下几个要素
-
Tcycle: Minimum CLK cycle time CLK^ CLK^。这个参数描述的是这个memory所能支持的最小周期(最高频率),这个一定是要比项目规划的频率要高,另外由于这个参数也是一个clock input transition的查找表,通常clock-transition一版会定义为50ps左右,所以这里建议,选择memory的时候,Tcycle需要比项目的需求多一个20%的余量。如果项目的主频是1G,那么就要要求SRAM的Tcycle time在 ssg的条件下不能超过:0.8ns
-
Tckh/Tckl Minimum CLK Pulse High/Low。通常各是Tcycle的一半上下,这里需要注意一点,对于级数过多(latency 过长)的时钟网络,必须优先使用clock inverter来构建clock tree,这样才能在leaf(memory clock pin)控制好占空比,也就是尽量可以满足:Tckh/Tckl
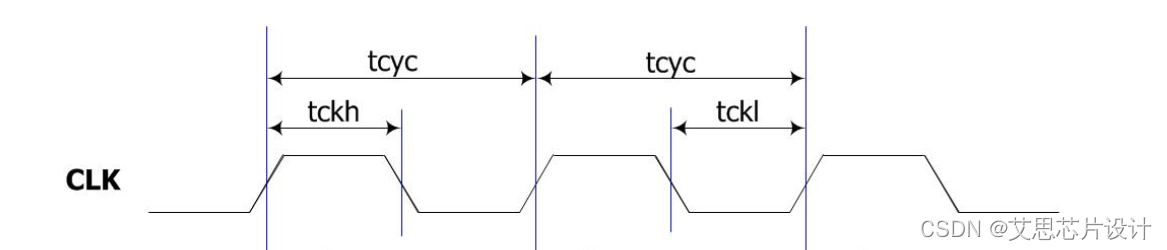
-
Tcd/Tacc: CLK to valid Q (data output)。这个是描述从memory 到Q 输出的时间,这个对from-memory的datapath影响比较大。
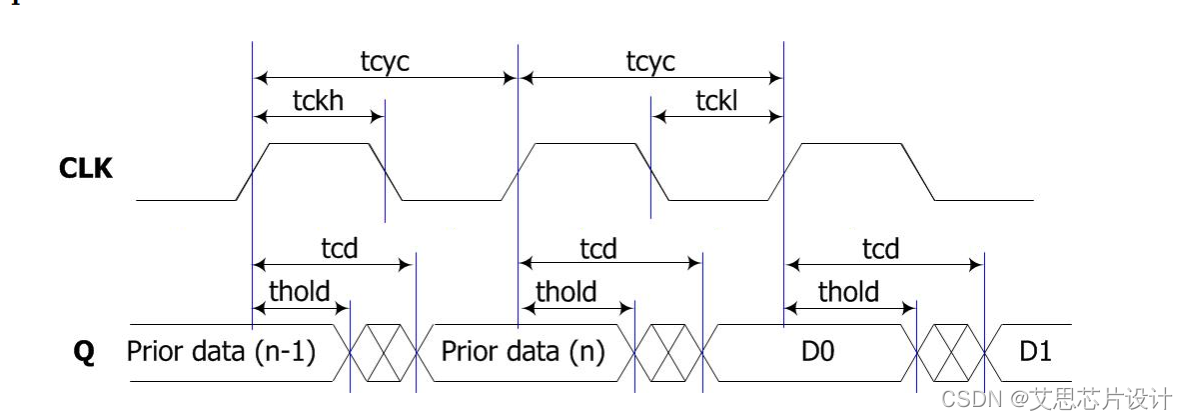
由于memory的规模通常比较大,这个访问时间通常都有200ps~朝上,所以对于一个timing path来看的化,这里可能是一个path上data的最大损耗
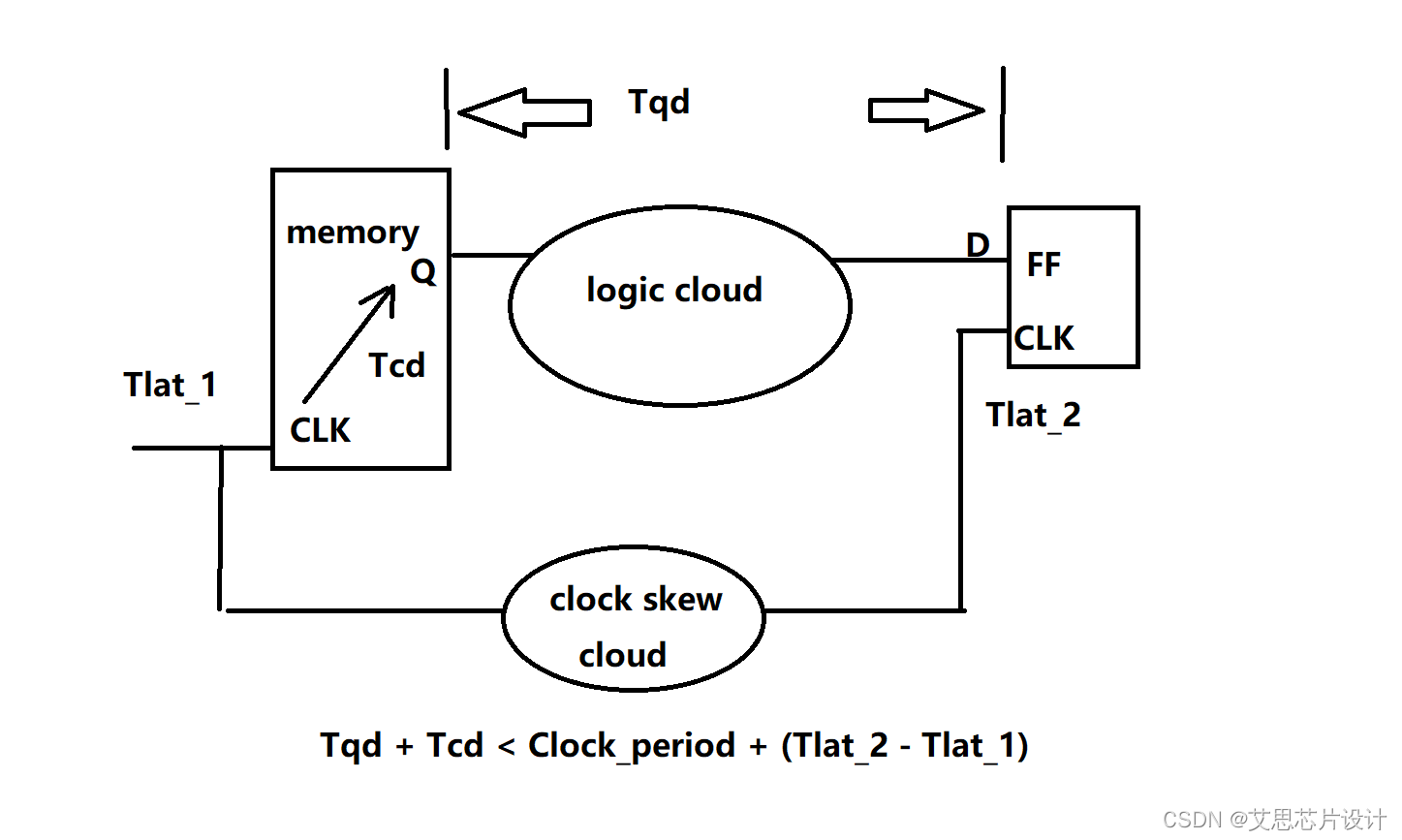
可以看到通过就降低Tqd和Tcd或者提高useful skew(Tlat_2 - Tlat_1),可以提高芯片的性能。
通常对于Tcd,要求不能超过整个period的60%为宜
-
-
功耗:不同的选型的memory 功耗也有不同,这时候memory的peripheral的ULVT和LVT的占比会让leakage有明显的区别,在选型的时候,需要辨别这两种的类型对时序的影响,从而采用合适的类型。
实际项目中SRAM 生成简易流程
通过对memory各项属性的理解,这里可以使用下面的简易流程来进行生成和遴选流程
- 确定rail和DFT对memory的通用需求
- 明确memory的位深和位宽需求,如果过大需要手动或者自动,基于前后端的定义的规律进行拆分
- 满足上述要求的memory进行批量生成:位宽、位深,column MUX和LVT/ULVT等配置不同,出来的结果不尽相同,这里需要遍历所有可能,提高选择范围
- 对所有的memory进行时序性能分析。需要同时满足上述描述的Tcd和Tcycle带余量的情况,才是可以用的memory
- 如果有满足时序要求的memory,再对功耗,高宽比进行再次遴选,选择功耗小,高宽比合理的memory交付实现使用;如果没有满足时序要求的memory,重新进行拆分(通常将位深砍半,时序会比较容易满足),然后再重复步骤3~5,直到选出合适的memory。
要点:
- memory的生成数据量巨大,一定需要使用脚本化的生成模式,譬如:excel-> perl -> memgen batch run -> analyze datasheet -> release suitable memory。
- 选型初期,可以只看datasheet,其他view可以先不生成,这样可以提高速度和减少磁盘占用。
- CM不宜过大来满足timing,可以适当拆分,让memory的形状更为合理。
- 默认使用LVT进行memory的peripheral规划,如果ECO的阶段有时序障碍,可以考量调换到ULVT进行局部timing pushing,可以牺牲一部分leakage 来换取性能和节省迭代周期。
- 同等logic memory的对应physical memory,尽量选择同等规格,这样在floorplan布局的时候会容易处理,减少channel,提高利用率。
本章词汇
| 词汇 | 解释 |
|---|---|
| Tcycle | memory 支持的最小周期(最高频率) |
| Tcd/Tacc | memory 的访问时间 CLK-> Q |
【敲黑板划重点】

通过三篇的学习,对于memory的结构,原理,特征参数、批处理生成和项目遴选都有了基本的了解和认识,希望这个系列的文章可以带给大家灵感和启发,在项目中可以更好地理解和应用memory,对项目带来更高效的收益和PPA。
参考资料
TSMC TSMC N7 SRAM Compiler Databook
Synopsys Embed-It! Integrator User Manual